Logistic回归推导(三)--牛顿法及纯python实现
1、牛顿法图解
牛顿法一般用来求解方程的根或求解极值,其基本思想是:在现有极值点估计值附近对f(x)做二阶泰勒展开,从而找到极值点的下一个估计值。
下面用一个例图说明:
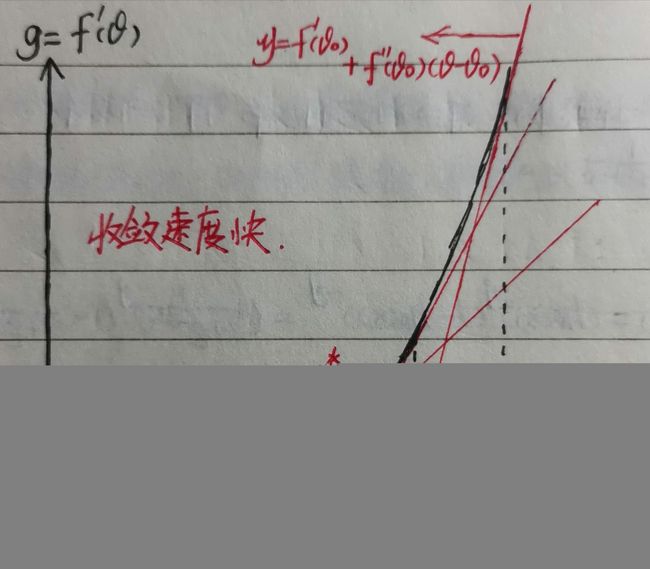
如图横坐标为参数 θ \theta θ,纵坐标为函数一阶导数 f ′ ( θ ) f^{'}(\theta) f′(θ),则牛顿法迭代过程如下:
(1)过点 ( θ 0 , f ′ ( θ 0 ) ) (\theta_{0},f^{'}(\theta_{0})) (θ0,f′(θ0))作切线,切线方程为 y = f ′ ( θ 0 ) + f ′ ′ ( θ 0 ) ( θ − θ 0 ) y=f^{'}(\theta_{0})+f^{''}(\theta_{0})(\theta-\theta_{0}) y=f′(θ0)+f′′(θ0)(θ−θ0);
(2)切线交横轴于 θ 1 = θ 0 − f ′ ( θ 0 ) f ′ ′ ( θ 0 ) \theta_{1}=\theta_{0}-\frac{f^{'}(\theta_{0})}{f^{''}(\theta_{0})} θ1=θ0−f′′(θ0)f′(θ0)处;
(3)过点 ( θ 1 , f ′ ( θ 1 ) ) (\theta_{1},f^{'}(\theta_{1})) (θ1,f′(θ1))作切线,切线方程为 y = f ′ ( θ 1 ) + f ′ ′ ( θ 1 ) ( θ − θ 1 ) y=f^{'}(\theta_{1})+f^{''}(\theta_{1})(\theta-\theta_{1}) y=f′(θ1)+f′′(θ1)(θ−θ1);
(4)切线交横轴于 θ 2 = θ 1 − f ′ ( θ 1 ) f ′ ′ ( θ 1 ) \theta_{2}=\theta_{1}-\frac{f^{'}(\theta_{1})}{f^{''}(\theta_{1})} θ2=θ1−f′′(θ1)f′(θ1)处;
(5)重复迭代得到 θ ∗ \theta^{*} θ∗。
2、牛顿法原理
(1)当样本只有一个特征
假设 f ( x ) f(x) f(x)二次可微,设 x = x m i n x=x_{min} x=xmin时,函数f(x)取得最小值,我们的目标就是希望能求得 x m i n x_{min} xmin。
首先用 x k x_{k} xk作为 x m i n x_{min} xmin的估计值,在 x = x k x=x_{k} x=xk处进行二阶泰勒展开:
f ( x ) ≈ f ( x k ) + f ′ ( x k ) ( x − x k ) + 1 2 f ′ ′ ( x k ) ( x − x k ) 2 f(x)\approx f(x_{k})+f^{'}(x_{k})(x-x_{k})+\frac{1}{2}f^{''}(x_{k})(x-x_{k})^{2} f(x)≈f(xk)+f′(xk)(x−xk)+21f′′(xk)(x−xk)2
求 f ( x ) f(x) f(x)的极值即求导数为0处的 x x x,对 f ( x ) f(x) f(x)求导:
f ′ ( x ) = 0 + f ′ ( x k ) ( 1 − 0 ) + 1 2 f ′ ′ ( x k ) 2 ( x − x k ) = f ′ ( x k ) + f ′ ′ ( x k ) ( x − x k ) \begin{aligned} f^{'}(x)&=0+f^{'}(x_{k})(1-0)+\frac{1}{2}f^{''}(x_{k})2(x-x_{k})\\ &=f^{'}(x_{k})+f^{''}(x_{k})(x-x_{k}) \end{aligned} f′(x)=0+f′(xk)(1−0)+21f′′(xk)2(x−xk)=f′(xk)+f′′(xk)(x−xk)
