TensorFlow综合实例——卫星图像识别(tf.data、卷积神经网络)
卫星图像识别实例
- 数据预处理
- tf.data相关处理方法
- 卷积神经网络(CNN)
识别卫星图像中的飞机和湖泊,所以实际是个二分类问题。
import tensorflow as tf
print('TensorFlow version:{}'.format(tf.__version__))
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# 面向对象路径管理工具
import pathlib
路径处理
data_dir = './dataset/2_class'
# 构建路径对象
data_root = pathlib.Path(data_dir)
data_root
![]()
# iterdir:对目录进行迭代
for item in data_root.iterdir():
print(item)
![]()
# 提取所有路径
all_image_path = list(data_root.glob('*/*')) # 所有目录中的所有文件
# 查看前三张
all_image_path[0:3]
# 查看最后三张
all_image_path[-3:]
# 将WindowsPath格式的地址转为str类型的
all_image_path = [str(path) for path in all_image_path]
数据预处理
import random
# 将图片路径乱序处理
random.shuffle(all_image_path)
# 获取图片总数
image_count = len(all_image_path)
# 获取分类名称
label_names = sorted(item.name for item in data_root.glob('*/')) # 提取所有目录名
![]()
# 为分类进行自动编码
label_to_index =dict((name,index) for index,name in enumerate(label_names))
![]()
# 取出图片的上一级路径名为它的label
pathlib.Path('dataset/2_class/lake/lake_700.jpg').parent.name
# 将所有的图片与它对应的标签序号对应
all_image_label = [label_to_index[pathlib.Path(p).parent.name] for p in all_image_path]
显示图片
# 引入显示图片
import IPython.display as display
# 构造(序号:标签)字典
index_to_label = dict((value,key) for key,value in label_to_index.items())
# 随机选择三张图片进行显示
for n in range(3):
image_index = random.choice(range(len(all_image_path))) # 从all_image_path的长度中随机选择一个数字
display.display(display.Image(all_image_path[image_index])) # 显示图片
print(index_to_label[all_image_label[image_index]]) # 显示图片对应label
print()
使用tensorflow的方式读取图片(二进制格式)
# 使用tensorflow的方法读取图片(二进制形式
img_raw = tf.io.read_file(img_path)
# 对图片数据进行解码
img_tensor = tf.image.decode_image(img_raw)
# 数据类型转换:uint8->float
img_tensor = tf.cast(img_tensor,tf.float32)
# 数据标准化:归一化
img_tensor = img_tensor/255
将预处理封装成一个函数
# 加载和预处理函数:读取、解码、类型转换、标准化
def load_preprosess_img(path):
# 使用tensorflow的方法读取图片(二进制形式
img_raw = tf.io.read_file(img_path)
# 对图片数据进行解码
img_tensor = tf.image.decode_jpeg(img_raw,channels=3)
# 改变图像大小的方法。此处无实际作用,只是告诉tensorflow图片的大小
img_tensor = tf.image.resize(img_tensor,[256,256])
# 数据类型转换:uint8->float
img_tensor = tf.cast(img_tensor,tf.float32)
# 数据标准化:归一化
img = img_tensor/255
return img
# 构建地址dataset
path_ds = tf.data.Dataset.from_tensor_slices(all_image_path)
# 通过对每一个元素进行load_preprosess_img变化的得到一个新的dataset
image_dataset = path_ds.map(load_preprosess_img)
# 构造标签dataset
label_dataset = tf.data.Dataset.from_tensor_slices(all_image_label)
for label in label_dataset.take(10):
print(label.numpy())
#将两个dataset进行合并对应
dataset = tf.data.Dataset.zip((image_dataset,label_dataset))
# 划分训练数据和测试数据
test_count = int(image_count*0.2)
train_count = image_count - test_count
# 跳过test_count张数据,剩下的作为训练数据
train_dataset = dataset.skip(test_count)
test_dataset = dataset.take(test_count)
BATCH_SIZE = 32
# 将训练数据集进行乱序、重复和分批次
train_dataset = train_dataset.repeat().shuffle(train_count).batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
建立模型
model = tf.keras.Sequential() # 顺序模型
model.add(tf.keras.layers.Conv2D(64,(3,3),input_shape = (256,256,3),activation = 'relu'))
model.add(tf.keras.layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(tf.keras.layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(256,(3,3),activation = 'relu'))
model.add(tf.keras.layers.Conv2D(256,(3,3),activation = 'relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(512,(3,3),activation = 'relu'))
model.add(tf.keras.layers.Conv2D(512,(3,3),activation = 'relu'))
model.add(tf.keras.layers.MaxPooling2D())
model.add(tf.keras.layers.Conv2D(1024,(3,3),activation = 'relu'))
model.add(tf.keras.layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(1024,activation='relu'))
model.add(tf.keras.layers.Dense(256,activation='relu'))
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))
配置、训练模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
steps_per_epoch = train_count//BATCH_SIZE
validation_steps = test_count//BATCH_SIZE
history = model.fit(train_dataset,epochs = 30,steps_per_epoch = steps_per_epoch,validation_data=test_dataset,validation_steps = validation_steps)
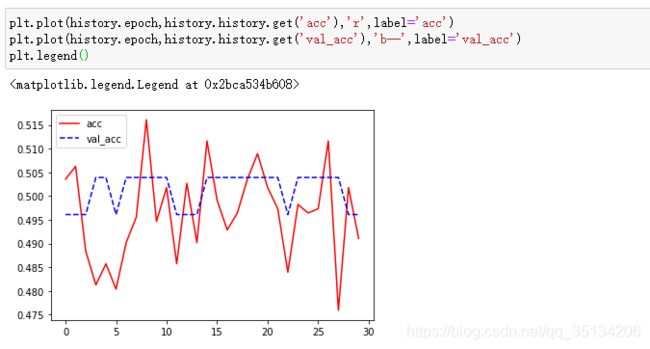
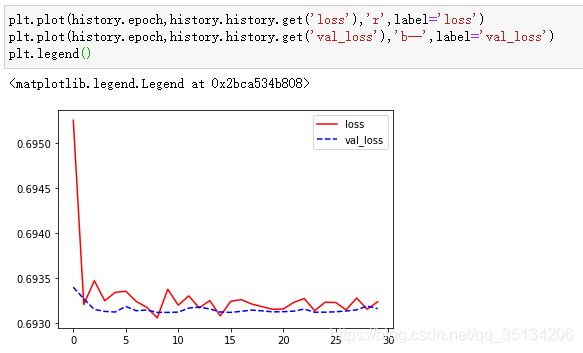
碎碎念:
cpu训练好慢好慢,笔记本gpu又太垃圾,虽说还有kaggle平台,但上传一个数据集已经将我折磨到疯掉了!心情很down。。。所以今天就先到这了,跑步去了。。。先逃离一会