一、基本使用
selenium 的基本使用步骤:
- 打开浏览器;
- 获取浏览器页面的特定内容;
- 控制浏览器页面上的控件,如向一个文本框中输入一个字符串;
- 关闭浏览器。
示例:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
browser = webdriver.Chrome()
try:
browser.get('https://www.jd.com')
input_t = browser.find_element_by_id('key')
input_t.send_keys('python爬虫')
input_t.send_keys(Keys.ENTER) # 模拟按下Enter键位
wait = WebDriverWait(browser, 4) # 设置最长等待时间4秒
wait.until(ec.presence_of_all_elements_located((By.ID, 'J_goodsList')))
print(browser.title) # 显示搜索页面的标题
print(browser.current_url)
print(browser.page_source)
browser.close()
except Exception as e:
print(e)
browser.close()
二、查找节点
2.1 查找单个节点
html 源码如下:
表单
姓名:
年龄:
国家:
收入:
样式如下图所示:
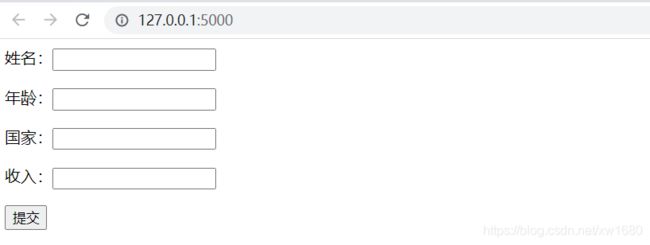
python 代码自动填充上图中的表单:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 不支持本地网页
browser = webdriver.Chrome()
try:
# 这里我是用flask自己搭建的一个服务 访问该页面即可打开demo.html
browser.get('http://127.0.0.1:5000/')
input_t = browser.find_element_by_id('name') # 通过id属性查找姓名input节点
input_t.send_keys('Amo') # 自动输入
input_t = browser.find_element_by_id('age')
input_t.send_keys('18')
input_t = browser.find_element_by_name('country') # 通过name属性查找国家input节点
input_t.send_keys('中国')
# 通过class属性查找收入input节点
input_t = browser.find_element_by_class_name('myclass')
input_t.send_keys('1850')
# 或下面的代码
input_t = browser.find_element(By.CLASS_NAME, 'myclass')
# 要想覆盖前面的输入,需要清空input节点,否则会在input节点原来的内容后面追加新内容
input_t.clear()
input_t.send_keys('3500')
except Exception as e:
print(e)
browser.close()
效果如下图所示:
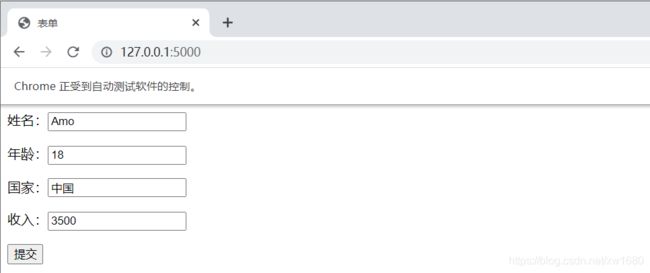
2.2 查找多个节点
示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 不支持本地网页
browser = webdriver.Chrome()
try:
browser.get('https://www.jd.com') # 打开京东
# 根据节点名查找所有名为li的节点
li_list = browser.find_elements_by_tag_name('li')
# 输出节点本身
print(li_list)
print(len(li_list))
print(li_list[0].text)
ul = browser.find_elements(By.TAG_NAME, 'ul')
print(ul)
print(ul[0].text)
browser.close()
except Exception as e:
print(e)
browser.close()
三、节点交互
使用 selenium 通过模拟浏览器单击动作循环单击页面上的6个按钮,单击每个按钮后,按钮下方的 div 就会按照按钮的背景颜色设置 div 的背景色。
demo1.html 静态页面代码如下:
彩色按钮
然后使用 Python 代码模拟浏览器的单击动作自动单击页面上的 6 个按钮。P
ython 代码如下所示:
from selenium import webdriver
import time
browser = webdriver.Chrome()
try:
browser.get('http://127.0.0.1:5000/')
buttons = browser.find_elements_by_class_name('mybutton')
i = 0
while True:
buttons[i].click()
time.sleep(1)
i += 1
if i == len(buttons):
i = 0
except Exception as e:
print(e)
browser.close()
四、动作链
使用 selenium 动作链的 move_to_element 方法模拟鼠标移动的动作,自动显示京东商城首页左侧的每个二级导航菜单。
示例代码如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
try:
browser.get('https://www.jd.com')
actions = ActionChains(browser)
li_list = browser.find_elements_by_css_selector(".cate_menu_item")
for li in li_list:
actions.move_to_element(li).perform()
time.sleep(1)
except Exception as e:
print(e)
browser.close()
使用 selenium 动作链的 drag_and_drop 方法将一个节点拖动到另外一个节点上。
示例代码如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
try:
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
except Exception as e:
print(e)
browser.close()
五、执行 JavaScript 代码
使用 selenium 的 execute_script 方法让京东商城首页滚动到最低端,然后弹出一个对话框。示
例代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_async_script('alert("已经到达页面底端")')
六、获取节点信息
使用 selenium 的 API 获取京东商城首页 HTML 代码中 id 为 navitems-group1 的 ul 节点的相关信息以及 ul 节点中 li 子节点的相关信息。
示例代码如下:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome(chrome_options=options)
# browser = webdriver.PhantomJS('./webdriver/phantomjs')
browser.get('https://www.jd.com')
ul = browser.find_element_by_id("navitems-group1")
print(ul.text)
print('id', '=', ul.id) # 内部id,不是节点id属性值
print('location', '=', ul.location)
print('tag_name', '=', ul.tag_name)
print('size', '=', ul.size)
li_list = ul.find_elements_by_tag_name("li")
for li in li_list:
print(type(li))
# 属性没找到,返回None
print('<', li.text, '>', 'class=', li.get_attribute('class'))
a = li.find_element_by_tag_name('a')
print('href', '=', a.get_attribute('href'))
browser.close()
执行结果如下:
秒杀
优惠券
PLUS会员
品牌闪购
id = 6bb622fb-df60-4619-a373-b55e44dc27af
location = {'x': 203, 'y': 131}
tag_name = ul
size = {'height': 40, 'width': 294}
< 秒杀 > class= fore1
href = https://miaosha.jd.com/
< 优惠券 > class= fore2
href = https://a.jd.com/
< PLUS会员 > class= fore3
href = https://plus.jd.com/index?flow_system=appicon&flow_entrance=appicon11&flow_channel=pc
< 品牌闪购 > class= fore4
href = https://red.jd.com/
七、管理 Cookies
使用 selenium API 获取 cookie 列表,并添加新的 cookie,以及删除所有的 cookie。
示例代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
print(browser.get_cookies())
browser.add_cookie({'name': 'name',
'value': 'jd', 'domain': 'www.jd.com'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies()) # 大部分删除了,可能还剩下一些
八、改变节点属性的值
通过 javascript 代码改变百度搜索按钮的位置,让这个按钮在多个位置之间移动,时间间隔是2秒。
示例代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
search_button = driver.find_element_by_id("su") # 百度搜索按钮
# arguments[0]对应的是第一个参数,可以理解为python里的%s传参,与之类似
x_positions = [50, 90, 130, 170]
y_positions = [100, 120, 160, 90]
for i in range(len(x_positions)):
js = '''
arguments[0].style.position = "absolute";
arguments[0].style.left="{}px";
arguments[0].style.top="{}px";
'''.format(x_positions[i], y_positions[i])
driver.execute_script(js, search_button)
time.sleep(2)
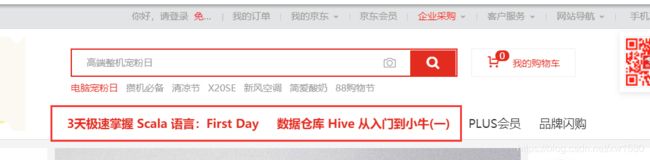
使用 javascript 代码修改京东商城首页顶端的前两个导航菜单的文本和链接,分别改成 ‘3天极速掌握 Scala 语言:First Day' 和 ‘数据仓库 Hive 从入门到小牛(一)',导航链接也会发生改变。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.jd.com")
ul = driver.find_element_by_id('navitems-group1')
li_list = ul.find_elements_by_tag_name('li')
a1 = li_list[0].find_element_by_tag_name('a')
a2 = li_list[1].find_element_by_tag_name('a')
js = '''
arguments[0].text = '3天极速掌握 Scala 语言:First Day'
arguments[0].href = 'https://blog.csdn.net/xw1680/article/details/118743183'
arguments[1].text = '数据仓库 Hive 从入门到小牛(一)'
arguments[1].href = 'https://blog.csdn.net/xw1680/article/details/118675528'
'''
driver.execute_script(js, a1, a2)
效果如下图所示:
到此这篇关于教你快速上手Selenium爬虫,万物皆可爬的文章就介绍到这了,更多相关Selenium爬虫内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!