令其为0得到下一个估计值 x = x k − f ′ ( x k ) f ′ ′ ( x k ) x=x_{k}-\frac{f^{'}(x_{k})}{f^{''}(x_{k})} x=xk−f′′(xk)f′(xk)
故迭代公式为:
x k + 1 = x k − f ′ ( x k ) f ′ ′ ( x k ) x_{k+1}=x_{k}-\frac{f^{'}(x_{k})}{f^{''}(x_{k})} xk+1=xk−f′′(xk)f′(xk)
(1)当样本有多个特征
二阶泰勒展开式的推广为:
φ ( X ) ≈ f ( X k ) + ▽ f ( X k ) ⋅ ( X − X k ) + 1 2 ( X − X k ) T ⋅ ▽ 2 f ( X k ) ⋅ ( X − X k ) \varphi(X) \approx f(X_{k})+\bigtriangledown f(X_{k}) \cdot (X-X_{k})+\frac{1}{2}(X-X_{k})^{T}\cdot \bigtriangledown^{2}f(X_{k})\cdot(X-X_{k}) φ(X)≈f(Xk)+▽f(Xk)⋅(X−Xk)+21(X−Xk)T⋅▽2f(Xk)⋅(X−Xk)
其中 ▽ f \bigtriangledown f ▽f为 f f f的梯度向量
▽ f = [ ∂ f ∂ x 1 ∂ f ∂ x 2 . . . ∂ f ∂ x N ] T \bigtriangledown f=[\frac{\partial f}{\partial x_{1}}\quad \frac{\partial f}{\partial x_{2}}\quad ... \quad \frac{\partial f}{\partial x_{N}}]^{T} ▽f=[∂x1∂f∂x2∂f...∂xN∂f]T
▽ 2 f \bigtriangledown^{2}f ▽2f为 f f f的海森矩阵。
由 ▽ φ ( X ) = 0 \bigtriangledown \varphi(X)=0 ▽φ(X)=0,即
▽ f ( X k ) + ▽ 2 f ( X k ) ⋅ ( X − X k ) = 0 \bigtriangledown f(X_{k})+\bigtriangledown^{2}f(X_{k})\cdot(X-X_{k})=0 ▽f(Xk)+▽2f(Xk)⋅(X−Xk)=0
得下一个极值的估计值为
X = X k − ▽ 2 f ( X k ) − 1 ▽ f ( X k ) X=X_{k}-\bigtriangledown^{2}f(X_{k})^{-1}\bigtriangledown f(X_{k}) X=Xk−▽2f(Xk)−1▽f(Xk)
令 ▽ f = g k , ▽ 2 f = H k \bigtriangledown f=g_{k},\bigtriangledown^{2}f=H_{k} ▽f=gk,▽2f=Hk,则迭代公式为
X k + 1 = X k − H k − 1 g k X_{k+1}=X_{k}-H_{k}^{-1}g_{k} Xk+1=Xk−Hk−1gk
3、牛顿法求解Logistic回归
Logistic回归假设函数为:
P ( y ∣ x ; θ ) = [ h θ ( x ) ] y [ 1 − h θ ( x ) ] ( 1 − y ) = ( 1 1 + e − θ T x ) y ( 1 − 1 1 + e − θ T x ) 1 − y \begin{aligned} P(y|x;\theta)&=[h_{\theta}(x)]^{y}[1-h_{\theta}(x)]^{(1-y)}\\ &=(\frac{1}{1+e^{-\theta^{T}x}})^{y}(1-\frac{1}{1+e^{-\theta^{T}x}})^{1-y} \end{aligned} P(y∣x;θ)=[hθ(x)]y[1−hθ(x)](1−y)=(1+e−θTx1)y(1−1+e−θTx1)1−y
