消费者客户端有两种方式从消息中间件获取消息并消费。严格意义上来讲,RocketMQ并没有实现PUSH模式,而是对拉模式进行一层包装,名字虽然是 Push 开头,实际在实现时,使用 Pull 方式实现。
通过 Pull 不断轮询 Broker 获取消息。当不存在新消息时,Broker 会挂起请求,直到有新消息产生,取消挂起,返回新消息。
1、概述
1.1、PULL方式
由消费者客户端主动向消息中间件(MQ消息服务器代理)拉取消息;采用Pull方式,如何设置Pull消息的拉取频率需要重点去考虑,举个例子来说,可能1分钟内连续来了1000条消息,然后2小时内没有新消息产生(概括起来说就是“消息延迟与忙等待”)。
如果每次Pull的时间间隔比较久,会增加消息的延迟,即消息到达消费者的时间加长,MQ中消息的堆积量变大;若每次Pull的时间间隔较短,但是在一段时间内MQ中并没有任何消息可以消费,那么会产生很多无效的Pull请求的RPC开销,影响MQ整体的网络性能;
1.2、PUSH方式
由消息中间件(MQ消息服务器代理)主动地将消息推送给消费者;采用Push方式,可以尽可能实时地将消息发送给消费者进行消费。
但是,在消费者的处理消息的能力较弱的时候(比如,消费者端的业务系统处理一条消息的流程比较复杂,其中的调用链路比较多导致消费时间比较久。
概括起来地说就是“慢消费问题”),而MQ不断地向消费者Push消息,消费者端的缓冲区可能会溢出,导致异常;
2、PUSH模式
主动推送的模式实现起来简单,避免了拉取的消费端业务逻辑的复杂度,消息的消费可以认为是实时的,同时也存在一定的弊端,要求消费端要有很强的消费能力。
2.1、代码实现
public class Consumer1 {
public static void main(String[] args){
try {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.setConsumerGroup("consumer_push");
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently(){
@Override
public ConsumeConcurrentlyStatus consumeMessage(List paramList,
ConsumeConcurrentlyContext paramConsumeConcurrentlyContext) {
try {
for(MessageExt msg : paramList){
String msgbody = new String(msg.getBody(), "utf-8");
SimpleDateFormat sd = new SimpleDateFormat("YYYY-MM-dd HH:mm:ss");
Date date = new Date(msg.getStoreTimestamp());
System.out.println("Consumer1=== 存入时间 : "+ sd.format(date) +" == MessageBody: "+ msgbody);//输出消息内容
}
} catch (Exception e) {
e.printStackTrace();
return ConsumeConcurrentlyStatus.RECONSUME_LATER; //稍后再试
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //消费成功
}
});
consumer.start();
System.out.println("Consumer1===启动成功!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
PUSH消费方式,需要注册一个监听器Listener,,用来监听最新的消息,进行业务处理,同时反馈消息的消费状态,消费成功(CONSUME_SUCCESS)、消费重试(RECONSUME_LATER),消息重试会根据配置的消息的延迟等级的时间间隔,定时重新发送消费失败的记录。(PS:延迟消息中会重点讨论)
PUSH消息方式由于返回了消息的状态,服务端会维护每个消费端的消费进度,内部会记录消费进度,消息发送成功后会更新消费进度。
PUSH消息方式的局限性,是在HOLD住Consumer请求的时候需要占用资源,它适合用在消息队列这种客户端连接数可控的场景中。
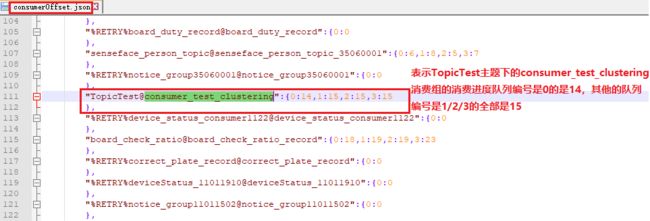
上一个章节说明了服务端存储的每个主题对应的消费组的每个消息队列的偏移量
查看服务器文件上的消费进度信息:
/usr/local/rocketmq-all-4.2.0/store/config/consumerOffset.json
3、PULL模式
3.1、代码实现(1)
public class PullConsumer {
private static final Map offseTable = new HashMap();
public static void main(String[] args) throws MQClientException {
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("pullConsumer");
consumer.setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
consumer.start();
Set mqs = consumer.fetchSubscribeMessageQueues("TopicTest");
for (MessageQueue mq : mqs) {
SINGLE_MQ: while (true) {
try {
PullResult pullResult =
consumer.pullBlockIfNotFound(mq, null, getMessageQueueOffset(mq), 32);
System.out.println("=============================================================");
System.out.println("Consume from the queue: " + mq + "offset:" + getMessageQueueOffset(mq) + "结果:" + pullResult.getPullStatus());
