深度学习基础--分类网络
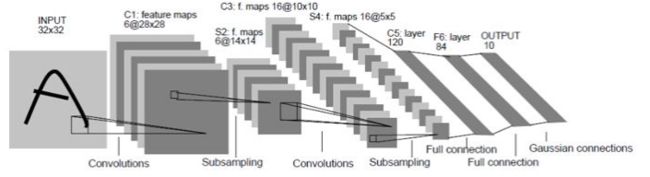
一、LetNet
LetNet网络是CNN网络的鼻祖,定义了CNN的基本部件:卷积层、池化层全连接层等。
二、AlexNet
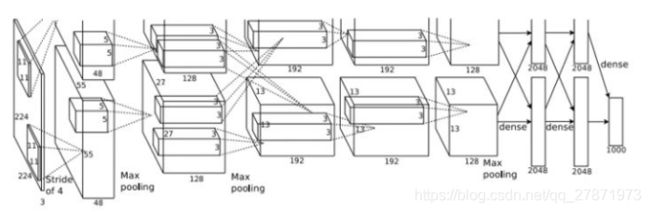
主要特点:
1、使用ReLU函数作为CNN的激活函数;
2、Dropout技术和数据增强技术的使用,防止模型过拟合;
3、当时计算性能满足不了网络需求,使用group conv技术;
4、基于神经科学中局部神经元活动竞争机制,提出LRN层,类似于在通道维度上做normalization,使得响应比较大的数值变大相对更大,以此抑制反馈比较小的filter。
LRN层(Local Response Normalization)个人理解:神经科学上来说,局部神经元互相之间有竞争,当多个神经元共同接受一个信号时,哪一个神经元表现的比较好,经过LRN处理之后(标准化后),该神经元相对应该更加明显。
在图像经过卷积层时,feature map会被多个filters采样,对于feature map上某一个点,filters之间会竞争,我们应该他们做一个标准化,突出他们之间的相对大小。因此是在通道维度上做normalization,这个层在后面的网络结构发展中,再也没怎么用了。
三、VGG
VGG网络通过堆叠3x3卷积和2x2最大池化层成功构建了一个较深层的网络。目前,VGG系列中的部分网络仍然被用来作为特征提取网络。
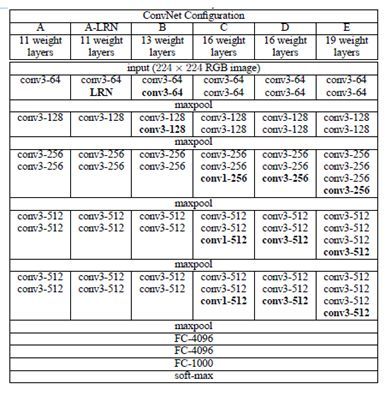
主要内容:
1、两个3x3的卷积层堆叠相当于一个5x5的卷积层的感受野大小,但是比5x5参数量更少,多一个卷积层多了更多的非线性。
2、使用网络权重pre-train技巧,先训练浅层网络,用浅层网络的权重去微调深层网络。
四、Google的Inception系列
Inception 系列是网络结构的神作,其中的多尺寸卷积和多个小卷积核替代大卷积核等概念是以后网络架构的基石。Inception网络系列的发展核心的思想就是模块化!Inception 的最初版本,其核心思想就是使用多尺寸卷积核去观察输入数据。比如我们看某个图像由于远近不同,同一个物体的大小也会有所不同,用不同尺度的卷积核提取特征会有这样的效果。于是有如下的网络:
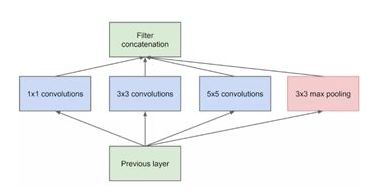
网络就变宽了,同时也提高了对于不同尺度的适应程度。问题来了: 网络变宽的同时,计算量也变大,要想办法减少参数量来减少计算量,于是在 Inception v1 中的最终版本加上 1x1 卷积核(Pointwise Conv)。
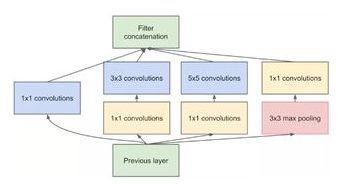
使用PW卷积核对输入的特征图进行降维,减少参数量,从而减少计算。 即使有 PW ,由于 5x5 卷积核参数量还是很大,要再优化。于是使用多个小卷积核替代大卷积核的方法,这就是 Inception v3:

用两个 3x3 卷积核来代替 5x5 卷积,(感受野大小)效果上差不多,但参数量减少很多,达到了优化的目的。不仅参数量少,层数也多了,深度也变深了。 除了规整的正方形,还有分解版本的 3x3 = 3x1 + 1x3,这个效果在深度较深的情况下比规整的卷积核更好。
我们假设输入 256 维,输出 512 维,计算一下参数量:
5x5 卷积核 256∗5∗5∗512=3276800
两个 3x3 卷积核 256∗3∗3∗256+256∗3∗3∗512=589824+1179648=1769472
参数量对比,两个 3x3 的卷积核的参数量是 5x5 一半,可以大大加快训练速度。
当然,Inception系列的贡献还有很多,比如:
1、使用BN层的Inception V2网络。
2、结合Resnet网络结构的Inception V4网络。
3、Inception系列提出辅助分类节点,即是在多个特征层次(浅层预测结合深层预测)上给出预测输出。
五、Resnet
网络特点: 跳跃链接和瓶颈结构
网络深度在增加中会遇到两个问题:1、梯度消失;2、网络退化。
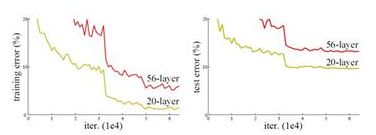