其目标函数为:
arg m a x θ 1 N ∑ i = 1 N [ y ( i ) l n h θ ( x ( i ) ) + ( 1 − y ( i ) ) l n ( 1 − h θ ( x ( i ) ) ) ] \text{arg } \underset{\theta}{max}\frac{1}{N}\sum_{i=1}^{N}[y^{(i)}lnh_{\theta}(x^{(i)})+(1-y^{(i)})ln(1-h_{\theta}(x^{(i)}))] arg θmaxN1i=1∑N[y(i)lnhθ(x(i))+(1−y(i))ln(1−hθ(x(i)))]
则
▽ J ( θ ) = 1 N ∑ i = 1 N [ h θ ( x ( i ) ) − y ( i ) ] x ( i ) \bigtriangledown J(\theta)=\frac{1}{N}\sum_{i=1}^{N}[h_{\theta}(x^{(i)})-y^{(i)}]x^{(i)} ▽J(θ)=N1i=1∑N[hθ(x(i))−y(i)]x(i)
H = ▽ 2 J ( θ ) = ▽ 1 N ∑ i = 1 N [ h θ ( x ( i ) ) − y ( i ) ] x ( i ) = ▽ 1 N ∑ i = 1 N h θ ( x ( i ) ) ⋅ x ( i ) = 1 N ∑ i = 1 N ∂ h θ ( x ( i ) ) ∂ θ ⋅ ( x ( i ) ) T = 1 N ∑ i = 1 N h θ ( x ( i ) ) T ⋅ ( 1 − h θ ( x ( i ) ) ) ⋅ x ( i ) ⋅ ( x ( i ) ) T \begin{aligned} H=\bigtriangledown^{2}J(\theta)&=\bigtriangledown\frac{1}{N}\sum_{i=1}^{N}[h_{\theta}(x^{(i)})-y^{(i)}]x^{(i)}\\ &=\bigtriangledown\frac{1}{N}\sum_{i=1}^{N}h_{\theta}(x^{(i)})\cdot x^{(i)}\\ &=\frac{1}{N}\sum_{i=1}^{N}\frac{\partial h_{\theta}(x^{(i)})}{\partial \theta} \cdot (x^{(i)})^{T}\\ &=\frac{1}{N}\sum_{i=1}^{N}h_{\theta}(x^{(i)})^{T} \cdot (1-h_{\theta}(x^{(i)})) \cdot x^{(i)} \cdot (x^{(i)})^{T} \end{aligned} H=▽2J(θ)=▽N1i=1∑N[hθ(x(i))−y(i)]x(i)=▽N1i=1∑Nhθ(x(i))⋅x(i)=N1i=1∑N∂θ∂hθ(x(i))⋅(x(i))T=N1i=1∑Nhθ(x(i))T⋅(1−hθ(x(i)))⋅x(i)⋅(x(i))T
使用牛顿法更新权重:
θ ( t + 1 ) : = θ ( t ) − H − 1 ▽ J ( θ ) \theta^{(t+1)}:=\theta^{(t)}-H^{-1}\bigtriangledown J(\theta) θ(t+1):=θ(t)−H−1▽J(θ)
4、纯python实现
代码如下:
import numpy as np
import matplotlib.pyplot as plt
import time
# 加载数据
def load_data():
