MTCNN+Face_recognition实时人脸识别(一)基础环境的搭建/算法结合
文章内容介绍
这段时间一直有点小懒,写文章的进度有点慢。。无奈。。。
本文的目的是将mtcnn人脸检测算法和face-recognition算法结合起来,实现实时视频中人脸识别(1:N)。本project将会以两篇博客的形式书写,project的代码将会等文章书写完同步到本人的github上,有兴趣的朋友记得给个小星星。
注意:由于本人能力有限,本博客不对算法做解读,只是从代码层面(搭积木)实现了人脸识别,要是您追求算法细节,可以先去参考相关的算法解读博客!!
目录
第一篇博客:基础环境的搭建以及mtcnn算法与人脸识别算法的结合
1.人脸识别思路以及project代码思路的简要介绍;
2.算法环境的搭建以及相关依赖包的安装;
3.MTCNN算法与face-recognition算法结合的测试code;
第二篇博客:训练自己的人脸识别模型
1.数据集结构的介绍
2.利用KNN训练生成自己的人脸特征底库
3.多进程实时人脸识别
4.Project总结
一. 人脸识别思路及project代码思路的介绍
人脸识别思路
人脸识别是当今非常热门的技术之一,很多大公司已经把精度做到了99%以上,厉害~
人脸识别技术简单的实现流程是人脸检测(对齐)+人脸特征提取+人脸比对+输出识别结果;这个简单实现思路中,涉及到了两部分比较重要的算法,一部分是人脸检测算法,还有一部分就是人脸特征提取算法;
1.本博客就是按照这个简单的人脸识别思路进行人脸识别;
2.人脸检测部分算法采用的是mtcnn(其实face-recognition算法里面也有相关的人脸检测算法,dlib和cnn的)、
3.人脸特征提取部分算法采用的是face-recognition模块中的face_encoding模块、
4.特征提取以及生成底库特征采用的是KNN算法、
5.人脸比对采用的是通过计算待识别人脸128特征与底库人脸特征的欧式距离;

编程实现思路:
mtcnn算法进行人脸检测,同时将人脸在图像中的box坐标信息传递给face-recognition模块,通过face-recognitin的face-encoding函数对检测到的人脸进行128维的人脸特征提取,然后,将提取到的特征与底库特征人脸进行欧式距离的计算,最后输出人脸识别的结果。
在该部分,mtcnn人脸检测模型的训练可参考本人之前的博客,这里用的模型是已经训练好的。人脸特征提取之face-encoding函数所调用的模型为face-recognition预期训练好的特征提取模型,在下载face-recognition库的时候,同步下载了下来,本project直接使用。
二.算法环境搭建以及相关依赖库的安装
由于本人习惯了用anaconda来管理环境,所以,所有的环境配置都是通过conda创建了虚拟环境,然后在虚拟环境中进行相关packages的编译安装;
基础环境配置: NVIDIA-410.93显卡驱动 + CUDA10 + CUDNN 7.4 + python3.5
创建虚拟环境: conda create -n face_recognize python=3.5
1.mtcnn环境配置
在face_recognize环境中安装:
pip install tensorflow-gpu==1.13
pip install opencv-python
将本人精简后的mtcnn人脸检测代码放入project文件内;
2.face-recognition依赖库安装
在face_recognize环境中安装:
pip install cmake
pip install easydict
pip install scikit-learn pickle
pip install dlib
pip install face-recognition-models
源码下载face-recognition代码(pip安装也行,但是为了后面能够方便的调整参数,源码下载使用更为方便)
git clone https://github.com/ageitgey/face_recognition.git
下载下来后只需要保留文件夹中的face_recognition文件夹即可
文件夹结构分析:
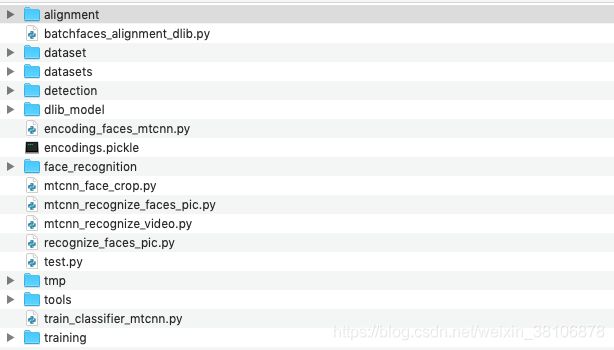
图中的face_recognition文件夹为刚刚github下载部分,tmp、datection、tools文件夹为mtcnn tensorflow版本简化后的代码以及要用到的库文件;其余的py文件为相关的使用脚本,训练模型、人脸比对等用途。。。。
三.MTCNN算法与face-recognition算法结合的测试code
这里就直接上代码,该部分代码为在图片中进行人脸识别;
用到的数据集为LFW人脸数据,所以测试识别的图也是LFW中的图;
代码:mtcnn_recognize_faces_pic.py
#coding: utf-8
#author: hxy
'''
人脸定位:mtcnn
测试模型在照片上的人脸识别情况
'''
import os
from cv2 import cv2 as cv2 #vscode中导入cv2老是提示报错,所以我用了这个方法导入
import time
import pickle
import numpy as np
import face_recognition
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg'}
# 加载mtcnn相关库和model
from training.mtcnn_model import P_Net, R_Net, O_Net
from tools.loader import TestLoader
from detection.MtcnnDetector import MtcnnDetector
from detection.detector import Detector
from detection.fcn_detector import FcnDetector
def net(stage):
detectors = [None, None, None]
if stage in ['pnet', 'rnet', 'onet']:
modelPath = '/home/lxz/project/faceid/main/tmp/model/pnet/'
a = [b[5:-6] for b in os.listdir(modelPath) if b.startswith('pnet-') and b.endswith('.index')]
maxEpoch = max(map(int, a)) # auto match a max epoch model
modelPath = os.path.join(modelPath, "pnet-%d"%(maxEpoch))
print("Use PNet model: %s"%(modelPath))
detectors[0] = FcnDetector(P_Net,modelPath)
if stage in ['rnet', 'onet']:
modelPath = '/home/lxz/project/faceid/main/tmp/model/rnet/'
a = [b[5:-6] for b in os.listdir(modelPath) if b.startswith('rnet-') and b.endswith('.index')]
