(计算机视觉实战)基于内容的图像检索
文章结构
- 1. 项目介绍
- 2. 什么是卷积去噪编码器
- 3.源码解释
1. 项目介绍
基于内容的图像检索,在工业生产中是有大量运用的。比如我们想在百度或者谷歌上搜索一张图片,搜素的过程就是通过图像的内容。想要完成基于图片内容的图片检索,首先应该确定以下的几件事情。首先既然是基于内容,如果一个图片中的噪音特别多,那么这些噪点就会被神经网络当做是图片内容的一部分进行学习。那么这样学出来的模型就很难正确的在大量的图片中对和目标相似的图片进行检索。另外,如何正确的提取一张图片的核心内容也是基于图片内容检索的关键。
2. 什么是卷积去噪编码器
基于内容的图片检索是基于所谓的卷积去噪编码器。他是无监督模型的一种。卷积去噪编码器是由两个部分组成的。首先第一个部分就是编码器(encoder)它主要负责将图片中的主要信息,即神经代码提取出来,或者说是将一张图片进行压缩。第二部分就是解码器(decoder),解码器的主要作用是将我们提取出来的神经代码重新解码成原来的图片。因为在进行压缩的时候,也就是在encoder中,巨大部分的噪点都会被抛弃掉。所以还原出来的图片就是清晰的没有噪点的图片。
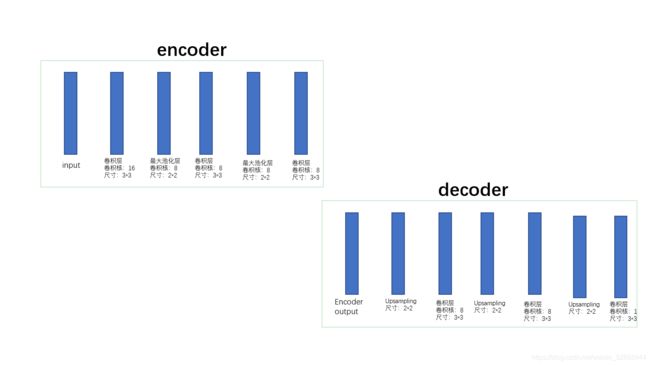
下图展现的是一个卷积去噪神经网络的基本结构。在这个小项目中,我门将使用以下的卷积去噪网络。
但是这个图片检索有什么关系呢?
基于图片内容的图片检索思路如下:
- 使用mnist手写数字数据集,并在原始数据集加上噪声。
- 根据上图提供的网络结构构件,卷积去噪编码器,并且将其训练好并存储模型
- 图片检索基于目标图片和图库中图片的欧几里得距离,计算出欧几里得距离,并且根据距离将图片进排序。
- 取出最靠前的N张图片作为结果。
3.源码解释
这个小项目将使用keras来完成。首先和其他的程序无异,第一步首先是导入我们所需要的辅助库。
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import cv2
导入辅助库之后,第一步肯定是导入数据集,使用keras提供的包可以直接下载。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
我们可以先来看一下数据的大小和数据本身:
x_train.shape: (60000, 28, 28)
x_test.shape: (10000, 28, 28)
y_train.shape: (60000,)
y_test.shape: (10000,)
一共是训练数据是60000条,长为28个像素,宽为28个像素。我们训练数据集中的第一张图片,使用openCv将这张图片画出来
img = x_train[0]
cv2.imshow('img',img)
cv2.waitKey()
我们可以得到这样的一张图片: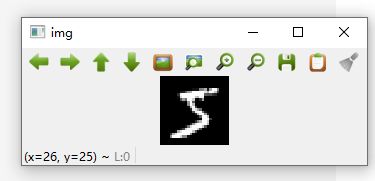
如图所示的一张手写图片。我们对所有的图片都进行归一化处理,并将其整形的格式转换成32位的浮点型,可以节省一点内存空间,因为训练数据集有6万张图片。除以255的原因是图片中每一个像素的颜色值是在0-255之间的,所以除以255就可以保证每一个像素点的值都在0-1之间。然后将训练数据集和测试数据集的形状改为(数量,宽,高,通道数)
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (x_train.shape[0], 28, 28, 1))
x_test = np.reshape(x_test, (x_train.shape[0], 28, 28, 1))
但是我们在图中可以看到的是这张图片是一个很干净的手写字母图片,他没有任何的噪音在里面。所有我们需要对这个图片加上一些噪声。所谓的噪声就是在图片的每一个像素点上随机的加上一些值。
noise_ = 0.3
x_train_n = x_train + np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)* noise_
x_test_n = x_test + np.random.normal(loc=0.0, scale=1.0, size=x_test.shape) * noise_
x_train_n = np.clip(x_train_n, 0., 1.)