网络更深时意味着需要学习的参数更大,优化问题变得更难,简单地增加网络深度反而出现更高的训练误差。即增加网络层数却导致更大的误差,如下图,一个56层的网络的性能却不如20层的性能好,这不是因为过拟合(训练集训练误差依然很高),是退化问题。
输入数据有两条路线,一条常规路线,另一条捷径(shortcut),直接实现单位映射的直接连接的路线,这有点类似与电路中的“短路”。把网络中的一个模块的输入和输出关系看作是y=H(x),那么直接通过梯度方法求H(x)就会遇到上面提到的退化问题,如果使用带shortcut的结构,可变参数部分的优化目标不再是H(x),若用F(x)来代表需要优化的部分,则H(x)=F(x)+x,也就是F(x)=H(x)-x。因为在单位映射的假设中y=x就相当于观测值,所以F(x)就对应着残差,因而叫残差网络。 学习残差F(X)比直接学习H(X)简单。设想,现在只需要去学习输入和输出的差值就可以,绝对量变为相对量(H(x)-x 就是输出相对于输入变化了多少),优化会简单很多。
学过模拟电子技术的同学,会不会觉得这残差结构的跳跃链接不就是模电中的差分放大电路嘛。
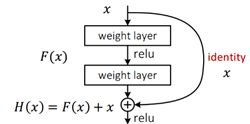
上图中x经过卷积层后的输出和直接跳跃的x在数据维度上可能不匹配,Resnet网络主要采用两种方法解决这个问题:
- zero_padding:对恒等层进行0填充的方式将维度补充完整,这种方法不会增加额外的参数。
- projection:在恒等层采用1x1的卷积核来增加维度,这种方法会增加额外的参数 。
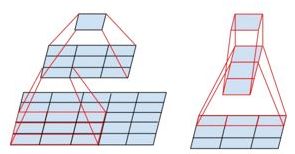
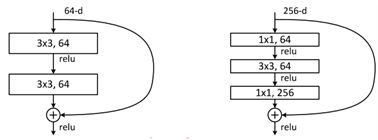
下图是两种形态的残差模块,左图是常规残差模块,有两个3×3卷积核组成,但是随着网络进一步加深,这种残差结构在实践中并不是十分有效。针对这右图的“瓶颈残差模块”(bottleneck residual block)可以有更好的效果,由1×1、3×3、1×1这三个卷积层堆积而成,这里的1×1的卷积能够起降维或升维的作用,从而令3×3的卷积可以在相对较低维度的输入上进行,以达到提高计算效率的目的。
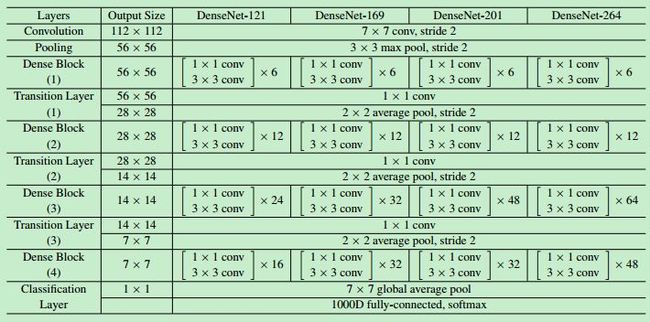
六、DenseNet
主要创新:特征重用和旁路设置。
在此之前,网络发展从加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能,而DenseNet从特征出发,通过特征重用(联合低级和高级图像特征)和旁路(Bypass)设置,不仅减少了网络的参数量,而且一定程度上缓解梯度消失问题。DenseNet有以下优点:
- 与ResNet对比,更少的特征就能达到resnet的性能,且short path链接模式不同,DenseNet使用的是concatenate操作,而ResNet使用add链接。
- 旁路加强了特征(feature map)的重用,因为大量特征图的重用,网络不必学习冗余的特征图,DenseNet需要更少的参数(不需要太多的filters去采样),网络更易训练。
- 由于每一层都连接最前层和最后面层,则最初信号和最初梯度都能收到,网络内含有隐式的深度监督。
ResNet假设:若某一较深的网络多出另一较浅网络的若干层有能力学习到恒等映射,那么这一较深网络训练得到的模型性能一定不会弱于该浅层网络。
DenseNet假设:与其多次学习冗余的特征,特征复用是一种更好的特征提取方式。
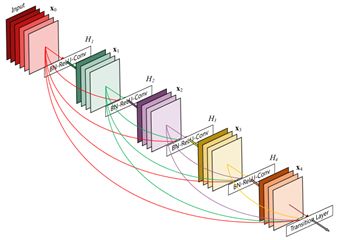
单个Dense Block
DenseNet将这种密集连接的结构分成多个block,每个block中使用Dense连接且feature maps尺寸相同,然后多个block组成一个DenseNet网络,每个block之间用transition layer(BN—conv_1x1—pool_avg_2x2)连接(实现pooling下采样)。
 DenseNet结构,红色框出的是transition layer。
DenseNet结构,红色框出的是transition layer。
具体结构: