如何快速掌握MYSQL?附牛客网精选的50道SQL题目详解【新手推荐】
如何才能快速掌握MYSQL?如何熟悉使用SQL以满足日常工作需求?
如果你目前啥也不会,只停留在知道SELECT用于查询的层面的话,又想要快速掌握MYSQL,那么刷题,并且过程中不会什么补什么,就是巩固和提升自己的SQL语言能力最快捷的方法。
在之前的一篇博客中,我给出了LeetCode上出现频率最高的50道数据库题目详解,那么这一次,我也SQ给出了牛客网上的50道SQL题,希望对大家有所收获。
补充:牛客网相对于LeetCode而言题目较少,且难度较低一些,但胜在免费,并且有些公司笔试的时候会直接饮用牛客网上的原题,所以也非常值得我们去刷一刷题。
目录
- SQL1 入门 查找最晚入职员工的所有信息
- SQL2 简单 查找入职员工时间排名倒数第三的员工所有信息
- SQL3 中等 查找当前薪水详情以及部门编号dept_no
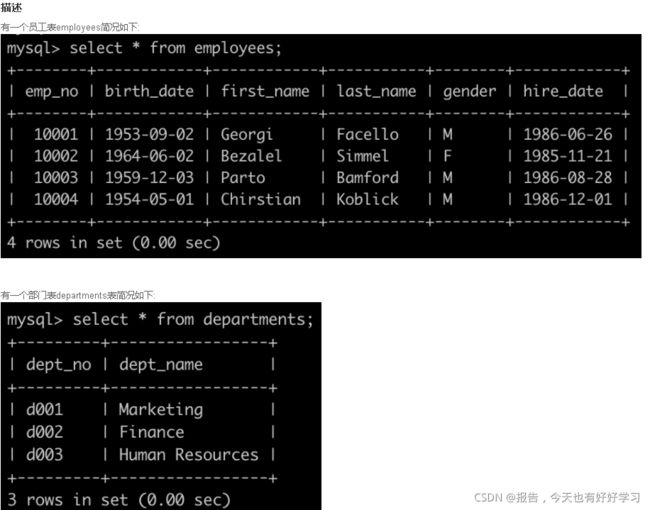
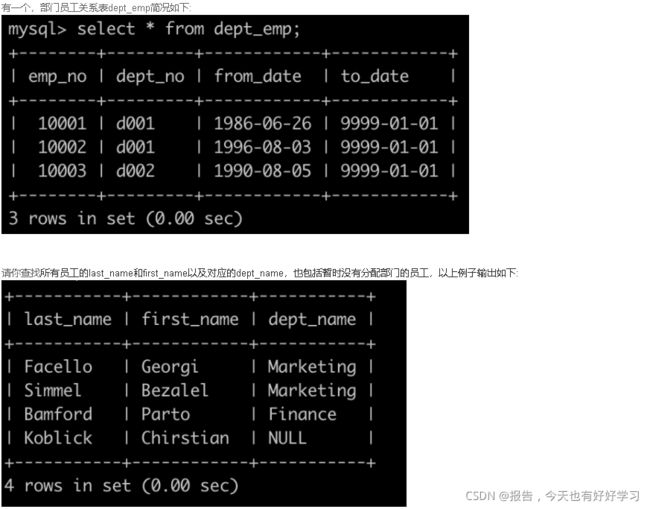
- SQL4 简单 查找所有已经分配部门的员工的last_name和first_name以及dept_no
- SQL5 中等 查找所有员工的last_name和first_name以及对应部门编号dept_no
- SQL7 简单 查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t
- SQL8 简单 找出所有员工当前薪水salary情况
- SQL10 简单 获取所有非manager的员工emp_no
- SQL11 中等 获取所有员工当前的manager
- SQL12 困难 获取每个部门中当前员工薪水最高的相关信息
- SQL15 简单 查找employees表emp_no与last_name的员工信息
- SQL16 中等 统计出当前各个title类型对应的员工当前薪水对应的平均工资
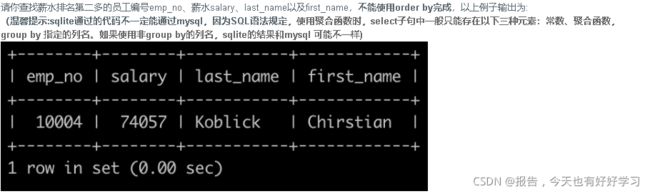
- SQL17 简单 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
- SQL18 较难 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
- SQL19 中等 查找所有员工的last_name和first_name以及对应的dept_name
- SQL21 困难 查找在职员工自入职以来的薪水涨幅情况
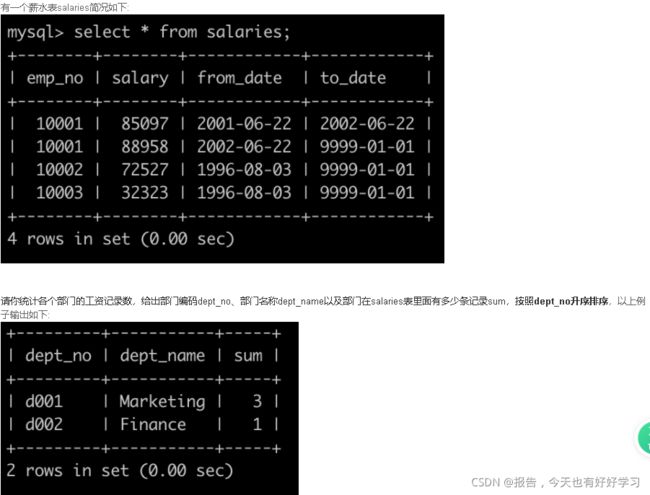
- SQL22 中等 统计各个部门的工资记录数
- SQL23 较难 对所有员工的薪水按照salary降序进行1-N的排名
- SQL24 较难 获取所有非manager员工当前的薪水情况
- SQL25 困难 获取员工其当前的薪水比其manager当前薪水还高的相关信息
- SQL26 困难 汇总各个部门当前员工的title类型的分配数目
- SQL29 中等 使用join查询方式找出没有分类的电影id以及名称
- SQL30 中等 使用子查询的方式找出属于Action分类的所有电影对应的title,description
- SQL32 简单 将employees表的所有员工的last_name和first_name拼接起来作为Name
- SQL33 中等 创建一个actor表,包含如下列信息
- SQL38 中等 针对actor表创建视图actor_name_view
- SQL50 中等 将employees表中的所有员工的last_name和first_name通过引号连接起来。
- SQL51 中等 查找字符串 10,A,B 中逗号,出现的次数cnt
- SQL52 中等 获取Employees中的first_name
- SQL53 中等 按照dept_no进行汇总
- SQL54 中等 平均工资
- SQL55 中等 分页查询employees表,每5行一页,返回第2页的数据
- SQL57 中等 使用含有关键字exists查找未分配具体部门的员工的所有信息。
- SQL59 较难 获取有奖金的员工相关信息。
- SQL60 较难 统计salary的累计和running_total
- SQL61 较难 对于employees表中,给出奇数行的first_name
- SQL65 较难 异常的邮件概率
- SQL66 简单 牛客每个人最近的登录日期(一)
- SQL67 较难 牛客每个人最近的登录日期(二)
- SQL68 较难 牛客每个人最近的登录日期(三)
- SQL69 较难 牛客每个人最近的登录日期(四)
- SQL70 困难 牛客每个人最近的登录日期(五)
- SQL71 较难 牛客每个人最近的登录日期(六)
- SQL87 中等 最差是第几名(一)
- SQL88 较难 最差是第几名(二)
