吴恩达机器学习笔记(十五)-异常检测
第十六章 异常检测
问题动机
这一章中将介绍异常检测问题,这是机器学习算法的常见应用,那么什么是异常检测问题?
举例:比如生产汽车引擎,需要进行质量测试,而作为测试的一部分,需要测量汽车引擎的一些特征变量:

(1)引擎运转时产生的热量;
(2)引擎的振动;
于是就会有一个数据集:![]() ,把数据绘制成图,如下图:
,把数据绘制成图,如下图:
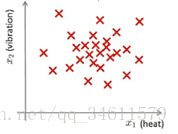
这样,异常检测问题可以定义如下:
假设,之后生产了一个新的汽车引擎,而新的汽车引擎有一个特征变量集![]() ,所谓的异常检测问题就是希望知道新的汽车引擎是否有某种异常,或者说希望判断这个引擎是否需要进一步测试。
,所谓的异常检测问题就是希望知道新的汽车引擎是否有某种异常,或者说希望判断这个引擎是否需要进一步测试。

如果 落在原来的特征集之中,认为它是没有异常的;如果
落在原来的特征集之中,认为它是没有异常的;如果![]() 出现在离原来的特征集很远的地方,则认为它是有异常的,需要做进一步检测,如上图所示。
出现在离原来的特征集很远的地方,则认为它是有异常的,需要做进一步检测,如上图所示。
更正式地定义:给定一个数据集,对它进行数据建模![]() ,当有新的特征变量
,当有新的特征变量![]() 时:
时:

异常检测的应用案例:
(1)欺诈检测:例如有些网站会记录用户的一些信息,打字速度![]() 、单位时间浏览网页次数
、单位时间浏览网页次数![]() 等等,然后用这些建立模型
等等,然后用这些建立模型![]() ,看哪些用户的
,看哪些用户的![]() 。
。

接下来看筛选出![]() 的用户,让他们做身份验证,从而可以让网站防御异常行为或欺诈行为。
的用户,让他们做身份验证,从而可以让网站防御异常行为或欺诈行为。
(2)工业生产领域:就像之前提到的汽车引擎的问题,可以找到异常的汽车引擎,然后进一步的检测这些引擎的质量。
(3)数据中心的计算机监控:如果管理一个计算机集群,可以为每台计算机计算特征向量,内存损耗![]() 、硬盘访问量
、硬盘访问量 、CPU负载
、CPU负载![]() 等等。
等等。

给定正常情况下数据中心计算机的特征变量,可以建立模型![]() ,观察是否有某台计算机
,观察是否有某台计算机![]() ,可以检测这些计算机的情况。
,可以检测这些计算机的情况。
这就是异常检测问题,接下来将继续探讨有关异常检测的算法。
高斯分布
这一节中将讨论高斯分布,也加正态分布,下一节中将由高斯分布推导异常检测算法。
假设x是一个实数的随机变量(![]() ),如果x服从高斯分布,其均值为
),如果x服从高斯分布,其均值为![]() ,方差为
,方差为![]() ,记作
,记作![]() 。
。
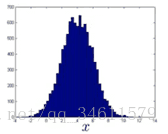
高斯分布的图像如下:
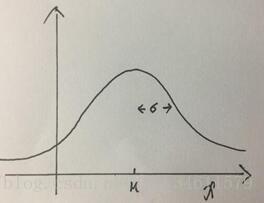
数学公式:
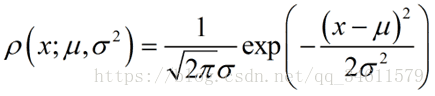
高斯分布的几个例子如下:

参数估计问题:给定数据集,希望能找到能够估算出![]() 和
和![]() 的值。
的值。
参数估计的公式:

高斯分布推导异常检测算法
这一节中将应用高斯分布来推导异常检测算法。
假设有数据集:![]() ,且
,且![]() ,要处理异常检测问题先是要用数据集建立概率建模
,要处理异常检测问题先是要用数据集建立概率建模![]() ,试图解决哪些特征量出现概率高,哪些特征量出现概率低。因此,x是个向量。要建立模型
,试图解决哪些特征量出现概率高,哪些特征量出现概率低。因此,x是个向量。要建立模型![]() 。
。
那么如何对这些项进行建模呢?
假定特征![]() 是分散的,它服从高斯分布
是分散的,它服从高斯分布![]() ,同样,也假设其他的特征服从高斯分布,那么得到模型:
,同样,也假设其他的特征服从高斯分布,那么得到模型:
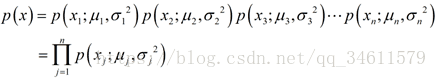
这个分布项![]() 的估计问题有时称作是密度估计问题。
的估计问题有时称作是密度估计问题。
下面是异常检测算法的步骤和实现:

