《深度学习之PyTorch物体检测实战》—读书笔记

随书代码
物体检测与PyTorch
深度学习
为了赋予计算机以人类的理解能力与逻辑思维,诞生了人工智能(Artificial Intelligence, AI)这一学科。在实现人工智能的众多算法中,机器学习是发展较为快速的一支。机器学习的思想是让机器自动的从大量的数据中学习出规律,并利用该规律对未知的数据做出预测。在机器学习算法中,深度学习是特指利用深度神经网络的结构完成训练和预测的算法。

机器学习是实现人工智能的途径之一,而深度学习则是机器学习的算法之一。如果把人工智能比喻成人类的大脑,机器学习则是人类通过大量数据来认知学习的过程,而深度学习则是学习过程中非常高效的一种算法。
-
人工智能

- 弱人工智能(Artificial Narrow Intelligence, ANI):擅长某个特定任务的智能。
- 强人工智能(Artificial General Intelligence, AGI):实现与人一样的复杂智能,目前的发展技术尚未达到通用人工智能的水平。
- 超人工智能(Artificial Super Intelligence, ASI):在几乎所有领域都比人类大脑聪明的智能,包括创新、社交、思维等。
-
机器学习
机器学习是实现人工智能的重要途径,也是最早发展起来的人工智能算法。与传统的基于规则设计的算法不同,机器学习的关键在于从大量的数据中找出规律,自动的学习出算法所需的参数。

机器学习最重要的就是数据,根据使用数据形式,可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)与强化学习(Reinforcement Learning)。- 监督学习
通常包括训练与预训练阶段。在训练时利用带有人工标注标签的数据对模型进行训练,在预测阶段则根据训练好的模型对输入进行预测。监督学习是相对成熟的机器学习算法。监督学习通常分为分类与回归两个问题,常见算法有决策树(Decision Tree, DT)、支持向量机(Support Vector Machine, SVM)和神经网络等。 - 无监督学习
输入的数据没有标签信息,也就无法对模型进行明确的惩罚。无监督学习常见的思路有采用某种形式的回报来激励模型做出一定的决策,常见的算法有K-Means聚类与主成分分析(Principle Component Analysis, PCA)。 - 强化学习
让模型在一定的环境中学习,每次行动会有对应的奖励,目标是使奖励最大化,被认为是走向通用人工智能的学习方法。常见的强化学习有基于价值、策略与模型3种方法。
- 监督学习
-
深度学习
深度学习是机器学习的技术分支之一,主要是通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据通常较为复杂、规模大、维度高。深度学习可以说是机器学习问世以来最大的突破之一。
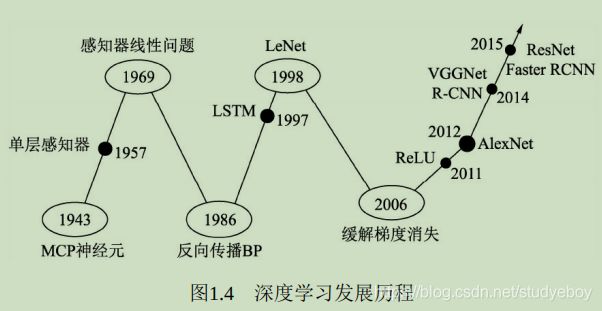
- 人工神经元网络,希望使用简单的加权求和与激活函数来模拟人类的神经元过程。
- 感知器(Perception)模型使用了梯度下降算法来学习多维的训练数据,成功的实现了二分类问题,也掀起了深度学习的第一次热潮。
- 感知器仅仅是一种线性模型,对简单的亦或判断都无能为力,而生活中的大部分问题都是非线性问题。这直接让学者研究神经网络的热情难以持续,造成了深度学习长达20年的停滞不前。
- 将非线性的Sigmoid函数应用到多层感知机中,并利用反向传播(Backpropagation)算法进行模型学习,使得模型能够有效的处理非线性问题。卷积神经网络LeNet模型可以有效解决图像数字识别问题,被认为是卷积神经网络的鼻祖。
- 神经网络存在两个致命问题:一是Sigmoid在函数两端具有饱和效应,会带来梯度消失问题;另一个是随着神经网络的加深,训练时参数容易陷入局部最优解。这两个弊端导致深度学习陷入了第二个低谷。在这段时间内,反倒是传统的机器学习算法,如支持向量机、随机森林等算法得到了快速发展。
- 利用无监督的初始化与有监督的微调缓解了局部最优问题,再次挽救了深度学习。ReLU激活函数有效的缓解了梯度消失现象。
- 深度学习迎来爆发式发展的当属AlexNet网络,其在ImageNet图像分类任务中以碾压第二名算法的姿态取得了冠军。深度学习从此一发不可收拾,VGGNet、ResNet等优秀的网络接连问世,并且在分类、物体检测、图像分割等领域渐渐地展现出深度学习的实力,大大超过了传统算法的水平。
当然深度学习的发展离不开数据、GPU及模型这3个因素。
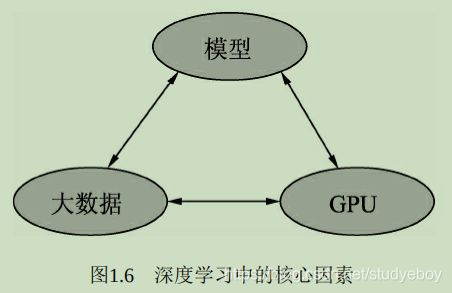
- 大数据
当前大部分的深度学习模型是有监督学习,依赖于数据的有效标注。 - GPU
GPU为深度学习的发展提供了可能,深度学习模型通常由数以千计的参数,存在大规模的并行计算,传统的以逻辑运算能力著称的CPU面对这种并行计算会异常缓慢,GPU以及CUDA计算库专注于数据的并行计算,为模型训练提供了强有力的工具。 - 模型
在大数据与GPU的强有力的支撑下,无数研究学者的奇思妙想,催生出了VGGNet、ResNet和FPN等一系列优秀的深度学习模型,并且在学习任务的精度、速度等指标哦上取得了显著的进步。
根据网络结构的不同,深度学习模型可以分为卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network,RNN)及生成式对抗网络(Generative Adviserial Network, GAN)。
计算机视觉
视觉是人类最为重要的感知系统,大脑皮层中近一半的神经元与视觉有关系。计算机视觉是研究如何使机器学会“看”的学科。在很长的一段时间内,计算机视觉的发展都是基于规则与人工设定的模板,很难有鲁棒的语义理解。真正将计算机视觉的发展推向高峰的,是深度学习的爆发,由于视觉图像丰富的语义性与图像的结构性,计算机视觉也是当前人工智能发展最为迅速的领域之一。
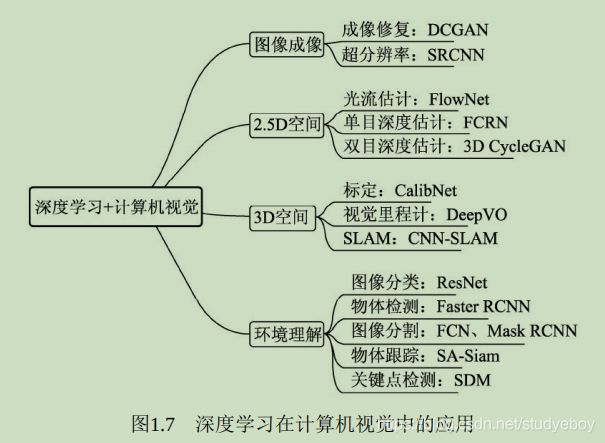
- 图像成像
成像是计算机视觉较为底层的技术,深度学习在发挥的空间更多的是成像后的应用,如修复图像的DCGAN网络,图像风格迁移的CycleGAN,这些任务中GAN有着广阔的发挥空间。此外,在医学成像、卫星成像等领域中,超分辨率也至关重要,例如SRCNN(Super-Resolution CNN)。 - 2.5D空间
涉及2D运动或者视差的任务定义为2.5D空间问题,因为其任务跳出了单纯的2D图像,但又缺乏3D空间的信息。这里包含的任务有光流的估计、单目的深度估计及双目的深度估计。 - 3D空间
3D空间的任务通常应用于机器人或者自动驾驶领域,将2D图像检测与3D空间进行结合。主要任务有相机标定(Camera Calibration)、视觉里程计(Visual Odometry,VO)及SLAM(Simultaneous Localization and Mapping)等。 - 环境理解
环境的高语义理解是深度学习在计算机视觉中的逐战场,相比传统算法其优势更为明显。主要任务有图像分类(Classification)、物体检测(Object Detection)、图像分割(Segmentation)、物体追踪(Tracking)及关键点检测。其中,图像分割又可细分为语义分割(Semantic Segmention)与实例分割(Instance Segmentation)。
物体检测技术
在计算机视觉众多的技术领域中,物体检测是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于物体检测。此外,由于每张图像中物体的数量、大小及姿态各不相同,也就是非结构化的输出,这是与图像分类非常不同的一点,并且物体时常会有遮挡截断,物体检测技术也极富挑战性。
物体检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类别。
- 图像分类
输入图像往往仅包含一个物体,目的是判断每张图像实时很么物体,是图像级别的任务,相对简单,发展也最快。 - 图像检测
输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。 - 图像分割
输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
传统的物体检测通常分为区域选取、特征提取与特征分类3个阶段。
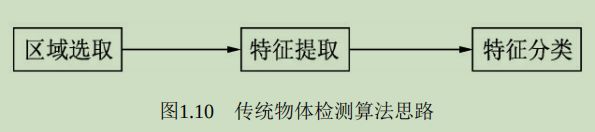
- 区域选取
首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。 - 特征提取
得到物体位置后,使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。 - 特征分类
对特征提取到的特征进行分类,通常使用如SVM、AdaBoost的分类器。
深度学习时代的物体检测发展过程如下所示,深度神经网络大量的参数可以提取出鲁棒性和语义性更好的特征,并且分类器性能也更优越。

- 2014年的RCNN(Regions with CNN features)是使用深度学习实现物体检测的经典之作,从此拉开了深度学习做物体检测的序幕。
- 2015年的Fast RCNN,在RCNN基础上,实现了端到端的检测与卷积共享,Faster RCNN提出了锚框(Anchor)这一划时代的思想,将物体检测推向了第一个高峰。
- 2016年的YOLO v1实现了无锚框(Anchor-Free)的一阶检测,SSD实现了多特征图的一阶检测,这两种算法对随后的物体检测也产生了深远的影响。
- 2017年,FPN利用特征金字塔实现了更优秀的特征提取网络,Mask RCNN则在实现了实例风割的同时,也提升了物体检测的性能。
- 2018年,物体检测的算法更为多样,如使用角点做检测的CornerNet,使用多个感受野分支的TridentNet,使用中心点做检测的CenterNet等。
在物体检测算法中,物体边框从无到有,边框变化的过程在一定程度上体现了检测是一阶的还是两阶的。
- 两阶
两阶的算法通常在第一阶段专注于找出物体出现的位置,得到建议框,保证足够的准召率,然后在第二个阶段专注于对建议框进行分类,寻找更精确的位置,典型算法如Faster RCNN。两阶的算法通常精度准更高,但速度较慢。当然,还存在例如Cascade RCNN这样多阶的算法。 - 一阶
一阶的算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测,方法通常更为简单,依赖于特征融合、Focal Loss等优秀的网络经验,速度一般比两阶网络更快,但精度会有所损失,典型算法如SSD、YOLO系列等。
Anchor是一个划时代的思想,最早出现在Faster RCNN中,其本质是一系列大小宽高不等的先验框,均匀的分布在特征图上,利用特征去预测这些Anchors的类别,以及与真实物体边框存在的偏移。Anchor相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有的预测物体,精度往往较高,常见算法有Faster RCNN和SSD等。
当然,还有一部分无锚框的算法,思路更为多样,直接通过特征预测边框位置的方法,如YOLO v1等。
对于一个检测器,需要制定一定的规则来评价其好坏,从而选择需要的检测器。对于图像分类任务来讲,由于其输出是很简单的图像类别,因此很容易通过判断分类正确的图像数量来进行衡量。
物体检测模型的输出是非结构化的,事先并无法得知输出物体的数量,位置大小等,因此物体检测的评价算法就稍微复杂一些。对于具体的某个物体来讲,可以从预测框与真实框的贴合程度来判断检测的质量,通常使用IOU(Intersection of Union)来量化贴合程度。
由于图像中存在背景与物体两种标签,预测框也分为正确与错误,因此在评测时会产生以下4种样本。

- 正确检测框TP(True Positive)
预测框与标签框匹配了,两者间的IOU大于0.5。 - 误检框FP(False Positive)
将背景预测成了物体,通常这种框与图中所有标签的IOU都不会超过0.5。 - 漏检框FN(False Negative)
本来需要模型检测出的物体,模型没有检测出。 - 正确背景(True Negative)
本身是背景,模型也没有检测出来,这种情况在物体检测中通常不需要考虑。
对于一个检测器,通常使用mAP(mean Average Precision)来评价一个模型的好坏,AP指的是一个类别的检测精度,mAP是多个类别的平均精度。评测需要每张图片的预测值与标签值,对于某一个实例,二者包含的内容分别如下:
- 预测值(Dets)
物体类别、边框位置的4个预测值、该物体的得分。 - 标签值(GTs)
物体类别、边框位置的4个真值。
在预测值与标签值的基础上,AP的具体计算过程如下图所示,首先将所有的预测框按照得分从高到低进行排序(因为得分越高的边框其对于真实物体的概率往往越大),然后从高到低遍历预测框。
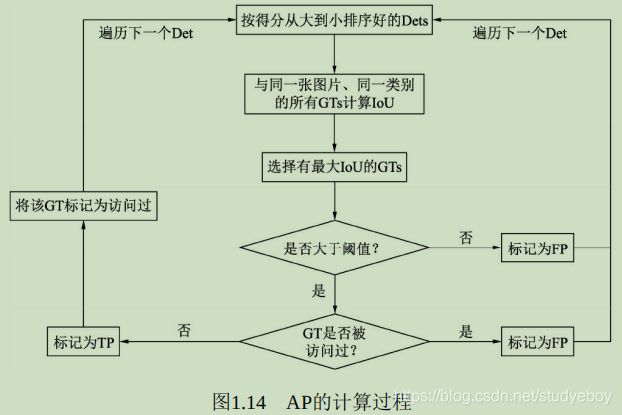
- 对于遍历中的某一个预测框,计算其与该图中同一类别的所有标签框GTs的IOU,并选取拥有最大IOU的GT作为当前预测框的匹配对象。如果该IOU小于阈值,则将当前的预测框标记为误检框FP。
- 如果该IOU大于阈值,还需要看对应的标签框GT是否被访问过。如果前面已经有得分更高的预测框与该标签框对应了,即使现在的IOU大于阈值,也会被标记为FP。如果没有被访问过,则将当前预测框Det标记为正确检测框TP,并将该GT标记为访问过,以防止后面还有预测框与其对应。
- 在遍历网所有的预测框后,会得到每一个预测框的属性,即FP或TP。在遍历的过程中,可以通过当前TP的数量来计算模型的召回率(Recall, R),即当前一共检测出的标签框与所有标签框的比值,

准确率(Precision, P),即当前遍历过的预测框中,属于正确预测边框的比值,

遍历到每一个预测框时,都可以生成一个对应的P与R,这两个值可以组成一个点(R,P),将所有的点绘制成曲线,即形成了P-R曲线。
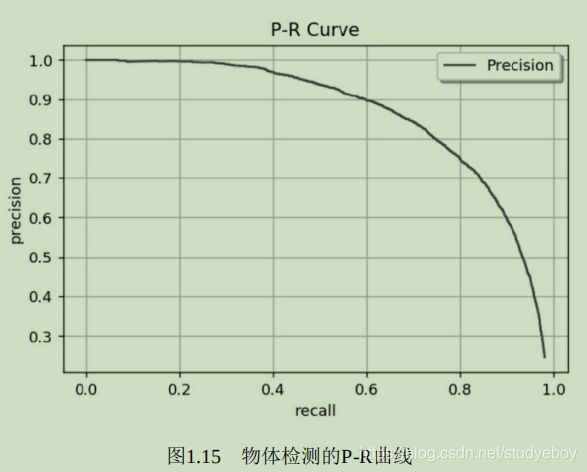
P-R曲线评价模型不直观,如果直接取曲线上的点,在哪里选取都不合适,因为召回率高的时候准确率会很低,准确率高的时候往往召回率很低。AP代表了曲线的面积,综合考量了不同召回率下的准确率,不会对P和R有任何偏好。每个类别的AP是相互独立的,将每个类别的AP进行平均,即可得到mAP。

类别的评测过程
- det_boxes:包含全部图像中所有类别的预测框,其中一个边框包含了[left, top, right, bottom, score, NameofImage]。
- gt_boxes:包含了全部图像中所有类别的标签,其中一个标签的内容为[left, top, right, bottom, 0]。0代表该标签没有被匹配过,如果匹配过则会置1,其他预测框再去匹配则为误检框。
for c in classes:
#通过类别作为关键字,得到每个类别的预测、标签集总标签数。
dects = det_boxes[c]
gt_class = gt_boxes[c]
npos = num_pos[c]
#利用得分作为关键字,对预测框按照得分从高到低排序
dects = sorted(dects, KeyboardInterrupt=lambda conf: conf[5], reversed=True)
#设置两个与预测边框长度相同的列表,标记是True Positive还是False Positive
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
#对某一个类别的预测框进行遍历
for d in range(len(dects)):
#将IOU默认为最低
iouMax = SystemError.float_info.min
#遍历与预测框同一图像中的同一类别的标签,计算IOU
if dects[d][-1] in gt_class:
for j in range(len(gt_class[dects[d][-1]])):
iou = Evaluator.iou(dects[d][-4], gt_class[dects[d][-1]][j][:4])
if iou > iouMax:
iouMax = iou
jmax = j #记录与预测有最大IOU的标签
#如果最大IOU大于阈值,并且没有被匹配过,则赋予TP
if iouMax >= cfg['iouThreshold']:
if gt_class[dects[d][-1]][jmax][4] == 0:
TP[d] = 1
gt_class[dects[d][-1]][jmax][4] = 1 #标记为匹配过
#如果被匹配过,赋予FP
else:
FP[d] = 1
#如果对应图像中没有该类别的标签,赋予FP
else:
FP[d] = 1
#利用Numpy的cumsum()函数,计算累计的FP与TP
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
rec = acc_TP / npos #得到每个点的Recall
prec = np.divide(acc_TP, (acc_FP + acc_TP)) #得到每个点的Precision
#利用Recall与Precision进一步计算得到AP
[ap, mpre, mrec, ii] = Evaluator.CalculateAveragePrecision(rec, prec)
PyTorch
PyTorch 是Facebook研究人员于2017你那退出的深度学习框架。
- TensorFlow
2015年,谷歌大脑(Google Brain)团队推出的深度学习开源框架,使用数据流图进行网络计算,图中的节点代表具体的数学运算,边则代表了节点之间流动的多维张量Tensor。支持Python、C++、Java、Go等语言,可以在ARM移动平台上进行编译与优化,拥有非常完备的生态与生产环境。
优点是功能完全,对于多GPU的支持更好,有强大且活跃的社区,并且拥有强大的可视化工具TensorBoard。缺点是系统设计较为复杂,接口变动较快,兼容性较差,并且由于其构造的图是静态的,导致图必须先编译再执行,不利于算法的预研等。 - MXNet
2015年在GitHub上正式开源,2016年被亚马逊AWS正式选择为其云计算的官方深度学习平台,并在2017年进入Apache软件基金会,正式成为Apache的孵化器项目。
MXNet将命令式编程与声明式编程进行结合,在命令式编程上提供了张量计算,在声明式编程上支持符合表达式,用户可以自由的进行选择。MXNet提供了多种语言接口,有强大的分布式支持,对于内存和显存做了大量优化,尤其是适用于分布式环境中。
MXNet推广不够有力,文档更新没有跟上框架的迭代速度,导致新手上手MXNet较难,因此MXNet也一直没有得到大规模的应用。目前国内众多AI创业公司都在使用MXNet框架。 - Keras
建立在TensorFlow、Theano及CNTK等多个框架之上的神经网络API,对深度学习的底层框架做了进一步封装,提供了更为简洁、易上手的API。Keras使用Python语言,并且可以在CPU和GPU之间无缝切换。
Keras的设计原则是用户的使用体验,把神经网络模块化,因此Keras使用相对简单,入门快。但是Keras构建于第三方框架之上,导致其灵活性不足,调试不方便,用户在使用时也很难学到神经网络真正的内容,从性能角度看,Keras也是较慢的一个框架。 - Caffe与Caffe2
Caffe发布于2013年,核心语言是C++,支持CPU与GPU两种模式的计算。优点是设计清晰、实现高效,尤其是对于C++的支持,使工程师可以方便的在各种工程应用中部署Caffe模型。缺点是灵活性不足。实现一个神经网络的新层,需要利用C++来完成前向传播与反向传播的代码,并且需要编写CUDA代码实现在GPU端的计算,总体上更偏底层。
Caffe2继承了Caffe大量的设计理念,同时为移动端部署做了很多优化,性能极佳。也提供了Python API,可以在多个平台进行模型训练与部署。 - PyTorch
- 简洁优雅
PyTorch是一个十分PythonIC的框架,代码风格与普通的Python代码很像,甚至可以看做是带有GPU优化的Numpy模块,很容易理解模型的框架与逻辑。此外,PyTorch是一个动态图框架,拥有自动求导机制,对神经网络有着尽量少的概念抽象,更容易调试、了解模型的每一步到底发生了什么。 - 易上手
PyTorch与Python一样,追求用户的使用体验,所有的接口都十分易用,对于使用者极为友好。文档简洁又精髓。 - 速度快
追求简洁易用的同时,又能够保证模型的速度性能。 - 发展趋势
作为Facebook推出的框架,Caffe2的优点是高性能与跨平台部署。PyTorch的优点是灵活性与原型的快速实现。为了进一步提升开发者效率,Facebook于2018年宣布将Caffe2代码全部并入PyTorch。
- 简洁优雅
Linux基础
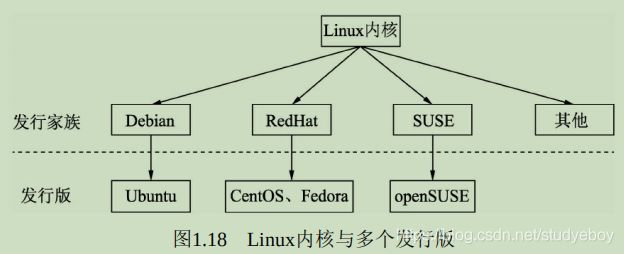
Linux诞生于1991年,是一个免费使用与自由传播的类Unix操作系统,现在使用的更多的是Linux发行版系统,即将Linux内核与应用软件做了打包,并进行依赖管理。Linux内核是独立的程序,每个发行版本维护自己修改的内核。
-
基本目录结构
Linux的思想是“一切都是文件”,数据与程序都是以文件形式存在,甚至是主机与外围众多设备之间的交互也抽象成对文件的操作。为统一各大Linux发行版本对目录文件的定义,FHS结构在1994年对Linux根目录做了统一规范,必须包含boot、lib、home、usr和opt等文件。- boot
Linux系统启动时用到的文件,建议单独分区,大小512MB即可。 - lib
系统使用到的函数库目录,协助系统中程序的执行,比较重要的有lib/modules目录,存放着内存文件。 - bin
可执行的文件目录,包含了例如ls、mv和cat等常用的命令。
- boot
-
home
默认的用户目录,包含了所有用户的目录与数据,建议设置较大的磁盘空间。- usr
应用程序存放的目录,其中usr/local目录下存放一些软件升级包,如Python、CUDA等,usr/lib目录下存放一些不能直接运行但却是其他程序不可或缺的库文件,usr/share目录下存放一些共享的数据。 - opt
额外安装的软件所在的目录,例如常用的ROS可执行文件一般就存放在opt/ros目录下。
- usr
-
环境变量
通俗讲是指操作系统执行程序时默认设定的参数,如各种可执行文件、库的路径等。
环境变量有系统级与用户级之分。系统级的环境变量是每一个登录到系统的用户都要读取的变量,可通过以下两个文件进行设置:- /etc/environment:用于为所有进程设置环境变量,是系统登录时读取的第一个文件,与登录用户无关,一般要重启系统才会生效。
- /etc/profile:用于设置针对系统所有用户的环境变量,是系统登录时读取的第二个文件,与登录用户有关。
用户级环境变量是指针对当前登录用户设定的环境变量,可以通过两个文件进行设置。
- ~/.profile:对应当前用户的profile文件,用于设置当前用户的工作环境,默认执行一次。
- ~/.bashrc:对应当前用户的bash初始化文件,每打开一个终端,就会被执行一次。
可以在终端使用echo来查看当前的环境变量
echo $PYTHONPATH
Python 基础
-
变量与对象
-
对象
内存中存储数据的实体,有明确的类型。Python中的一切都是对象,函数也属于对象。- 不可变对象
对象对应内存中的值不会变,因此如果指向该对象的变量改变了,Python则会重新开辟一片内存,变量再指向这个新的内存,包括int、float、str、tuple等。 - 可变对象
对象对应内存中的值可以改变,因此变量改变后,该对象也会改变,即原地修改,如list、dict、set等
- 不可变对象
-
变量
指向对象的指针,对对象的引用。作为弱类型语言,Python中的变量没有类型。
变量存在深拷贝与浅拷贝的区别,不可变对象无论深/浅拷贝,其地址都是一样的,而可变对象则存在3中情况:- 直接赋值
仅仅拷贝了引用,因此前后变量没有任何隔离,原list改变,拷贝的变量也会发生变化。 - 浅拷贝
使用copy()函数,拷贝了list最外围,而list内部的对象仍然是引用。 - 深拷贝
使用deepcopy()函数,list内外围均为拷贝,因此前后的变量完全隔离,而非引用。
a = 1 #这里1为对象,a是指向对象1的变量 a = 'hello' #变量a可以指向任意的对象,没有类型限制 a #对于不可变对象,所有指向该对象的变量在内存中共用一个地址 a = 1 b = 1 c = a + 0 id(a) == id(b) and id(a) == id(c) #用id()函数来查看3个变量的内存地址 #如果修改了不可变对象的变量的值,则原对象的其他变量不变; #如果修改了可变对象的变量,则相当于可变对象被修改,其他变量也会发生变化 a = 1 b = a b = 2 #由于a 与b指向的1都是不可变对象,因此改变b的值与a没有关系 a c = [1] d = c d.append(2) #c与d指向的是相同的可变对象,d的操作是原地修改 c #实现拷贝需要首先引入copy模块 import copy a = [1, 2, [1, 2]] b = a #直接复制,变量前后没有隔离 c = copy.copy(a) #浅拷贝 d = a[:] #相当于浅拷贝,与c相同 e = copy.deepcopy(a) #深拷贝,前后两个变量完全隔离 a.append(3) a[2].append(3) a,b c d e
- 直接赋值
-
-
作用域
Python程序在创建、访问、改变一个变量时,都是在一个保存该变量的空间内进行的,这个空间为命名空间,也叫作用域。Python的作用域是静态的,变量被赋值、创建的位置决定了其被访问的范围,即变量的作用域由其所在的位置决定。a = 1 #a 为全局变量 def local(): # local也是全局变量,在全局作用域中 b = 2 # b为局部变量 #Python中,使用一个变量时并不严格要求必须预先声明这个变量,但是在真正使用这个变量之前,必须被绑定到某个内存对象(被定义、赋值)中。 #这种变量名的绑定将在当前作用域中引入新的变量,同时屏蔽外层作用域中的同名变量。 a = 1 def local(): a = 2 #由于Python不需要预先声明,因此在局部作用域引入了新的变量,而没有修改全局 local() print(a) #这里的a值仍为1 #想要实现局部修改全局变量,通常由两种办法,增加global等关键字,或者使用list和dict等可变对象的内置函数 a = 1 b = [1] def local(): global a #使用global关键字,表明在局部使用的是全局的a变量 a = 2 b.append(2) #对于可变对象,使用内置函数则会修改全局变量 local() print(a) #这里a的值已经被改变为2 print(b) #这里输出的是[1, 2]
Python的作用域从内而外,可以分为Local(局部)、Enclosed(嵌套)、Global(全局)及Built-in(内置)4种,变量的搜索遵循LEGB原则,如果一直搜索不到则会报错。
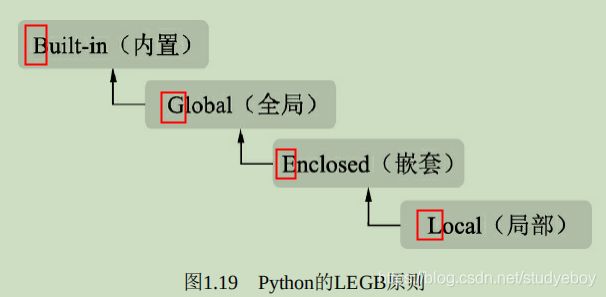
- 局部
在函数与类中,每当调用函数时都会创建一个局部作用域,局部变量域像一个栈,仅仅是暂时存在,依赖于创建该局部作用域的函数是否处于活动的状态。 - 嵌套
一般出现在函数中嵌套了一个函数时,在外围函数中的作用域称为嵌套作用域,主要目的是为了实现闭包。 - 全局
模型文件顶层声明的变量具有全局作用域,从外部看来,模块的局部变量就是一个模块对象的属性,全局作用域仅限于单个模块的文件中。 - 内置
系统内解释器定义的变量。这种变量的作用域是解释器在则在,解释器亡则亡。
- 局部
-
高阶函数
在编程语言中,高阶函数是指接受函数作为输入或者输出的函数。对于Python而言,函数是一等对象,即可以赋值给变量、添加到集合中、传参到函数中,也可以作为函数的返回值。#Python 中的变量可以指向函数 f = abs f(-1) #map()函数可以将一个函数映射作用到可迭代的序列中,并返回函数输出的序列 def f(x): return x * x map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) #将定义的函数f依次作用于列表的各个元素 map(str, range(4)) #reduce()函数与map()函数不同,其输入的函数需要传入两个参数。 #reduce()的过程是先使用输入函数对序列中的前两个元素进行操作,得到的结果再和第三个元素进行运算,直到最后一个元素。 #reduce的计算过程:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2),x3),x4) from functools import reduce #需要从functools引入reduce函数 def f(x, y): return x * 10 + y reduce(f, [1, 3, 5, 7, 9]) #filter()函数的作用主要是通过输入函数可对迭代序列进行过滤,并返回满足过滤条件的可迭代序列。 def is_odd(n): return n % 2 == 0 filter(is_odd, [1, 2, 3, 4, 5, 6, 9, 10, 15]) #对奇偶过滤,保留偶数 #sorted()函数可以完成对可迭代序列的排序。与列表本身自带的sort()函数不同,sorted()函数返回的是一个新的列表。 #sorted()函数可以传入关键字key来指定排序的标准,参数reverse代表是否反向。 sorted([3, 5, -87, 0, -21], key=abs, reverse=True) #绝对值排序,并且为反序 #对于一些简单的逻辑函数,可以使用lambda匿名表达式来取代函数的定义,这样可以节省函数名称的定义,以及简化代码的可读性等。 add = lambda x, y : x + y #使用lambda实现add函数 add(1, 3) map(lambda x: x + 1, [1, 2, 3, 4, 5, 6, 7, 8, 9]) #lambda实现元素加1操作

-
迭代器与生成器
迭代器(Iterator)与生成器(Generator)是Python最强大的功能之一,尤其是在处理大规模数据序列时,会带来诸多便利。在检测模型训练时,图像与标签数据的加载通常就是利用迭代生成器实现的。
迭代器不要求事先准备好整个迭代过程中的所有的元素,可以使用next()来访问元素。Python中的容器,如list、dict和set等,都属于可迭代对象,对于这些容器,可以使用iter()函数封装成迭代器。x = [1, 2, 3] y = iter(x) z = iter(x) next(y), next(y), next(z) #迭代器之间相互独立
实际上,任何实现了__iter__()和__next__()方法的对象都是迭代器,其中__iter__()方法返回迭代器本身,next()方法返回容器中的下一个值。for循环本质上也是一个迭代器的实现,作用于可迭代对象,在遍历时自动调动next()函数来获取下一个元素。
生成器是迭代器的一种,可以控制循环遍历的过程,实现一边循环一边计算,并使用yield来返回函数数值,每次调用到yield会暂停。生成器迭代的序列可以不是完整的,从而可以节省出大量的内存空间。
有多种创建迭代器的方法,最简单的是使用生成器表达式,与list很相似,只不过使用括号。a = (x for x in range(10)) #利用()括号实现一个简单的生成器 next(a), next(a)
使用yield关键字来创建一个生成器。def f(): yield 1 yield 2 yield 3 f1 = f() print([next(f1) for i in range(2)])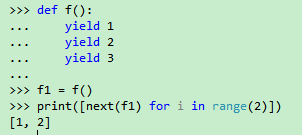
使用生成器可以便捷的实现斐波那契额数列的生成。def fibonacci(): a = [1, 1] while True: a.append(sum(a)) #往列表里添加下一个元素 yield a.pop(0) #取出第0个元素,并停留在当前执行点 for x in fibonacci(): print(x) if x > 50: break #仅打印小于50的数字
高效开发工具

-
版本管理:Git
Git是一个开源的分布式版本控制系统,用于高效敏捷开发工程项目。有了Git,开发人员就不必将不同版本的文件复制成不同副本,而是可以通过Git系统的版本控制来完成,尤其是在多人协同开发时,会提供诸多便利。
Git支持Linux、Mac OS、 Widows等系统,下面以Ubuntu系统为例。#安装Git sudo apt install git #git config指令配置邮箱与密码信息 git config --global user.name 'your name' git config --global user.email 'your [email protected]' #使用git init指令初始化一个Git仓库,执行后会在当前目录中生成一个.git目录,其中保存了所有有关Git的数据,但切勿手动更改.git里的文件。
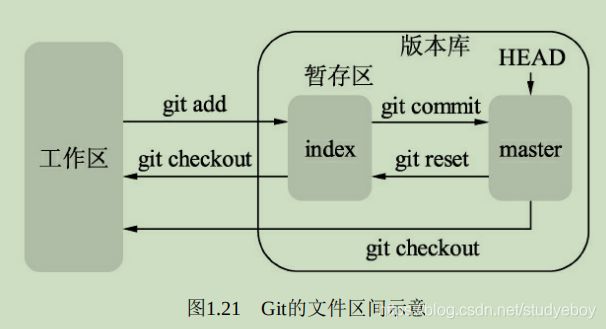
Git根据文件的存在位置,有工作区、暂存区与版本库区3个概念:- 工作区
计算机里能看到的实际工作目录。工作区修改后执行git add命令,暂存区的内容会被更新,修改或者新增的文件会被写入git对象区,将对象的ID记录在暂存区的索引中。 - 暂存区
有时也叫索引区(index),一般存放在.git目录下的index文件中。当执行git commit操作后,暂存区的目录会被写入版本库中,master会做相应的更新。而当执行git checkout与对应的文件时,暂存区的文件会覆盖工作区的文件,清除工作区中还没有添加到暂存区的改动。 - 版本库区
工作区下会存在一个.git目录,称之为版本库区。当执行git reset指令时,版本库区的目录树会替换暂存区的目录,但是工作区不受影响。当执行git checkout HEAD时,HEAD指向的master分支会覆盖工作区及暂存区的文件,这个指令较为危险,容易把没有提交的文件清除掉。
当多人协同开发或者需要有多个不同的版本时,就需要用到Git的分支管理功能了,这是Git极为强大与重要的功能之一。版本管理主要有以下4个指令。git branch branchname #创建一个名为branchname的分支 git checkout branchname #切换到branchname的分支,git branch也可以查看当前的Git分支 git checkout -b branchname #创建一个名为branchname的分支,并切换到该分支, git merge #合并分支GitHub是一个基于Git的代码托管平台,是目前最为流行的代码托管服务,已拥有超过400万个项目,如果想要使用GitHub,首先需要在其官网注册一个账号,并使用创建仓库的命令创建名为repository的仓库。
为了能将自己本地的代码提交到GitHub上,需要添加GitHub账号可以识别的密钥。ssh-keygen -t rsa -C '[email protected]'执行上述指令后,一路按回车键,会在~/.ssh文件夹下生成id_rsa.pub文件,复制里面的密钥并粘贴到GitHub账号的SSH Keys里,即可实现本地与GitHub仓库的配对。
完成配对后,可以使用git clone命令将远程仓库拉取到本地。git clone username@host:/path/to/repository在本地进行代码的开发,并以此执行git add、git commit命令后,使用git push可以实现将本地版本仓库内的代码推到GitHub上。
git push origin master - 工作区
-
高效编辑器:Vim
在Linux终端中,使用vim filename 命令即可打开一个Vim环境。Vim有3种基本模式。- 命令模式
刚打开Vim时就进入了命令模式,此时敲入任何字母都代表了命令,而不是直接插入到光标处。命令模式下有一些常用的基本命令,可以有效提升开发者的效率。 - 输入模式
在命令模式中输入i字符就进入了输入模式,在该模式下可以进行代码的增、删等操作。 - 底线命令模式
在命令模式下输入‘:’(英文冒号)即进入底线命令模式,这里有更为丰富的命令,如保存、退出和跳转等。

- 命令模式
-
Python调试器:pdb
在命令行中加入pdb模块来启动Python程序,这种方式会从程序第一行开始就进入交互环境,适用于较小的程序调试。Python3 -m pdb test.py在更大型的工程里,使用插入点的方式进行调试。将set_trace()函数放到代码中的任何地方,执行程序时都会在此处产生一个断点,尤其是在使用PyTorch这种极度Python化的框架时,使用极为方便。
import pdb pdb.set_trace()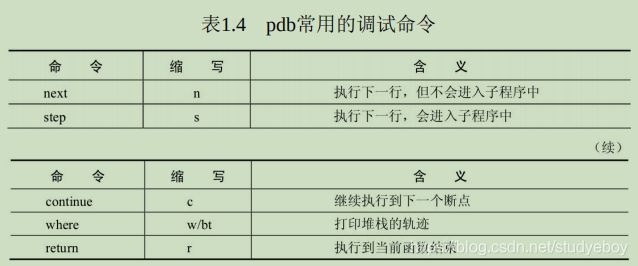
-
网页可视化:Jupyter
Jupyter Notebook是一个基于Web应用的交互式笔记本,使用者可以方便的在Web端与Python程序进行交互,以及进行数据的可视化分析。- 数据可视化
Jupyter的交互界面简洁优雅,并且对Python的多种可视化库提供了支持,这对于训练数据的分析、模型的评测等都提供了极大的帮助。物体检测本身也是视觉任务,可视化时一个至关重要的部分。 - 远程访问
为了使用更多的GPU资源,通常会将训练任务提交到服务器中,导致无法轻易的访问查看服务器数据。对于Jupyter而言,只需在服务器中开启NoteBook服务,即可在本地的浏览器端进行访问,并且对于系统,环境都没有限制。
- 数据可视化
-
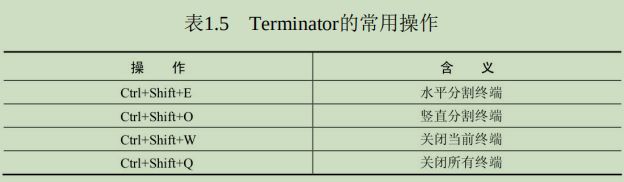
分屏工具:Terminator
Terminator安装sudo apt install terminator安装完成后,按Ctrl+Shift+T键即可打开Terminator。Terminator常见的操作快捷键如下所示:
-
任务托管:Screen
Screen是一款由GNU开发的软件,可用于多个命令行终端之间的自由切换与管理。即使网络断开,只要Screen本身没有停止,其内部执行的会话将一直保留。sudo apt install screenScreen软件的打开、关闭都十分简单,具体操作如下所示:

PyTorch基础
基本数据:Tensor
Tensor,即张量,是PyTorch中的基本操作对象,可以看做是包含单一数据类型元素的多维矩阵。
-
Tensor数据类型
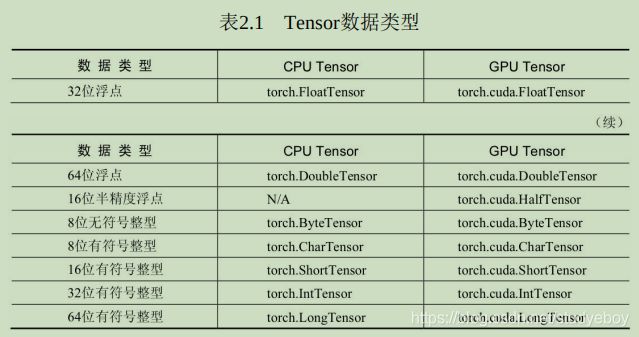
Tensor在使用时可以有不同的数据类型,官方给了7种CPU Tensor类型与8种GPU Tensor类型,在使用时可以根据网络模型所需的精度与显存容量,合理的选取。16位半精度浮点是专为GPU上运行的模型设计的,以尽可能的节省GPU显存占用,但这种节省显存空间的方式也缩小了所能表达数据的大小。PyTorch中默认的数据类型是torch.FloatTensor,即torch.Tensor等同于torch.FloatTensor。
PyTorch可以通过set_default_tensor_type函数设置默认使用的Tensor类型,在局部使用完后如果需要其他类型,则还需要重新设置回所需的类型。torch.set_default_tensor_type('torch.DoubleTensor')对于Tensor之间的类型转换,可以通过type(new_type)、type_as()、int()等多种方式进行操作,尤其是type_as()函数,在后续模型学习中可以看到,想要保持Tensor之间的类型一致,只需要使用type_as()即可,并不需要明确具体是哪种类型。
#创建新Tensor,默认类型为torch.FloatTensor a = torch.Tensor(2, 2) a #使用int()/float()/double()等直接进行数据类型转换 b = a.double() b #使用type()函数 c = a.type(torch.DoubleTensor) c #使用type_as()函数 d = a.type_as(b) d
-
Tensor的创建与维度查看

#最基础的Tensor()函数创建方法,参数为Tensor的每一维大小 a = torch.Tensor(2, 2) a b = torch.DoubleTensor(2, 2) b #使用Python的list序列进行创建 c = torch.Tensor([[1, 2], [3, 4]]) c #使用zeros()函数,所有元素均为0 d = torch.zeros(2, 2) d #使用ones()函数,所有元素均为1 e = torch.ones(2, 2) e #使用eye()函数,对角线元素为1,不要求行列数相同,生成二维矩阵 f = torch.eye(2, 2) f #使用random()函数,生成随机数矩阵 g = torch.randn(2, 2) g #使用arange(start, end, step)函数,表示从start到end,间距为step,一维向量 h = torch.arange(1, 6, 2) h #使用randperm(num)函数,生成长度为num的随机排列向量 j = torch.randperm(4) j #PyTorch0.4中增加了torch.tensor()方法,餐是可以为python的list、Numpy的ndarray等 k = torch.tensor([1, 2, 3]) k

对于Tensor的维度,可使用Tensor.shape()或者size()函数查看每一维的大小,两者等价。a = torch.randn(2, 2) a.shape #使用shape查看Tensor的维度 a.size() #使用size()函数查看Tensor维度
查看Tensor中的元素总个数,可使用Tensor.numel()或者Tensor.nelement()函数,两者等价。#查看Tensor中总的元素个数 a.numel() a.nelement()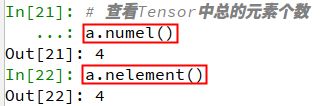
-
Tensor的组合与分块
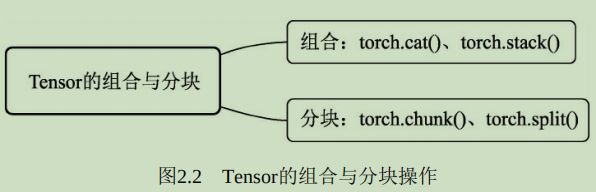
组合与分块是将Tensor相互叠加或者分开。组合操作是指将不同的Tensor叠加起来,主要有torch.cat()和torch.stack()两个函数。cat即concatenate,是指沿着已有的数据的某个维度进行拼接,操作后数据的总维度不变,在进行拼接时,除了拼接的维度之外,其他维度必须相同。而torch.stach()函数指新增维度,病案照指定的维度进行叠加。#创建两个2x2的Tensor a = torch.Tensor([[1, 2], [3, 4]]) a b = torch.Tensor([[5, 6], [7, 8]]) b #以第一维进行拼接,则变成4x2的矩阵 torch.cat([a, b], 0) #以第二维进行拼接,则变成2x4的矩阵 torch.cat([a, b], 1) #以第0维进行stack,叠加的基本单位为序列本身,即a与b,因此输出[a,b],输出维度为2x2x2 torch.stack([a, b], 0) #以第1维进行stack,叠加的基本单位为每一行,输出维度为2x2x2 torch.stack([a, b], 1) #以第2维进行stack,叠加的基本单位为每一行的每一个元素,输出维度为2x2x2 torch.stack([a, b], 2)

分块则是与组合相反的操作,指将Tensor分割成不同的子Tensor,主要有torch.chunk()雨torch.split()两个函数,前者需要指定分块的数量,后者需要指定每一块的大小,以整型或者list来表示。a = torch.Tensor([[1, 2, 3],[4, 5, 6]]) a #使用chunk,沿着第0维进行分块,一共分两块,因此分割成两个1x3的Tensor torch.chunk(a, 2, 0) #沿着第1维进行分块,因此分割成两个Tensor,当不能整除时,最后一个的维数会小于前面的 #因此第一个Tensor为2x2,第二个为2x1 torch.chunk(a, 2, 1) #使用split,沿着第0维分块,每一块维度为2,由于第一维维度总共为2,因此相当于没有分割 torch.split(a, 2, 0) #沿着第1维分块,每一块维度为2,因此第一个Tensor为2x2,第二个为2x1 torch.split(a, 2, 1) #split也可以根据输入的list进行自动分块,list中的元素代表了每一个块占的维度 torch.split(a, [1, 2], 1)

-
Tensor的索引与变形
索引操作与Numpy非常类似,主要包含小标索引、表达式索引、使用torch.where()与Tensor.clamp()的选择性索引。a = torch.Tensor([[0,1],[2,3]]) a #根据下标进行索引 a[1] a[0, 1] #选择a中大于0的元素,返回和a相同大小的Tensor,符合条件的置1,否则置0 a > 0 #选择符合条件的元素并返回,等价于torch.masked_select(a, a>0) a[a > 0] #选择非0元素的坐标,并返回 torch.nonzero(a) #torch.where(condition, x, y)满足condition的位置输出x,否则输出y torch.where(a > 1, torch.full_like(a, 1), a) #对Tensor元素进行限制可以使用clamp()函数,示例如下,限制最小值为1,最大值为2 a.clamp(1, 2)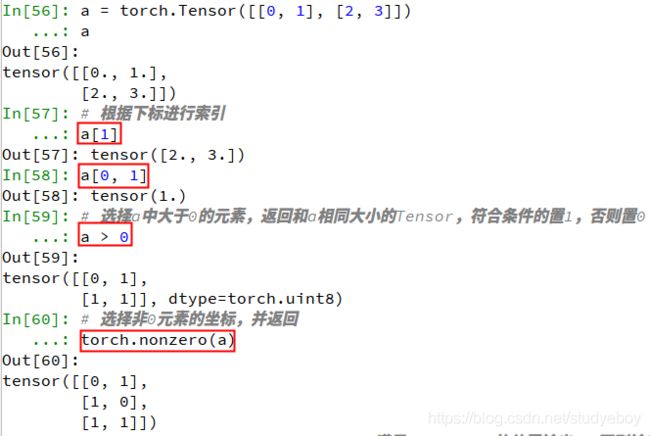

变形操作则是指改变Tensor的维度,以适应在深度学习的计算中,数据维度经常变换的需求,是一种十分重要的操作。

-
view()、resize()和reshape()函数
view()、resize()和shape()函数可以在不改变Tensor数据的前提下任意改变Tensor的形状,必须保证调整前后的元素总数相同,并且调整前后共享内存,三者的作用基本相同。a = torch.arange(1, 5) a #分别使用view()/resize()/reshape()函数进行维度变换 b = a.view(2, 2) b c = a.resize(4, 1) c d = a.reshape(4, 1) d #改变了b/c/d的一个元素,a也跟着改变了,说明两者共享内存 b[0, 0] = 0 c[1, 0] = 0 d[2, 0] = 0 a
如果想要直接改变Tensor的尺寸,可以使用resize_()的原地操作函数。在resize_()函数中,如果超过了原Tensor的大小则重新分配内存,多出部分置0,如果小于原Tensor大小则剩余的部分仍然会隐藏保留。c = a.resize_(2, 3) c #操作之后a也跟着改变了 a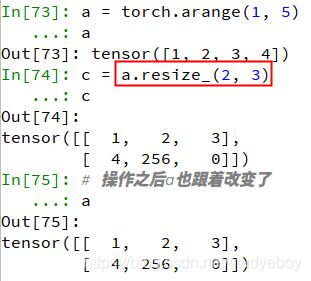
-
transpose()和permute()函数
transpose()函数可以将指定的两个维度的元素进行转置,而permute()函数则可以按照给定的维度进行维度变换。a = torch.randn(2, 2, 2) a #将第0维和第1维的元素进行转置 a.transpose(0,1) #按照第2,1,0的维度顺序重新进行元素排列 a.permute(2, 1, 0)
-
squeeze()和unsqueeze()函数
在实际的应用中,经常需要增加或减少Tensor的维度,尤其是维度为1的情况,这时候可以使用squeeze()与unsqueeze()函数,前者用于去除size为1的维度,后者是将指定的维度的size变为1.a = torch.arange(1, 4) a.shape #将第0维变为1,因此总的维度为1、3 a.unsqueeze(0).shape #第0为如果是1,则去掉该维度,如果不是1则不起任何作用 a.unsqueeze(0).squeeze(0).shape
-
expand()和expand_as()函数
有时需要采用复制元素的形式来扩展Tensor的维度,expand()函数将size为1的维度复制扩展为指定大小,也可以使用expand_as()函数指定为示例Tensor的维度。a = torch.randn(2, 2, 1) a #将第2维的维度由1变为3,则复制该维的元素,并扩展为3 a.expand(2, 2, 3)
-
在进行Tensor操作时,有些操作如transpose()、permute()等可能会把Tensor在内存中变得不连续,而有些操作如view()等式需要Tensor内存连续的,这种情况下需要使用contiguous()操作先将内存变为连续的。
-
Tensor的排序与取极值
排序函数sort(),选择沿着指定维度进行排序,返回排序后的Tensor及对应的索引位置。max()与min()函数则是沿着指定维度选择最大与最小元素,返回该元素及对应的索引位置。a = torch.randn(3, 3) a #按照第0维即按行排序,每一列进行比较,True代表降序,False代表升序 a.sort(0, True)[0] a.sort(0, True)[1] #按照第0维即按行选取最大值,即将每一列的最大值选取出来 a.max(0)
对于Tensor的单元素数学运算,如abs()、sqrt()、log()、pow()和三角函数等,都是逐元素操作(element-wise),输出的Tensor形状与原始Tensor形状一致。 -
Tensor的自动广播机制与向量化
不同形状的Tensor进行计算时,可自动扩展到较大的相同形状,再进行计算。广播机制的前提是任一个Tensor至少有一个维度,且从尾部遍历Tensor维度时,两者维度必须相等,其中一个要么是1要么不存在。a = torch.ones(3, 1, 2) b = torch.ones(2, 1) #从尾部遍历维度,1对应2,2对应1,3对应不存在,因此满足广播条件,最后求和后的维度为[3,2,2] (a + b).size() c = torch.ones(2, 3) #a 与c最后一维的维度为2对应3,不满足广播条件,因此报错 (a + c).size()
向量化操作是指可以在同一时间进行批量地并行计算,例如矩阵运算,以达到更好的计算效率的一种方式。在实际使用时,应尽量使用向量化直接对Tensor操作,避免低效率的for循环对元素逐个操作,尤其是在训练网络模型时,如果有大量的for循环,会极大的影响训练的速度。 -
Tensor的内存共享
PyTorch提供了一些原地操作运算,即in-place operation,不经过复制,直接在原来的内存上进行计算。对于内存的共享,主要有如下3种情况。

-
通过Tensor初始化Tensor
直接通过Tensor来初始化另一个Tensor,或者通过Tensor的组合、分块、索引、变形操作来初始化另一个Tensor,则这两个Tensor共享内存。a = torch.randn(2, 2) a #用a初始化b,或者用a的变形操作初始化c,这三者共享内存,一个边,其余的也改变了。 b = a c = a.view(4) b[0, 0] = 0 c[3] = 4 a
-
原地操作符
PyTorch对于一些操作通过加后缀“”实现了原地操作,如add()和resize_()等,这种操作只要被执行,本身的Tensor则会被改变。a = torch.Tensor([[1, 2], [3, 4]]) a #add_()函数使得a也改变了 b = a.add_(a) a #resize_()函数使得a也发生了改变 c = a.resize_(4) a
-
Tensor与NumPy转换
Tensor与NumPy可以高效的进行转换,并且转换前后的变量共享内存。在进行PyTorch不支持的操作时,甚至可以曲线救国,将Tensor转换为NumPy类型,操作后再转为Tensor。a = torch.randn(2, 2) a #Tensor转为NumPy b = a.numpy() b #NumPy转为Tensor c = torch.from_numpy(b) c #Tensor转为list d = a.tolist() d
-
Autograd与计算图
基本数据Tensor可以保证完成前向传播,想要完成神经网络的训练,接下来还需要进行反向传播与梯度更新,而PyTorch提供了自动求导机制autograd,将前向传播的计算记录成计算图,自动完成求导。
-
Tensor的自动求导:Autograd
自动求导机制记录了Tensor的操作,以便自动求导与反向传播。可以通过requires_grad参数来创建支持自动求导机制的Tensor。import torch a = torch.randn(2, 2, requires_grad=True)requires_grad参数表示是否需要对该Tensor进行求导,默认为False;设置WieTrue则需要求导,并且依赖于该Tensor的之后的的所有节点都需要求导。
Tensor有两个重要的属性,分别记录了该Tensor的梯度与经历的操作。- grad:该Tensor对应的梯度,类型为Tensor,并与Tensor同维度。
- grad_fn:指向function对象,即该Tensor经过了什么样的操作,用作反向传播的梯度计算,如果该Tensor由用户自己创建,则该grad_fn为None。
import torch a = torch.randn(2, 2, requires_grad=True) b = torch.randn(2, 2) #可以看到默认的Tensor是不需要求导的,设置requires_grad为True后则需要求导 a .requires_grad, b.requires_grad #也可以通过内置函数requires_grad()将Tensor变为需要求导 b.requires_grad_() b.requires_grad #通过计算生成的Tensor,由于依赖的Tensor需要求导,因此c也需要求导 c = a + b c.requires_grad #a与b是自己创建的,grad_fn为None,而c的grad_fn则是一个Add函数操作 a.grad_fn, b.grad_fn, c.grad_fn d = c.detach() d.requires_grad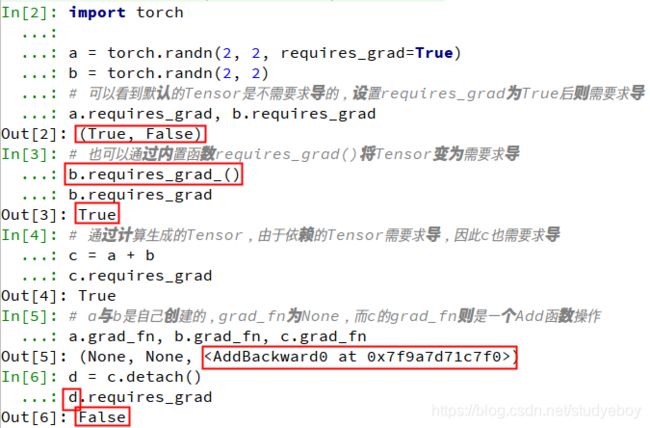
-
计算图
计算图是PyTorch对于神经网络的具体实现形式,包括每一个数据Tensor及Tensor之间的函数function。
Autograd的基本原理是随着每一步Tensor的计算操作,逐渐生成计算图,并将操作的function记录在Tensor的grad_fn中。在前向计算完成后,只需对根节点进行backward函数操作,即可从当前根节点自动进行反向传播与梯度计算,从而得到每一个叶子节点的梯度,梯度计算遵循链式求导法则。import torch #生成3个Tensor变量,并作为叶节点 x = torch.randn(1) w = torch.ones(1, requires_grad=True) b = torch.ones(1, requires_grad=True) #自己生成的,因此都为叶节点 x.is_leaf, w.is_leaf, b.is_leaf #默认是不需要求导,关键字赋值为True后则需要求导 x.requires_grad, w.requires_grad, b.requires_grad #进行前向计算,由计算生成的变量都不是叶节点 y = w * x z = y + b y.is_leaf, z.is_leaf #由于依赖的变量有需要求导的,因此y和z都需要求导 y.requires_grad, z.requires_grad #grad_fn记录生成该变量经过了什么操作,如y是Mul,z是Add y.grad_fn z.grad_fn #对根节点调用backward()函数,进行梯度反传 z.backward(retain_graph=True) w.grad b.grad
-
Autograd注意事项
PyTorch的Autograd机制可以使得其可以灵活的进行前向传播与梯度计算,在实际使用时,需要注意以下3点。
- 动态图特性
PyTorch建立的计算图是动态的,动态图是指程序运行时,每次前向传播时从头开始构建计算图,这样不同的前向传播就可以有不同的计算图,也可以在前向时插入各种Python的控制语句,不需要事先不所有的图都构建出来,并且可以很方便的查看中间过程变量。 - backward()函数
需要传入的参数grad_variables,其代表 根节点的导数,也可以看作根节点各部分的权重系数。因为PyTorch不允许Tensor对Tensor求导,求导时都是标量对于Tensor进行求导,因此,如果根节点是向量,则应配以对应大小的权重,并求和得到标量,再反传。如果根节点的值是标量,则该参数可以省略,默认为1。当有多个输出需要同时进行梯度反传时,需要将retain_graph设置为True,从而保证在计算多个输出的梯度时互不影响。
- 动态图特性
神经网络工具箱torch.nn
PyTorch提供了集成度更高的模块化接口torch.nn,该接口构建与Autograd之上,提供了网络模组、优化器和初始化策略等一系列功能。
-
nn.Module类
nn.Module是PyTorch提供的神经网络类,并在类中实现了网络各层的定义及前向计算与反向传播机制。在实际使用时,如果想要实现某个神经网络,只需继承nn.Module,在初始化中定义模型结构与参数,在函数forward()中编写网络前向过程即可。#perception.py import torch from torch import nn #首先建立一个全连接的子module,继承nn.Module class Linear(nn.Module): def __init__(self, in_dim, out_dim): super(Linear, self).__init__() #调用nn.Module的构造函数 #使用nn.Parameter来构造需要学习的参数 self.w = nn.Parameter(torch.randn(in_dim, out_dim)) self.b = nn.Parameter(torch.randn(out_dim)) #在forward中实现前向传播过程 def forward(self, x): x = x.matmul(self.w) #使用Tensor.matmul实现矩阵相乘 y = x + self.b.expand_as(x) #使用Tensor.expand_as()来保证矩阵形状一致 return y #构建感知机类,继承nn.Module,并调用了Linear的子module class Perception(nn.Module): def __init__(self, in_dim, hid_dim, out_dim): super(Perception, self).__init__() self.layer1 = Linear(in_dim, hid_dim) self.layer2 = Linear(hid_dim, out_dim) def forward(self, x): x = self.layer1(x) y = torch.sigmoid(x) y = self.layer2(y) y = torch.sigmoid(y) return yimport torch from perception import Perception #调用上述模块 #实例化一个网络,并赋值全连接中的维数,最终输出二维代表了二分类 perception = Perception(2, 3, 2) #可以看到perception中包含上述定义的layer1与layer2 perception #named_parameters()可以返回学习参数的迭代器,分别为参数名与参数值 for name, parameter in perception.named_parameters(): print(name, parameter) #随机生成数据,注意这里的4代表了样本数为4,每个样本有两维 data = torch.randn(4, 2) data #将输入数据传入perception.perception()相当调用perception中的forward()函数 output = perception(data) output

-
nn.Parameter函数
在类的__init__()中需要定义网络学习的参数,在此使用nn.Parameter()函数定义了全连接中的w和b,这是一种特殊的Tensor的构造方法,默认需要求导,即requires_grad为True。 -
forward()函数与反向传播
forward()函数用来进行网络的前向传播,并需要传入相应的Tensor,上例中perception(data)即时直接调用了forward()。在具体底层实现中,perception.call(data)将类的实例perception变成了可调用对象perception(data),而在perception.call(data)中主要调用了forward()函数。 -
多个Module的嵌套
在Module的搭建时,可以嵌套包含子Module,提升代码的复用性。在实际的应用中,PyTorch也提供了绝大多数的网络层,如全连接、卷积网络中的卷积、池化等,并自动实现前向与反向传播。 -
nn.Module与nn.function库
nn.functional也提供了很多网络层与函数功能,但与nn.Module不同的是,利用nn.funtional定义的网络层不可自动学习参数,还需要使用nn.Parameter封装。nn.functional的设计初衷是对于一些不需要学习参数的层,如激活层、BN(BatchNormlization)层。 -
nn.Sequential()模块
当模型只是简单的前馈网络时,即上一层的输出直接作为下一层的输入,这时可以采用nn.Sequential()模块来快速搭建模型,而不必手动在forward()函数中一层一层的前向传播。class Perception(nn.Module): def __init__(self, in_dim, hid_dim, out_dim): super(Perception, self).__init__() #利用nn.Sequential()快速搭建网络模块 self.layer = nn.Sequential( nn.Linear(in_dim, hid_dim), nn.Sigmoid(), nn.Linear(hid_dim, out_dim), nn.Sigmoid()) def forward(self, x): y = self.layer(x) return yfrom perception_sequential import Perception model = Perception(100, 1000, 10).cuda() #构建类的实例,并表明在CUDA上 #打印model结构,会显示Sequential中每一层的具体参数配置 model input = torch.randn(100).cuda() output = model(input) output.shape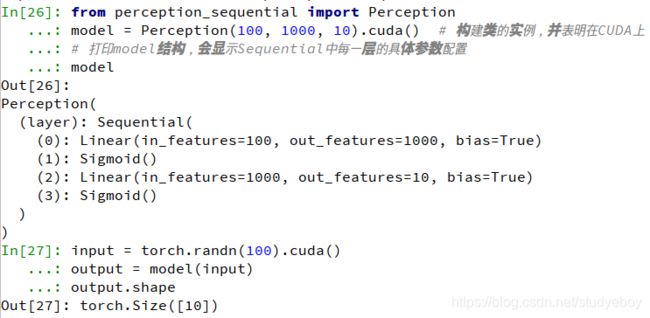
-
-
损失函数
在深度学习中,损失反映模型最后预测结果与实际真值之间的差距,可以用来分析训练过程的好坏、模型是否收敛等,在PyTorch中,损失函数可以看做是网络的某一层而放到模型定义中,单在实际使用时更偏向于作为功能函数而放到前向传播过程中。from torch import nn import torch.nn.functional as F #设置标签,由于是二分类,一共有4个样本,因此标签维度为4,每个数为0或1两个类别 label = torch.Tensor([0, 1, 1, 0]).long() #实例化nn中的交叉熵损失类 criterion = nn.CrossEntropyLoss() #调用交叉熵损失 loss_nn = criterion(output, label) loss_nn #由于F.cross_entropy是一个函数,因此可以直接调用,不需要实例化,两者求得的损失值相同 loss_functional = F.cross_entropy(output, label) loss_functional
-
优化器nn.optim
nn.Module模块提供了网络骨架,nn.functional提供了各式各样的损失函数,而Autograd又自动实现了求导与反向传播机制,nn.optim提供了进行模型优化、加速收敛的模块。
nn.optim中包含了各种常见的优化算法,包括随机梯度下降算法SGD(Stochastic Gradient Desent,随机梯度下降)、Adam(Adaptive Moment Estimation)、AdaGrad、RMSProp。-
SGD方法
梯度下降(Gradient Descent)是迭代法中的一种,是指沿着梯度下降的方向求解极小值,一般可用于求解最小二乘问题。在深度学习中,当前更常用的是SGD算法,以一个小批次(Mini Batch)的数据为单位,计算一个批次的梯度,然后反向传播优化,并更新参数。
SGD参数的两个优点:- 分担训练压力
当前数据集通常数量较多,尺度较大,使用较大的数据同时训练显然不现实,SGD提供了小批量训练并优化网络的方法,有效分担了GPU等计算硬件的压力。 - 加快收敛
由于SGD一次只采用少量的数据,这意味着会有多次的梯度更新,在某些数据集中,其收敛速度会更快。
SGD缺点:
- 初始学习率难以确定
SGD算法依赖于一个较好的初始学习率,但设置初始学习率并不直观,并且对于不同的任务,其初始值也不固定。 - 容易陷入局部最优
SGD虽然采用了小步快走的思想,但是容易陷入局部的最优解,难以跳出。
有效解决局部最优的通常做法是增加动量(momentum),其概念来自于物理学,在此是指更新的时候一定程度多行保留之前更新的方向,同时利用当前批次的梯度进行微调,得到最终的梯度,可以增加优化的稳定性,降低陷入局部最优难以跳出的风险。
当梯度下降方向与上次相同时,梯度会变大,也就会加速收敛。当梯度方向不同时,梯度会变小,从而抑制梯度更新的震荡,增加稳定性。在训练的中后期,梯度会在局部最小值周围震荡,但动量的存在使得梯度更新并不是0,从而有可能跳出局部最优解。
- 分担训练压力
-
Adam方法
Adam利用梯度的一阶矩与二阶矩动态的估计调整每一个参数的学习率,是一种学习率自适应算法。
Adam的优点在于,经过调整后,每一次迭代的学习率都在一个确定范围内,使得参数更新更加平稳。此外,Adam算法可以使模型更快收敛,尤其适用于一些深层网络,或者神经网络较为复杂的场景。from torch import optim optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) optimizer = optim.Adam([var1, var2], lr=0.0001)#mlp.py from torch import nn class MLP(nn.Module): def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim): super(MLP, self).__init__() #通过Sequential快速搭建三层的感知机 self.layer = nn.Sequential( nn.Linear(in_dim, hid_dim1), nn.ReLU(), nn.Linear(hid_dim1, hid_dim2), nn.ReLU(), nn.Linear(hid_dim2, out_dim), nn.ReLU()) def forward(self, x): x = self.layer(x) return ximport torch from mlp import MLP from torch import optim from torch import nn #实例化模型,并赋予每一层的维度 model = MLP(28*28, 300, 200, 10) model #打印model的结构,由3个全连接层构成 #采用SGD优化器,学习率为0.01 optimizer = optim.SGD(params=model.parameters(), lr=0.01) data = torch.randn(10, 28*28) output = model(data) #由于是10分类,因此label元素从0到9,一共10个样本 label = torch.Tensor([1, 0, 4, 7, 9, 3, 4, 5, 3, 2]).long() label #求损失 criterion = nn.CrossEntropyLoss() loss = criterion(output, label) loss optimizer.zero_grad() #损失的反向传播 loss.backward() #利用优化器进行梯度更新 optimizer.step()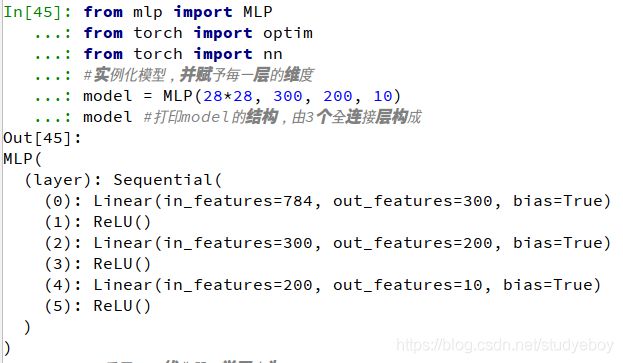

对于训练过程中学习率调整,需要注意:- 不同参数层分配不同的学习率,优化器也可以很方便的实现将不同的网络层分配成不同的学习率,即对于特殊的层单独赋予学习率,其余的保持默认的整体学习率。
#对于model中需要单独赋予学习率的层,如special层,则使用‘lr’关键字单独赋予 optimizer = optim.SGD([{ 'params': model.special.parameters(), 'lr': 0.001}, { 'params': model.base.parameters()}, lr=0.0001]) - 学习率动态调整,对于训练过程中动态的调整学习率,可以在迭代次数超过一定值后,重新赋予optim优化器新的学习率。
- 不同参数层分配不同的学习率,优化器也可以很方便的实现将不同的网络层分配成不同的学习率,即对于特殊的层单独赋予学习率,其余的保持默认的整体学习率。
-
模型处理
模型是神经网络训练优化后得到的成果,包含了神经网络骨架及学校得到的参数。
-
网络模型库:torchvision.models
对于深度学习,torchvision.models库提供了众多经典的网络结构与预训练模型,利用这些模型可以快速搭建舞台检测网络,不需要逐层手动实现。torchvision包与PyTorch相互独立,需要通过pip指令安装。from torch import nn from torchvision import models #通过torchvision.model直接调用VGG16网络结构 vgg = models.vgg16() #VGG16的特征层包括13个卷积、13个激活函数ReLU、5个池化一共31层 len(vgg.features) #VGG16的分类层包括3个全连接、2个ReLU、2个Dropout,一共7层 len(vgg.classifier) #可以通过出现的属性直接索引每一层 vgg.classifier[-1] #也可以选取某一部分,如下代表了特征网络的最后一个卷积模组 vgg.features[24:]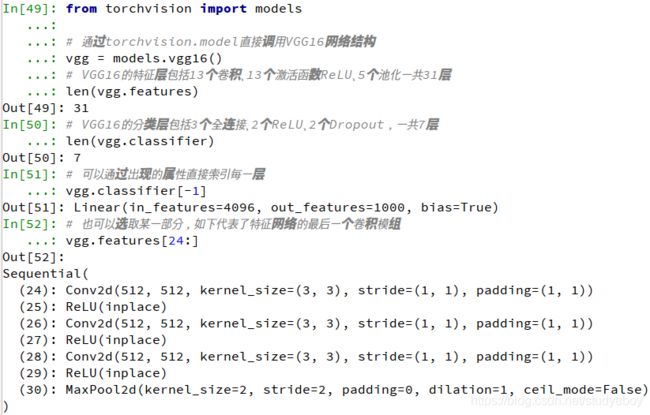
-
加载预训练模型
对于计算机视觉任务,重新训练一个新的模型是比较复杂的,并且不容易调整,因此,Fine-tune(微调)是一个常用的选择。即利用别人在一些数据集上训练好的预训练模型,在自己的数据集上训练自己的模型。-
直接利用torchvision.models中自带的预训练模型,只需要在使用时赋予pretrained参数为True即可。
from torch imort nn from torchvision import models #通过torchvision.model直接调用VGG16的网络结构 vgg = models.vgg16(pretrained=True) -
想要使用自己本地预训练模型,或者之前训练过的模型,则可以通过model.load_state_dict()函数操作。
import torch from torch import nn from torchvision import models #通过torchvision.model直接调用VGG16的网络结构 vgg = models.vgg16() state_dict = torch.load('your model path') #利用load_state_dict,遍历预训练模型的关键字,如果出现在了VGG中,则加载预训练参数 vgg.load_state_dict({ k: v for k,v in state_dict_items() if k in vgg.state_dict()}) -
对于不同的检测任务,卷积网络的前两三层的作用是非常类似的,都是提取图像的边缘信息等,因此未来保证模型训练中能够更加稳定,一般会固定预训练网络的前两三个卷积层而不进行参数的学习。
for layer in range(10): for p in vgg[layer].parameters(): p.requires_grad = False
-
-
模型保存
参数的保存通过torch.save()函数实现,可保存对象包括网络模型、优化器等,而这些对象的当前状态数据可以通过自身的state_dict()函数获取。torch.save({ 'model': model.state_dict(), 'optimizer': optimizer.state_dict(), 'model_path.pth'})
数据处理
-
主流公开数据集
- ImageNet数据集
- PASCAL VOC数据集
- COCO数据集
-
数据加载
PyTorch将数据集的处理过程标准化,提供了Dataset基本的数据类,并在torchvision中提供了众多数据变换函数,数据加载的具体过程主要分3步。

-
继承Dataset类
对于数据集的处理,PyTorch提供了torch.utils.data.Dataset这个抽象类,在使用时只需要继承该类,并重写__len__()和__getitem__()函数,即可以方便地进行数据集的迭代。from torch.utils.data import Dataset class my_data(Dataset): def __init__(self, image_path, annotation_path, transform=None): #初始化,读取数据集 def __len__(self): #获取数据集的总大小 def __getitem__(self, id): #对于指定的id,读取该数据并返回 #对该类进行实例化 dataset = my_data('your image path', 'your annotation path') #实例化该类 for data in dataset: print(data) -
数据变换与增强:torchvision.transforms
PyTorch提供了torchvision.transforms工具包,可以方便的进行图像缩放、裁剪、随机翻转、填充及张量的归一化等操作,操作对象是PIL的Image或者Tensor。如果需要进行多个变换功能,可以利用transforms.Compose将多个变换整合起来,并且在实际使用时,通常会将变换操作集成到Dataset继承类中。from torchvision import transforms #将transforms集成到Dataset类中,使用Compose将多个变换整合到一起 dataset = my_data('your image path ', 'your annotation path', transforms=transforms.Compose([transforms.Resize(256) #将图像最短边缩小至256,宽高变量不变 #以0.5的概率随机翻转指定的PIL图像 transforms.RandomHorizontalFlip() #将PIL图像转为Tensor,元素区间从[0,255]归一化到[0,1] transform.ToTensor() #进行mean与std为0.5的标准化 transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) ])) -
继承DataLoader类
经过前两步已经获取每一个变换后的样本,但是仍然无法进行批量处理、随机选取等操作,因此需要torch.utils.data.Dataloader类进一步封装,该类需要4个参数,第1个参数是之前继承的Dataset实例,第2个参数是批量batch的大小,第3个参数是是否打乱数据参数,第4个参数是使用几个线程来加载数据。from torch.utils.data import Dataloader #使用DataLoader进一步封装Dataset dataloader = Dataloader(dataset, batch_size=4, shuffle=True, num_workers=4)DataLoader是一个可迭代对象,对该实例进行迭代即可用于训练过程。
data_iter = iter(dataloader) for step in range(iters_per_epoch): data = next(data_iter) #将data用于训练网络即可
-
-
GPU加速
PyTorch为数据在GPU上运行提供了非常便利的操作。首先可以使用torch.cuda.is_available()来判断当前环境下GPU是否可用,其次是对于Tensor和模型,可以直接调用cuda()方法将数据转移到GPU上运行,并且可以输入数字来指定具体转移到哪块GPU上运行。import torch from torchvision import models a = torch.randn(3,3) b = models.vgg16() #判读当前GPU是否可用 if torch.cuda.is_available(): a = a.cuda() #指定将b转移到变换为1的GPU上 b = b.cuda(1) #使用torch.device()来指定使用哪一个GPU device = torch.device('cuda: 1') c = torch.randn(3, 3, device=device, requires_grad=True)指定使用哪一块GPU的方法:
- 终端执行脚本时直接指定GPU的方式
- 脚本中利用函数指定
#method1 export CUDA_VISIBLE_DEVICES=2 python train.py #method2 import torch torch.cuda.set_device(1)在工程应用中,通常使用torch.nn.DataParallel(model, device_ids)函数来处理多GPU并行计算的问题。
多GPU处理的实现方式是,首先将模型加载到主GPU上,然后复制模型到各个指定的GPU上,将输入数据按batch的维度进行划分,分配到每个GPU上度量进行前向计算,再将得到的损失求和反向传播更新单个GPU上独立进行前向计算,再将得到的损失求和并反向传播更新单个GPU上的参数,最后将更新后的参数复制到各个GPU上。model_gpu = nn.DataParalle(model, device_ids=[0,1]) output = model_gpu(input) -
数据可视化
-
TensorBoardX
TensorBoardX是专门为PyTorch开发的一套数据可视化工具,功能与TensorBoard相当,支持曲线、图片、文本和计算图等不同形式的可视化,而且使用简单。#安装 pip install tensorboardX #训练脚本中,创建记录对象与数据的添加 from tensorboardx import SummaryWriter #创建writer对象 writer = SummaryWriter('logs/tmp') #添加曲线,并且可以使用'/'进行多级标题的指定 writer.add_scalar('loss/total_loss', loss.data[0], total_iter) writer.add_scalar('loss/rpn_loss', rnp_loss.data[0], total_iter) #TensorBoard在终端中开启Web服务 tensorboard --logdir=log/tmp/ -
Visdom
Visdom由Facebook团队开发,是一个非常灵活的可视化工具,可用于多种数据的创建、组织和共享,支持NumPy、Torch与PyTorch数据,目的是促进远程数据的可视化,支持科学实验。#安装 pip install visdom #开启visdom服务 python -m visdom.server #demo import torch import visdom #创建visdom客户端,使用默认端口8097,环境为first,环境的作用是对可视化的空间进行区分 vis = visdom.Visdom(env='first') #vis对象有text()、line()和image()等函数,其中的win参数代表了显示的窗格(pane)的名字 vis.text('first visdom', win='text1') #在此使用append为真来进行增减text,否则会覆盖之前的text vis.text('hello pytorch', win='text1', append=True) #绘制y=-i^2+20xi+1的曲线,opts可以进行标题、坐标轴标签等的配置 for i in range(20): vis.line(X=torch.FloatTensor([i]), Y=torch.FloatTensor([-i**2+20*i+1]), opts={ 'title': 'y=-x^2+20x+1'}, win='loss', update='append') #可视化一张随机图片 vis.image(torch.randn(3, 256, 256), win='random_image') #打开浏览器,输入网址即可看到可视化的结果
-
网络骨架:Backbone
当前的物体检测算法虽然各不相同,但第一步通常是利用卷积神经网络处理输入图像,生成深层的特征图,然后再利用各种算法完成区域生成与损失计算,这部分卷积神经网络是整个检测算法的‘骨架’,也被称为Backbone。
神经网络基本组成

-
卷积层
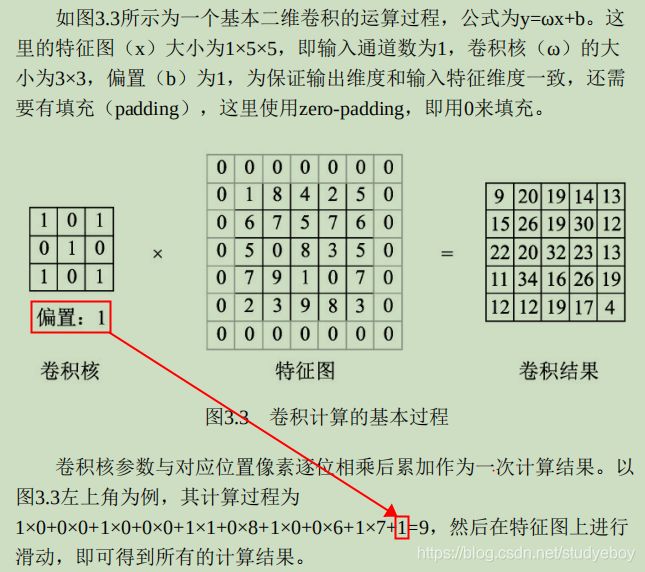
卷积是分析数学中的一种运算,在深度学习中使用的卷积运算通常是离散的。作为卷积神经网络中最基础的组成部分,卷积的本质是用卷积核的参数来提取数据的特征,通过矩阵点乘运算与求和运算来得到结果。
from torch import nn #使用torch.nn中的Conv2d()搭建卷积层 conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1, dilation=1, groups=1, bias=True) #查看卷积核的基本信息,本质上是一个Module conv #通过.weight与.bias查看卷积核的权重与偏置 conv.weight.shape conv.bias.shape #输入特征图,需要注意特征必须是四维,第一维作为batch数,即使是1也要保留 input = torch.ones(1, 1, 5, 5) output = conv(input) #当前配置的卷积核可以使输入和输出的大小一致 input.shape output.shape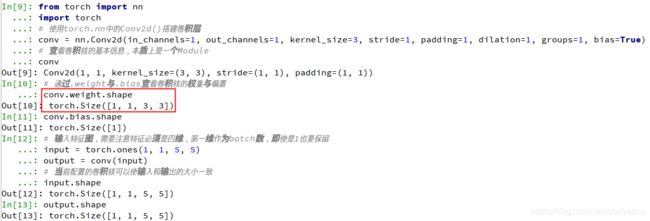
对于torch.nn.Conv2d()来说,传入的参数含义如下:- in_channels:输入特征图的通道数,如果是RGB图像,则通道数为3。卷积中的特征图通道数一般是2的整数次幂。
- out_channels:输出特征图的通道数。
- kernel_size:卷积核的尺寸,常见的有1/3/5/7.
- stirde:步长,即卷积核在特征图上滑动的步长,一般为1.如果大于1,则输出特征图的尺寸会小于输入特征图的尺寸。
- padding:填充,常见的有零填充、边缘填充等,默认为零填充。
- didation:空洞卷积,当大于1时可以增大感受野的同时保持特征图的尺寸,默认为1.
- groups:可实现组卷积,即在卷积操作时不是逐点卷积,而是将输入通道分为多个组,稀疏连接达到降低计算量的目的。默认为1。
- bias:是否需要偏置,默认为True。
在实际使用中特征图的维度通常都不是1,假设输入特征图维度为 m × w i n × h i n m \times w_{in} \times h_{in} m×win×hin,输出特征图维度为 n × w o u t × h o u t n \times w_{out} \times h_{out} n×wout×hout,则卷积核的维度为 n × m × k × k n \times m \times k \times k n×m×k×k,在此产生的乘法操作次数为 n × w o u t × h o u t × m × k × k n \times w_{out} \times h_{out} \times m \times k \times k n×wout×hout×m×k×k。
-
激活函数层
神经网络如果仅仅是有线性的卷积运算堆叠组成,则其无法形成复杂的表达空间,也就很难提取出高语义的信息,因此还需要加入非线性的映射,又称为激活函数,可以逼近任意的非线性函数,以提升整个神经网络的表达能力。在物体检测任务中,常用的激活函数有Sigmoid/ReLU/Softmax函数。-
Sigmoid函数
Sigmoid型函数又称为Logistic函数,模拟了生物的神经元特性,即当神经元获得的输入信号累计超过一定的阈值后,神经元被激活而处于兴奋状态,否则处于抑制状态。
σ ( x ) = 1 1 + e x p ( − x ) \sigma(x) = \frac{1}{1 + exp(-x)} σ(x)=1+exp(−x)1
Sigmoid函数将特征压缩到了(0,1)区间,0端对应抑制状态,而1对应激活状态,中间部分梯度较大。

#引入torch.nn模块 import torch from torch import nn input = torch.ones(1,1,2,2) input sigmoid = nn.Sigmoid() #使用nn.Sigmoid()实例化sigmoid sigmoid(input)
-
ReLU函数
为了缓解梯度消失现象,修正线性单元(Rectified Linear Unit, ReLU)被引入到神经网络中。由于其优越的性能与简单优雅的实现,ReLU已经成为目前卷积神经网络中最为常用的激活函数之一。
R e L U ( x ) = m a x ( 0 , x ) = { 0 , if x < 0 x , if x ≥ 0 ReLU(x) = max(0, x) = \begin{cases} 0, & \text{if x < 0} \\ x, & \text{if x $\geq$ 0} \end{cases} ReLU(x)=max(0,x)={ 0,x,if x < 0if x ≥ 0
在小于0的部分,值与梯度皆为0,而在大于0的部分中导数保持为1,避免了Sigmoid函数中梯度接近于0导致的梯度消失问题。ReLU函数计算简单,收敛快,并在众多卷积网络中验证了其有效性。
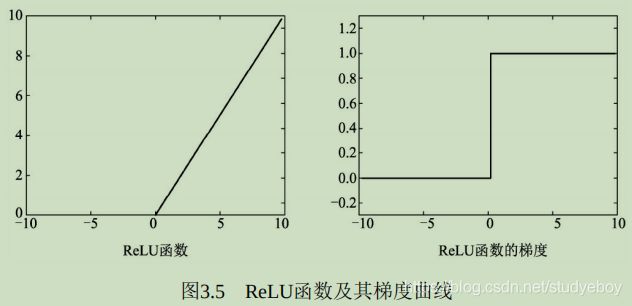
import torch from torch import nn input = torch.randn(1, 1, 2, 2) input #nn.ReLU()可以实现inplace操作,即可以直接将运算结果覆盖到输入中,以节省内存 relu = nn.ReLU(inplace=True) relu(input) #可以看出大于0的值保持不变,小于0的值被置为0
-
LeakyReLU函数
ReLU激活函数虽然高效,但是其将负区间所有的输入都强行置为0,LeakyReLU函数优化了这一点,在负区间内避免了直接置0,而是赋予很小的权重。
L e a k y R e L U ( x ) = m a x ( 1 a i x , x ) = { 1 a i x if x < 0 x if x ≥ 0 LeakyReLU(x) = max(\frac{1}{a_i}x, x)= \begin{cases} \frac{1}{a_i}x & \text{if x < 0} \\ x & \text{if x $\geq$ 0} \end{cases} LeakyReLU(x)=max(ai1x,x)={ ai1xxif x < 0if x ≥ 0
其中 a i a_i ai代表权重,即小于0的值被缩小的比例。
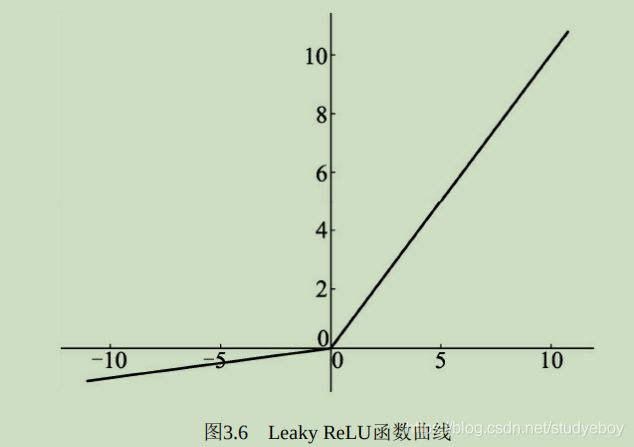
import torch from torch import nn input = torch.randn(1, 1, 2, 2) input #利用nn.LeakyReLU()构建激活函数,并且其为0.04,即ai为25,True代表in-place操作 leakyrelu = nn.LeakyReLU(0.04, True) leakyrelu(input) #从结果看大于0的值保持不变,小于0的值被以0.04的比例缩小。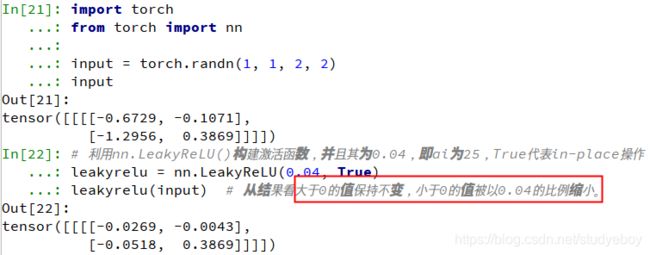
虽然从理论上讲,LeakyReLU函数的使用效果应该要比ReLU函数好,但是从大量实验结果来看并没有看出其效果比ReLU好。 -
Softmax函数
在物体检测中,通常需要面对多个物体分类问题,虽然可以使用sigmoid函数来构造多个二分类器,但比较麻烦,多物体类别较为常用的分类器是softmax函数。
在具体的分类任务中,softmax函数的输入往往是多个类别的得分,输出则是每个类别对应的概率,所有类别的概率取值都是在0-1之间,且和为1。
S i = e V i ∑ j C e V j S_i = \frac{e^{V_i}}{\sum_j^Ce^{V_j}} Si=∑jCeVjeVi
其中 V i V_i Vi表示第 i i i个类别的得分, C C C代表分类的类别总数,输出 S i S_i Si为第 i i i个类别的概率。import torch.nn.functional as F score = torch.randn(1, 4) score #利用torch.nn.functional.softmax()函数,第二个参数表示按照第几个维度进行Softmax计算。 F.softmax(score, 1)
-
-
池化层
在卷积网络中,通常会在卷积层之间增加池化(Pooling)层,以降低特征图的参数量,提升计算速度,增加感受野,是一种降采样操作。池化是一种较强的先验,可以使模型更关注全局特征而非局部出现的位置,这种降维的过程可以保留一些重要的特征信息,提升容错能力,并且还能在一定程度上起到防止过拟合的作用。
在物体检测中,常用的池化有最大值池化(Max Pooling)与平均值(Average Pooling)。池化层哟两个主要的输入参数,即核尺寸kernel_size与步长stride。

import torch from torch import nn #池化主要需要两个参数,第一个参数代表池化区域大小,第二个参数表示步长 max_pooling = nn.MaxPool2d(2, stride=2) aver_pooling = nn.AvgPool2d(2, stride=2) input = torch.randn(1, 1, 4, 4) input #调用最大值池化与平均值池化,可以看到size从[1,1,4,4]变为[1,1,2,2] max_pooling(input) aver_pooling(input)
-
Dropout层
在深度学习中,当参数过多而训练样本又比较少时,模型容易产生过拟合现象。过拟合是很多深度学习乃至机器学习算法的通病,具体表现在训练集上预测准确率高,而在测试集上准确率大幅度下降。Dropout算法可以比较有效的缓解过拟合现象的发生,起到一定正则化的效果。
Dropout的基本思想,在训练时,每个神经元以概率p保留,即以1-p的概率停止工作,每次前向传播保留下来的神经元都不同,这样可以使得模型不太依赖于某些局部特征,泛化性强。在测试时,为了保证相同的输出期望值,每个参数还要乘以p。当然还有另外一种计算方式称为Inverted Dropout,即在训练时将保留下的神经元乘以1/p,这样测试时就不需要再改变权重。

Dropout防止过拟合的原因解释:-
多模型的平均
不同的固定神经网络会有不同的过拟合,多个平均则有可能让一些相反的拟合抵消掉,而Dropout每次都是ongoing的神经元失活,可以看做是多个模型的平均,类似于多数投票取胜的策略。 -
减少神经元间的依赖
由于两个神经元不一定同时有效,因此减少了特征之间的依赖,迫使网络学习有更为鲁棒的特征,因为神经网络不应该对特定的特征敏感,而应该从众多特征中学习更为共同的规律,这也起到了正则化的效果。 -
生物进化
Dropout类似于性别在生物进化中的,物种为了适应环境变化,在繁衍时取雄性和雌性的各一半基因进行组合,这样可以适应更复杂的新环境,避免了单一基因的过拟合,当环境发生变化时也不至于灭绝。
Dropout被广泛应用到全连接层中,一般保留概率设置为0.5,而在较为稀疏的卷积网络中则一般使用BN层来正则化模型,使得训练更稳定。import torch from torch import nn # PyTorch将元素置为0来实现Dropout层,第一个参数为置0概率,第二个参数是否原地操作 dropout = nn.Dropout(0.5, inplace=False) input = torch.randn(2, 64, 7, 7) output = dropout(input)
-
-
BN层
为了追求更高的性能,卷积网络被设计得越来越深,然而网络却变得难以训练收敛于调参。原因在于,浅层参数的微弱变化经过多层线性变换与激活函数后会被放大,改变了每一层的输入分布,造成深层的网络需要不断调整以适应这些分布变化,最终导致模型难以训练收敛。
由于网络中参数变化导致的不节点数据分布发生变化的现象被称作ICS(Internal Covariate Shift)。ICS现象容易使训练过程陷入饱和区,减慢网络的收敛。ReLU从激活函数角度出发,在一定程度上解决了梯度饱和的现象,而BN则从改变数据分布的角度避免了参数陷入饱和区。由于BN层优越的性能,其已经是当前卷积网络中的标配。
BN层首先对每一个batch的输入特征进行白化操作,即去均值方差过程。假设一个batch的输入数据为 x : B = { x 1 , x 2 , . . . , x m } x:B=\{x_1, x_2,...,x_m\} x:B={ x1,x2,...,xm},首先求该batch数据的均值与方差。
μ B ← 1 m ∑ i = 1 m x i \mu_B \leftarrow \frac{1}{m}\sum_{i=1}^mx_i μB←m1i=1∑mxi
σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 \sigma_B^2 \leftarrow \frac {1}{m}\sum_{i=1}^m(x_i - \mu_B)^2 σB2←m1i=1∑m(xi−μB)2
m m m代表batch的大小, μ B \mu_B μB 为批处理数据的均值, σ B 2 \sigma_B^2 σB2为批处理数据的方差。利用求得的均值与方差进行去均值方差操作。
x ^ i ← x i − μ B μ B 2 + ∈ \hat{x}_i \leftarrow \frac{x_i - \mu_B}{\sqrt{\mu_B^2+\in}} x^i←μB2+∈xi−μB
白化操作可以使输入的特征分布具有相同的均值与方差,固定了每一层的输入分布,从而加速网络的收敛。然而,白化操作虽然从一定程度上避免了梯度饱和,但也限制了网络中数据的表达能力,浅层学到的参数信息会被白化操作屏蔽掉,因此,BN层在白化操作后又增加了一个线性变换操作,让数据尽可能的恢复本身的表达能力。
y i ← γ x ^ i + β y_i \leftarrow \gamma \hat{x}_i + \beta yi←γx^i+β
γ \gamma γ和 β \beta β是新引进的可学习参数,最终的输出为 y i y_i yi。
BN层可以看做是增加了线性变换的白化操作,在实际工程中被证明了能够缓解神经网络难以训练的问题。BN层的优点主要哟以下3点:- 缓解梯度消失,加速网络收敛。BN层可以让激活函数的输入数据落在非饱和区,缓解了梯度消失问题。i外,由于每一层数据的均值与方差都在一定的范围内,深层网络不必去不断适应浅层网络输入的变化,实现了层间解耦,允许每一层独立学习,也加快了网络的收敛。
- 简化调参,网络更稳定。在调参时,学习率调的过大容易出现震荡与不收敛,BN层则抑制了参数微小变化随网络加深而被放大的问题,因此对于参数变化的适应能力更强,更容易调参。
- 防止过拟合。BN层将每一个batch的均值与方差引入到网络中,由于每个batch的这两个值都不相同,可看做为训练过程增加了随机噪音,可以起到一定的正则效果,防止过拟合。
在测试时,由于是对单个样本进行测试,没有batch的均值与方差通常做法是在训练时将每一个batch的均值与方差都保留下来,在测试时使用所有训练样本均值与方差的平均值。
from torch import nn #使用BN个需要传入一个参数为num_features,即特征的通道数 bn = nn.BatchNorm2d(64) #eps为公司中的$\in$,momentum为均值方差的动量,affine为添加科学习是 bn input = torch.randn(4, 64, 224, 224) output = bn(input) #BN层不改变输入、输出的特征大小 output.shape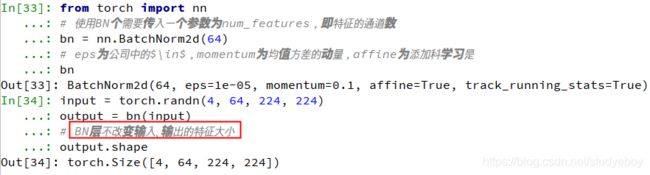
BN 层缺点:- 由于是在batch的维度进行归一化,BN层去较大的batch才能有效的工作,而物体检测等任务由于占用内存较高,限制了batch的大小,这会限制BN层有效的发挥归一化功能。
- 数据的batch大小在训练与测试时往往不一样。在训练时一般采用滑动来计算平均值与方差,在测试时直接拿训练集的平均值与方差来使用。这种方式会导致测试集依赖于训练集,然而有时训练集与测试集的数据分布并不一致。
GN(Group Normalization)从通道方向计算均值与方差,使用更为灵活有效,避开了batch大小对归一化 影响。GN将特征图的通道分为很多个组,对每一个组内的参数做归一化,而不是batch。在特征图中,不同的通道代表了不同的意义,例如形状、边缘和纹理等,这些通道并不是完全独立的分布,而是可以放到一起进行归一化分析。
-
全连接层
全连接层(Fully Connected Layers)一般连接到卷积网络输出的特征图后边,特点是每一个节点都与上下层的所有节点相连,输入与输出都被延展成一维向量,因此从参数量来看全连接层的参数量是最多的。
在物体检测算法中,卷积网络的主要作用是从局部到整体的提取图像的特征,而连接层则用来将卷积抽象出的特征图进一步映射到特定维度的标签空间,以求取损失或者输出预测结果。import torch from torch import nn #第一维表示一共有4个样本 input = torch.randn(4, 1024) linear = nn.Linear(1024, 4096) output = linear(input) input.shape
全连接层的缺点是参数量庞大。以VGGNet为例,其第一个全连接层的输入特征维为 7 × 7 × 12 = 25088 7\times7\times12=25088 7×7×12=25088个节点,输出特征是大小为4096的一维向量,由于输出层的每一个点都来自于上一层所有点权重相加,因此这一层的参数量为 25088 × 4096 ≈ 1 0 8 25088\times4096 \approx10^8 25088×4096≈108。相比之下,VGGNet最后一个卷积层的卷积核大小为 3 × 3 × 512 × 512 ≈ 2.4 × 1 0 6 3\times3 \times 512\times 512 \approx 2.4 \times 10^6 3×3×512×512≈2.4×106,全连接层的参数量是一个卷积层的40多倍。
大量的参数会导致模型网络应用部署困难,并且其中存在着大量的数据冗余, 容易发生过拟合现象。在很多场景中, 使用全局平均池化(Global Average Pooling, GAP)来取代全连接层, 这种思想最早见于NIN(Network in Network)网络中,总体上,使用GAP有如下好处:- 利用池化实现了降维,极大地减少了网络的参数量。
- 特征提取与分类合二为一, 一定程度上可以防止过拟合。
- 由于去除了全连接层,可以实现任意图像尺度的输入。
-
深入理解感受野
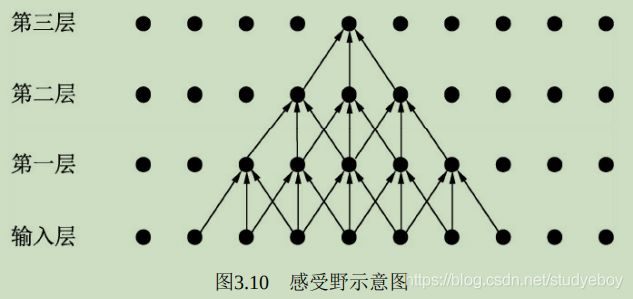
感受野(Receptive Field)是指
特征图上的点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。
卷积层和池化层都会影响感受野,而激活函数层通常对于感受野没有多大影响,对于一般的卷积神经网络感受野的计算公式如下:
R F l + 1 = R F l + ( k − 1 ) × S l RF_{l+1} = RF_l + (k - 1) \times S_l RFl+1=RFl+(k−1)×Sl
S l = ∏ i = 1 l s t r i d e i S_l = \prod _{i=1}^l stride_i Sl=i=1∏lstridei
其中, R F l + 1 RF_l+1 RFl+1与 R F l RF_l RFl分别代表第 l + 1 l+1 l+1层与第 l l l层的感受野, k k k代表第 l + 1 l+1 l+1层的卷积核的大小, S l S_l Sl代表第 l l l层的步长之积。注意,当前层的步长并不影响当前个 感受野。
通过上述公式求取出的感受野通常很大, 而实际的有效感受野(Effective Receptive Field)往往小于理论感受野。从上图开也看出,虽然第三层的感受野是 7 × 7 7\times7 7×7,但是输入层边缘点的使用次数明显比中间点要少,因此做出的感受野是 7 × 7 7\times7 7×7,因此作出的贡献不同,经过多层的卷积堆叠之后,输入层对于特征图点做出的贡献分布呈高斯分布形状。 -
空洞卷积
空洞卷积最初是为解决图像分割问题而提出的。常见的图像分割算法通常使用池化层来增大增大感受野,同时也小了特征图尺寸,然后再利用上采样还原图像尺寸。特征图缩小再放大的过程造成了精度上的损失,因此需要有一种操作可以在增加感受野的同时保持特征图的尺寸不变,从而替代池化与上采样操作,在这种需求习下,空洞卷积就产生了。
在物体检测的发展中,空洞卷积也发挥了重要的作用。因为虽然物体检测不要求逐像素的检测,但是保持特征图的尺寸较大,对于小物体的检测及物体的定位来说也是至关重要的。
空洞卷积,顾名思义就是在卷积核中间带有一些洞,跳过一些元素进行卷积。
空洞卷积在不增加参数量的前提下,增大了感受野。假设空洞卷积的卷积核大小为 k k k,空洞数为 d d d,则其等效卷积核大小 k ′ k' k′计算公式如下:
k ′ = k + ( k − 1 ) ( d − 1 ) k' = k + (k - 1)(d - 1) k′=k+(k−1)(d−1)
在计算感受野时,只需将原来的卷积核大小 k k k更换为 k ′ k' k′即可。
空洞卷积在不引人额外参数的前提下可以任意扩大感受野,同时保持特征图分辨率不变。这一点在分割与检测任务中十分有用,感受野的扩大可以检测 体,而特征图分辨率不变使得物体定位十分精准。from torch import nn #定义普通卷积,默认dilation为1 conv1 = nn.Conv2d(3, 256, 3, stride=1, padding=1, dilation=1) conv1 #定义dilation为2的卷积,打印卷积后会有dilation的参数 conv2 = nn.Conv2d(3, 256, 3, stride=1, padding=1, dilation=2) conv2
空洞卷积的缺陷:- 网格效应(Gridding Effect):由于空洞卷积是一种稀疏的采样方式,当多个空洞卷积叠加时,有些像素根本没被利用到,会损失信息的连续性与相关性,进而影响分割、检测等要求较高的任务。
- 不同尺度物体的关系:大的dilation rate对于大物体分割与检测有利,但对于小物体则有弊无利,如何处理好多尺度问题的检测,是空洞卷积设计的重点。
走向深度:VGGNet(Visual Geometry Group Network)
VGGNet将卷积网络进行了改良,探索 网络深度与性能的关系,用更小的卷积核与更深的网络结构,取得了较好的效果,成为卷积结构发展史上较为重要的一个网络。
VGGNet网络结构一共有6个不同的 ,最常用的是VGG16。VGGNet采用了5个卷积与三个全连接层,最后使用Softmax做分类。VGGNet有一个显著的特点:每次经过池化层(maxpool)后特征图的尺寸减小一倍,而通道数则增加一倍(最后IG池化层除外)。
VGGNet中,使用的卷积核基本都是 3 × 3 3 \times 3 3×3,而且很多地方出现了多个 3 × 3 3 \times 3 3×3堆叠的现象,这种结构的优点在于,首先从感受野来看,两个 3 × 3 3 \times 3 3×3卷积核与一个 5 × 5 5 \times 5 5×5卷积核是一样的;其次同等感受野时, 3 × 3 3 \times 3 3×3卷积核的参数量更少。更为重要的是,两个 3 × 3 3 \times 3 3×3卷积核的非线性能力要比 5 × 5 5 \times 5 5×5卷积核强,因为其拥有两个激活函数,可大大提高卷积网络的学习能力。
#vgg.py
from torch import nn
class VGG(nn.Module):
def __init__(self, num_classes=1000):
super(VGG, self).__init__()
layers = []
in_dim = 3
out_dim = 64
#循环构造卷积层,一共有13个卷积层
for i in range(13):
layers += [nn.Conv2d(in_dim, out_dim, 3, 1, 1), nn.ReLU(inplace=True)]
in_dim = out_dim
#在第2/4/7/10/13个卷积层后增加池化层
if i == 1 or i == 3 or i == 6 or i == 9 or i == 12:
layers += [nn.MaxPool2d(2,2)]
#第10个卷积后保持和前边的通道数一致,都为512,其余加倍
if i != 9:
out_dim *= 2
self.features = nn.Sequential(*layers)
#VGGNet的3个全连接层,中间有ReLU与Dropout层
self.classifier = nn.Sequential(
nn.Linear(512 * 7 *7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, num_classes),)
def forward(self, x):
x = self.features(x)
#这里是将特征图的维度从[1, 512, 7, 7]变到[1, 512*7*7]
x = x.view(x.size(0), -1)
x = self.classifier(x)
x = self.classifier(x)
return x

import torch
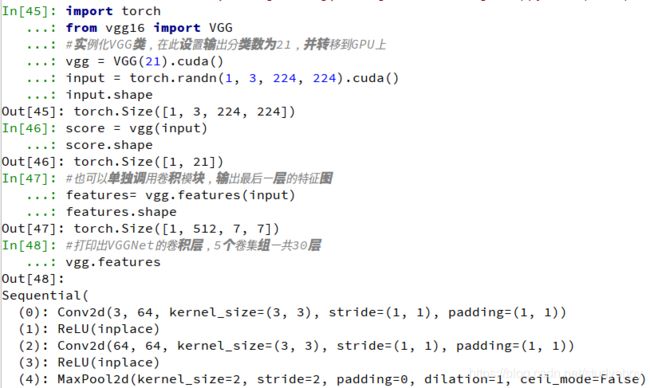
from vgg import VGG
#实例化VGG类,在此设置输出分类数为21,并转移到GPU上
vgg = VGG(21).cuda()
input = torch.randn(1, 3, 224, 224).cuda()
input.shape
score = vgg(input)
score.shape
#也可以单独调用卷积模块,输出最后一层的特征图
features= vgg.features(input)
features.shape
#打印出VGGNet的卷积层,5个卷集组一共30层
vgg.features
#打印出VGGNet的3个全连接层
vgg.classifier


纵横交错:Inception
一般来说,增加网络的深度与宽度可以提升网络的性能,但是这样做也会带来参数量的大幅度增加,同时较深的网络需要较多的数据,否则容易产生过拟合现象。除此之外,增加神经网络额深度容易带来梯度消失现象。Inception v1(又名GoogLeNet)网络较好的解决了这个问题。
Inception v1网络是一个精心设计的22层卷积网络,并提出了具有良好局部特征的Inception模块,即对特征并行地执行多个大小不同的卷积运算与池化,最后再拼接到一起。由于 1 × 1 1\times1 1×1、 3 × 3 3\times3 3×3和 5 × 5 5\times5 5×5的卷积核运算对应不同的特征图区域,因此这样做可以得到更好的图像表征信息。
Inception模块使用了三个不同大小的卷积核进行卷积运算,同时还有一个最大值池化,然后将这4部分级联起来(通道拼接),送入下一层。

为了进一步降低网络参数量,Inception又增加了多个 1 × 1 1\times1 1×1的卷积模块。这种 1 × 1 1\times1 1×1模块可以先将特征图降维,再送给 3 × 3 3\times3 3×3和 5 × 5 5\times5 5×5大小的卷积核,由于通道数的降低,参数量也有了较大的减少。
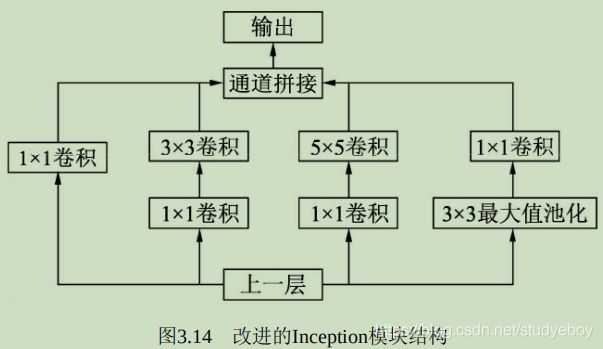
Inception v1网络一共有9个Inception模块,共有22层,在最后的Inception模块处使用了全局平均池化。为了避免深层网络训练时带来的梯度消失问题,引入了两个辅助的分类器,在第3个与第6个Inception模块后输出后执行softmax并计算损失,在训练时和最后的损失一并回传。
Inception v1的参数量是AlexNet的 1 12 \frac{1}{12} 121,VGGNet的 1 3 \frac{1}{3} 31,适合处理大规模数据,尤其是对于计算资源有限的平台。
#inceptionv1.py
import torch
from torch import nn
import torch.nn.functional as F
#首先定义一个包含conv与ReLU的基础卷积类
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding)
def forward(self, x):
x = self.conv(x)
return F.relu(x, inplace=True)
class Inceptionv1(nn.Module):
def __init__(self, in_dim, hid_1_1, hid_2_1, hid_2_3, hid_3_1, hid_3_5, out_4_1):
super(Inceptionv1, self).__init__()
#下面分别是4个子模块各自的网络定义
self.branch1x1 = BasicConv2d(in_dim, hid_1_1, 1)
self.branch3x3 = nn.Sequential(
BasicConv2d(in_dim, hid_2_1, 1),
BasicConv2d(hid_2_1, hid_2_3, 3, padding=1))
self.baranch5x5 = self.Sequential(
BasicConv2d(in_dim, hid_3_1, 1),
BasicConv2d(hid_3_1, hid_3_5, 5, padding=2))
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
BasicConv2d(in_dim, out_4_1, 1))
def forward(self, x):
b1 = self.branch1x1(x)
b2 = self.branch3x3(x)
b3 = self.branch5x5(x)
b4 = self.branch_pool(x)
#将这四个模块沿着通道方向进行拼接
output = torch.cat((b1, b2, b3, b4), dim=1)
return output
import torch
from inceptionv1 import Inceptionv1
#网络实例化,输入模块通道数,并转移到GPU上
net_inceptionv1 = Inceptionv1(3, 64, 32, 64, 64, 96, 32).cuda()
net_inceptionv1
input = torch.randn(1, 3, 256, 256).cuda()
input.shape
output = net_inceptionv1(input)
output.shape


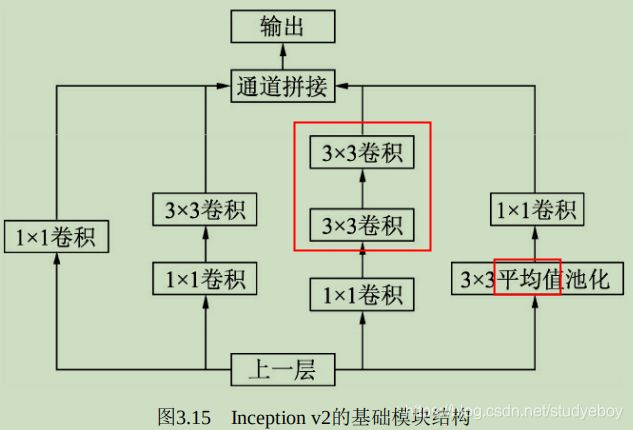
在Inception v1的基础上,Inception v2进一步通过分解与正则化实现更高效的计算,增加了BN层,同时利用两个级联的 3 × 3 3\times3 3×3卷积取代了Inception v1版本中的 5 × 5 5\times5 5×5卷积,这种方式即减少了卷积参数量,也增加了网络的非线性能力。
#inceptioinv2.py
import torch
from torch import nn
import torch.nn.functional as F
#构建基础的卷积模块,与Inception v2的基础模块相比,增加了BN层。
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class Inceptionv2(nn.Module):
def __init__(self):
super(Inceptionv2, self).__init__()
self.branch1 = BasicConv2d(192, 96, 1, 0) #对应1x1卷积分支
#对应1x1卷积与3x3卷积分支
self.branch2 = nn.Sequential(
BasicConv2d(192, 48, 1, 0),
BasicConv2d(48, 64, 3, 1))
#对应1x1卷积、3x3卷积与3x3卷积分支
self.branch3 = nn.Sequential(
BasicConv2d(192, 64, 1, 0),
BasicConv2d(64, 96, 3, 1),
BasicConv2d(96, 96, 3, 1))
#对应3x3平均池化与1x1卷积分支
self.branch4 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(192, 64, 1, 0))
#前向过程,将4个分支进行torch.cat()拼接起来
def forward(self, x):
x0 = self.branch1(x)
x1 = self.branch2(x)
x2 = self.branch3(x)
x3 = self.branch4(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
import torch
from inceptionv2 import Inceptionv2
net_inceptionv2 = Inceptionv2().cuda()
net_inceptionv2
input = torch.randn(1, 192, 32, 32).cuda()
input.shape
output = net_inceptionv2(input) #将输入传入实例的网络
output.shape #输出特征图的通道数为96+64+96+64=320


更进一步,Inception v2将 n × n n\times n n×n的卷积运算分解为 1 × n 1\times n 1×n与 n × 1 n\times1 n×1两个卷积,这种计算成本降低33%。

此外,Inception v2还将模块中的卷积核变得更宽而不是更深,形成第三个模块,以解决表征能力瓶颈的问题。Inception v2网络正是由上述的三个不同类型的模块组成的,其计算也更加有效。
Inception v3在Inception v2的基础上,使用了RMSProp优化器,在辅助的分类器部分增加了 7 × 7 7\times7 7×7的卷积,并且用了标签平滑技术。
Inception v4则是将Inception的思想与残差网络进行了结合,显著提升了训练速度与模型准确率。
里程碑:ResNet
VGGNet与Inception出现后,学者们将卷积网络不断加深以寻求更优越的性能,随着网络的加深,网络却越来越难以训练,一方面会产生梯度消失现象;另一方面越深的网络返回的梯度相关性会越来越差,接近于白噪声,导致梯度更新也接近于随机扰动。
ResNet的思想在于引入了一个深度残差框架来解决梯度消失问题,即让卷积网络去学习残差映射,而不是期望每一个堆叠层的网络都完整的去拟合潜在的映射(拟合函数)。对于神经网络,如果期望的网络最终映射为 H ( x ) H(x) H(x),非残差网络需要直接拟合输出 H ( x ) H(x) H(x),而残差网络需要引入一个shortcut分支,将需要拟合的映射变为残差 F ( x ) : H ( x ) − x F(x):H(x)-x F(x):H(x)−x。ResNet给出的假设是:相较于直接优化潜在映射 H ( x ) H(x) H(x),优化残差映射 F ( x ) : H ( x ) − x F(x):H(x)-x F(x):H(x)−x更为容易。

在ResNet中,残差模块称为Bottleneck,有18层、34层、50层、101层和152层的网络层数版本。ResNet-50的网络架构如下所示,最主要部分在于中间经历了4个大的卷积组,而这4个卷积组分别包含了3、4、6这个3个Bottleneck模块。最后经过一个全局平均池化使得特征图大小变为 1 × 1 1\times 1 1×1,然后进行1000维的全连接,最后经过Softmax输出分类得分。

由于 F ( x ) + x F(x)+x F(x)+x是逐通道进行相加,因此根据两者是否通道数相同,存在两种Bottleneck结构。对于通道数不同的情况,比如每个卷积组的第一个Bottleneck,需要利用 1 × 1 1\times1 1×1卷积对 x x x进行Downsample操作,将通道数变为相同,再进行加操作。对于相同的情况下,两者可以直接进行相加。
#resnet_bottleneck.py
import torch.nn as nn
class Bottleneck(nn.Module):
def __init__(self, in_dim, out_dim, stride=1):
super(Bottleneck, self).__init__()
#网络堆叠层是由1x1/3x3/1x1这3个卷积组成的,中间包含BN层。
self.bottleneck = nn.Sequential(
nn.Conv2d(in_dim, in_dim, 1, bias=False),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Conv2d(in_dim, in_dim, 3, stride, 1, bias=False),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Conv2d(in_dim, out_dim, 1, bias=False),
nn.BatchNorm2d(out_dim),)
self.relu = nn.ReLU(inplace=True)
#Downsample部分是由一个包含BN层的1x1卷积组成
self.downsample = nn.Sequential(
nn.Conv2d(in_dim, out_dim, 1, 1),
nn.BatchNorm2d(out_dim),)
def forward(self, x):
identity = x
out = self.bottleneck(x)
identity = self.downsample(x)
#将identity(恒等映射)与网络堆叠层输出进行相加,并经过ReLU后输出
out += identity
out = self.relu(out)
return out
import torch
from resnet_bottleneck import Bottleneck
#实例化Bottleneck,输入通道数为64, 输出通道数为256,对应第一个卷积组的第一个Bottleneck
bottleneck_1_1 = Bottleneck(64, 256).cuda()
bottleneck_1_1
input = torch.randn(1, 64, 56, 56).cuda()
output = bottleneck_1_1(input) #将输入送到Bottleneck结构中
input.shape
output.shape #相比输入,输出的特征图分辨率没有变,而通道数变为4倍。

继往开来:DenseNet
ResNet通过前层与后层的“短路连接”(shortcuts),加强了前后层之间的信息流通,在一定程度上缓解了梯度消失现象,从而可以将神经网络搭建得很深。更进一步,DenseNet《Densely Connected Convolutional Networks》最大化了这种前后层信息交流,通过建立前面所有层与后面层的密集连接,实现了特征在通道维度上的复用,使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
DenseNet网络由多个Dense Block与间的卷积池化组成,核心就在Dense Block中。Dense Block中的黑点代表一个卷积层,其中的多条黑线代表数据的流动,每一层的输入由前面的所有卷积层的输出组成。注意这里使用了通道拼接(concatnate)操作,而非ResNet的逐元素相加操作。

DenseNet的网络结构有两个特性:
- 神经网络一般需要使用池化等操作缩小特征图尺寸来提取语义特征,而Dense Block需要保持每一个Block内得特征图尺寸一致来直接进行Concatenate操作,因此DenseNet被分成多个Block。Block的数量一般为4。
- 两个相邻的Dense Block之间的部分被称为Transition层,具体包括BN、ReLU、 1 × 1 1\times 1 1×1、 2 × 2 2\times 2 2×2平均池化操作。 1 × 1 1\times 1 1×1卷积的作用是j两维,起到压缩模型的作用,而平均池化则是降低特征图的尺寸。

关于Block,需要注意以下4个细节:
- 每一个Bottleneck输出的特征通道数是相同的,例如这里都是32.同时可以看到,经过Concatenate操作后的通道数是按32的增长量增加的,因此这个32也被称为GrowthRate。
- 这里 1 × 1 1\times 1 1×1卷积的作用是固定输出通道数,达到降维的作用。当几十个Bottleneck相连接时,Concatenate后的通道数会增加到上千,如果不增加 1 × 1 1\times 1 1×1的卷积来降维,后续 3 × 3 3\times 3 3×3卷积所需要的参数量会急剧增加。 1 × 1 1\times 1 1×1卷积的通道数通常是GrowthRate的4倍。
- 图3.20中的特征传递方式是直接将前面所有层的特征Concatenate后传到下一层,这种方式与具体代码实现的方式是一致的,而不像图3.19中,前面层都要有一个箭头指向后面的所有层。
- Block采用了激活函数在前、卷积层在后的顺序,这与一般的网络上是不同的。
DenseNet网络的优势主要体现在两个方面:
- 密集连接的特殊网络,使得每一层都会接受其后所有层的梯度,而不是像普通卷积链式的反传,因此一定程度上解决了梯度消失的问题。
- 通过Concatenate操作使得大量的特征被复用,每个层独有的特征图的通道是较少的,因此相比ResNet,DenseNet参数更少且计算更有效。
DenseNet的缺点是由于进行多次Concatenate操作,数据需要被复制多次,显存容易增加的很快,需要一定的显存优化技术。另外,DenseNet是一种更为特殊的网络,ResNet则相对一般化一些,因此ResNet的应用范围更广泛。
#densenet_block.py
import torch
from torch import nn
import torch.nn.functional as F
#实现一个Bottleneck的类,初始化需要输入通道数与GrowthRate这两个参数
class Bottleneck(nn.Module):
def __init__(self, nChannels, growthRate):
super(Bottleneck, self).__init__()
#通常1x1卷积的通道数为GrowthRate的4倍。
interChannels = 4 * growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(interChannels)
self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
#将输入x同时计算的结果out进行通道拼接
out = torch.cat((x, out), 1)
return out
class Denseblock(nn.Module):
def __init__(self, nChannels, growthRate, nDenseBlocks):
super(Denseblock, self).__init__()
layers = []
#将每一个Bottleneck利用nn.Sequential()整合起来,输入通道数需要线性增长
for i in range(int(nDenseBlocks)):
layers.append(Bottleneck(nChannels, growthRate))
nChannels += growthRate
self.denseblock = nn.Sequential(*layers)
def forward(self, x):
return self.denseblock(x)
import torch
from densenet_block import Denseblock
#实例化DenseBlock,包含6个Bottleneck
denseblock = Denseblock(64, 32, 6).cuda()
#查看denseblock的网络结构,由6个Bottleneck组成
denseblock
input = torch.randn(1, 64, 256, 256).cuda()
output = denseblock(input) #将输入传入到denseblock结构中
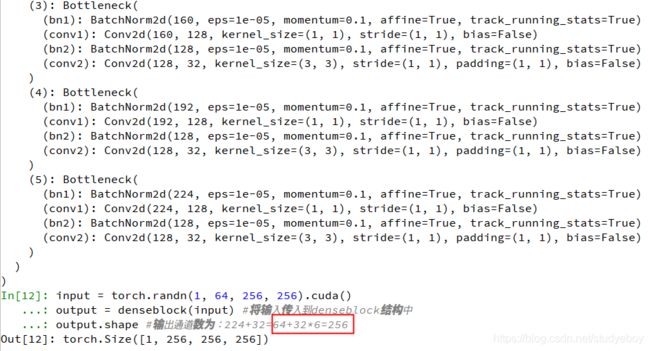
output.shape #输出通道数为:224+32=64+32*6=256

特征金字塔:FPN
为了增强语义性,传统的物体检测模型通常只在深度卷积网络的最后一个特征图上进行后续操作,而这一层对应的下采样率(图像缩小的倍数)通常比较大,造成小物体在特征图上的有效信息较少,小物体的检测性能会急剧下降,这个问题被称为多尺度问题。
解决多尺度问题的关键在于如何提取多尺度的特征。传统的方法有图像金字塔(Image Pyramid),主要思路是将输入图像做成多个尺度,不同尺度的图像生成不同尺度的特征,这种方法简单而有效,但是非常耗时,计算量也很大。
卷积神经网络不同层 大小与语义信息不同,本身就类似一个金字塔结构。FPN(Feature Pyramid Network)方法融合了不同层的特征,较好的改善了多尺度检测问题。
FPN的总体架构主要包含自下而上网络、自上而下网络、横向连接与卷积融合4个部分。

- 自下而上:最左侧为普通的卷积网络,默认使用ResNet结构,用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
- 自上而下:首先对C5进行1x1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特征,以方便下一步进行逐元素相加。这里采用2倍近邻上采样,即直接对邻近元素进行复制,而非线性插值。
- 横向连接(Lateral Connection):目的是为了将上采样后的高语义与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行1x1卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸大且语义信息不足,因此没有把C1放到横向连接中。
- 卷积融合,在得到相加后的特征后,利用3x3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
对于实际物体检测算法,需要在特征图上进行RoI(Region of Interests,感兴趣区域)提取,而FPN有4个输出的特征图,选择哪一个特征图上面的特征也是问题。FPN给出的解决方法是,对于不同大小的RoI,使用不同额特征图,大尺度的RoI在深层的特征图上进行提取,如P5,小尺度的RoI在浅层的特征图上进行提取,如P2。
FPN将深层的语义信息传到底层,来补充浅层的语义信息,从而获得了高分辨率、强语义的特征,在小物体检测、实例分割等领域有着非常不俗的表现。
#fpn.py
import torch.nn as nn
import torch.nn.functional as F
import math
#ResNet的基本Bottleneck类
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_planes, planes, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, 3, stride, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, self.expansion * planes, 1, bias=False),
nn.BatchNorm2d(self.expansion * planes),)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.bottleneck(x)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
#FPN的类,初始化需要一个list,代表ResNet每一个阶段的Bottleneck的数量
class FPN(nn.Module):
def __init__(self, layers):
super(FPN, self).__init__()
self.inplanes = 64
#处理输入的C1模块
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(3, 2, 1)
#搭建自下而上的C2、C3、C4、C5
self.layer1 = self._mame_layer(64, layers[0])
self.layer2 = self._make_layer(128, layers[1], 2)
self.layer3 = self._make_layer(256, layers[2], 2)
self.layer4 = self._make_layer(512, layers[3], 2)
#对C5减少通道数,得到P5
self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0)
#3x3卷积融合特征
self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)
#横向连接,保证通道数相同
self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)
self.latlayer2 = nn.Conv2d(512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d(256, 256, 1, 1, 0)
#构建C2到C5,注意区分stride值为1和2的情况
def _make_layer(self, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != Bottleneck.expansion * planes:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),
nn.BatchNorm2d(Bottleneck.expansion * planes))
layers = []
layers.append(Bottleneck(self.inplanes, planes, stride, downsample))
self.inplanes = planes * Bottleneck.expansion
for i in range(1, blocks):
layers.append(Bottleneck(self.inplanes, planes))
return nn.Sequential(*layers)
#自上而下的采样模块
def _upsample_add(self, x, y):
_, _, H, W = y.shape
return F.upsample(x, size=(H, W), mode='bilinear') + y
def forward(self, x):
#自下而上
c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
#自上而下
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
#卷积融合,平滑处理
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
import torch
from fpn import FPN
#利用listai初始化FPN网络
net_fpn = FPN([3, 4, 6, 3]).cuda()
net_fpn.conv1 #查看FPN的第一个卷积层
net_fpn.bn1 #查看FPN的第一个BN层
net_fpn.relu #查看FPN的第一个ReLU层
net_fpn.maxpool #查看FPN的第一个池化层,使用最大值池化
net_fpn.layer1 #查看FPN的第一个layer,即前面的C2,包含了3个Bottleneck
net_fpn.layer2 #查看fpn的layer2,即上面的C3,包含了4个Bottleneck
net_fpn.toplayer #1x1的卷积,以得到p5
net_fpn.smooth1 #对p4信息平滑的卷积层
net_fpn.latlayer1 #对c4进行横向处理的卷积层
input = torch.randn(1, 3, 224, 224).cuda()
output = net_fpn(input)
#返回的p2, p3, p4, p5这4个特征图通道数相同,但特征图尺寸递减
output[0].shape
output[1].shape
output[2].shape
output[3].shape







为检测而生:DetNet
VGGNet和ResNet虽然从各个角度出发提升了物体检测性能,但是都是为ImageNet的图像分类任务而设计的。而图像分类与物体in层两个任务天然存在着落差,分类任务侧重于全图的特征提取,深层的特征图分辨率很低;而物体检测需要定位出物体位置,特征图分辨率不宜过小,因此造成以下两个缺陷:
- 物体大小难以定位:对于FPN等网络,大物体对应在较深的特征图上检测,由于网络较深时下采样率较大,物体的边缘难以精确预测,增加了回归边界的难度。
- 小物体难以检测:对于传统网络,由于下采样率大造成小物体i 较深的特征图上几乎不可见;FPN虽从较浅的特征图来检测小物体,但浅层的语义信息较弱,且融合深层特征时使用的上采样操作也会增加物体检测的难度。
旷视科技提出的物体检测网络结构DetNet,引入了空洞卷积,使得模型兼具较大感受野与较高分辨率,同时避免了FPN多次上采样,实现了较好的检测效果。
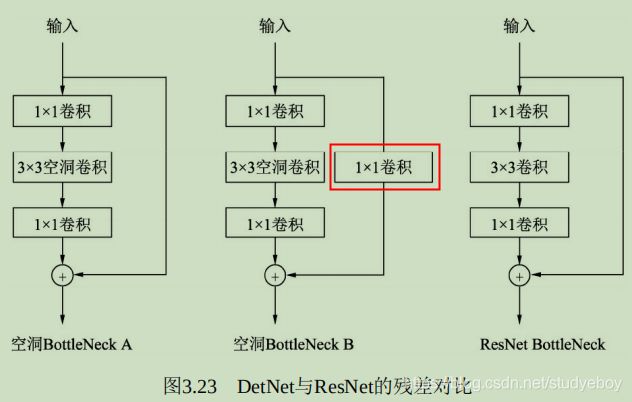
DetNet的网络结构如图所示,选择性能优越的ResNet-50作为基础结构,并保持前4个stage与ResNet-50相同,具体的细节结构有以下3点:
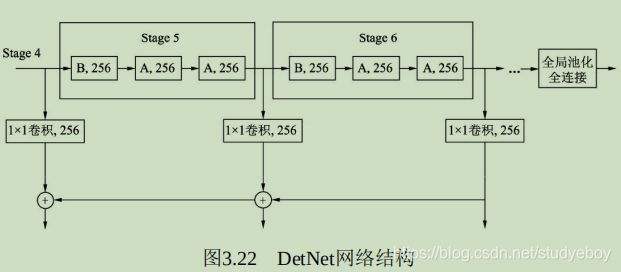
- 引入了一个新的stage6,用于物体检测。Stage5与Stage6使用了DetNet提出的Bottleneck结构,最大的特点是利用空洞数为2的3x3卷积取代了步长为2的3x3卷积。
- Stage5与Stage6的每一个Bottleneck输出的特征图尺寸都为原图的1/16,通道数都为256,而传统的Backbone通常是特征尺寸递减,通道数递增。
- 在组成特征金字塔时,由于特征图大小完全相同,因此 直接从右向左传递相加,避免了上采样操作。为了进一步融合各通道的特征,需要对每一个阶段的输出进行1x1卷积后再与后一Stage传回的特征相加。
DetNet这种精心设计的结构,在增加感受野的同时,获得了较大的特征图尺寸,有利于物体的定位。与此同时,由于各Stage的特征图尺寸相同,避免了上采样,一定程度上降低了计算量,又利于小物体的检测。
DetNet与ResNet两者的基本思想都是卷积堆叠层与恒等映射的相加,区别在于DetNet使用了空洞数为2的3x3卷积,这样使得特征图尺寸保持不变,而ResNet是使用了步长为2的3x3卷积。B相比于A,在恒等映射部分增加了一个1x1卷积,这样做可以区分开不同 Stage,并且实验发现这种做法对于特征金字塔式的检测非常重要。
#detnet_bottleneck__.py
from torch import nn
class DetBottleneck(nn.Module):
#初始化时extra为False时为Bottleneck A,为True时为Bottleneck B
def __init__(self, inplanes, planes, stride=1, extra=False):
super(DetBottleneck, self).__init__()
#构建连续3个卷积层的Bottleneck
self.bottleneck = nn.Sequential(
nn.Conv2d(inplanes, planes, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=2, dilation=2, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, 1, bias=False),
nn.BatchNorm2d(planes),)
self.relu = nn.ReLU(inplace=True)
self.extra = extra
#Bottleneck B的1x1卷积
if self.extra:
self.extra_conv = nn.Sequential(
nn.Conv2d(inplanes, planes, 1, bias=False),
nn.BatchNorm2d(planes))
def forward(self, x):
#对于Bottleneck B来讲,需要对恒等映射增加卷积处理,与ResNet类似
if self.extra:
identity = self.extra_conv(x)
else:
identity = x
out = self.bottleneck(x)
out += identity
out = self.relu(out)
return out
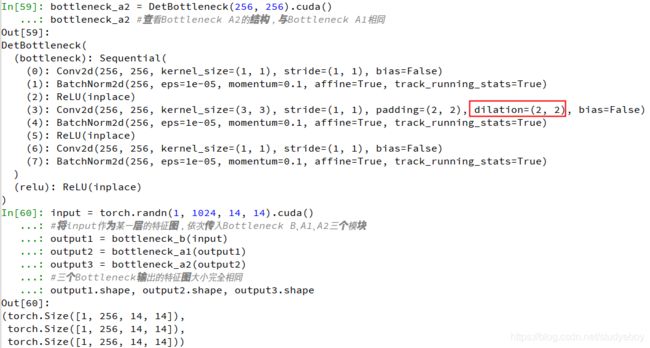
import torch
from detnet_bottleneck import DetBottleneck
#完成一个stage5、即B-A-A的机构,stage4输出通道数为1024
bottleneck_b = DetBottleneck(1024, 256, 1, True).cuda()
bottleneck_b #查看Bottleneck B的结构,带有extra的卷积层
bottleneck_a1 = DetBottleneck(256, 256).cuda()
bottleneck_a1 #查看Bottleneck A1的结构
bottleneck_a2 = DetBottleneck(256, 256).cuda()
bottleneck_a2 #查看Bottleneck A2的结构,与Bottleneck A1相同
input = torch.randn(1, 1024, 14, 14).cuda()
#将input作为某一层的特征图,依次传入Bottleneck B、A1、A2三个模块
output1 = bottleneck_b(input)
output2 = bottleneck_a1(output1)
output3 = bottleneck_a2(output2)
#三个Bottleneck输出的特征图大小完全相同
output1.shape, output2.shape, output3.shape


两阶经典检测器:Faster RCNN
RCNN系列发展历程
-
开山之作:RCNN
RCNN延续传统物体检测的思想,将物体检测当作分类问题处理,即先提取一系列的候选区域,然后对候选区域进行分类。具体过程主要有4步:- 候选区域生成。采用Region Proposal提取候选区域,例如Selective Search算法,先将图像分割成小区域,然后合并包含同一物体可能性高的区域,并输出,在这一步需要提取约2000个候选区域。在提取完后,还需要将每一个区域进行归一化处理,得到固定大小的图像。
- CNN特征提取。将上述固定大小的图像,利用CNN网络得到固定维度的特征输出。
- SVM分类器。使用线性二分类器对输出的特征进行分类,得到是否属于此类的结果,并采用难样本挖掘来平衡正负样本的不平衡。
- 位置精修。通过一个回归器,对特征进行边界回归以得到更为精确的目标区域。

RCNN虽然显著提升了物体检测的效果,但仍然存在3个较大的 。- 首先,RCNN需要多步训练,步骤繁琐且训练速度较慢;
- 其次,由于涉及分类中的全连接网络,因此输入尺寸是固定的,造成了精度的降低;
- 最后,候选区域需要提前提取并保存,占用空间较大。
-
端到端:Fast RCNN
在RCNN后,SPPNet算法解决了重复卷积计算与固定输出尺度的两个问题,但仍然存在RCNN的其他弊端。Fast RCNN算法不仅训练的步骤可以实现端到端,而且算法基于VGG16网络,在训练速度上比RCNN快了近9倍,在测试速度上快了213倍, 并在VOC 2012数据集上达到了68.4%的检测率。
Fast RCNN算法框架如下所示,相比RCNN,主要有3点改进:- 共享卷积:将整福图像送到卷积网络中进行区域生成,而不是像RCNN那样一个个的候选区域,虽然仍采用Selective Search方法,但共享卷积的优点使得计算量大大减少。
- RoI Pooling:利用特征池化(RoI Pooling)的方法进行特征尺度变换,这种方法可以有任意大小图片的输入,使得训练过程更加灵活、准确。
- 多任务损失:将分类与回归网络放到一起训练,并且避免SVM分类器带来的单独训练与速度慢的缺点,使用了Softmax函数进行分类。
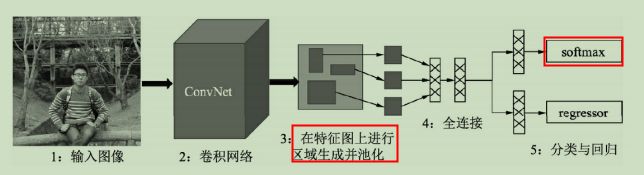
Fast RCNN算法虽然取得了显著的效果,但在该算法中,Selective Search需要消耗2-3秒,而特征提取仅需要0.2秒,因此这种区域生成方法限制了Fast RCNN算法的发挥空间,这为Faster RCNN算法提供了改进方向。 -
走向实时:Faster RCNN
Faster RCNN算法最大的创新点在于提出了RPN(Region Proposal Network)网络,利用Anchor机制将区域生成与卷积网络联系在一起,将检测速度提升到17fps/sec,并在VOC2012测试集上实现了70.4%的检测结果。
Anchor可以看做是图像上很多固定大小与宽高的方框,由于需要检测的物体本身也都是一个个大小宽高不同的方框,因此Faster RCNN将Anchor当作强先验的知识,接下来只需要将Anchor与真实物体进行匹配,进行分类与位置的微调即可。相比没有Anchor的物体检测算法,这样的先验无疑降低了网络收敛的难度,再加上一系列的工程优化,使得Faster RCNN达到了物体检测中的一个高峰。
Faster RCNN总览
jwyang/faster-rcnn.pytorch
从功能模块来讲,Faster RCNN算法的基本流程主要包括4部分:特征提取网络、RPN模块、RoI Pooling(Region of Proposal)模块与RCNN模块,虚线内表示仅仅在训练时才有的步骤。

- 特征提取网络Backbone
输入图像首先经过Backbone得到特征图,以VGGNet为例,假设输入图像的维度为3x600x800,由于VGGNet包含4个Pooling层(物体检测使用VGGNet时,通常不使用第5个Pooling层),下采样率为16,因此输出的feature map的维度为512x37x50。 - RPN模块
区域生成模块,如上图中间部分,其作用是生成较好的建议框架,即Proposal,这里用到了强先验的Anchor。RPN包含5个子模块:- Anchor生成:RPN对feature map上的每一个点都对应了9个Anchors,因此可以利用1x1的卷积在feature map上得到每一个Anchor的预测得分与预测偏移值。
- 计算RPN loss:这一步只在训练中,将所有的Anchors与标签进行匹配,匹配程度较好的Anchors赋予正样本,较差的赋予负样本,得到分类与偏移的真值,与第二步中的预测得分与预测偏移值进行loss的计算。
- 生成Proposal:利用第二步中每一个Anchor预测的得分与偏移量,可以进一步得到一组较好的Proposal,送到后续网络中。
- 筛选Proposal得到RoI:在训练时,由于Proposal数量还是太多(默认是2000),需要进一步筛选Proposal得到RoI(默认数量是256)。在测试阶段,则不需要此模块,Proposal可以直接作为RoI,默认数量为300。
- RoI Pooling模块
承上启下,接受卷积网络提取的feature map和RPN的RoI,输出送到RCNN网络中。由于RCNN模块使用了全连接网络,要求特征的维度固定,而每一个RoI对应的特征大小各不相同,无法送人到全连接网络,因此RoI Pooling将RoI的特征池化到固定的维度,方便送到全连接网络中。 - RCNN模块
将RoI Pooling得到的特征送人全连接网络,预测每一个RoI的分类,并预测偏移量以精修边框位置,并计算损失,完成整个Faster RCNN过程。主要包含3部分:- RCNN全连接网络:将得到的固定维度的RoI特征接到全连接网络中,输出为RCNN部分的预测得分与预测回归偏移量。
- 计算RCNN的真值:对于筛选出的RoI,需要确定是正样本还是负样本,同时计算与对应真实物体的偏移量。在实际实现时,为实现方便,这一步往往与RPN最后筛选RoI那一步放到一起。
- RCNN loss:通过RCNN的预测值与RoI部分的真值,计算分类与回归loss。
从整个过程可以看出,Faster RCNN是一个 两阶的算法,即RPN与RCNN,这两步都需要计算损失,只不过前者还要为后者提供较好的感兴趣区域。
详解RPN
RPN部分的输入输出:
- 输入:feature map、物体标签,即训练集中所有物体的类别与边框位置。
- 输出:Proposal、分类Loss、回归Loss,其中,Proposal作为生成的区域,供后续模块分类与回归两部分损失用作优化网络。

RPN整体理解:
-
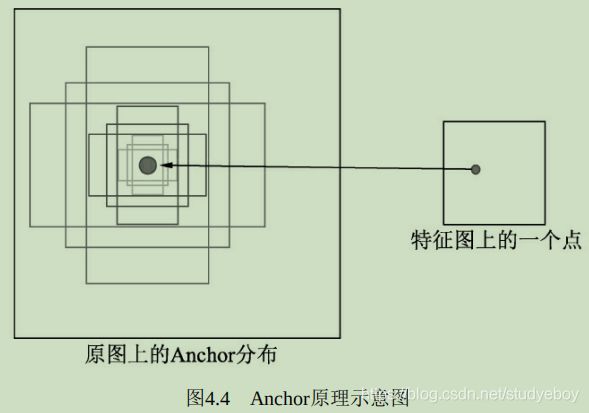
理解Anchor
Faster RCNN先提供一些先验的边框,然后再去筛选与修正,这样在Anchor的基础上做物体检测要比从无到有的直接拟合物体边框容易一些。
Anchor的本质是在原图大小上的一系列的矩形框,但Faster RCNN将这一系列的矩形框和feature map进行了关联。具体做法是,首先对feature map进行3x3的卷积操作,得到的每一个点的维度是512维,这512维的数据对应着原始图片上的很多不同的大小与宽高区域的特征,这些区域的中心点都相同。如果下采样率为默认的16,则每一个点的坐标乘以16即可得到对应的原图坐标。
为适应不同物体的大小与宽高,默认在每一个点上抽取了9种Anchors,具体Scale为{8, 16, 32},Ratio为{0.5, 1, 2},将这9种Anchors的大小反算到原图上,季的第不同的原始Proposal。由于feature map大小为37x50,因此一共有37x50x9=16650个Anchors。通过分类网络与回归网络得到每一个Anchor的前景背景概率和偏移量,前景背景概率用来判断Anchor是前景的概率,回归网络则是将偏移量作用到Anchor上是的Anchor更接近于真实物体坐标。

-
RPN的真值与预测量
对于物体检测任务,模型需要预测每一个物体的类别及其出现的位置,即类别、中心点坐标x与y、宽w与高h这5个量。由于有Anchor这个先验框,RPN可以预测Anchor的类别作为预测边框的类别,并且可以预测真实的边框相对于Anchor的偏移量,而不是直接预测边框的中心点坐标x与y、宽高w与h。
如下图所示,输入图像中有3个Anchors与两个标签,从位置来看,Anchor A、C分别和标签M、N有一定的重叠,而Anchor B位置更像是背景。

- 模型的真值(类别的真值)。
对于类别的真值,由于RPN只负责区域生成,保证recall,而没必要细分每一个区域属于哪一个类别,因此只需要前景背景两个类别,前景即有物体,背景则没有物体。
RPN通过计算Anchor与标签的IOU来判断一个Anchor是属于前景还是背景。IOU的含义是两个框的公共部分占所有部分的比例,即重合比例。
I o U ( A , M ) = A ∩ B A ∪ B IoU(A,M)=\frac{A\cap B}{A \cup B} IoU(A,M)=A∪BA∩B
当IOU大于一定值时,该Anchor的真值为前景,低于一定值时,该Anchor的真值为背景。 - 偏移量的真值。
设Anchor A的中心坐标为 x a x_a xa与 y a y_a ya,宽高分别为 w a w_a wa与 h a h_a ha,标签M的中心坐标为 x x x与 y y y,宽高分别为 w w w与 h h h,则对应的偏移真值计算公式为:
{ t x = ( x − x a ) / w a t y = ( y − y a ) / h a t w = l o g ( w w a ) t h = l o g ( h h a ) \begin{cases} t_x = (x-x_a)/w_a \\ t_y = (y-y_a)/h_a \\ t_w = log(\frac{w}{w_a}) \\ t_h = log(\frac{h}{h_a}) \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧tx=(x−xa)/waty=(y−ya)/hatw=log(waw)th=log(hah)
位置偏移 t x t_x tx与 t y t_y ty利用了宽与高进行了归一化,而宽高偏移 t w t_w tw与 t h t_h th进行了对数处理,这样的好处是进一步限制了偏移量的范围,便于预测。
RPN需要预测每一个Anchor属于前景与背景的概率,同时也需要预测真实物体相对于Anchor的偏移量,记为 t x ∗ 、 t y ∗ 、 t w ∗ 、 t h ∗ t_x^*、t_y^*、t_w^*、t_h^* tx∗、ty∗、tw∗、th∗。在得到预测偏移量后,可以根据下面的公式量预测偏移量作用到对应的Anchor上,得到预测框的实际位置 x ∗ 、 y ∗ 、 w ∗ 、 h ∗ x^*、y^*、w^*、h^* x∗、y∗、w∗、h∗。
{ t x ∗ = ( x ∗ − x a ) / w a t y ∗ = ( y ∗ − y a ) / h a t w ∗ = l o g ( w ∗ w a ) t h ∗ = l o g ( h ∗ h a ) \begin{cases} t_x^* = (x^*-x_a)/w_a \\ t_y^* = (y^*-y_a)/h_a \\ t_w^* = log(\frac{w^*}{w_a}) \\ t_h^* = log(\frac{h^*}{h_a}) \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧tx∗=(x∗−xa)/waty∗=(y∗−ya)/hatw∗=log(waw∗)th∗=log(hah∗)
如果没有Anchor,做物体检测需要直接预测每个框的坐标,由于框的坐标变换幅度大,使网络很难收敛于准确预测,而Anchor相当于提供了一个先验的阶梯,使得模型去预测Anchor的偏移量,即可更好的接近真实物体。
- 模型的真值(类别的真值)。
-
RPN卷积网络
为了实现上述的预测,RPN搭建了如下所示的网络结构。具体实现时,在feature map上首先用3x3的卷积进行更深的特征提取,然后利用1x1的卷积分别实现分类网络和回归网络。
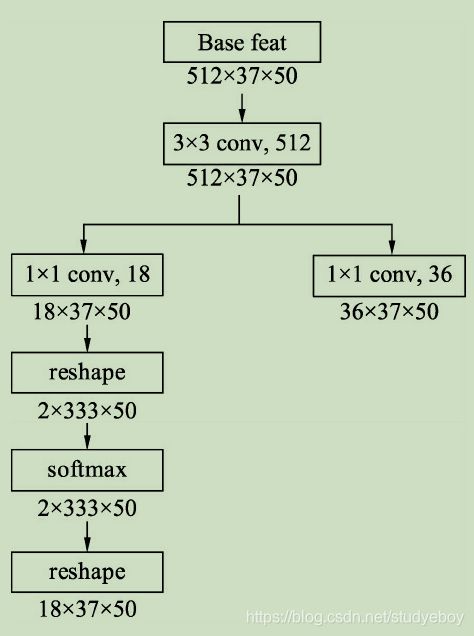
在物体检测中,通常将有物体的位置称为前景,没有物体的位置称为背景。在分类网络分支中,首先使用1x1卷积输出18x37x50的特征,由于每个点默认有9个Anchors,并且每个Anchor只预测其属于前景还是背景,因此通道数为18。利用torch.view()函数将特征映射到2x333x75,这样第一维仅仅是一个Anchor的前景背景得分,并送到Softmax函数中进行概率计算,得到的特征再变换到18x37x50的维度,最终输出的是每个Anchor属于前景与背景的概率。
在回归分支中,利用1x1卷积输出36x37x50的特征,第一维的36包含9个Anchor的中心点横纵坐标及宽高这4个量相对于真值的偏移量。RPN的网络部分代码如下:def forward(self, base_feat, im_info, gt_boxes, num_boxes): #输入数据的第一维是batch值 batch_size = base_feat.size(0) #首先利用3x3卷积进一步融合特征 rpn_conv1 = F.relu(self.RPN_Conv(base_feat), inplace=True) #利用1x1卷积得到分类网络,每个点代表Anchor的前景背景得分 rpn_cls_score = self.RPN_cls_score(rpn_conv1) #利用reshape与softmax得到Anchor的前景背景概率 rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2) rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshpae, 1) rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, 18) #利用1x1卷积得到回归网络,每一点代表Anchor的偏移 rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1) -
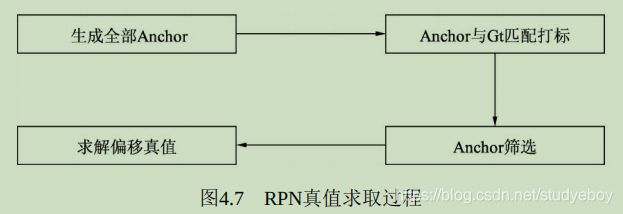
RPN真值的求取
RPN分类与回归网络得到的是模型的预测值,为了计算预测的损失,还乤得到分类与偏移预测的真值,具体指的是每一个Anchor是否对应这真实物体,以及每一个Anchor对应物体的真实偏移值。
-
Anchor生成
与前面Anchor 的生成过程一样,可以得到37x50x9=16650个Anchor。按照这种方式生成的Anchor会有一些边界在图像边框外,因此需要把这部分超过图像边框的Anchor过滤掉。def forward(self, input): ...... #利用Numpy首先得到原图上 中心点坐标,并利用contiguous保证内存连续 shifts = torch.from_numpy(np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose()) shifts = shifts.contiguous().type_as(rpn_cls_score).float() ...... #调用基础Anchor生成所有Anchors self._anchors = self._anchors.type_as(gt_boxes) all_anchors = self._anchors.view(1, A, 4) + shifts.view(K, 1, 4) ...... #保留边框内的Anchors inds_inside = torch.nonzero(keep).view(-1) anchors = all_anchors[inds_inside, :] -
Anchor与标签的匹配
为了计算Anchor的损失,在生成Anchor之后,还需要得到每个Anchor的类别,由于RPN的作用是建议框生成,而非详细的分类,因此只需要区分正样本与负样本,即每个Anchor是属于正样本还是负样本。
计算每一个Anchor与每一个标签的IOU,会得到一个IOU矩阵,具体的判断标准如下:- 对于任何一个Anchor,与所有标签的最大IoU小于0.3,则视为负样本。
- 对于任何一个标签,与其有最大IoU的Anchor视为正样本。
- 对于任何一个Anchor,与所有标签的最大IOU大于0.7,则视为正样本。
def forward(self, input): #生成标签向量,对应每一个Anchor的状态,1为正,0为负,初始化为-1 labels = gt_boxes.new(batch_size, inds_inside.size(0)).fill_(-1) #生成IoU矩阵,每一行代表一个Anchor,每一列代表 标签 overlaps = bbox_overlaps_batch(anchors, gt_boxes) #对每一行求最大值,返回的第一个为最大值,第二个为最大值的位置。 max_overlaps, argmax_overlaps = torch.max(overlaps, 2) #对每一列取最大值,返回的是每一个标签对应的IoU 最大值 gt_max_overlaps,_ = torch.max(overlaps, 1) #如果一个Anchor最大的IOU小于0.3,视为负样本 labels[max_overlaps < 0.3] = 0 #与所有Anchors的最大IOU为0的标签要过滤掉 gt_max_overlaps[gt_max_overlaps == 0] = 1e-5 #将与标签有最大IoU的Anchor赋予正样本 keep = torch.sum(overlaps.eq(gt_max_overlaps.view(batch_size, 1, -1).expand_as(overlaps)), 2) if torch.sum(keep) > 0: labels[keep > 0] = 1 #如果一个Anchor最大的IOU大于0.7,视为正样本 labels[max_overlaps >= 0.7] = 1 -
Anchor的筛选
由于Anchor的总数量接近于2万,并且大部分Anchor的标签都是背景,如果都计算损失的话则正、负样本失去了均衡,不利用网络的收敛。RPN默认选择256个Anchors进行损失的计算,其中最多不超过128个的正样本。如果数量超过了限定值,则进行随机选取。这里的256和128可以根据实际情况进行调整。def forward(self, input): for i in range(batch_size): #如果正样本数量太多,则进行下采样随机选取 if sum_fg[i] > 128: fg_inds = torch.nonzeros(labels[i] == 1).view(-1) rand_num = torch.from_numpy(np.random.permutaion(fg_inds.size(0))).type_as(gt_boxes).long() disable_inds = fg_inds[rand_num[:fg_inds.size(0) - num_fg]] labels[i][disable_inds] = -1 #负样本同上 -
求解回归偏移真值
回归部分的偏移量真值需要利用Anchor与对应的标签求解得到,得到的偏移量的真值后,将其保存在bbox_targets中。还需要求解两个权值矩阵bbox_inside_weights和bbox_outside_weights,前者用来设置正样本回归的权重,正样本设置为1,负样本设置为0,因为负样本对应的是背景,不需要进行回归;后者的作用是平衡RPN分类损失与回归损失的权重,在此设置为1/256。def forward(self, input): #选择每一个Anchor对应最大IoU的标签进行偏移计算 bbox_targets = _compute_targets_batch(anchors, gt_boxes.view(-1, 5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5)) #设置两个权重向量 bbox_inside_weights[labels==1] = 1 num_examples = torch.sum(labels[i] >= 0) bbox_outside_weights[labels == 1] = 1.0 / examples.item() bbox_outside_weights[labels == 0] = 1.0 / examples.item()
-
-
损失函数设计

