深度学习入门--感知机与神经网络
1. 从简单线性分类器到深度学习
给定4个特征,简单线性分类器进行的是加权计算。
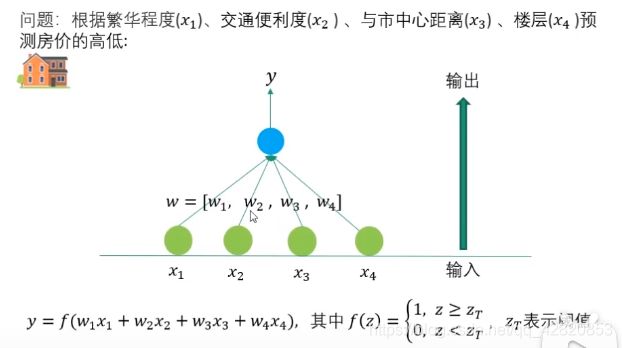
深度学习中,在输入层和输出层之间加入了中间层,即隐藏层。
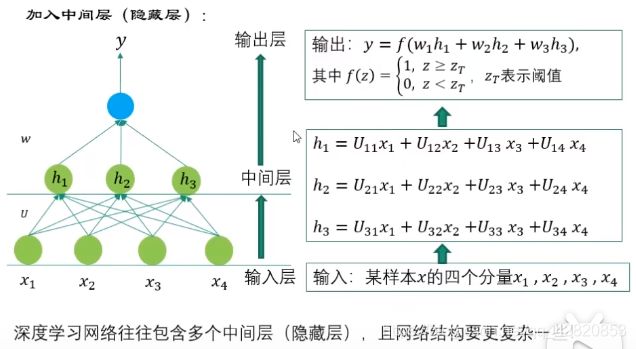
在中间层,由原来的4个特征变成了3个,深度学习的一个特点就是:通过组合低层特征形成更加抽象的高层特征。
传统机器学习先从图像中提取特征量,再用机器学习技术学习这些特征量的模式。这里所说的“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。图像的特征量通常表示为向量的形式。在计算机视觉领域,常用的特征量包括SIFT、 SURF和HOG等。使用这些特征量将图像数据转换为向量,然后对转换后的向量使用机器学习中的SVM、 KNN等分类器进行学习。但是需要注意的是,将图像转换为向量时使用的特征量仍是由人设计的。也就是说,即使使用特征量和机器学习的方法,也需要针对不同的问题人工考虑合适的特征量。
神经网络直接学习图像本身。神经网络都是通过不断地学习所提供的数据,尝试发现待求解的问题的模式。也就是说,与待处理的问题无关,神经网络可以将数据直接作为原始数据,进行“端对端”的学习。
2. 感知机
2.1 什么是感知机
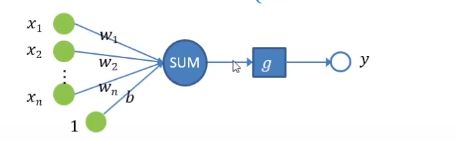
感知机是两类分类的线性分类模型。假设输入为实例样本的特征向量 x x x,输出为实例样本的类别 y y y,则由输入空间到输出空间的如下函数称为感知机:
y = g ( ∑ i = 1 n w i x i + b ) y=g(\sum_{i=1}^{n}w_ix_i+b) y=g(∑i=1nwixi+b)或者 y = g ( w ⋅ x + b ) y=g(w \cdot x+b) y=g(w⋅x+b)
g为激励函数,已到达对样本分类的目的。Rosenblatt的感知机用阶跃函数作为激励函数,其公式如下:
g ( z ) = { 1 , ( z > 0 ) 0 , ( z < = 0 ) \begin{aligned} g(z)=\left\{\begin{matrix} 1, (z>0)\\ 0,(z<=0) \end{matrix}\right. \end{aligned} g(z)={ 1,(z>0)0,(z<=0)
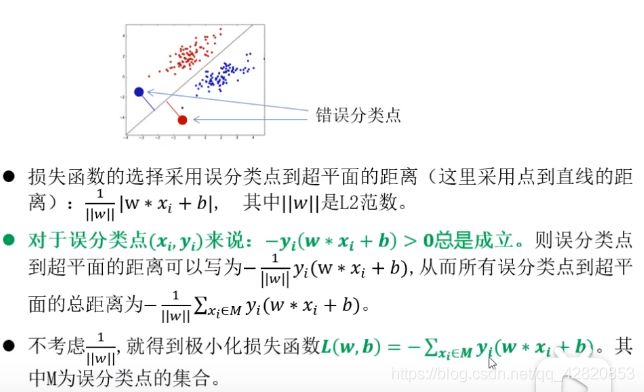
2.2 感知机模型的损失函数
2.3 感知机模型的优化–随机梯度下降法

