ubuntu16+python3.7+tensorflow-gpu安装过程
ubuntu16+python3.7+tensorflow-gpu安装过程
- 安装情况
- 出现错误
- 列计划
-
- cuda安装问题
- 重启系统
- cudnn
- tensorflow-gpu
- 验证
- 后续(一周后)
- 结论
安装情况
配置一台ubuntu16的命令行服务器,无脑conda安装tensorflow-gpu后,测试时我只是import tensorflow,看没有问题就没继续管了。结果后来发现服务器无法启动gpu跑模型,本文记录下崎岖的解决问题的过程。
出现错误
在我用conda和pip移除了所有tensorflow依赖以后,验证gpu时出现以下错误:
tensorflow.python.framework.errors_impl.InternalError: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version
当时傻傻的准备卸载1.14改装1.13,后来证明依然不行
判定我的CUDA版本有问题(这里花费了不少时间在弄服务器的网)
本机cuda9 cudnn7.1.3
我的tensorflow版本是1.14.0,找不到与cuda对应关系
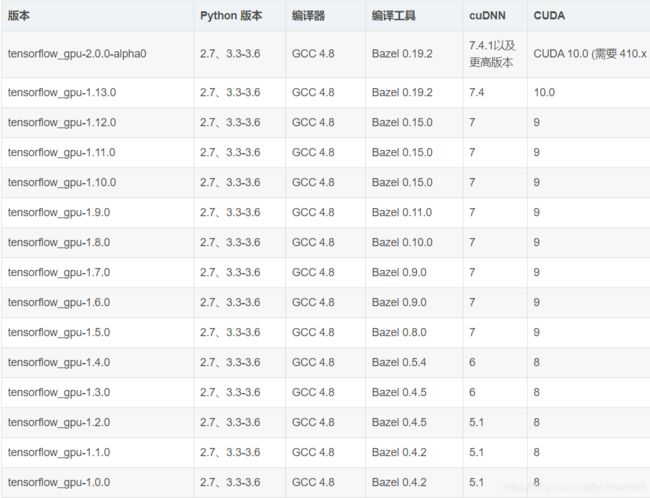
tensorflowgpu与各个版本需要的CUDA版本以及Cudnn的对应关系如上表
这里基本确定自己是要更新cuda了
列计划
干货
给了我很大启发,我很多步骤都是从此来的。
我直接从安装cuda10.0开始操作
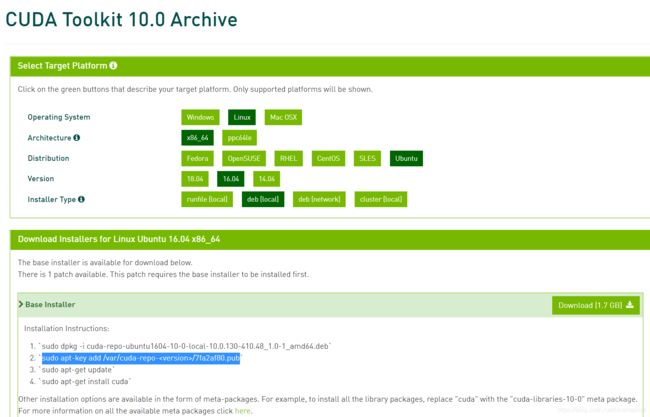
这里第二步有个是需要自己填写的
cd /var
ls -a
看到cuda-repo的文件夹,把名字拷贝过来代替version即可
cuda安装问题
1 dpkg的问题
W: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/dists/precise/InRelease
W: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/dists/precise-updates/InRelease
W: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/dists/precise-backports/InRelease
这里是因为当时我用迅雷下载东西导致网速变慢,连不上ubuntu服务器了
-----------------------(这里有误,大家看看就好)-----------------------------------------------------------------------------------------------
后来添加阿里云的ubuntu源和dns
sudo gedit /etc/apt/sources.list
deb http://mirrors.aliyun.com/ubuntu/ raring main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ raring-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ raring-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ raring-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ raring-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ raring main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ raring-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ raring-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ raring-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ raring-backports main restricted universe multiverse
sudo vi /etc/resolv.conf
#阿里云的DNS服务器
nameserver 223.5.5.5
nameserver 223.6.6.6
结果更加悲剧,出现找不到指定源的问题。
E: Failed to fetch http://mirrors.aliyun.com/ubuntu/dists/raring/main/source/Sources 404 Not Found
-------------------------------------(雾)-------------------------------------------------------------------------------------------------------------
后来我关了迅雷后,把所有东西恢复,即可安装。
期间出现了
/sbin/ldconfig.real: /usr/local/lib is not a known library type
的问题,事实证明不影响后面的结果,我就没管。
2 安装包的问题
期间由于自己的愚昧,把系统版本记成18了 结果先下载了18的cuda10.0
后来重新下载16的cuda后,dpkg时出现了
dpkg: error processing archive xxx.deb (--unpack):
trying to overwrite 'xxx', which is also in packagexxx
左思右想,明明把之前的解压包删除了,但还是出这个错,最后莽夫做法,直接强制安装,解决问题,命令如下:
sudo dpkg -i --force-overwrite xxx.deb
重启系统
shutdown -r now 立刻重启(root用户使用)
cudnn
安装比较正常。
tensorflow-gpu
最后没有用conda,而是用pip解决问题
pip install tensorflow-gpu==1.13.1
结果出现了一屏幕红字
最后更新pip
pip install --upgrade pip
再安装就没问题了
验证
import tensorflow as tf
# Creates a graph.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(c))
后续(一周后)
使用tensorflow1.13跑网络时,会莫名出现错误
ValueError: None values not supported.
发现是在算梯度时出现的错误
上网查到的解决办法都不能解决我的错误(参考链接)
/Users/laox1ao/anaconda/lib/python2.7/site-packages/keras/engine/training.pyc in _make_train_function(self)
988 training_updates = self.optimizer.get_updates(
989 params=self._collected_trainable_weights,
--> 990 loss=self.total_loss)
991 updates = self.updates + training_updates
992 # Gets loss and metrics. Updates weights at each call.
是由于网络存在ops的梯度为None,导致图的梯度流断裂(disconnected),检查发现是keras.backend.switch操作在以tensorflow为backend的情况下无法计算梯度,tf.gradients()返回结果为None
做了些对比实验,发现同样的数据源和同样的代码tensorflow1.14和1.12都不会报错,推测可能是该版本没有对这个场景做特殊处理。
于是着手安装1.14
经过无数弯路,最终安装了cuda10.1+tensorflow-gpu1.14.0
证实结果可行。
结论
别贪图简单就用conda安装tensorflow-gpu
首先应该搞清楚cuda版本再确定tensorflow版本
其次pip更加靠谱一些
最后再次感谢博主指路! 链接
纪念啥都没干,光配置环境的一天