X_train = np.loadtxt("./Exam/train/x.txt")
Y_train = np.loadtxt("./Exam/train/y.txt", dtype=int)
X_test = np.loadtxt("./Exam/test/x.txt")
Y_test = np.loadtxt("./Exam/test/y.txt", dtype=int)
return X_train, Y_train, X_test, Y_test
# Logistic回归类
class Logistic(object):
def __init__(self, X_train, Y_train):
self.X_train = X_train
self.Y_train = Y_train
# M:特征数,N:样本数
self.M = X_train.shape[1]
self.N = X_train.shape[0]
self.train()
def normalization(self):
# 均值方差归一化
mean = np.mean(self.X_train)
variance = np.std(self.X_train)
self.X_train = (self.X_train - mean)/variance
self.X_train = np.insert(self.X_train, 0, values=1.0, axis=1)
self.Y_train = self.Y_train.reshape(self.N, 1)
self.M += 1
def sigmoid(self, X):
eta = -np.dot(X, self.theta) # N*1
H = np.exp(eta)
H = 1.0 / (1.0 + H)
return H
def Newton_method(self):
self.theta = -np.ones((self.M, 1))
for i in range(100):
self.H = self.sigmoid(self.X_train)
self.J = np.dot(self.X_train.T, (self.H - self.Y_train)) #M*1
self.Hession = np.dot(self.H.T, self.X_train).dot(self.X_train.T).dot((1.0 - self.H)) / self.N
self.theta -= np.dot(self.J, np.linalg.inv(self.Hession))
self.loss = -np.sum(self.Y_train * np.log(self.H) + (1.0 - self.Y_train)* np.log(1 - self.H))/self.N
print("iter: %d, loss: %f" % (i, self.loss))
print(self.theta)
def train(self):
self.normalization()
self.Newton_method()
if __name__ == "__main__":
X_train, Y_train, X_test, Y_test = load_data()
Logistic(X_train, Y_train)
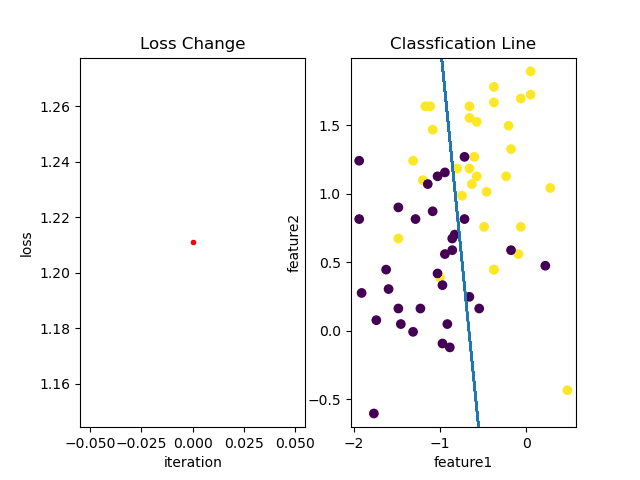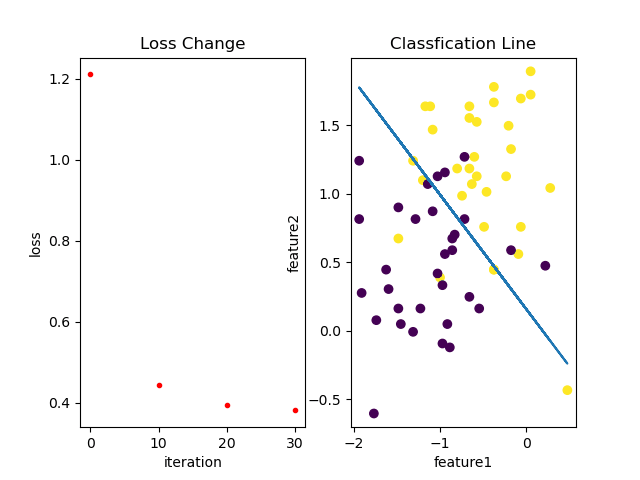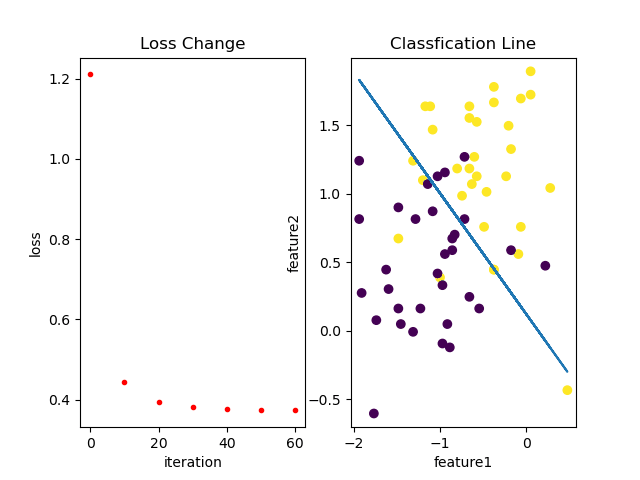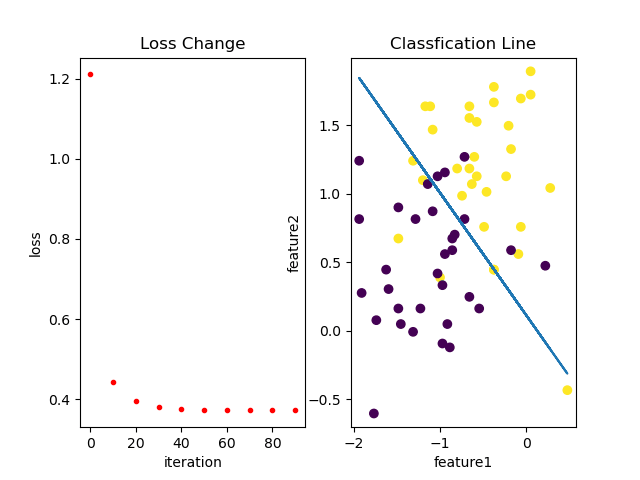
训练过程中loss变化以及分类效果如下:
(自己学习机器学习的笔记,如有错误望提醒修正)