2.4 感知机学习算法

一层感知机是线性分类模型,2层感知机便可以进行非线性分类。
一般来说,“朴素感知机”是指单层网络,指的是激活函数使用了阶跃函数的模型;“多层感知机”是指神经网络,即使用sigmoid函数等平滑激活函数的多层网络。
3. 神经网络基础
3.1 激活函数
感知机与神经网络的主要区别就在于激活函数。其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。感知机使用阶跃函数作为激活函数,如果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。
sigmoid函数
h ( x ) = 1 1 + e − x \begin{aligned} h(x)=\frac{1}{1+e^{-x}} \end{aligned} h(x)=1+e−x1
神经网络中使用sigmoid函数作为激活函数,进行信号的转换。转换后的信号被传递给下一个神经元。
sigmoid函数和阶跃函数的比较:
(1)sigmoid函数是一条平滑的曲线,输出随着输入发生连续性变化,而阶跃函数以0为界,输出发生急剧性变化;
(2)两者的值都在0到1之间,在输入小时,输出接近0(为0),输入大时,输出接近1(为1),即当输入信号为重要信号时,两个函数都会输出较大的值;
(3)两者都是非线性函数。
ReLU函数
h ( x ) = { x , ( x > 0 ) 0 , ( x < 0 ) \begin{aligned} h(x)=\left\{\begin{matrix} x, (x>0)\\ 0,(x<0) \end{matrix}\right. \end{aligned} h(x)={ x,(x>0)0,(x<0)
当输入大于0时,直接输出该值;输入小于等于0时,输出0.
神经网络的激活函数必须使用非线性函数。线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”,这样的话,加深网络的层数就没有意义了。
import numpy as np
import matplotlib.pyplot as plt
#阶跃函数的实现
def step_function0(x):
if x > 0:
return 1
else:
return 0
#这里参数x只能接受实数,为了允许参数为Numpy数组,进行改进如下
def step_function(x):
y = x > 0 #布尔型数组
return y.astype(np.int) #将布尔型转换为数值型
#sigmoid函数的实现
def sigmoid(x):
return 1 / (1 + np.exp(-x))
#ReLU函数的实现
def relu(x):
return np.maximum(0, x)
3.2 3层神经网络从输入到输出的前向处理
从输入层到第1层
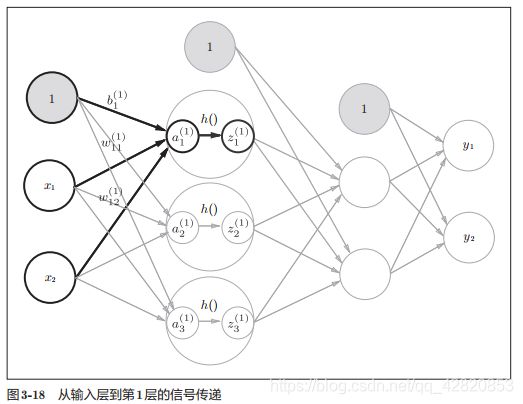
计算过程如下:
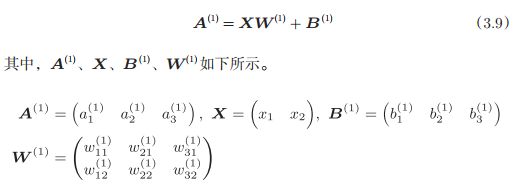
隐藏层的加权和(加权信号和偏置的总和)用a表示,被激活函数转换后的信号用z表示。此外,图中h()表示激活函数,这里我们使用的是sigmoid函数。
从第1层到第2层
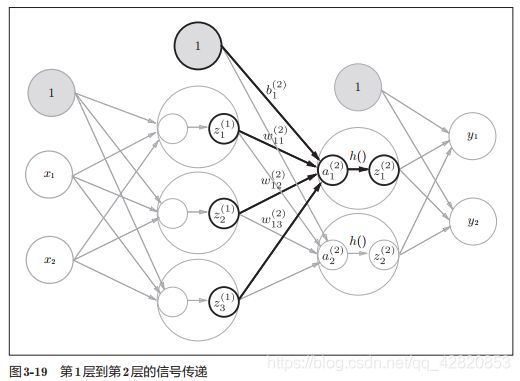
计算过程与上一层类似。
从第2层到输出层
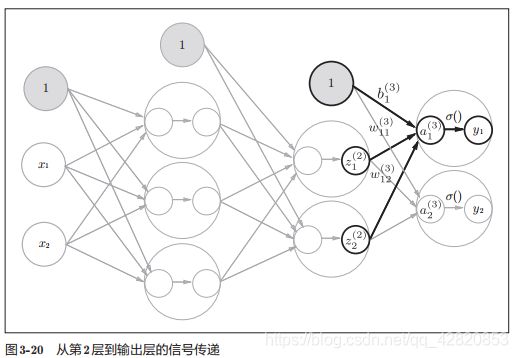
输出层所用的激活函数,要根据求解问题的性质决定。一般地,回归问题可以使用恒等函数,二元分类问题可以使用 sigmoid函数,多元分类问题可以使用 softmax函数。
#实现3层神经网络从输入到输出的前向传播
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]);
B1 = np.array([0.1, 0.2, 0.3])
A1 = np.dot(X, W1) + B1 #第0层到第1层
Z1 = sigmoid(A1)
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
A2 = np.dot(Z1, W2) + B2 #第1层到第2层
Z2 = sigmoid(A2)
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3 #第2层到输出层
Y = A3
3.3 输出层的设计
恒等函数
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直接输出。因此,在输出层使用恒等函数时,输入信号会原封不动地被输出。
softmax函数
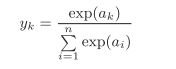
softmax函数的输出是0.0到1.0之间的实数。并且, softmax函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正因为有了这个性质,我们才可以把softmax函数的输出解释为“概率”。即便使用了softmax函数,各个元素之间的大小关系也不会改变。这是因为指数函数(y = exp(x))是单调递增函数。
softmax函数的实现中要进行指数函数的运算,但是此时指数函数的值很容易变得非常大。比如, e10的值会超过20000, e100会变成一个后面有40多个0的超大值, e1000的结果会返回一个表示无穷大的inf。如果在这些超大值之间进行除法运算,结果会出现“不确定”的情况。

这里的 C ′ C' C′可以使用任何值,但是为了防止溢出,一般会使用输入信号中的最大值。
#实现softmax函数
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) #溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
上面实现的函数是针对一条数据的,下面函数的针对批量数据的。
def softmax(x):
if x.ndim == 2:
x = x - np.max(x, axis=1).reshape((-1,1))
y = np.exp(x) / np.sum(np.exp(x), axis=1).reshape((-1,1))
return y
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。