maxEpoch = max(map(int, a))
modelPath = os.path.join(modelPath, "rnet-%d"%(maxEpoch))
print("Use RNet model: %s"%(modelPath))
detectors[1] = Detector(R_Net, 24, 1, modelPath)
if stage in ['onet']:
modelPath = '/home/lxz/project/faceid/main/tmp/model/onet/'
a = [b[5:-6] for b in os.listdir(modelPath) if b.startswith('onet-') and b.endswith('.index')]
maxEpoch = max(map(int, a))
modelPath = os.path.join(modelPath, "onet-%d"%(maxEpoch))
print("Use ONet model: %s"%(modelPath))
detectors[2] = Detector(O_Net, 48, 1, modelPath)
return detectors
# distance_threshold数值的设定越小比对则越严格, 0.6为默认值
def predict(X_img_path, knn_clf=None, model_path=None, distance_threshold=0.6):
pic_list = []
face_location = []
#加载分类模型
with open(model_path, 'rb') as f:
knn_clf = pickle.load(f)
pic_list.append(X_img_path)
testDatas = TestLoader(pic_list)
# 这里需要注意boxes坐标信息的处理
allBoxes, _ = mtcnnDetector.detect_face(testDatas)
for box in allBoxes[0]:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
face_location.append((y1-10, x2+12, y2+10, x1-12)) # 适当调节定位范围,防止人脸关键位置遗漏
print(face_location)
# If no faces are found in the image, return an empty result.
if len(allBoxes[0]) == 0:
print('No face find in pic!!!!')
return []
# Find encodings for faces in the test iamge
X_img = face_recognition.load_image_file(X_img_path)
star = time.time()
# face_encodings api里面有个参数设定 num_jitters 数值越大,精度相对会高,默认为1
faces_encodings = face_recognition.face_encodings(X_img, known_face_locations=face_location, num_jitters=6)
end = time.time()
print('face_encodings cost: {} s'.format(end-star))
# Use the KNN model to find the best matches for the test face
closest_distances = knn_clf.kneighbors(faces_encodings, n_neighbors=1)
are_matches = [closest_distances[0][i][0] <= distance_threshold for i in range(len(face_location))]
# Predict classes and remove classifications that aren't within the threshold
return [(pred, loc) if rec else ("unknown", loc) for pred, loc, rec in zip(knn_clf.predict(faces_encodings), face_location, are_matches)]
def show_results(img_path, predictions):
image = cv2.imread(img_path)
for name, (top, right, bottom, left) in predictions:
cv2.putText(image, str(name), (left, top-10), cv2.FONT_HERSHEY_TRIPLEX, 1, color=(0,255,0))
cv2.rectangle(image, (left, top),(right, bottom), (0, 0, 255), 2)
cv2.imwrite(str(img_path)+'.jpg', image)
cv2.imshow('Recognition_Results', image)
cv2.waitKey(500)
cv2.destroyAllWindows()
if __name__=='__main__':
detectors = net('onet')
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
mtcnnDetector = MtcnnDetector(detectors=detectors, min_face_size = 40, threshold=[0.9, 0.6, 0.7])
for image_file in os.listdir("/home/hxy/project/faceid/datasets/test"):
full_file_path = os.path.join("/home/hxy/project/faceid/datasets/test", image_file)
predictions = predict(full_file_path, model_path="/home/hxy/project/faceid/LFW_classifier_model.clf")
show_results(os.path.join("/home/hxy/project/faceid/datasets/test", image_file), predictions)
该部分代码只是简单的展示了照片中人脸识别的基本流程。主要的代码请看代码中predict函数。基本的人脸识别流程也在代码中展示出来了,看懂了此部分代码,下一篇博客你就会更加轻松!若代码有不足之处,请指出!谢谢!(代码传到csdn上,貌似格式有点不怎么好看。。。。 尴尬)
照片的识别的结果图:




最后,等国庆假期这几天我把整个peoject代码上传到github上,同时,将下一部分的内容完善!!文中有不足之处还请各位技术大佬多多谅解!欢迎指出不足之处,互相学习,共同进步!!文章仅供学习参考