x_test_n = np.clip(x_test_n, 0., 1.)
np.clip()在这里是为了让加了噪声之后的图片的每一个像素的值还在保持在0–1之间。
上述代码中的nose_是指的噪声的强度。我们可以更改噪声的强度来看看会有什么不同的结果。
noise_ = 0.3

noise_ = 0.5

对比以上的两张图可以看得出来,noise_ 越大,图中的噪点也就越明显。当我们给图片添加好了噪声之后就可以来设计卷积去噪网络了。
整个网络根据前面提供的网络结构构建:
def My_model():
input_img = Input(shape=(28, 28, 1))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
e_ = MaxPooling2D((2, 2), padding='same', name='encoder')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(e_)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
de_ = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
然后使用adam 作为优化算法,binary_crossentropy作为损失函数,对网络进行训练。注意在设置epoch的时候,不要设置的太低,可能会因为训练不充分导致,网络效果很差的情况出现。batchsize的设置和自己的电脑内存相关,结合自己的电脑情况来设置。这里我设置的是64。要注意一点,在创建网络的时候,将encoder的最后一层命名,因为可以使得后面的操作更简单。
encoder = Model(input_img, decoded)
encoder.compile(optimizer='adam', loss='binary_crossentropy')
encoder.fit(x_train_noisy, x_train,
epochs=20,
batch_size=64,
shuffle=True,
validation_data=(x_test_noisy, x_test))
我是使用的CPU训练的模型,训练了大概有40分钟左右,如果有NVIDIA显卡的朋友尽可能使用显卡来进行训练,可以节约很多时间。
模型训练好了之后,将模型保持.h5格式。
encoder.save('encoder_1.h5')
在这里我遇到了一个问题。出现h5py的版本与当前Tensorflow不兼容的问题。我的解决方式是将当前电脑中的h5py卸载,并安装与当前TensorFlow版本兼容的版本。直接在pycharm的终端上运行以下代码即可解决问题。
pip uninstall h5py
pip install h5py==2.8.0
编写完以上代码之后 就可以运行My_model函数对整个模型进行训练了。
My_model()
等待模型训练完成。我们可以来试一下,模型的去噪性能如何。我们新建一个.py文件,再导入了相应的辅助包之后,我们可以用模型的predict方法对模型的除噪能力进行检测。具体导入模型和除燥的步骤如下:
encoder = load_model('encoder_1.h5')
denoised_img = encoder.predict(x_test_n)
得到的denoised_img 是x_test_n数据数据集中所有的除噪图片,我们可以取第一张图片来进行对比。
cv2.imshow('noise_img',cv2.resize(x_test_n[5],(280,280)))
cv2.imshow('denoise_img',cv2.resize(denoised_img[5],(280,280)))
cv2.waitKey()
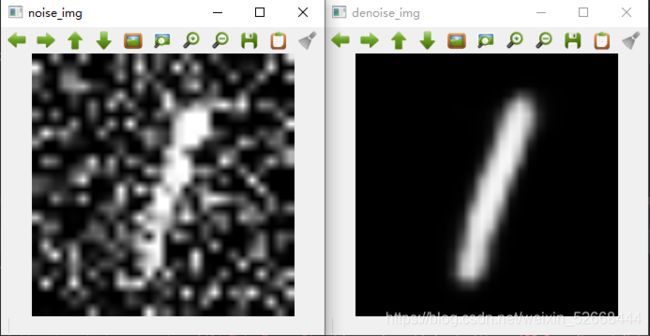
从上图可以看到的是,除噪网络已经有了很好的去除噪音的效果,他可以从噪点特别多的图片中,提取出图片的本质。这里要强调一点的就是,一定一定要保证训练的epoch足够。接下来我们将使用卷积去噪网络的encoder层的输出来构建基于图像内容的图像检索功能。
这个图像检索功能有两个大的板块构成,第一是要根据输入的神经代码,在图库中寻找和其相似的图片,因为是无监督学习,所以不需要标签。第二部是对所有选择出来的图片进行排序。根据与输入图片之间的欧几里得距离来进行排序。最后提取出对应的前N个图片作为左后的输出结果即可。
接下来我们就来一步一步的实现:
我们可以同样的新建一个.py文件,然后一样的导入所需要的辅助包。同样我们需要导入训练好的卷积去噪神经网络。但是前两次的导入不同的是,我们并不是想要整个神经网络,而是想要encoder层而已。所以这个时候我们同通过以下代码,网络结构中的某一层:
encoder_1 = load_model('encoder_1.h5')
encoder = Model(inputs=encoder_1.input, outputs=encoder_1.get_layer('encoder').output)
所以我们还是使用上述代码块中的第一句代码,来导入整个模型,然后使用第二句代码来将网络截取到encoder层,这个时候网络就只有输入到encoder层,decoder层就会被抛弃。接下来创建主要的检索函数 CBIR,需要有三个输入,一个是将是目标图片的神经代码,在哪个图库中检索,以及我们想看检索排序之后的前N张图片。
def CBIR(target_img,img_corpus,top_samples=5):
接下来我们需要将输入图片target_img还有图库img_corpus做神经代码的提取,并将其整理成一个1维向量,因为之后会计算距离,我们可以通过以下的代码实现:
neural_code = encoder_1.predict(img_corpus).reshape(img_corpus[0],img_corpus[1]*img_corpus[2]*img_corpus[3])
target_img_code = encoder_1.predict(target_img).reshape(target_img[1]*target_img[2]*target_img[3])
做完以上操作之后,我们就可以让目标图片和每一个图库中的图片来求欧几里得距离。首先我们需要记录每一次计算的结果,因为我们最后是使用这个欧几里得距离来进行排序的,所以新建一个list来会保存每一次的计算结果。
distance = []
之后就逐个计算即可。
for img in neural_codes
distance.append(np.linalg.norm(target_img_code - img))
当我们拿到了计算结果之后,就需要对结果进行排序,并且提取出计算结果所对应的图库中的图片。我们想要的是一个N行2列的矩阵,每一行为一张图片,每一列是其对应的欧几里得距离,以及index。目前为止计算结果和图库中的图片位置是相互对应的,所以我们先给图库中的图片打上index,在做排序,就不会导致顺序混乱的问题。
根据图库的大小生成索引:
index_ = np.arange(len(img_corpus))
接下来我们将前面两个向量(distance,index)拼成一个矩阵,并根据欧几里得距离对矩阵中所有的行进行排列。这里要注意的是,我们想要的矩阵形状是(60000,2)。可以通过以下的代码来实现:
E_distance = np.stack((np.array(distance),
index_),axis=-1)
axis = -1,可让拼接出来的矩阵的形状是我们想要的形状。之后就可以以distance的大小对整个矩阵的行进行排序。
sorted_distance = E_distance[E_distance[:,0].argsort()]
之后的步骤就是从排序完成的矩阵中取出前N个index.
top_sample_index = sorted_distance[0:top_sample_,][:,1]
将图库中对应的图片叠加成一个矩阵,可以方便使用cv2直接对其进绘制。首先拿出第一张照片。
results = img_corpus[int(top_sample_index)[0],:]
然后使用循环对将剩下的照片全部叠上去。
for i in range(1:top_sample_):
results = np.hstack((results,img_corpus[int(top_sample_[i],:)]))
注意循环是从第一个图片开始而不是第0个。之后就可以用OpenCv将得到的图片与目标图片都画出来,看看得到的N张图片是否是和我们想要的一致。
cv2.inshow('target_img',target_img)
cv2.imshow('results',results)

我们的目标检索是0,我们得到的是图库中和0最像的五张图片(因为图片实在是太小了,做了一个resize有点变形)。这说明这个检索系统的工作很棒。

换一个目标图片试试。
以上便是一个基于图片内容进行图片检索的小项目,麻雀虽小,五脏俱全。