关联规则Apriori算法例子
文章目录
- 前言
- 支持度、置信度、提升度
- 举例
- 总结
前言
什么是AI?
The theory and development of computer systems able to perform tasks normally requiring human intelligence.(–Oxford Dictionary)
Using data to solve problems.(–cy)
支持度、置信度、提升度
1.支持度:是个百分比,指的是某个商品组合出现的次数与总次数之间的比例,支持度越高,代表这个组合出现的频率越大;
2.置信度:置信度(A→B)是个条件概念。指的是当你购买了商品A,会有多大的概率购买商品B;
3.提升度:商品A的出现,对商品B的出现概率提升的程度。提升度(A→B)=置信度(A→B)/支持度(B);
提升度的三种可能:提升度(A→B)>1:代表有提升;提升度(A→B)=1:代表有没有提升,也没有下降;提升度(A→B)<1:代表有下降。
举例
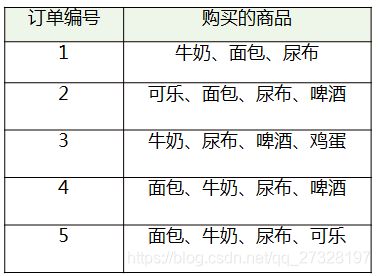
有下图这样一组订单:
from efficient_apriori import apriori
# 设置数据集
transactions = [('牛奶','面包','尿布'),
('可乐','面包', '尿布', '啤酒'),
('牛奶','尿布', '啤酒', '鸡蛋'),
('面包', '牛奶', '尿布', '啤酒'),
('面包', '牛奶', '尿布', '可乐')]
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(transactions, min_support=0.5, min_confidence=1)
print("频繁项集:\n", itemsets)
print("关联规则:\n", rules)
频繁项集:
{1: {(‘牛奶’,): 4, (‘尿布’,): 5, (‘面包’,): 4, (‘啤酒’,): 3}, 2: {(‘尿布’, ‘牛奶’): 4, (‘尿布’, ‘面包’): 4, (‘牛奶’, ‘面包’): 3, (‘啤酒’, ‘尿布’): 3}, 3: {(‘尿布’, ‘牛奶’, ‘面包’): 3}}
关联规则:
[{牛奶} -> {尿布}, {面包} -> {尿布}, {啤酒} -> {尿布}, {牛奶, 面包} -> {尿布}]
#看一下频繁项集
print(itemsets)
print(type(itemsets))
{1: {(‘牛奶’,): 4, (‘尿布’,): 5, (‘面包’,): 4, (‘啤酒’,): 3}, 2: {(‘尿布’, ‘牛奶’): 4, (‘尿布’, ‘面包’): 4, (‘牛奶’, ‘面包’): 3, (‘啤酒’, ‘尿布’): 3}, 3: {(‘尿布’, ‘牛奶’, ‘面包’): 3}}
for k,value in itemsets.items():#最前面的数字123代表商品组合数 分别代表1件 2件 3件商品的组合
print(k,value)#{
}括号里面又是():数字,()代表商品组合名称,:后面的数字代表()商品组合出现的次数
#支持度小于0.5的已经被pass了,因为设置的min_support=0.5
1 {(‘牛奶’,): 4, (‘尿布’,): 5, (‘面包’,): 4, (‘啤酒’,): 3}
2 {(‘尿布’, ‘牛奶’): 4, (‘尿布’, ‘面包’): 4, (‘牛奶’, ‘面包’): 3, (‘啤酒’, ‘尿布’): 3}
3 {(‘尿布’, ‘牛奶’, ‘面包’): 3}
#看一下关联规则
print(rules)#关联规则是置信度和支持度都满足
#这里的意思就是说 {
}里面的组合支持度 大于0.5 并且 {
}->{
} 前面括号对后面括号的置信度等于1(因为设置的置信度最小值是1 本身置信度最大值也是1)
print(type(rules))
[{牛奶} -> {尿布}, {面包} -> {尿布}, {啤酒} -> {尿布}, {牛奶, 面包} -> {尿布}]
总结
(如果您发现我写的有错误,欢迎在评论区批评指正)。