这一节中讲述了如何估计![]() 的值,即x的概率值,使得构造出了一种异常检测算法。
的值,即x的概率值,使得构造出了一种异常检测算法。
开发和评估异常检测系统
这一节中将介绍如何开发一个异常检测的应用来解决实际问题,同时也将重点介绍如何评估一个异常检测算法。
到目前为止,都把异常检测看作是一个无监督学习问题,因为用的是无标签的数据,但如果有一个带标签的数据来指定哪些是异常样本和哪些是正常样本,这是能评估异常检测的标准方法。
为了评估一个异常检测系统,假设有一些带标签的数据,代表异常样本,同时还有一些无异常样本。(用y=0表示无异常样本,y=1表示异常样本)
异常检测算法的开发过程和评估方法:
(1)假设有训练集:![]() ,把它看作是无标签的,所以它是一个很大的无异常样本集合;
,把它看作是无标签的,所以它是一个很大的无异常样本集合;
(2)定义一个交叉验证集和测试集,用来评估这个异常检测算法。交叉验证集:![]() ,测试集:
,测试集:![]() ;
;
具体实例:
假设有10000个正常的汽车引擎,还有20个异常的汽车引擎,有了这组数据,要把数据分离到训练集、交叉验证集和测试集中,一种典型的方法如下:

有时候也会用如下的方式进行分离(不推荐):

得到了训练集、交叉验证集和测试集之后,接下来使如如何推导和评估算法:
(1)首先使用训练集拟合模型![]() ,即是把m个无标签样本都用高斯函数来拟合;
,即是把m个无标签样本都用高斯函数来拟合;
(2)然后在交叉验证集和测试集上,假设有一个样本x,用异常检测算法来预测出y的值;
(3)什么是好的评价指标?
▷ 计算True positive、false positive、false negative、true negative的比例
▷ 计算出算法的精确率和召回率
▷ 计算出F1-score,来总结和反映精确率和召回率
通过上述方法,就可以评价异常检测算法在样本集中的表现了。
(4)选择参数ε的方法:尝试使用不同的ε值,然后从中选出一个,该值能够最大化F1-score。

这一节中讨论了评估一个异常检测算法的步骤,开始用一些带标签的数据来评估异常检测算法,很像在监督学习中所做的。
异常检测VS监督学习
在这一节中将介绍一些思想和方法可以在使用异常检测算法时用到,并且在使用监督学习算法时,这些方法可能会更有效。
异常检测算法更有效:
▷ 它的正常例子数量更少,记住当y=1时这些例子为异常样例(0-20个正样本);
▷ 通常会有一个相比于正样本数量更大的负样本,可以用这数量庞大的负样本来拟合出![]() 的值。
的值。
所以如果只有负样本,仍然可以很好的拟合![]() 的值。
的值。
监督学习算法更有效:
▷ 在合理范围内有大量的正样本和负样本。
所以这是一种思考方式决定应该使用异常检测算法还是监督学习算法。
另一种经常考虑使用异常检测算法的方法:
对于异常检测应用来说,经常有许多不同类型的异常。因此,如果是这种情况,有很少数量的正样本,那么对一个算法就很难去从小数量的正样本中去学习异常是什么;尤其是,未来可能出现的异常看起来会与已有的截然不同,如果是这种情况,那么更有可能的是对负样本用高斯分布模型![]() 来建模。
来建模。
另一种经常考虑使用监督学习算法的方法:
在一些其他问题中,有足够数量的正样本或是一个已经能识别正样本的算法;尤其是,假如认为未来可能出现的正样本与当前训练集中的正样本类似,那么这种情况下,使用监督学习算法更合理,它能够查看大量正样本和大量负样本来学到相应特征。
所以决定应该使用异常检测算法还是监督学习算法,它们之间关键不同在于在异常检测中,通常只有很少量的正样本,对学习算法而言是不可能从这些正样本中学习到足够的内容。
下面是一些使用异常检测的应用和监督学习算法的应用:

所以从本节的学习中,就可以知道分别在什么时候使用异常检测算法还是时候监督学习算法。
选择要使用的功能
这一节中将会给出一些建议:如何设计或选择异常检测算法的特征。
如果数据不是符合高斯分布,但是数据画出来图像是像下图所示的这样:
该图看上去近似于高斯分布,所以如果特征是这样的话,那么也可以将数据输入算法中,但是如果画出来的数据像这样:

该图看上去不像高斯分布的图像,是一个不均匀的分布,遇到这样的数据,通常会对数据进行一些不同地转换,使得它看上去更接近高斯分布。比如会进行一次对数转换(![]() ),进行一次指数转换(
),进行一次指数转换(![]() )。
)。
如何得到异常检测算法的特征?通过一个误差分析步骤:
▷ 异常检测中,希望![]() 的值在正常样本的情况下比较大,在异常的情况下比较小;
的值在正常样本的情况下比较大,在异常的情况下比较小;
▷ 很常见的问题:![]() 是可比较的,当样本正常和异常时,
是可比较的,当样本正常和异常时,![]() 的值都比较大。
的值都比较大。
具体实例1:
假如有一个异常样本,并假设这异常样本x1的取值为2.5,如下图所示:

算法能把它标记为异常样本,如果这代表汽车引擎的生产或其他什么,那么我会做的是看看我的训练样本,看看到底是哪一个具体的汽车引擎出错了,看看通过这个样本能不能启发我想出新的特征x2来帮助算法找出异常的样本与正常样本的区别。
所以,希望能否创建一个新的特征下x2,使数据能够像下图中展示出来,当然,也希望能看到对于异常样本,特征x2能发现不寻常的值:

现在如果再给数据建模,会发现异常检测算法在中间区域的数据有较高的概率,然后越到外层概率越小,到了图中绿色样本时,算法会给出很低的概率,这就更容易将异常样本从正常的样本中区分出来了。
具体实例2:
假如有一个计算机集群的管理,如何判断哪一台计算机有异常?,假设计算机特征有:
x1:内存使用量 x2:磁盘的容量
x3:CPU的负载程度 x4:网络流量
此时,可以想出一个新的特征x5来帮助更好的检测异常,x5=CPU负载程度/网络流量,通过这种建立特征的方法,就可以捕捉到这些特殊的特征组合所出现的异常值。
这就是误差分析的过程以及如何为异常检测算法建立新的特征来检测不同的异常情况。
多变量高斯分布以及它在异常检测中的应用
这一节中将介绍目前为止学习的异常检测算法的一种延伸,这个延伸将会用到多元高斯分布。
多元高斯分布:假设有特征变量![]() ,不为
,不为![]() 分别建模,而要建立一个整体的
分别建模,而要建立一个整体的![]() 模型,就是为所有
模型,就是为所有![]() 建立统一模型。它参数是
建立统一模型。它参数是![]() 和
和![]() (Σ被称为协方差矩阵)。
(Σ被称为协方差矩阵)。
多元高斯分布的公式:
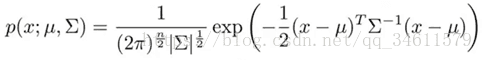
多元高斯分布的几个例子如下:


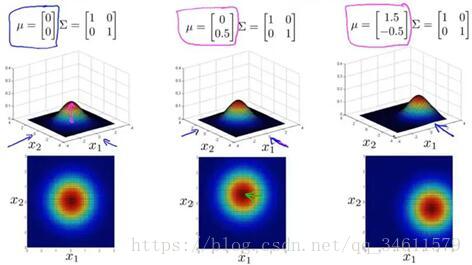
通过这些例子可以让我们对多元高斯分布所能描述的概率分布有更多的了解,它最大的优点就是能描述两个特征变量之间可能存在正相关或者负相关的情况。
接下来将多元高斯分布应用于不同的异常检测算法中去。
假如有一组样本:![]() ,并且它们是服从多元高斯分布的,那么应该如何去估计参数μ和Σ,参数估计的标准公式如下:
,并且它们是服从多元高斯分布的,那么应该如何去估计参数μ和Σ,参数估计的标准公式如下:

应用多元高斯分布的异常检测算法:
▷ 首先用数据来拟合该模型,通过设定的μ和Σ来拟合![]() ;
;
▷ 接着当有一个新样本x,也是测试样本,然后需要用多元高斯分布的公式计算![]() ,如果得到
,如果得到![]() 很小(
很小(![]() ),就标记该样本异常。
),就标记该样本异常。
多元高斯模型和原始模型的关系:
原始模型实际上就是某种特殊情况下的多元高斯分布,这种特殊的情形就是当协方差矩阵Σ在非对角线上都是0的时候,也就如下所示:
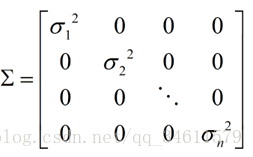
如果用这σ值,将它们放在协方差矩阵中,这时两个模型就会完全相同,所以这个原始意义上的模型只是多元高斯模型的一种特殊情况。
那么,如何在这两个模型之间进行选择呢?
原始模型要用的跟多一些;多元高斯模型用的想多少一些,但它在捕捉特征间的关系方面有着很多优点。
原始模型:
▷ 需要手动创建一些新特征来捕捉异常的组合值,因为比如x1和x2组合值出现异常的时候,可能x1和x2本身看起来都是很正常的值,如果花时间来手动创建这样一个新特征,原始模型就=才能运行的更好;
▷ 原始模型最大的优势在于它的计算成本比较低(换言之,它能适应巨大规模n);
▷ 即使有一个较小的有一定相关性的训练集,也能顺利运行,这是一个较小的无标签样本用来拟合模型![]() 。
。
多元高斯模型:
▷ 对于之下,多元高斯模型就能自动地捕捉这种不同特征之间的关系;
▷ 但是它的计算成本比较高(即:能适应的n值的范围比较小);
▷ 必须使训练样本数量m大于特征数量n,如果在参数估计时不能满足这个条件的话,协方差矩阵就会不可逆(1.m
这就是如何用多元高斯模型来进行异常检测,所以通过本章的学习,我们了解了异常检测这个算法,并且掌握了高斯模型在异常检测算法中的应用。