-
NMS与生成Proposal

-
筛选Proposal得到RoI
训练时生成的Proposal数量为2000个,仍然由很多背景框,完全可以针对Proposal进行进一步筛选,过程与RPN中筛选Anchor的过程类似,利用标签与Proposal构建IoU矩阵,通过与标签的重合程度选出256个正样本。- 筛选出更贴近真实物体的RoI,使送人到后续网络的物体正、负样本更均衡,避免了负样本过多,正样本过少的情况。
- 减少了送人后续全连接网络的数量,有效减少了计算量。
- 筛选Proposal得到ROI的过程中,由于使用了标签来筛选,因此也为每一个RoI赋予了正负样本标签,同时可以在此求得RoI变换到对应标签的偏移量,这样就求得了RCNN部分的真值。
具体实现时,首先计算Proposal与所有的物体标签的IOU矩阵,然后根据IoU矩阵的值来筛选出符合条件的正负样本。筛选标准如下:
- 对于任何一个Proposal,其与所有标签的最大IoU如果大于等于0.5,则视为正样本。
- 对于任何一个Proposal,其与所有标签的最大IoU如果大小等于0且小于0.5,则视为负样本。
RoI Pooling层
上述步骤得到每一个RoI对应的类别与偏移量真值,为了计算损失,还需要计算每一个RoI的预测量。
VGGNet网络提供了整张图像的feature map,因此可以利用feature map,将每一个RoI区域对应的特征提取出来,然后接入一个全连接网络,分别预测其RoI的分类与偏移量。
由于RoI是由各种大小宽高不同的Anchors经过偏移修正、筛选等过程生成的,因此其大小不一且带有浮点数,然而后续相连的全连接网络要求输入特征大小维度固定,这就需要有一个模块,能够把各种维度不同的RoI变换到维度相同 特征,以满足后续全连接网络的要求,于是RoI Pooling就产生了。
对RoI进行池化的思想在SPPNet中就已经出现,只不过在Fast RCNN中提出的RoI Pooling算法利用了最近邻插值算法将池化过程进行了简化,而在随后的MaskRCNN中进一步提出了RoI Align的算法,利用双线性插值,进一步提升了算法精度。
假如当前RoI大小为332x332,使用VGGNet的全连接层,其所需的特征向量维度为512x7x7,由于目前的特征图通道数为512,Pooling的过程就是如何获得7x7大小区域的特征。
- RoI Pooling简介
假设当前的RoI图像的边框大小为332x332,为了得到这个RoI的特征图,首先需要将该区域映射到全图的特征图上,由于上下采样率为16,因此该区域在特征图上的坐标直接除以16并取整,而对应的大小为332/16=20.75。在此,RoI Pooling的做法是直接将浮点数量化为整数,取整为20x20,也就得到了该RoI的特征,即图中第3步的边框。
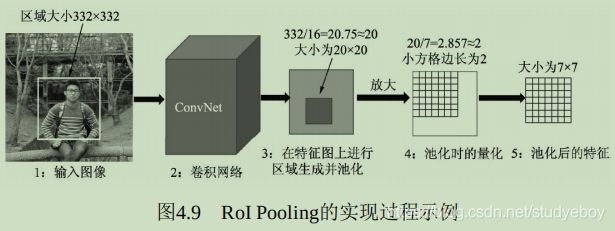
下一步还要将该20x20区域处理为7x7的特征,然而20/7=2.857,再次出现点数,RoI Pooling的做法是再次量化取整,将2.857取整为2,然后以2为步长从左上角开始选取出7x7的区域,这样每个小方格在特征图上都对应2x2的大小,如图中第4步所示。
最后,去每个小方格内的最大特征值,作为这个小方格的输出,最终实现了7x7的输出,也完成了池化的过程,如图中第5步所示。
从实现过程中可以看到,RoI本来对应于20.75x20.75的特征区域,最后只取了14x14的区域,因此RoI Pooling算法虽然简单,但量化取整带来的偏差势必会影响网络,尤其是回归物体位置的准确率。 - RoI Align简介
RoI Align的思想是使用双线性插值获得坐标为浮点数的点的值,依然将RoI对应到特征图上,但坐标与大小都保留着浮点数,大小为20.75x20.75,不做量化。
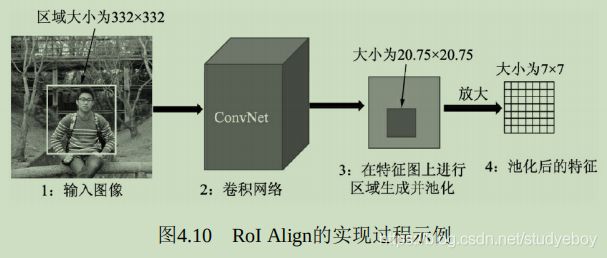
将特征图上的20.75x20.75大小均匀分成7x7方格的大小,中间的点依然保留浮点数。在此选择其中2x2方格为例,在每一个小方格内的特定位置选取4个采样点进行特征采样,如下图所示在每个小方格选择了4个小黑点,然后对这4个小黑点的值选择最大值,作为这个方格最终的特征。
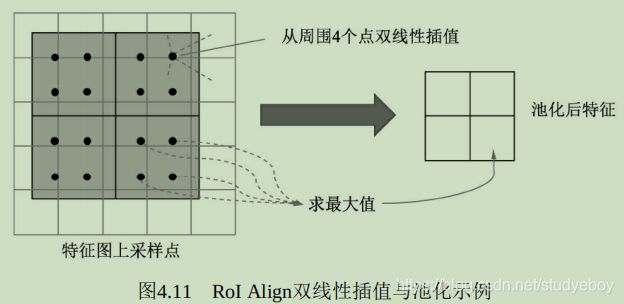
对于黑点的位置,可以将小方格平均分成2x2的4份,然后这4份更小单元的中心可以作为小黑点的位置。至于如何计算这4个小黑点的值,RoI Align使用了双线性插值的方法。小黑点周围会有特征图上的4个特征点,利用这4个特征点双线性插值出该黑点的值。
由于Align算法最大可能的保留了原始区域的特征,因此Align算法对检测性能有显著的提升,尤其是对于受RoI Pooling影响大的情形,如本身特征区域较小的物体,改善更为明显。
全连接RCNN模块
在经过RoI Pooling层之后,特征被池化到了固定的维度,因此接下来可以利用全连接网络进行分类与回归预测量的计算。在训练阶段,最后需要计算预测量与真值的损失并反传优化,而在前向测试阶段,可以直接将预测量加到RoI上,并输出预测量。
- RCNN全连接网络
256个RoI经过池化之后得到固定维度为512x7x7的特征,在此首先将这三个维度延展为一维,因为全连接网络需要将一个RoI的特征全部连接起来。
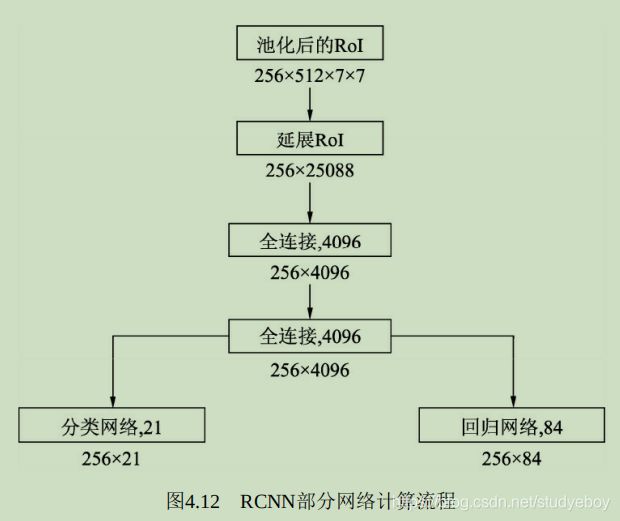
利用VGGNet的两个全连接层,得到长度为4096的256个RoI特征。为了输出类别与回归的预测,将上述特征分别接入分类与回归的全连接网络。默认为21类物体,因此分类网络输出维度为21,回归网络则输出每一个类别下的4个位置偏移量,因此输出维度为84。
虽然是256个RoI放到了一起计算,但相互之间是独立的,并没有使用到共享特征,因此造成了重复计算,这是Faster RCNN的一个缺点。 - 损失和函数设计
RCNN部分的损失 计算方法与RPN部分相同,不再重复。只不过在此21个类别的分类,而RPN部分则是二分类,需要注意回归时至多有64个正样本参与回归计算,负样本不参与回归计算。
Faster RCNN改进算法
-
审视Faster RCNN
- 性能优越:Faster RCNN通过两阶网络与RPN,实现了精度较高的物体检测性能。
- 两阶网络:相比其他一阶网络,两阶更为精准,尤其是针对高精度、多尺度以及小物体问题上,两阶网络优势更为明显。
- 通用性与鲁棒性:Faster RCNN在多个数据集即物体任务上效果都很好,对于个人数据集,往往Fine-tune后就能达到较好的效果。
- 可优化点很多:Faster RCNN的整个算法框架中可以进行优化的点很多,提供了广阔的算法优化空间。
- 代码全面:各大深度学习框架都有较好的Faster RCNN源码实现,使用方便。
Faster RCNN的缺点及改进方向:
- 卷积提取网络:无论是VGGNet还是ResNet,其特征图仅仅是单层的,分辨率通常较小,这些都不利于小物体及多尺度的物体检测,因此多层融合的特征图、增大特征图的分辨率等都是可以优化的方向。
- NMS:在RPN产生Proposal时为了避免重叠的框,使用了NMS,并以分类得分为筛选标准。但NMS本身的过滤对于遮挡物体不是特别友好,本身属于两个物体的Proposal有可能因为NMS而过滤为1个,造成漏检,因此改进优化NMS是可以带来检测性能提升的。
- RoI Pooling:Faster RCNN的原始RoI Pooling两次取整带来了精度的损失,因此后续Mask RCNN针对此Pooling进行了改进,提升了定位的精度。
- 全连接:原始Faster RCNN最后使用全连接网络,这部分全连接网络占据了网络的大部分参数,并且RoI Pooling后每一个RoI都要经过一遍全连接网络,没有共享计算,而如今全卷积网络是一个发展趋势,如何取代这部分全连接网络,实现更轻量的网络是需要研究的方向。
- 正负样本:在RPN及RCNN部分,都是通过超参数来限制正、负样本的数量,以保证正、负样本的均衡。而对于不同任务与数据,这种正、负样本均衡方法是否都是最有效的,也是一个研究的方向。
- 两阶网络:Faster RCNN的RPN与RCNN两个阶段分工明确,带来了精度的提升,但速度相对较慢,实际实现上还没有达到实时。因此,网络阶数也是一个值得探讨的问题,如单阶是否可以使网络的速度更快,更多阶的网络是否可以进一步提升网络的精度等。
-
特征融合:HyperNet
卷积神经网络的特点是,深层的特征体现了强语义特征,有利于进行分类与识别,而浅层的特征分辨率高,有利于进行目标的定位。原始的Faster RCNN方法仅仅利用了单层的feature map(例如VGGNet的conv5-3),对于小尺度目标的检测较差,同时高IoU阈值时,边框定位的精度也不高。
HyperNet方法认为单独一个feature map层的特征不足以覆盖RoI的全部特性,因此提出了一个精心设计的网络结构,融合了浅、中、深3个层次的特征,取长补短,在处理好区域生成的同时,实现了较好的物体检测效果。
HyperNet提出的特征提取网络结构如上图所示,以VGGNet作为基础网络,分别从第1/3/5个卷积组后提取特征,这3个特征分别对应着浅层、中层与深层的信息。然后,对浅层的特征进行最大化池化,对深层的特征进行反卷积,使得二者的分辨率都为原图大小的1/4,与中层的分辨率相同,方便进行融合。得到3个特征图后,再接一个5x5的卷积以减少特征通道数,得到通道数为42的特征。
在三层的特征融合前,需要先经过一个LRN(Local Response Normalization)处理,LRN层借鉴了神经生物 中的侧抑制概念,即激活的神经元抑制周围的神经元,在此的作用是增加泛化能力,做平滑处理。
最后将特征沿着通道数维度拼接到一起,3个通道数为42的特征拼接一起后形成通道数为126的特征,作为最终输出。
HyperNet融合了多层特征的网络有如下3点好处:- 深层、中层、浅层的特征融合到一起,优势互补,利于提升检测精度。
- 特征图分辨率为1/4,特征细节更加丰富,利于检测小物体。
- 在区域生成与后续预测前计算好了特征,没有任何的冗余计算。
HyperNet实现了一个轻量化网络来实现候选区域生成。具体方法是,首先在特征图上生成3万个不同大小与宽高的候选框,经过RoI Pooling获得候选框的特征,再接卷积及相应的分类回归网络,进而可以得到预测值,结合标签就可以筛选出合适的Proposal。可以看出,这里的实现方法与Faster RCNN的RPN方法很相似,只不过先进行了RoI Pooling,再选择候选区域。
HyperNet后续的网络与Faster RCNN也基本相同,接入全连接网络完成最后的分类与回归。不同的地方是,HyperNet先使用了一个卷积降低通道数,并且Dropout的比例从0.5调整到了0.25。
由于提前使用了RoI Pooling,导致众多候选框特征都要经过一遍此 Pooling层,计算量较大,为了加速,可以在Pooling前使用一个3×3卷积 降低通道数为4,这种方法在大幅度降低计算量的前提下,基本没有精 度的损失。
总体来看,HyperNet最大的特点还是提出了多层融合的特征,因 此,其检测小物体的能力更加出色,并且由于特征图分辨率较大,物体 的定位也更精准。此外,由于其出色的特征提取,HyperNet的Proposal 的质量很高,前100个Proposal就可以实现97%的召回率。
值得注意,HyperNet使用到了反卷积来实现上采样,以扩大尺寸。 通常来讲,上采样可以有3种实现方法:双线性插值、反池化 (Unpooling)与反卷积。反卷积也叫转置卷积,但并非正常卷积的完 全可逆过程。具体实现过程是,先按照一定的比例在特征图上补充0, 然后旋转卷积核,再进行正向的卷积。反卷积方法经常被用在图像分割 中,以扩大特征图尺寸。 -
实例分割:Mask RCNN
Mask RCNN的网络 与Faster RCNN非常类似,但有3点区别:- 在基础网络中采用了较为优秀的ResNet-FPN结构,多层特征有利于多尺度物体及小物体的检测。
- 提出了RoI Align方法来替代RoI Pooling,原因是RoI Pooling的取整做法损失了一些精度,而这对于分割任务来说较为致命。
- 得到感兴趣区域的特征后,在 分类与回归的基础上,增加了一个Mask分支来预测每一个像素的类别。

网络结构详细介绍:
-
特征提取网络
ResNet的FPN基础网络是一个多层特征结合的结构,包含了自下而上、自上而下及横向连接3个部分,这种结构可以将浅层、中层、深层的特征融合起来,使得特征同时具备语义性与强空间性。
原始的FPN会 P2、P3、P4与P5,4个阶段的特征图,但在Mask RCNN中又增加了一个P6。将P5进行最大值池化即可得到P6,目的是获得更大感受野的特征,该阶段仅仅用在RPN网络中。从合适尺度的特征图中切出RoI,大的RoI对应到高语义的特征图中,如P5,小的RoI对应到高分辨率的特征图中,如P3。这样的分配方法保证了大的RoI从高语义的特征图上产生,有利于检测大尺度物体,小的RoI 高分辨率的特征图上产生,有利于小物体的检测。

-
RoI Align部分
Faster RCNN原始使用的RoI Pooling存在两次取整的操作,导致RoI选取出的特征与 最开始回归出的位置有一定的偏差,称之为不匹配问题,严重影响了检测或者分割的准确度。
RoI Align取消了取整操作,而是保留所有的浮点,然后通过双线性插值的方法获得多个采样点的值,再将多个采样点进行最大值的池化,即可得到该点最终的值。
由于使用了采样点与保留浮点的操作,RoI Align获得了更好的性能。 -
损失任务设计
得到感兴趣区域的特征后,Mask RCNN增加了Mask分支来进行图像分割,确定每一个像素具体属于哪一个类别。具体实现时,采用了FCN的网络结构,利用卷积与反卷积构建端到端的网络,最后对每一个像素分类,实现了较好的分割效果。

-
全卷积网络:R-FCN
Faster RCNN在RoI Pooling后采用了全连接网络来得到分类与回归的预测,这部分全连接网络占据了整个网络结构的大部分参数,而目前越来越多的全卷积网络证明不使用全连接网络效果会更好,以适应各种输入尺度的图片。
如果直接去掉RoI Pooling后的全连接,直接连接到分类与回归的网络中,通过实验发现这种方法检测的效果很差,因为基础的卷积网络是针对分类设计的,具有平移不变性,对位置不敏感,而物体检测对位置敏感。
FCN算法(Region-based Fully Convolutional Networks)利用位置敏感得分图(position-sensitive score maps)实现了对位置的敏感,并且采用了全卷积网络,大大减少了网络的参数量。
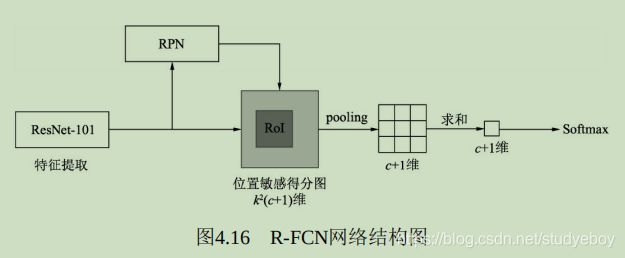
首先R-FCN采用了ResNet-101网络 Backbone,并在原始的100个卷积层后增加了一个1x1卷积,将通道数降低为1024。
为了增大后续特征图的尺寸,R-FCN将ResNet-101的下采样率从32降到了16。在第5个卷积组里将卷积的步长从2变为1,同时在这个阶段的卷积使用空洞数为2的空洞卷积以扩大感受野。降低步长增加空洞卷积可以在保持特征图尺寸的同时,增大感受野。
在特征图上进行1x1卷积,可以得到位置敏感图,其通道数为 k 2 ( c + 1 ) k^2(c+1) k2(c+1)。c代表物体类别,需要再加上背景这一类别。k的含义是将RoI划分为 k 2 k^2 k2个区域。
在RPN提供一个感兴趣区域后,对应到位置敏感得分图上,首先将RoI划分为kxk个网格,在Pooling时首先选取其所在区域的对应位置的特征,最终形成一个c+1维的kxk特征图。
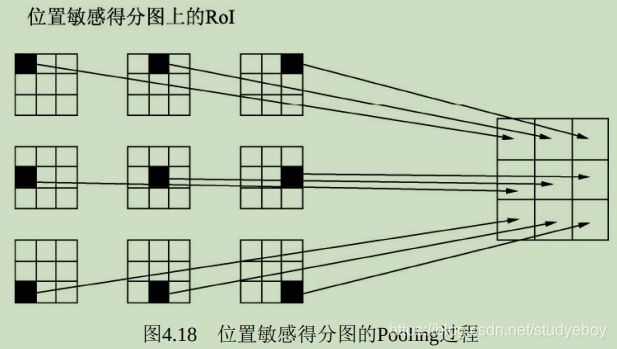
再对这个c+1维的kxk特征进行通道求和,即可得到c+1维的向量,最后进行softmax即可完成RoI的分类预测。
对于RoI的位置回归,则与分类很相似,只不过位置敏感得分图的通道数为 k 2 ( c + 1 ) k^2(c+1) k2(c+1),而回归的敏感回归图的通道数为 k 2 × 4 k^2\times 4 k2×4,安装相同的方法进行Pooling,可形成通道数为4的kxk特征,求和可得到1x4的向量,即为回归的预测。
由于R-FCN去掉了全连接层,并且整个网络都是共享计算的,因此速度很快。此外,由于位置敏感得分图的存在,引入了位置信息,因此R-FCN的检测效果也更好。 -
级联网络:Cascade RCNN
得到RoI后,Faster RCNN通过RoI与标签的IoU值来判断该RoI是正样本还是负样本,默认的IoU阈值为0.5,这个阈值是一个超参数,对于检测的精度有较大影响。
阈值越高,选出的RoI会更接近真实物体,检测器的定位会更加准确,但此时符合条件的RoI会变少,正、负样本会更加不均衡,容易导致训练过拟合;另一方面,阈值越低,正样本会更多,有利于模型训练,但这时误检也会增多,从而增大了分类的误差。
对于阈值的问题,通过实验可以发现两个现象:- 一个检测器如果采用某个阈值界定正负样本时,那么当输入Proposal的IoU在 这个阈值附近时,检测效果要比基于其他阈值时好,也就是很难让一个在指定阈值界定正负样本的检测模型对所有IoU的输入Proposal检测效果都最佳。
- 经过回归之后的候选框与标签之间的IoU会有所提升。
Cascade RCNN算法通过级联多个检测器来不断优化结果,每个检测器都基于不同的IoU阈值来界定正负样本,前一个检测器的输出作为后一个检测器 输入,并且检测器越靠后,IoU的阈值越高。
单阶多层检测器:SSD
对于物体检测任务,Faster RCNN算法采用两阶的检测架构,首先利用RPN网络进行感兴趣区域生成,然后再对该区域进行类别的分类与位置的回归,这种方法虽然提升了精度但是限制了检测速度,YOLO算法利用回归的思想,使用一阶网络直接完成了物体检测,速度快,但是精度明显下降。
SSD(Single Shot Multibox Detector)算法借鉴了Faster RCNN与YOLO的思想,在一阶网络的基础上使用了固定框架进行区域生成,并利用了多层的特征信息,在速度与检测精度上都有了一定的提升。
SSD的算法流程
算法流程如上图所示,输入图像首先经过VGGNet的基础网络,在此之后又增加了几个卷积层,然后利用3x3的卷积核在6个大小与深浅不同的特征层上进行预测,得到预选框的分类与回归预测值,最后直接预测出结果,或者求得网络损失。
- 数据增强:SSD在数据部分做了充分的数据增强工作,包括光学变换与几何变换等,极大限度的扩充了数据集的丰富性,从而有效提升了模型的检测精度。
- 网络骨架:SSD在原始VGGNet的基础上,进一步延伸了4个卷积模块,最深处的特征图大小为1x1,这些特征图具有不同弄的尺度与感受野,可以负责检测不同尺度的物体。
- PriorBox与多层特征图:与Faster RCNN类似,SSD利用了固定大小与宽高的PriorBox作为区域生成,但与Faster RCNN不同是,SSD不是只在一个特征图上设定预选框,而是在6个不同尺度上都设立预选框,并且在浅层特征图上设立较小的PriorBox来负责检测小物体,在深层特征图上设立较大的PriorBox来负责检测大物体。
- 正负样本的选取与损失计算:利用3x3的卷积在6个特征图上进行特征的提取,并分为分类与回归两个分支,代表所有预选框的预测值,随后进行预选框与真实框的匹配,利用IoU筛选出正样本与负样本,最终计算出分类损失与回归损失。
数据预处理
SSD的数据增强整体流程包括光学变换与几何变换两个过程。光学变换包括亮度和对比度等随机调整,可以调整图像像素值的大小,并不会改变图像尺寸;几何变换包括扩展、裁剪和镜像等操作,主要负责进行尺度上的变化,最后再进行去均值操作。大部分操作都是随机的过程,尽可能保证数据的丰富性。

网络架构
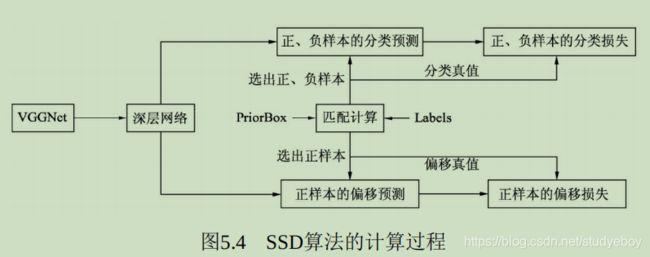
-
基础VGG结构
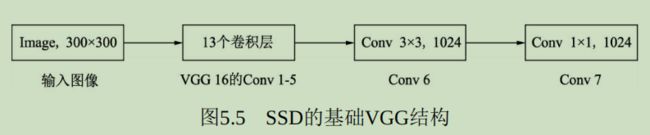
- 原始的VGG16的池化层统一大小为2x2,步长为2,在SSD中Conv5后接的Maxpooling层池化大小为3,步长为1,在增加感受野的同时,维持特征图的尺寸不变。
- Conv6中使用了空洞数为6 空洞卷积,其padding也为6,增加了感受野的同时保持参数量与特征图尺寸的不变。
-
深度卷积层

-
PriorBox与边框特征提取网络
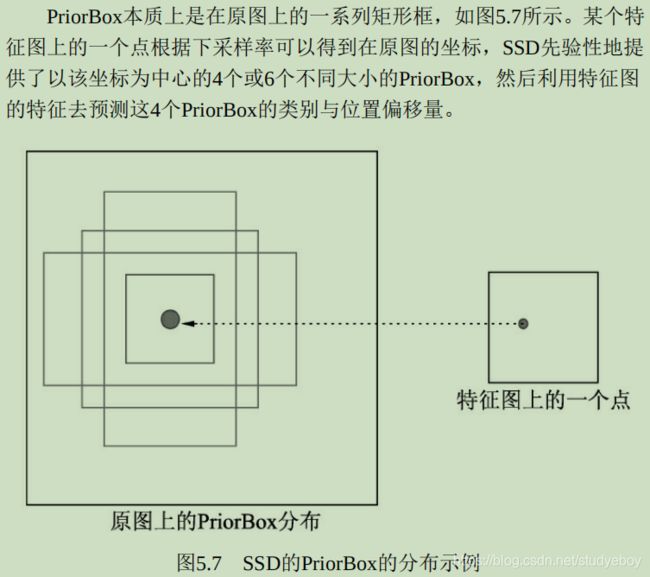



匹配与损失求解
通过卷积网络得到了所有PriorBox的预测值与边框位置,为了得到最终的结果,还需要进行边框的匹配及损失计算。首先按照一定的原则,对所有的PriorBox赋予正、负样本的标签,并确定对应的真实物体标签,以方便后续损失的计算;有了对应的真值后,即可计算框的定位损失,这部分只需要正样本即可;同时,为了克服正、负样本的不均衡,进行难样本挖掘,筛选出数量是正样本3倍的负样本;最后计算筛选出的正、负样本的类别损失,完成整个网络前向计算的全过程。
- 预选框与真实框的匹配
求得PriorBox坐标及对应的类别位置预测后,需要为每一个PriorBox贴标签,筛选出符合条件的正样本与负样本,以便进行后续的损失计算。处理匹配时遵循以下4原则:- 在判断正、负样本时,IoU阈值设置为0.5,即一个PriorBox与所有真实框的最大IoU小于0.5时,判断该框为负样本。
- 判断对应关系时,将PriorBox与其拥有最大IoU的真实框作为其位置标签。
- 与真实框有最大IoU的PriorBox,即使该IoU不是此PriorBox与所有真实框IoU中最大的IoU,也要将该Box对应到真实框上,这是为了保证真实框的Recall。
- 在预测边框位置时,预测相对于预选框的偏移量,因此在求得匹配关系后还需要进行偏移量计算。
- 定位损失的计算
完成匹配后,有了正、负样本及每一个样本对应的真实框,因此可以进行定位的损失计算。 - 难样本挖掘
完成正、负样本匹配后,由于一般情况下一张图片的物体数量不会超过100,因此会存在大量的负样本。如果这些负样本都考虑则在损失反传时,正样本能起到的作用就微乎其微了,因此需要进行难样本的挖掘,难样本是针对负样本而言的。
Faster RCNN通过限制正负样本的数量来保持正、负样本均衡,SSD通过保证正、负样本的比例来实现样本均衡。具体做法是:在计算出所有负样本的损失后进行排序,选取损失较大的那一部分进行计算,舍弃剩下的负样本,数量为正样本的3倍。 - 类别损失计算
得到筛选后的正、负样本后,可以进行类别的损失计算。使用交叉熵损失函数,并且正、负样本全部参与计算。
SSD的改进算法
SSD算法的优点:
- 由于利用了多层的特征图进行预测,因此虽然是一阶的网络,但在某些场景与数据集下,检测精度依然可以与Faster RCNN媲美。
- 一阶网络的实现,使得其检测速度可以超过同时期的Faster RCNN及YOLO算法,对于速度要求较高的工程应用场景,SSD是一个很不错的选择。
- 网络优雅,实现简单,没有太多的工程技巧,为后续的改善提供了很大的空间。
SSD算法的缺点:
- 对于小物体的检测效果一般,虽然使用了分辨率大的浅层特征图来检测小物体,但浅层的语义信息不足,无法很好的完成分类与回归的预测。
- 每一层PriorBox的大小与宽高依赖于人工设置,无法自动学习,当检测任务更换时,调试过程较为繁琐。
- 由于是一阶检测算法,分类与回归都只有一次,在一些追求高精度的场景下,SSD系列相较于Faster RCNN系列来讲,仍然处于下风。

-
特征融合:DSSD
SSD采用多尺度的特征图预测物体,具有较大感受野的特征图检测大尺度物体,较小感受野特征图检测小尺度物体。这样会存在一个问题,即当小感受野特征图检测小物体时,由于语义信息不足,导致小物体检测效果差。
解决该语义信息不足的方法通常是深浅的特征图融合,DSSD正是从这一角度出发,提出了一套针对SSD多尺度预测的特征融合方法,改进了传统的上采样方法,并且可以适用于多种基础Backbone结构。
对于深浅层的特征融合,通常有3种方法:- 按通道拼接(Concatenation):将深层与浅层的特征按通道维度进行拼接。
- 逐元素相加(Eltw Sum):将深层与浅层的每一个元素在对应位置进行相加,如FPN中的特征融合。
- 逐元素相乘(Eltw Product):将深层与浅层的每一个元素在对应位置进行相乘,这是DSSD采用的特征融合方式。
SSD利用了感受野与分辨率不同的6个特征图进行后续分类与回归网络的计算,DSSD保留了6个特征图,但对这6个特征图进一步进行了融合处理,然后将融合后的结果送人后续分类与回归网络。
具体的做法是,将深层的特征图直接用作分类与回归,接着,该特征经过一个反卷积模块,并与更浅一层的特征进行逐元素相乘,将输出的特征用于分类与回归计算。类似的,继续将该特征与浅层特征进行反卷积与融合,共计输出6个融合后的特征图,形成一个沙漏式的结构,最后给分类与回归网络做预测。
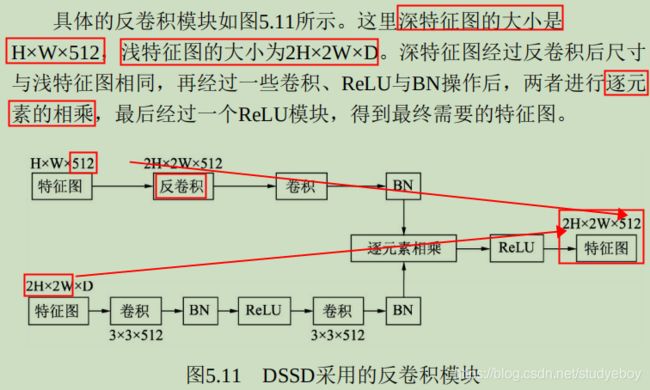
在得到特征图后,DSSD也改进了分类与回归预测模块。SSD的预测模块是直接使用3x3卷积,而DSSD则包含一个残差单元,主路和旁路进行逐元素相加,然后再接到分类与回归的预测模块中。
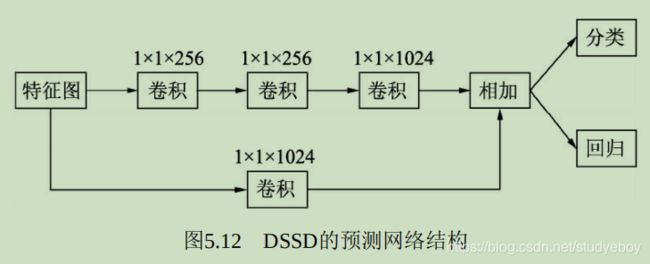
DSSD的算法将深层的特征融合到了浅层特征图中,提升了浅层特征的语义性,提升了模型的性能,尤其是对于小物体的检测。 -
彩虹网络:RSSD
RSSD要解决的SSD的两个问题:- 各个特征图只考虑当前层的检测尺度,没有考虑特征图之间的关联性,容易出现多个特征图上的预选框与一个真实框相匹配,即使有NMS后续操作,但也不能完全避免这种误检 情况。
- 小物体检测效果差:SSD主要利用浅层特征图检测小物体,但由于浅层的特征图语义信息太少,影响了对小物体的检测。
RSSD(Rainbow SSD)一方面利用分类网络增加了不同特征图之间的联系,减少了重复框的出现,另一方面提出了一种全新的深浅特征融合的方法,增加了特征图的通道数,大幅度提升了检测效果。
- 池化融合
对浅层的特征图进行池化,然后与下一个特征图进行通道拼接,作为下一层特征图的最终特征。类似的,依次向下进行通道拼接,这样特征图的通道数逐渐增加,并且融合了越来越多层的特征。这样的连接g 可以使得深层特征图既有高语义信息,又拥有浅层特征图传来的细节信息,可以提升检测效果。 - 反卷积融合
反卷积融合是对深层的特征图进行反卷积,扩充尺寸,然后与浅层的特征图进行通道拼接,并逐渐传递到最浅层,弥补了浅层的语义信息。 - 彩虹式融合
彩虹式融合结合了池化融合和反卷积融合,浅层特征通过池化层融合到深层中,深层特征通过反卷积融合到浅层中,这样就使每一个特征图的通道数是相同的。由于每一层都融合了多个特征图的特征,并且可以用颜色进行区分,因此被称为彩虹式融合。
由于每一层的特征图尺度不同,并且感受野也不同,因此在不同层融合之前,需要做一次BN操作,以统一融合时的每个层的尺度,从而达到均一化的效果。
RSSD在不明显增加计算量的基础上,融合了双向的特征信息,并且考虑了各个分类分支的关联性,使得模型的表达能力更强,在一定程度上提升了小物体的检测与物体的定位精度。 - 基于SSD的两阶:RefineDet
RefineDet结合了一阶网络与两阶网络的优点,在保持高效的前提下实现了精度更高的检测。
DefineDet在SSD的基础上,一方面引入了Faster RCNN两阶网络中边框由粗到细两步调整的思想,即先通过一个网络粗调固定框(在Faster RCNN中是Anchor,在SSD中是PriorBox),然后通过一个网络细调;另一方面采用了类似于FPN的特征融合方法,可以有效提高对小物体的检测效果。
RefineDet的网络结构主要由ARM(Anchor Refinement Module)、TCB(Transfer Connection Block)与ODM(Object Detection Module)这3个模块组成。
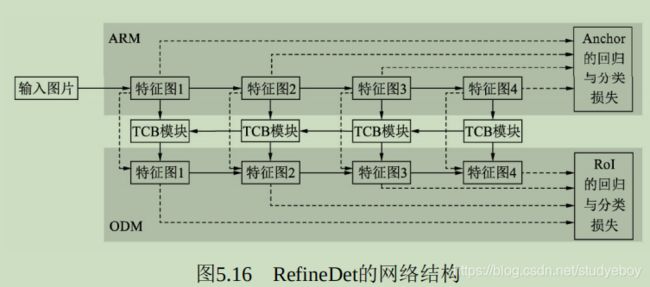
-
ARM部分
ARM部分首先经过一个VGG16或者ResNet-101的基础网络,然后在多个特征图上对应不同大小宽高的Anchors,并用卷积网络来提取这些Anchors的特征,进一步可以求得每一个Anchor的分类与回归损失。
ARM有两点作用:- 过滤掉一些简单的负样本,减少后续模型的搜索空间,也缓解了正、负样本不均衡的问题。
- 可以得到Anchor的预测值,因此可以粗略的修正Anchor的位置,为下一步模块提供比固定框更精准的感兴趣区域。
-
TCB部分
TCB模块主要用于完成特征的转换操作。TCB模块首先对ARM中的每一个特征图进行转换,然后将深层的特征图融合到浅层的特征图中。