putMessageQueueOffset(mq, pullResult.getNextBeginOffset());
switch (pullResult.getPullStatus()) {
case FOUND:
List messageExtList = pullResult.getMsgFoundList();
for (MessageExt m : messageExtList) {
System.out.print(new String(m.getBody()) +" == ");
}
System.out.println("");
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
break SINGLE_MQ;
case OFFSET_ILLEGAL:
break;
default:
break;
}
}
catch (Exception e) {
e.printStackTrace();
}
}
}
consumer.shutdown();
}
private static void putMessageQueueOffset(MessageQueue mq, long offset) {
offseTable.put(mq, offset);
}
private static long getMessageQueueOffset(MessageQueue mq) {
Long offset = offseTable.get(mq);
if (offset != null)
return offset;
return 0;
}
}
结果:

每次拉取消息的时候需要提供偏移量和拉取的消息的个数,需要自己业务实现每个主题下的队列的消费进度。
代码实现(1)这种方式只能拉取历史的消息,最新的消息拉取不了,也可以进行改造,来实现一直拉取。
3.2、代码实现(2)
在MQPullConsumer这个类里面,有一个MessageQueueListener,它的目的就是当queue发生变化的时候,通知Consumer。也正是这个借口,帮助我们在Pull模式里面,实现负载均衡。
注意,这个接口在MQPushConsumer里面是没有的,那里面有的是上面代码里的MessageListener。
void registerMessageQueueListener(final String topic, final MessageQueueListener listener);
public interface MessageQueueListener {
void messageQueueChanged(final String topic, final Set mqAll,
final Set mqDivided);
}
有了这个Listener,我们就可以动态的知道当前的Consumer分摊到了几个MessageQueue。然后对这些MessageQueue,我们可以开个线程池来消费。
public class PullConsumerExtend {
public static void main(String[] args) throws MQClientException {
//消费组
final MQPullConsumerScheduleService scheduleService = new MQPullConsumerScheduleService("pullConsumer");
//MQ NameService地址
scheduleService.getDefaultMQPullConsumer().setNamesrvAddr("10.10.12.203:9876;10.10.12.204:9876");
//负载均衡模式
scheduleService.setMessageModel(MessageModel.CLUSTERING);
//需要处理的消息topic
scheduleService.registerPullTaskCallback("TopicTest", new PullTaskCallback() {
@Override
public void doPullTask(MessageQueue mq, PullTaskContext context) {
MQPullConsumer consumer = context.getPullConsumer();
try {
long offset = consumer.fetchConsumeOffset(mq, false);
if (offset < 0)
offset = 0;
PullResult pullResult = consumer.pull(mq, "*", offset, 32);
System.out.println("");
System.out.println("Consume from the queue: " + mq + "offset:" + offset + "结果:" + pullResult.getPullStatus());
switch (pullResult.getPullStatus()) {
case FOUND:
List messageExtList = pullResult.getMsgFoundList();
for (MessageExt m : messageExtList) {
System.out.print(new String(m.getBody()) +" == ");
}
break;
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
case OFFSET_ILLEGAL:
break;
default:
break;
}
consumer.updateConsumeOffset(mq, pullResult.getNextBeginOffset());
//设置下一下拉取的间隔时间
context.setPullNextDelayTimeMillis(10000);
} catch (Exception e) {
e.printStackTrace();
}
}
});
scheduleService.start();
}
}
结果:

比较**代码实现(1)**这种方式改进了很多,不需要业务维护每个消费队列的消费进度,可以更新到服务端的。
弊端也很明显就是每次队列拉取消息的时间间隔,时间长导致消息挤压,时间段消息少,影响服务端性能。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。