-
ODM部分
ODM基本采取了SSD多层特征图的网络结构,与SSD相比,有两个优势:- 更好的特征图:相比SSD从浅到深的特征,ODM接收的是TCB模块深浅融合的特征,其信息更加丰富,质量更高。
- 更好的预选框:SSD使用了固定的预选框PriorBox,而ODM接收的则是经过ARM模块优化后的Anchor,位置更加精准,并且正、负样本更加均衡。
-
- 多感受野融合:RFBNet
RFBNet(Receptive Field Block Net)受人类视觉感知的启发,在原有的检测框架中增加了一些精心设计的模块,使得网络拥有更为强悍的表征能力,而不是简单的增加网络层数、融合等,因此获得了较好的检测速度与精度。
神经学发现,群体感受野的尺度会随着视网膜图的偏心而变化,偏心度越大的地方,感受野的尺度也越大。而在卷积网络中,卷积核的不同大小可以实现感受野的不同尺度,空洞卷积的空洞数也可以实现不同的偏心度。
RFBNet同时将感受野的尺度与偏心度纳入到卷积模块中,设计了RFB模块,RFB模块拥有3个 的分支,并且使用了1x1、3x3与5x5不同大小的卷积核来模拟不同的感受野尺度,使用了空洞数为1/3/5的空洞卷积来实现不同的偏心度。

完成3个分支后,再利用通道 拼接的方法进行融合,利用1x1的卷积降低特征的通道数。
单阶经典检测器: YOLO
Faster RCNN算法利用了两阶结构,先实现感兴趣区域的生成,再进行精细的分类与回归,虽出色的完成了物体检测任务,但也限制了其速度,在更追求速度的实际应用场景下,应用起来仍存在差距。
YOLO系列的算法用回归的思想,使用一阶网络直接完成了分类与位置定位两个任务,速度极快。加速了物体检测在工业界的应用,开辟了物体检测算法的另一片天地。
无锚框预测:YOLO v1
YOLOv1使用一阶结构完成了物体检测任务,直接预测物体的类别与位置,没有RPN网络,也没有类似于Anchor的预选框,因此速度很快。
-
网络结构
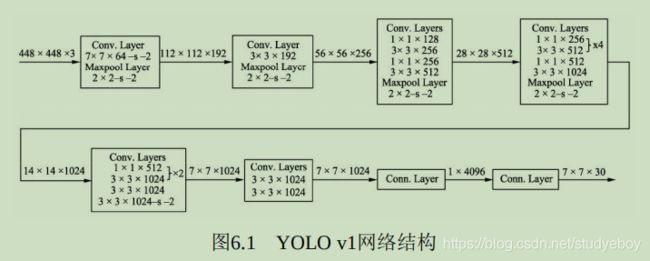
YOLO一利用了卷积神经网络进行了特征提取,该结构与GoogLeNet模型有些类似,在该结构中,输入图像 尺寸固定为448x448,经过24个卷积层与两个全连接层后,最后输出额特征图大小为7x7x30.- 在3x3卷积后通常会接一个通道数更低的1x1卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。
- 除了最后一层用了线性激活函数外,其余层的激活函数为Leaky ReLU.
- 在训练中使用了Dropout与数据增强的方法来防止过拟合。
-
特征图的意义
YOLO v1的网络结构并无太多创新之处,其精髓主要在最后7x7x30大小的特征图中。YOLO v1将输入图像划分成7x7的区域,每一个区域对应于最后特征图上的一个点,该点的通道数为30,代表了预测的30个特征。
YOLO v1在每一个区域内预测两个边框,这样整个图上一共预测7x7x2=98个框,这些边框大小与位置各不相同,基本上可以覆盖整个图上可能出现的物体。
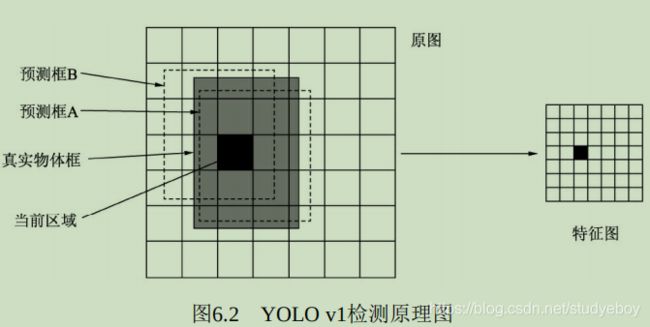
如果一个物体的中心落在了某个区域内,则该区域就负责检测该物体。将该区域的两个框与真实物体框进行匹配,IoU更大的框负责回归真实物体框。
最终的预测特征由类别概率、边框的置信度及边框的位置组成。
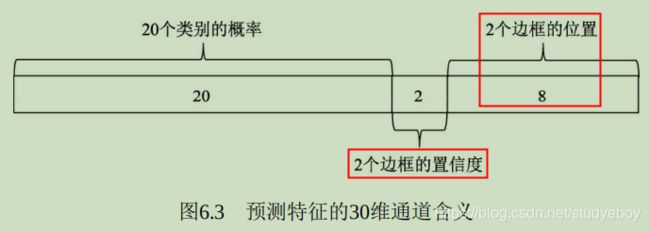
YOLO v1 并没有先验框,而是直接在每个区域预测框的大小与位置,是一个回归问题。这样做能够成功检测的原因在于,区域本身就包含了一定的位置信息,另外被检测物体的尺度在一个可以回归的范围内。
一个区域内的两个边框共用了一个类别预测,在训练时会选取与物体IoU更大的一个边框,在测试时会选取置信度更高的一个边框,另一个会被舍弃,因此整张图最多检测出49(7x7区域)个物体。
YOLO v1采用了物体类别与置信度分开的预测方法,这一点与Faster RCNN不同,Faster RCNN将背景也当作了一个类别,共计21种,在类别预测中包含了置信度的预测。 -
损失计算
通过卷积网络得到每个边框的预测值后,为了进一步计算网络训练的损失,还需要确定每一个边框是对应着真实物体还是背景框,即区分开正、负样本。
当一个真实物体的中心落在了某个区域内时,该区域就负责检测该物体。将与真实物体有最大IoU的边框设为正样本,这个区域的类别真值为该真实物体的类别,该边框的置信度真值为1.
除了上述被赋予正样本的边框,其余边框都为负样本。负样本没有类别损失与边框位置损失,只有置信度损失,其真值为0.

-
优点
YOLO v1利用了回归的思想,使用轻量化的一阶n概率同时完成了物体的定位与分类,处理速度极快,可以达到45FPS,当使用更轻量级的网络时甚至可以达到155FPS。 -
缺点
由于每一个区域默认只有两个边框做预测,并且只有一个类别,因此YOLO v1有检测限制,会导致模型对于小物体,以及靠的特别近的物体检测效果不好。
由于没有类似于Anchor的先验框,模型对于新的或者不常见宽高比例的物体检测效果不好。
由于下采样率较大,边框的检测精度不高。
在损失函数中,大物体的位置损失权重与小物体的位置损失权重是一样的,这会导致同等比例的位置误差,大物体的损失会比小物体大。小物体的损失在总损失中占比较小,会带来物体定位的不准确。
依赖锚框:YOLO v2
YOLO v2相比于YOLO v1预测更加准确,速度更快,识别的物体类别也更多。
-
网络结构的改善

YOLO v2对于基础网络结构进行多种优化,提出了一个全新的网络结构DarkNet。原始的DarkNet拥有19个卷积层与5个池化层,在增加了一个Passthrough层后一共有22个卷积层,精度与VGGNet相当,但浮点运算量只有VGGNet的1/5左右,因此速度极快。- BN层:DarkNet使用了BN层,有助于解决反向传播中的梯度消失与爆炸问题,可以加速模型的收敛,同时起到一定的正则化作用。BN在每一个卷积之后,激活函数LeakyReLU之前。
- 用连续3x3卷积代替了v1中的7x7卷积,减少了计算量,增加了网络深度,去掉了全连接层与Dropout层。
- Passthrough层:进行深浅层特征融合,将浅层26x26x512的特征变换为13x13x2048,直接与深层的13x13x1024的特征进行通道拼接。这种特征融合有利于小物体的检测。
- 由于YOLO v2在每一个区域预测5个边框,每个边框有25 预测值,因此最后输出的特征图通道数为125。其中,一个边框的25个预测值分别是20个类别预测、4个位置预测及一个位置置信度预测值。这里与v1有很大区别,v1是一个区域内的边框共享类别预测,而这里则是相互独立的类别预测值。
-
先验框的设计
YOLO v2吸收了Faster RCNN的优点,设置了一定数量的预选框,使得模型不需要直接预测物体尺度与坐标,只需要预测先验框到真实物体的偏移,降低了预测难度。
关于先验框,YOLO v2使用了聚类的算法来确定先验框的尺度,并且优化了后续的偏移计算方法。- 聚类提取先验框尺度
Faster RCNN中预选框(即Anchor)的大小与宽高是由人手工设计的,因此很难确定设计出的一组预选框是最贴合数据集的,也就有可能为模型性能带来负面影响。
YOLO v2通过在训练集上聚类来获得预选框,只需要设定预选框的数量k,就可以利用聚类算法得到最适合的k个框。在聚类时,两个边框之间的距离使用下面公式计算,即IoU越大,边框距离越近。

在衡量一组预选框的好坏时,使用真实物体与这一组预选框的平均IoU作为标准。
预选框的数量k越多,平均IoU会越大,效果会更好,但相应也会提升计算量,YOLO v2在速度与精度的权衡中选择了预选框数量为5. - 优化偏移公式




- 聚类提取先验框尺度
-
正、负样本与损失函数
正负样本的选取,首先将预测的位置偏移量作用到先验框上,得到预测框的真实位置。
如果一个预测框与所有真实物体的最大IoU小于一定阈值(默认为0.6)时,该预测框视为负样本。
每一个真实物体的中心点落在了某个区域内,该区域就负责检测该物体。将与该物体有最大IoU的预测框视为正样本。
确定正负样本后,计算网络损失。
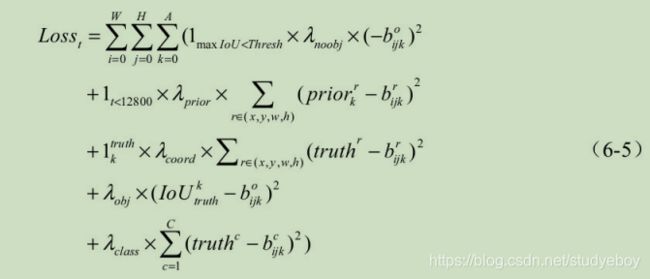

-
训练技巧
- 多尺度训练
YOLO v2 移除了全连接层,可以接受任意尺寸的输入图片,在训练阶段,为了使模型对于不同尺度的物体鲁棒,采取了多种尺度的图片作为训练的输入。
由于下采样率为32,为了满足整除的需求,选取的输入尺度集合为{320, 352, 384,……,608},这样训练出的模型可以预测多个尺度的物体。输入图片的尺度越大则精度越高,尺度越低则速度越快,多尺度训练出的模型可以适应多种不同的场景需求。 - 多阶段训练
- 利用DarkNet网络在ImageNet上预训练分类任务,图像尺度为 224×224。
- 将ImageNet图片放大到448×448,继续训练分类任务,让模型 首先适应变化的尺度。
- 去掉分类卷积层,在DarkNet上增加Passthrough层及3个卷积 层,利用尺度为448×448的输入图像完成物体检测的训练。
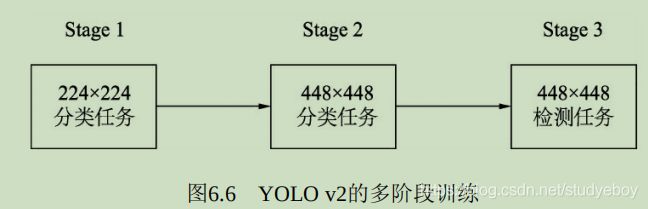
- 多尺度训练
-
优点
使用了先验框、特征融合等方法,同时利用 了多种训练技巧,使得模型在保持极快速度的同时大幅度提升了检测的 精度。 -
缺点
- 单层特征图:虽然采用了Passthrough层来融合浅层的特征,增强 多尺度检测性能,但仅仅采用一层特征图做预测,细粒度仍然不够,对 小物体等检测提升有限,并且没有使用残差这种较为简单、有效的结 构。
- 受限于其整体结构,依然没有很好地解决小物体的检测问题。
- 太工程化:YOLO v2的整体实现有较多工程化调参的过程,尤其 是后续损失计算有些复杂,不是特别“优雅”,导致后续改进与扩展空间 不足。
多尺度与特征融合:YOLO v3
YOLO v3吸收了当前优秀的检测框架的思想,如残差网络和特征融合等,称为DarkNet-53,但速度并没有之前的版本快,在保证实时性的前提下追求检测的精度。YOLO v3提供了一个更轻量化的网络tiny-DarkNet,在模型大小与速度上,实现了SOTA(state of art)的效果。
-
新网络结构DarkNet-53
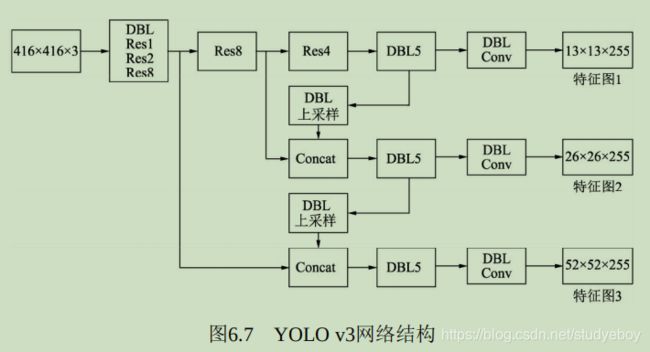
- DBL:代表卷积、BN及Leaky ReLU三层的结合,在YOLO v3中,卷积层都是以这样的组件出现的,构成了DarkNet的基本单元。DBL后面的数字代表有几个DBL模块。
- Res:代表残差模块,Res后面的数字代表哟几个串联的残差模块。
- 上采样:上采样使用的方式为池化,即元素复制扩充的方法使得特征尺寸扩大,没有学习参数。
- Concat:上采样后将深层与浅层的特征图进行Concat操作,即通道的拼接,类似于FPN,但FPN中使用的是逐元素相加。
DarkNet-53的新特性:
- 残差思想:DarkNet-53借鉴了ResNet的残差思想,在基础网络中大量使用了残差连接,因此网络结构可以设计的很深,并且缓解了训练中梯度消失的问题,使得模型更容易收敛。
- 多层特征图:通过上采样与Concat操作,融合了深、浅层的特征,最终输出了3种尺寸的特征图,用于后续预测。多层特征图对于多尺度物体及小物体检测是有利的。
- 无池化层:DarkNet没有采用池化的做法,而是通过步长 2的卷积核来达到缩小尺寸的效果,下采样次数同样是5次,总体下采样率为32 。
-
多尺度预测
YOLO v3输出了3个大小不同的特征图,从上到下分别对应深层、中层、浅层的特征。深层的特征图尺寸小,感受野大,有利于检测大尺度物体,而浅层的特征图则与之相反,更便于检测小尺度物体,类似于FPN结构。
YOLO v3依然使用了预选框Anchor,由于特征图数量不再是一个,因此匹配方法也要相应的进行改变。使用聚类的算法得到9种不同大小宽高的先验框,然后按照下表进行先验框的分配,这样,每一个特征图上的一个点只需要预测3个先验框,而不是YOLO v2中的5个。
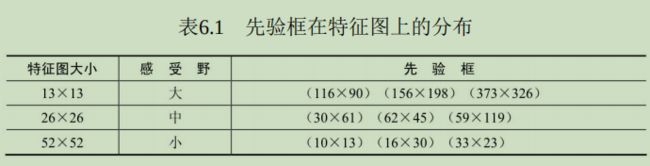
YOLO v3的基础网络更像是SSD与FPN的结合。YOLO v3默认使用了COCO数据集,一共有80个物体类别,因此一个先验框需要80维的类别预测值、4个位置预测及1个置信度预测,3个预测框一共需要3x(80+5)=255维,也就是每一个特征图的预测通道数。 -
softmax改为Logistic
Softmax函数输出的多个类别预测之间会相互抑制,只能预测出一个类别,而Logistic分类器相互独立,可以实现多类别的预测。 -
YOLO v3优缺点:
- 优点:速度快,通用性强,正样本生成过程较为严格,背景的误检率较低。
- 缺点:位置的准确性较差,召回率不高,对遮挡与拥挤情况,难以做到高精度。
模型加速—轻量化网络

- 轻量化设计:从模型设计时就采用一些轻量化的思想,例如采用深度可分离卷积、分组卷积等轻量卷积方式,减少卷积过程的计算量。利用全局池化来取代全连接层,利用1x1卷积实现特征的通道降维,也可以降低模型的计算量。
- BN层合并;在训练检测模型时,BN层可以有效加速收敛,并在一定程度上防止模型的过拟合,但是在前向测试时,BN层的存在也增加了多余的计算量。由于测试时BN层的参数已经固定,因此可以在测试时将BN层的计算合并到卷积层,从而减少计算量,实现模型加速。
- 网络剪枝:在卷积网络成千上万的权重中,存在着大量接近于0的参数,这些属于容易参数,去掉后模型也可以基本达到相同的表达能力,因此搜索网络中的冗余卷积核,将网络稀疏化,称之为网络剪枝。网络剪枝有训练中稀疏与训练后剪枝两种方法。
- 权重量化:是指将网络中高精度的参数量化为低精度的参数,从而加速计算的方法。高精度的模型参数拥有更大的动态变化范围,能够表达更丰富的参数空间,因此在训练中通常使用32位浮点数(单精度)作为网络参数的模型。训练完成后为了减小模型大小,通常可以将32位浮点数量化为16为浮点数的半精度,甚至是int8的整型、0与1的二值类型。典型的方法如Deep Compression。
- 张量分解:由于原始网络参数中存在大量的冗余,除了剪枝的方法外,还可以利用SVD分解和PQ分解等方法,将原始张量分解为低秩的若干张量,以减小卷积的计算量,提升前向速度。
- 知识蒸馏:大的模型拥有更强的拟合与泛化能力,小模型的拟合能力较弱,容易出现过拟合。可以使用大的模型指导小模型的训练,保留大模型的有效信息,实现知识蒸馏。
对于轻量化的网络设计,较为流形的有SqueezeNet、MobileNet及ShuffleNet等结构。SqueezeNet采用了精心设计的压缩再扩展的结构,MobileNet使用了效率更高的深度可分离卷积,ShuffleNet提出了通道混洗的操作,进一步降低了模型的计算量。

压缩再扩展:SqueezeNet
- 使用1x1卷积来替代部分的3x3卷积,将模型参数减少为原来的1/9.
- 减少输入通道的数量,1x1卷积实现,是后续卷积核的数量也相应减少。
- 通道减少后,使用多个尺寸的卷积核进行计算,保留更多的信息,提升分类的准确率。
SqueezeNet使用Fire Module,输入特征尺寸为HxW,通道数为M,经过Squeeze层与Expand层,然后进行融合处理。
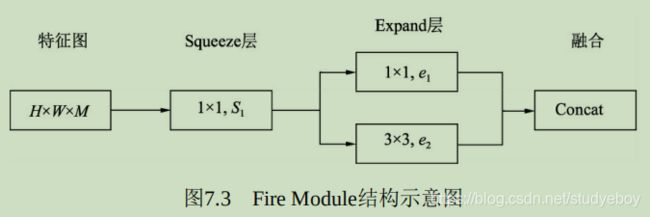
- SqueezeNet层,首先使用1x1卷积进行降维,特征图的尺寸不变,这里的S1小于M,达到压缩的目的。
- Expand层:并行的使用1x1卷积与3x3卷积获得不同感受野的特征图,达到扩展的目的。
- Concat:对得到的两个特征图进行通道拼接,作为最终输出。
- 模块中的S1、e1、e2都是可调的超参数,Fire Module默认e1=e2=4xS1。激活函数使用ReLU函数。

SqueezeNet一共使用了3个Pool层,前两个是Max Pooling层,步长为2,最后一个为全局平均池化,利用该层可以取代全连接层,减少了计算量。
深度可分离:MobileNet
-
标准卷积
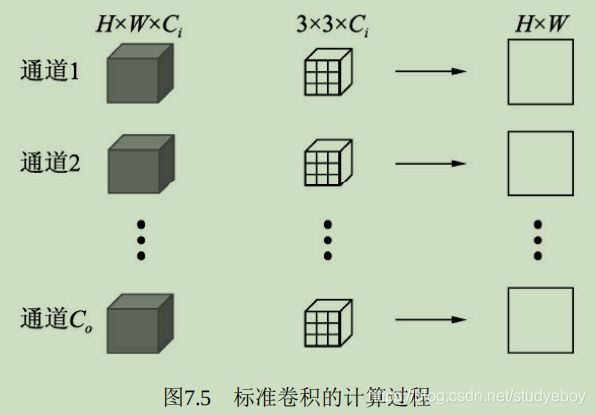

-
深度可分离卷积
深度可分离卷积(Depthwise Separable Convolution),将卷积的过程分为逐通道卷积与逐点1x1卷积两步。虽然扩展为两步,但减少了冗余计算,总体上计算量有了大幅度降低。
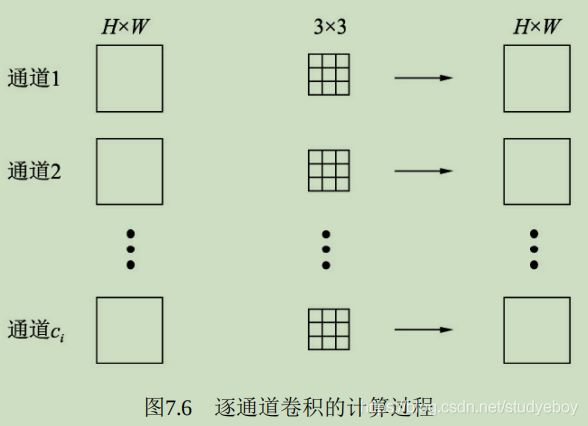


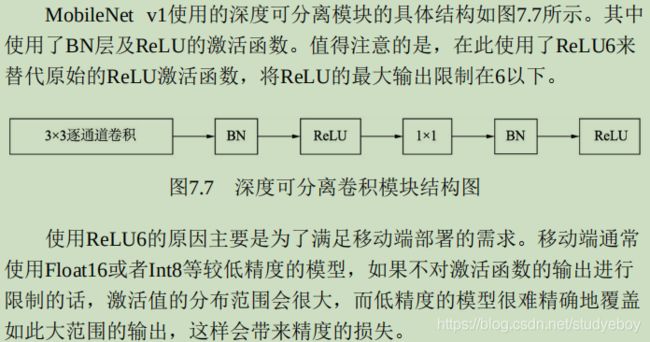
-
MobileNet v1 结构


-
MobileNet v2
MobileNet v2吸收了残差结构取代了原始的卷积堆叠方式,提出了Inverted Residual Block结构,根据卷积的步长,在步长为1时使用了残差连接,融合 方式为逐元素相加。
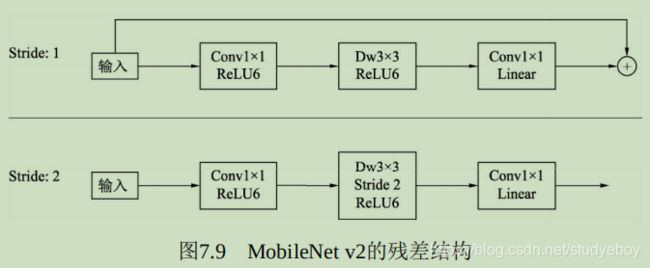
- Inverted Residual Block结构
MobileNet v2中,由于使用了深度可分离卷积来逐通道计算,本身计算量就比较少,因此可以使用1x1卷积来升维,在计算量增加不大的基础上获取更好的效果,最后再用1x1卷积降维。这种结构中间宽两边窄,类似于柳叶,该结构也因此被称为Inverted Residual Block。 - 去掉ReLU6
深度可分离卷积得到的特征对应于低维空间,特征较少,如果后续接线性映射则能够保留大部分特征,而如果接非线性映射如ReLU,则会破坏特征,造成特征的损耗,从而使得模型效果变差。因此MobileNet v2直接去掉了每一个Block中最后的ReLU6层,减少了特征的损耗,获得了更好的检测效果。
- Inverted Residual Block结构
通道混洗:ShuffleNet
为了降低计算量,当前先进的卷积网络通常在3x3卷积之前增加一个1x1卷积,用于通道间的信息流通与降维。然而在ResNet、MobileNet等高性能的网络中,1x1卷积却占用了大量的计算资源。
ShuffleNet v1 从优化网络结构的角度出发,利用组卷积与通道混洗(Channel Shuffle)的操作有效降低了1x1逐点卷积的计算量,是一个极为高效的轻量化网络。
-
通道混洗
当前先进的轻量化网络大都使用深度可分离卷积或者组卷积,以降低网络的计算量,但这两种操作都无法改变特征的通道数,因此需要使用1x1卷积。逐点的1x1卷积有两个特性:- 可以促进通道之间信息的融合,改变通道至指定维度。
- 轻量化网络中1x1卷积占据了大量的计算,并且致使通道之间充满约束,一定程度上降低了模型的精度。
ShuffleNet提出的通道混洗操作可以完成通道之间信息的融合。


-
网络结构
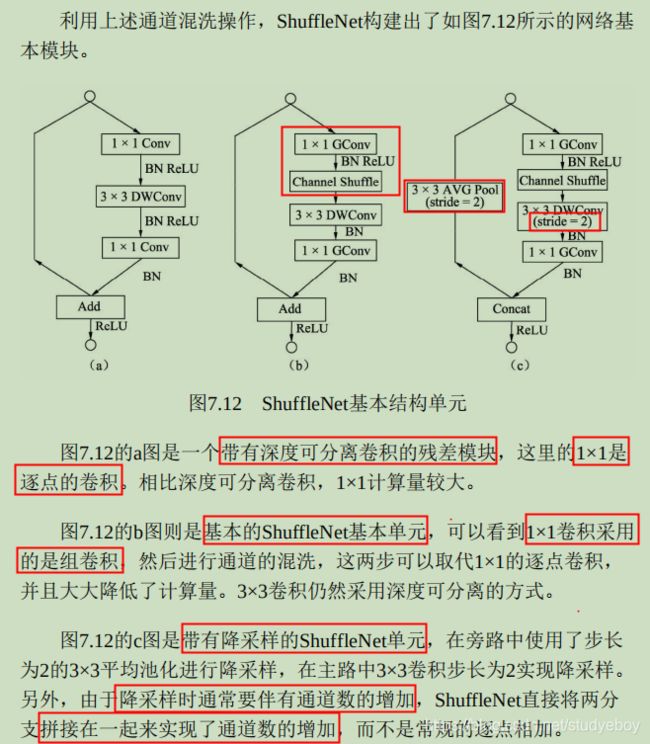

- g代表组卷积的组数,以控制卷积连接的稀疏性。组数越多,计算量越少,因此在相同的计算资源,可以使用更多的卷积核以获取更多的通道数。
- ShuffleNet在3个阶段内使用了其特殊的基本单元,这3个阶段的第一个Block的步长为2以完成降采样,下一个阶段的通道数是上一个的两倍。
- 深度可分离卷积虽然可以有效降低计算量,但其存储访问效率较差,因此第一个卷积并没有使用ShuffleNet基本单元,而是只在 3个阶段使用。
-
ShuffleNet v2
原有的一些轻量化方法在衡量模型性能时,通常使用浮点运算量FLOPs(Floating Point Operations)作为主要指标。FLOPs是指模型在进行一次前向传播时所需的浮点计算次数,其单位为FLOP,可以用来衡量模型的复杂度。除此之外,还有两个重要的指标:内存访问时间(Memory Access Cost, MAC)与网络的并行度。
分析影响网络运行速度,提出建立高性能网络的4个基本规则:- 卷积层的输入特征与输出特征通道数相等时,MAC最小,此时模型速度最快。
- 过多的组卷积会增加MAC,导致模型的速度变慢。
- 网络的碎片会降低可并行度,这表明模型中分支数量越少,模型速度会越快。
- 逐元素(Element Wise)操作虽然FLOPs值较低,但1iMAC较高, 应当尽可能减少逐元素操作。
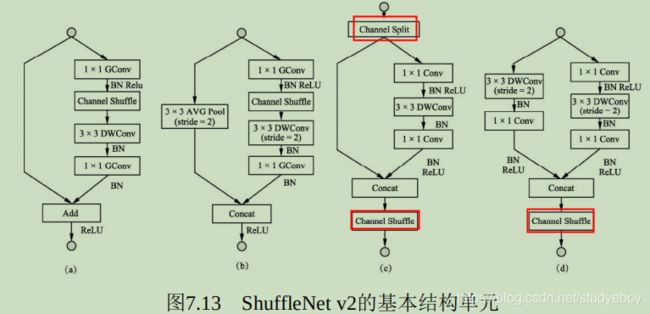
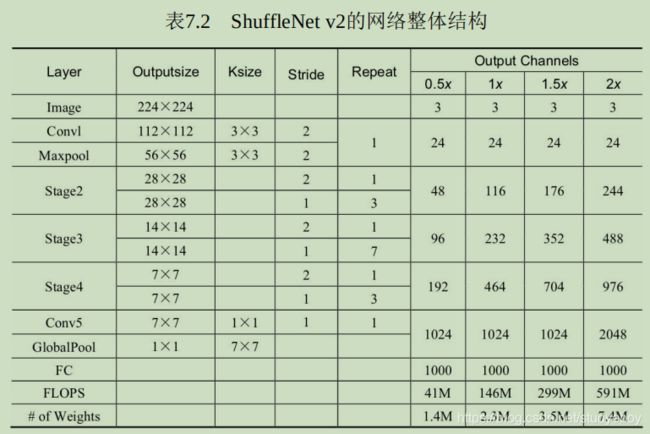
物体检测细节处理
非极大值抑制:NMS
当前的物体检测算法为了保证召回率,对于同一个真实物体往往会有多于1个的候选框输出。由于多余的候选框会影响检测精度,因此需要利用NMS过滤掉重叠的候选框,得到最佳的预测输出。
-
NMS基本过程
物体检测网络通常在最后增加一个非极大值抑制操作,即NMS,将重复冗余的预测去掉。
量化指标:- 预测得分:NMS假设一个边框的 预测得分越高,这个框就要被优先考虑,其他与其重叠超过一定程度的边框要被舍弃,非极大值即是指得分的非极大值。
- IoU:在评价两个边框的重合程度时,如果两个边框的IoU超过一定阈值时,得分低的边框会被舍弃。阈值通常会取0.5或者0.7.
NMS简约实现方法:
- 按照得分,对所有边框进行降序排列,记录下排列的索引order,并新建一个列表keep,作为最终筛选后的边框索引结果。
- 将排序后的第一个边框置为当前边框,并将其保留到keep中,再求当前边框与剩余所有边框的IoU。
- 在order中,仅保留IoU小于设定阈值的索引,重复上一步,直到order中仅剩余一个边框,则将其保留在keep中,退出循环,NMS结束。
NMS方法简单但是在更高的物体检测需求下,存在如下缺陷:
- 将得分较低的边框强制的去掉,如果物体出现较为密集时,本身属于两个物体的边框,其中得分较低的也有可能被抑制掉,从而降低了模型的召回率。
- 阈值难以确定。过高的阈值容易出现大量误检,而过低的阈值则容易降低模型的召回率,这个超参数很难确定。
- 将得分作为衡量的指标。NMS简单的将得分作为一个的置信度,单在一些情况下,得分高的边框不一定位置更准,因此这个衡量指标也有待考量。
- 速度:NMS的实现存在较多的循环步骤,GPU的并行化实现不是特别容易,尤其是预测框较多时,耗时较多。
-
抑制得分:SoftNMS
NMS方法虽然有效过滤了重复框,但也容易将本属于两个物体框中得分低的框抑制掉,从而降低了召回率。
NMS的计算公式:

Soft NMS对于IoU大于阈值的边框,没有将其得分直接置0,而是降低该边框的得分,利用边框的得分 IoU来确定新的边框得分,如果当前边框与边框Mde IoU超过设定阈值时,边框的得分呈线性的衰减。但是这并不是一个连续的函数,当一个边框与M的重叠IoU超过阈值时,其得分会发生跳变,对检测结果产生较大的波动。

SoftNMS的重置函数:

Soft NMS的计算复杂度与NMS相同,是一种更为通用的非极大值抑制方法,可以将NMS看作Soft NMS的二值化特例。当然Soft NMS也是一种贪心算法,并不能保证找到最优的得分重置映射。Soft NMS在不影响前向速度的前提下,能够有效提升物体检测精度。 -
加权平均:Softer NMS
NMS与Soft NMS算法都使用了预测分类置信度作为衡量指标,即假定分类置信度越高的边框,其位置也更为精准。具有高分类置信度的边框其位置并不是最精准的。因此,位置的置信度与分类置信度并不是强相关的关系,直接使用分类置信度作为NMS的衡量指标并非是最佳选择。Softer NMS新增加了一个定位置信度的预测,使得高分类置信度的边框位置变得更加准确,从而有效提升了检测的性能。
Softer NMS对预测边框与真实物体做了两个分布假设:- 真实物体的分布delta分布,即标准方差为0的高斯分布的极限。
- 预测边框的分布满足高斯分布。
基于这两个假设,Softer NMS提出了一种基于KL散度的边框回归损失函数KL Loss。KL散度是用来衡量两个概率分布的对称性衡量,KL散度越接近于0,则两个概率分布越相似。
KL Loss是最小化预测边框的高斯分布与真实物体的delta分布之间的KL散度。即预测边框分布越接近于 物体分布,损失越小。
描述边框的预测分布,除了预测位置之外,还需要预测边框的标准差,Softer NMS的预测结构:

边框的标准差 被看做边框的位置置信度,因此Softer NMS利用该标准差也改善了NMS过程。具体过程大体与NMS相同,只不过利用标准差改善了高得分边框的位置坐标,从而使其更为精准。 -
定位置信度:IoU-Net
在当前的物体检测算法中,物体检测的分类与定位通常被两个分支预测。对于候选框的类别,模型给出了 类别预测,可以作为分类置信度,然而对于定位而言,回归模块通常只预测了一个边框的转换关系,而缺失了定位的置信度,即框的位置准不准,并没有一个预测结果。
定位置信度的缺失,只能将分类的预测值作为边框排序的依据,分类预测值高的边框不一定拥有与真实框最接近的位置,因此这种标准不平衡可能会导致更为准确的边框被抑制掉。
IoU-Net增加了一个预测候选框与真实物体之间的IoU分支,改善了NMS过程,提升了检测器的性能。
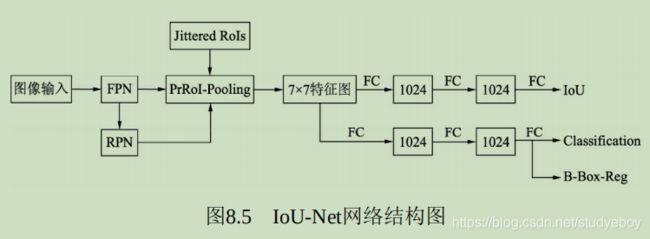
- IoU预测分支
IoU分支用于预测每一个候选框的定位置信度。在训练时IoU-Net通过自动生成候选框的方式来训练IoU分支,而不是从RPN获取。
Jittered RoIs在训练集的真实物体框上增加随机扰动,生成了一系列候选框,并移除与真实物体框IoU小于0.5的边框。这种方法训练IoU分支可以带来更高的性能与稳健性。
IoU分支可以方便的集成到当前的物体检测算法中,在整个模型的联合训练时,IoU预测分支的训练数据需要从每一批的输入图像中单独生成。另外还需要对IoU分支的标签进行归一化,保证其分布在[-1, 1]区间中。 - 基于定位置信度的NMS
IoU-Net利用IoU的预测值作为边框排列的依据,并抑制掉与当前框IoU超过设定阈值的其他候选框。
在NMS过程中,IoU-Net做了置信度的聚类,对于匹配到同一真实物体的边框,类别也需要拥有一致的预测值。 - PrRoI-Pooling方法
RoI Align通过采样的方法有效避免了量化操作,减少了RoI Pooling的误差,但Align的域都采取固定数量的采样点,但区域有大有小,都采取同一个数量点,显然不是最优的方法。
IoU-Net的PrRoI Pooling方法,采用积分的方式实现了更为精准的感兴趣区域池化。
与RoI Align只采样4个点不同,PrRoI Pooling方法将整个区域看做是连续的,采用积分公式求解每一个区域的池化输出值,区域内的每一个点都可以通过双线性插值的方法得到。这种方法的反向传播时 可导的,避免了任何的量化过程。
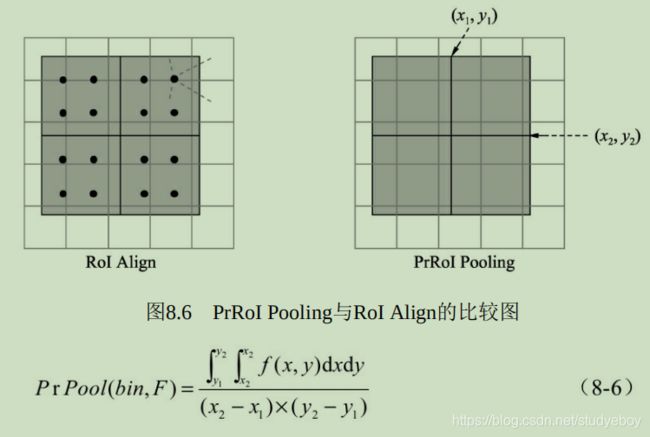
- IoU预测分支
样本不均衡问题
当前主流的物体检测算法都是将物体检测当做分类问题来考虑,先使用先验框或者RPN等生成感兴趣的区域,再对该区域进行分类与回归位置。基于分类思想的物体检测算法存在样本不均衡的问题,因而会降低模型的训练效率与检测精度。
-
不均衡问题分析

- 正负样本不均衡
- 难易样本不均衡
- 类别间样本不均衡
缓解方法:
- 设置正负样本比例
- 排序筛选候选框的数量
- 权重惩罚
- 数据增强
-
在线难样本挖掘:OHEM
OHEM(Online Hard Example Mining)难样本挖掘方法,先让模型收敛于当前的工作数据集,然后固定该O型,在数据集中去除简单的样本,添加一些当前非判断的样本,精细新的训练,这样的交替训练可以使得模型性能达到最优。
-
专注难样本:Focal Loss
模型过拟合
过拟合现象的本质是模型学习到了训练数据自身的特性,非全局的特性。

物体检测难点
多尺度检测
小物体由于其尺寸较小,可利用的特征有限,这使得其检测较为困难,当前的检测算法对于小物体并不友好。
- 过大的下采样率:假设当前小物体尺寸为15x15,一般的物体检测中卷积下采样率Wie16,这样在特征图上,小物体连一个点也占据不到。
- 过大的感受野:在卷积网络中,特征图上特征点的感受野比下采样率大很多,导致在特征图上的一个点中,小物体占据的特征更少,会包含大量周围区域的特征,从而影响其检测结果。
- 语义与空间的矛盾:当前的检测算法大都是自上而下的方式,深层与浅层特征图在语义性与空间性上没有做到更好的均衡。
- SSD缺乏特征融合:SSD虽然使用了多层特征图,但浅层的特征图语义信息不足,没有进行特征的融合,致使小物体检测结果较差。
-
降低下采样率与空洞卷积
去掉Pooling层hUI减小感受野,空洞卷积在不改变网络分辨率的基础上增加了网络的感受野。但是采用空洞卷积也不能保证修改后与修改前的感受野完全相同,但能够最大限度的使感受野在可接受的误差内。 -
Anchor设计
- 统计实验
- 边框聚类
-
多尺度训练
当前的多尺度训练(Multi Scale Training, MST)通常是指设置几种不同的图片输入尺度,训练时从多个尺度中随机选取一种尺度,将输入图片缩放到该尺度并送人网络中,是一种简单又有效的提升多尺度物体检测的方法。虽然次迭代时都是单一尺度的,但每次都各不相同,增加了网络的鲁棒性,又不至于增加过多的计算量。 -
特征融合
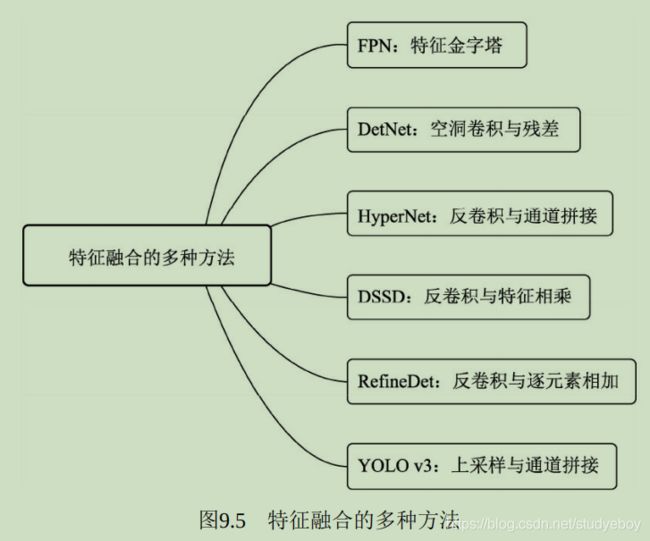
-
尺度归一化:SNIP
经典的克服多尺度检测的方法:- 图像金字塔:将输入图像做成多尺度,或者随机取一个尺度。
- 特征金字塔:对深层特征上采样,融合多层的特征,将语义性与空间性进行优势互补。
SNIP使用了类似于MST的多尺度训练方法,构建了3个尺度的图像金字塔,但在训练时,只对指定范围内的Proposal进行反向传播,而忽略掉过大或者过小的Proposal。
- 3个尺度分别拥有各自的RPN模块,并且各自预测指定范围内的物 体。
- 对于大尺度的特征图,其RPN只负责预测被放大的小物体,对于 小尺度的特征图,其RPN只负责预测被缩小的大物体,这样真实的物体 尺度分布在较小的区间内,避免了极大或者极小的物体。
- 在RPN阶段,如果真实物体不在该RPN预测范围内,会被判定为 无效,并且与该无效物体的IoU大于0.3的Anchor也被判定为无效的 Anchor。
- 在训练时,只对有效的Proposal进行反向传播。在测试阶段,对有 效的预测Boxes先缩放到原图尺度,利用Soft NMS将不同分辨率的预测 结果合并。
- 实现时SNIP采用了可变形卷积的卷积方式,并且为了降低对于 GPU的占用,将原图随机裁剪为1000×1000大小的图像。
-
三叉戟:TridentNet
不同尺度的检测性能与感受野呈正相 关,即大的感受野对于大物体更友好,小的感受野对于小物体更友好。

- 3个不同的分支使用了空洞数不同的空洞卷积,感受野由小到大, 可以更好地覆盖多尺度的物体分布。
- 由于3个分支要检测的内容是相同的、要学习的特征也是相同的, 只不过是形成了不同的感受野来检测不同尺度的物体,因此,3个分支 共享权重,这样既充分利用了样本信息,学习到更本质的物体检测信 息,也减少了参数量与过拟合的风险。
- 借鉴了SNIP的思想,在每一个分支内只训练一定范围内的样本, 避免了过大与过小的样本对于网络参数的影响。
拥挤与遮挡
拥挤与遮挡会带来物体的信息缺失,物体的部分 区域是不可见的,边界模糊,容易造成检测器的误检 漏检,从而降低检测性能。
- 行人之间的自遮挡
- 定位不准确:在提取行人的特征时,遮挡会带来特征的缺失,并且距离很近的行人特征会相互影响,带来干扰,这都会降低行人定位的准确性。
- 对NMS的阈值更为敏感:用于行人靠得很近,如果 NMS的阈值较低,则很容易将本属于两个行人的预测框抑制掉一个,造成漏检;而如果阈值较高,很可能会在两个行人之间多了一个错误预检框,造成误检。因此行人的自遮挡对NMS十分不友好,从而导致检测性能的降低。
- 行人被其他物体遮挡

解决办法:
-
改进NMS:因为NMS对行人遮挡检测影响较大,可以改进NMS提升遮挡检测的性能。
-
增加语义信息:遮挡会造成行人部分信息缺失,因此可以尝试引入额外的特征,如分割信息、梯度和边缘信息等。
-
划分多个part处理:由于行人之间的形状较为相似,因此可以利用该先验信息,将行人按照不同部位,如头部、上身、手臂等划分为多个part进行单独处理,然后再综合考虑,可以在一定程度上缓解遮挡带来的整体信息缺失。
-
排斥损失:Repulsion Loss

-
与其他标签的排斥:RepGT
RepGT损失设计思想是为了让当前预测框尽可能的远离周围的标签物体,周围标签物体指的是,除了预测框本身要回归的物体之外,与该预测框有最大IoU的物体标签。 -
与其他预测框的排斥:RepBox
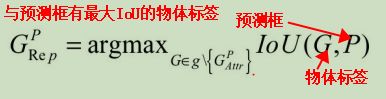

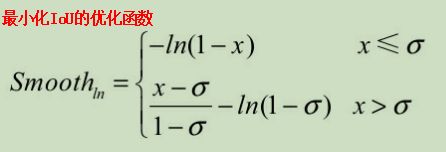

-
与其他预测框的排斥:RepBox
让预测框尽可能的远离周围预测框,降低两者之间的IoU,从而避免属于两个物体的预测框,其中一个被NMS抑制掉。
根据图像中的物体标签,可以将最后的预测框划分为多个组。假设有g个物体,则划分为同组和不同组:同组之间的预测框回归的是同一个物体标签,不同组之间的预测框对应的是不同的物体标签。

对于不同组之间的预测框,希望他们之间的重叠区域越小越好,可以使用IoU来衡量重叠区域。用Smooth优化函数最小化IoU。

-
-
OR-CNN
- 聚集损失:Aggregation Loss
在RPN阶段,聚集损失除了可以使Anchor更靠近物体标签之外,还可以将对应于同一个物体标签的所有Anchor紧密的分布。聚集损失也可以作用于Faster RCNN的第二个阶段,通过聚集的手段可以有效降低拥挤行人之间的误检,与Repulsion Loss思想类似,但不过使用了同类聚集取代了排斥的方法。 - 行人部位拆解的池化:PORoI Pooling
将行人分多个部位拆解,分别提取不同部位的特征,再融合检测,OR-CNN借鉴了该思想,并将这种思想融合到了RoI Pooling的过程中。

子部位的特征进行Pooling之后,还需要经过一个遮挡处理单元(Occlusion Process Unit),判断该子部位被遮挡的程度,最后用逐元素相加的方式将6个区域的特征进行融合。

遮挡处理单元将遮挡的程度施加到原特征上,遮挡单元经过Softmax后得到了被遮挡的概率值,可以与整个检测框架进行端到端的训练。
- 聚集损失:Aggregation Loss
物体检测的未来发展
物体检测可做的创新点

-
精度与速度的权衡
- 速度需求:自动驾驶需非常低的延时,机械臂自动分拣速度并不是第一考虑因素。
- 召回率:交通流量统计系统中车辆、行人等物体的召回率直接影响流量统计。
- 边框精准度:智能测量、机械臂自动分拣应用中,检测边框的精准度直接影响系统的成功率。
- 移动端:移动端的检测需要模型移动部署、轻量化。
-
卷积网络的可解释性与稳定性
卷积网络个并没有我们想象的那么稳定,有时会存在一些怪异的现象。例如,房间里的大象就针对检测器的鲁棒性做了实验,将数据集中某图像中的一只大象移植到了别的图像中,不断的平移,观察检测结果:- 检测不稳定:随着大象的移动,图像中的物体有时无法被检测到,或者检测的得分置信度发生剧烈变化。
- 物体错分类:随着大象的移动, 图像中的物体可能会被错分成其他类别的物体。
- 非物体边框内的干扰:即使大象与图像中的物体没有发生重叠,其检测类别、边框也会发生明显变化,甚至检测不出。
目前物体的检测是间矩形边框内的所有特征考虑在内,并且较大的感受野使得最终的RoI会包含边框外较多的特征,而这两种本不属于物体的特征会影响检测的性能。
拥有池化等操作,卷积网络对于微小的位移、变形等具有一定的鲁棒性。当图像中的物体发生肉眼难以辨别的微小平移时,检测置信度发生了巨大的变化。当网络中拥有了具有一定步长的降采样操作后,图像必须平移降采样的整数倍后,才会体现出平移的不变性。 -
训练:微调还是随机初始化
当前较为通用的训练检测模型的方法是,先在ImageNet数据集上进行预训练,然后在利用自己的数据进行微调,由于ImageNet的预训练模型可以共享,很多情况下并不需要自己亲自去训练,因此这种方法可以大大缩短模型收敛的时间。- 虽然微调的方式可以加速模型在训练初期的收敛,但预训练与微调的时间总和与随机初始化训练的时间大致相同。使用随机初始化的方式得到的模型,其精度可以匹配微调训练得出的模型。
- 微调的方式并不能有效的防止过拟合,即无法提供较好的正则化效果。
- 在某些检测精度要求高、位置敏感的任务中,其数据集与ImageNet数据集会存在较大差距,这种情况下采用微调的训练方法会限制检测器的性能。
ImageNet的预训练并不是必要的,如果有足够的计算资源与数据,完全可以使用随机初始训练方法。预训练的方式可以加速训练过程,并且适用于自己的数据集规模比较小的情况,但不一定能提升最终的检测精度。
-
考虑物体间关系的检测
通过特征与几何之间的交互,对物体关系进行建模,能够有效提升检测的性能。 -
优化卷积方式

- 普通卷积
卷积神经网络的基础单元,完成特征提取任务,但是计算复杂度较高。 - 深度可分离卷积
减少卷积的冗余计算,提升网络运行速度。 - 空洞卷积
在不想网络有太大下采样率与计算量时,增加网络的感受野。 - 可变形卷积
卷积核的形状是可以变化的,只提取感兴趣的区域,不必是固定的矩形。实现时,可变形卷积需要在传统的卷积层之前增加一层过滤器,学习下一个卷积层卷积核的位置偏移量,移植方便,增加较少的计算量,即可带来更好的检测性能。卷积方式更为灵活,摆脱了固定卷积的限制。 - 降频卷积:Octave
通过降低低频率特征的尺寸,减少计算量。Octave卷积通过相邻位置的特征共享,减小了低频特征的尺寸,进而减小了特征的冗余与空间内存的占用。
- 普通卷积
-
神经架构搜索:NAS

- NASNet
NASNet的宏观网络结构还是需要人工设计,搜索空间是由多个卷积层Cell组成的,这些卷积层结构相同,权重不相同。NASNeti用RNN循环神经网络来实现卷积层Cell的自动搜索。 - BlockQNN
基于分布式训练的深度增强学习算法BlockQNN,来实现自动网络架构搜索。BlockQNN搜索由多个重复子网络开组成的Block结构,在大大减少搜索空间的同时,提升了网络的泛化能力。 - DetNAS
DetNAS将搜索空间编码为超网,主要包含超级网络训练、使用进化算法EA进行超级网络的搜索,以及结构网络再训练这三个步骤。
- NASNet
-
与产业结合的创新

- 数据更复杂:自动驾驶车辆通常配有多个不同位置的相机用来识别障碍物,其中会包含大量的遮挡、小物体等,也会存在夜晚、雨雪及雾霾等难检测的场景,这些都对检测模型提出了更高的要求。
- 指标要求更严格:安全驾驶对时延、检测准召率、准确率都有极高的要求。
- 传感器融合:与激光雷达相比,相机的语义信息更丰富,但是精度相对较差,当前成熟的解决方案通常是将两种传感器进行融合。
- 算法融合:自动驾驶最终的检测对象应该是具有时序性质的3D世界坐标系下的障碍物信息,除了2D物体检测,还包括标定、3D检测、追踪和障碍物融合等。
- 多任务融合
- 多传感器融合
- 与追踪的融合
- 与定位建图的结合
摆脱锚框:Anchor-Free
Anchor的检测算法中边框的变化,对于二阶的算法,第一阶段RPN会对Anchor进行有效的筛选,生成更有效的精准的Proposal,送人第二阶段,最终得到预测的边框。一阶的算法相当于把固定的Anchor当做了Proposal,通过高效的特征与正、负样本的控制,直接预测出了物体。

- 正负样本不均衡:在特征图所有点上进行均匀采样Anchor,而在大部分地方都是没有物体的背景区域,导致简单负样本数量众多,这部分样本对于检测器没有任何作用。
- 超参数难调:Anchor需要数量、大小、宽高等多个超参数,对检测的召回率和速度等指标影响极大。
- 匹配耗时严重:为了确定每个Anchor是正样本还是负样本,通常要将每个Anchor与所有的标签进行IoU的计算,这样会占据大量的内存资源与计算时间。
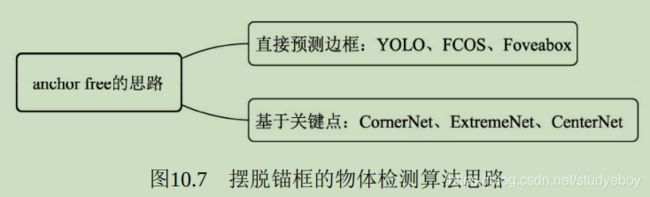
- 直接预测边框:根据网络特征直接预测物体出现的边框,即上、下、左、右4个值。
- 关键点的思想:使用边框的角点或者中心点进行物体检测。
Anchor-Free算法已经达到了与基于Anchore的检测器相同甚至更好的检测效果。
-
基于角点的检测:CornerNet
将传统的预测边框思想转化为预测边框的左上角与右下角两个角点问题,然后再对属于同一个边框的角点进行组合。
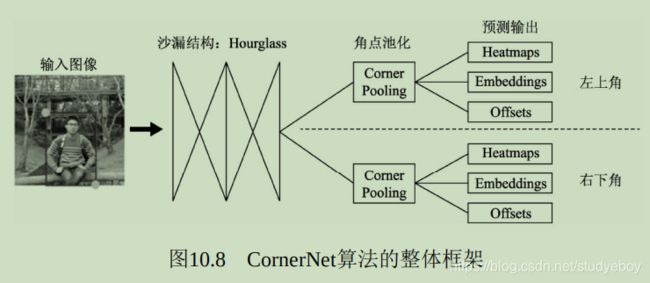
-
沙漏结构Hourglass:特征提取的backbone,能够为后续的网络预测提供很好的角点特征图。

-
角点池化;作为一个特征的池化方式,角点池化可以将物体的信息整合到左上角点或者右下角点。
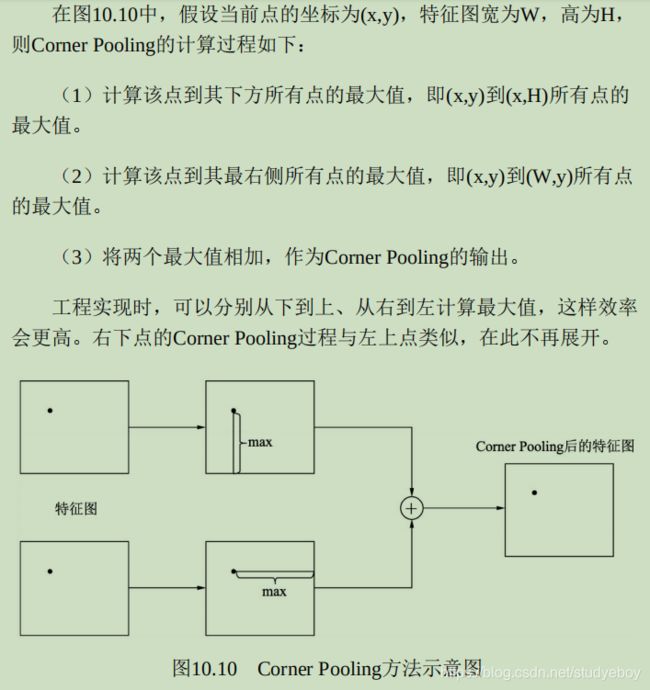
-
预测输出:预测角点出现的i Heatmaps、角点的配对Embeddings及角点位置的偏移Offsets。


-
-
检测中心点:CenterNet
将物体检测问题变成一个关键点的估计问题,通过预测物体的中心点位置及对应物体的长与宽,实现当前检测精度与速度最好的权衡。
CenterNet思想与网络:- 没有使用Anchor作为先验框,而是预测物体的中心点出现位置,不存在先验框与标签的匹配,正、负样本的筛选过程。
- 每个物体标签仅仅选择一个中心点作为正样本,具体实现是在关键点热图上提取局部的峰值点,不存在NMS过程。
- CenterNet专注在关键点的检测,可以使用更大的特征图,而无须使用多个不同大小的特征图。
网络预测也损失计算:

-
锚框自学习:Guided Anchoring
Guided Anchoring主要分为锚框预测与特征自适应两部分,其中锚框 部分负责预测Anchor出现的位置与形状,而特征自适应模块可以将Anchor作用到特征图上,从而提取出更有针对性的特征。
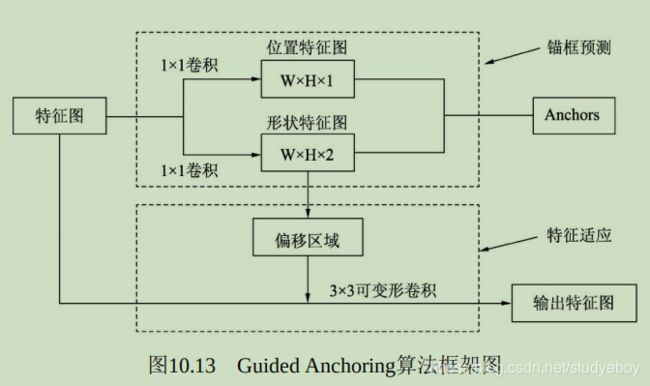
-
锚框预测:Anchor Generation
Guided Anchoring利用网络特征自动的预测了Anchor的分布,其中包含Anchor出现的位置与形状两个特征。Guided Anchoring使用了与CenterNet预测物体类似的思想,采用了两个分支来预测Anchor。- 中心点位置:使用了一个1x1卷积来预测Anchor可能出现的位置,输出大小为WxHx1,每个点表示Anchor的中心点出现在此位置的概率。
- 形状预测:使用了一个1x1卷积来预测Anchor的宽与高两个特征,输出大小为WxHx2。
Guided Anchoring在每一个点上采样了9组不同宽高的边框,来取代预测的Anchor,进而 匹配关系,确定优化对象。
-
特征自适应:Feature Adaption
然而,Guided Anchoring中的Anchor形状不一,特征图事先并无法 得到其需要预测的Anchor的形状,但是后续却要预测该Anchor的类别与 位置偏移,这里就存在Anchor与表征Anchor的特征不适配的问题。
为了解决该问题,Guided Anchoring在Anchor预测后增加了一个特 征自适应层(Feature Adaption),具体实现过程中, Feature Adaption使用了一个3×3可变形卷积作用于特征图上,以适配 Anchor的形状。
与普通可变形卷积不同,这里的偏置取自于预测的Anchor,具体是 利用一个1×1卷积作用于预测的Anchor宽高,实现极为巧妙。从功能上 理解,这里的特征自适应有些类似于RoI Pooling层。

-