- SQL89 中等 获得积分最多的人(一)
- SQL90 较难 获得积分最多的人(二)
- SQL91 困难 获得积分最多的人(三)
- SQL92 中等 商品交易(网易校招笔试真题)
- SQL93 较难 网易云音乐推荐(网易校招笔试真题)
- 结束语
SQL1 入门 查找最晚入职员工的所有信息
原题链接

SELECT * FROM employees
WHERE hire_date = (SELECT max(hire_date) FROM employees)
SQL2 简单 查找入职员工时间排名倒数第三的员工所有信息
原题链接
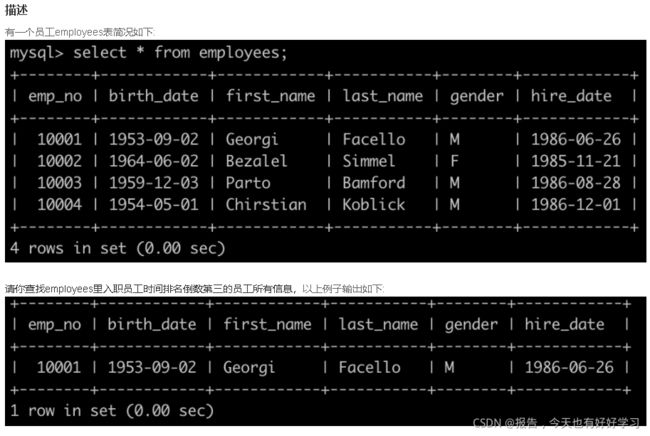
/*
with tmp as (
SELECT *, rank() over(order by hire_date desc) rk
FROM employees
)
SELECT emp_no, birth_date, first_name, last_name, gender, hire_date
FROM tmp
WHERE rk=3
*/
SELECT *
FROM employees
order by hire_date DESC
LIMIT 2,1
SQL3 中等 查找当前薪水详情以及部门编号dept_no
原题链接
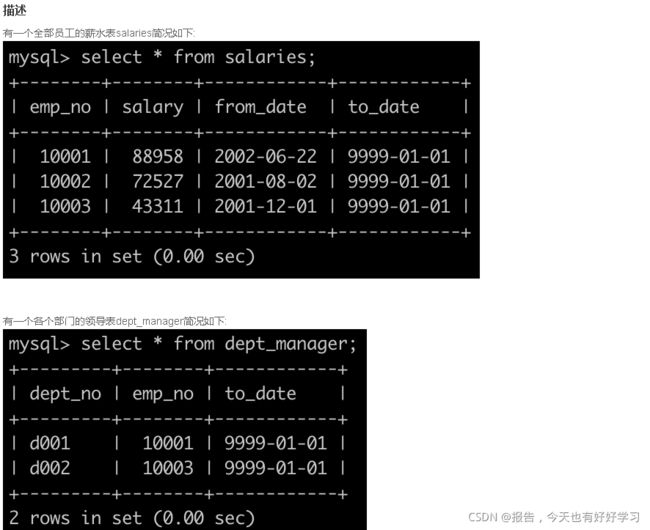

SELECT s.emp_no,s.salary, s.from_date, s.to_date, d.dept_no
FROM dept_manager d
LEFT JOIN salaries s
ON d.emp_no = s.emp_no
ORDER BY s.emp_no
SQL4 简单 查找所有已经分配部门的员工的last_name和first_name以及dept_no
原题链接
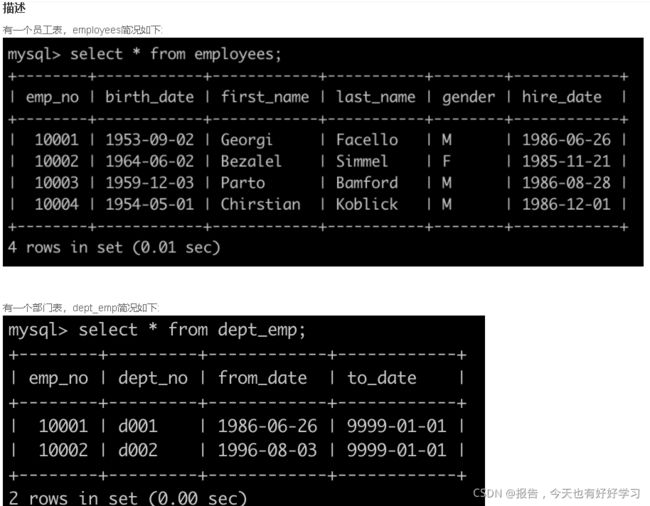

SELECT e.last_name, e.first_name, d.dept_no
FROM dept_emp d
join employees e
on d.emp_no = e.emp_no
SQL5 中等 查找所有员工的last_name和first_name以及对应部门编号dept_no
原题链接
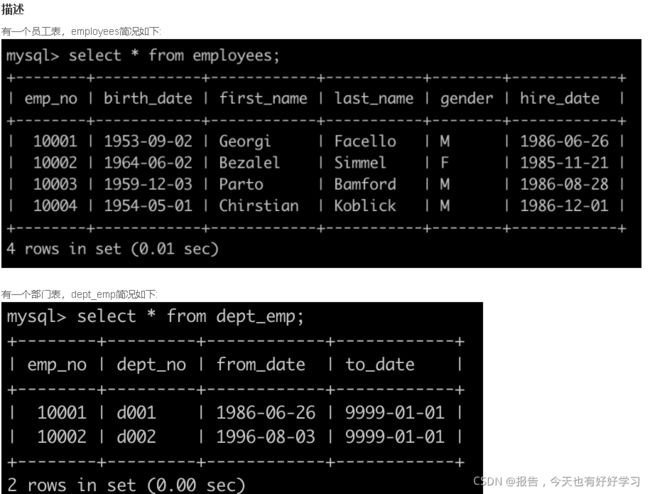
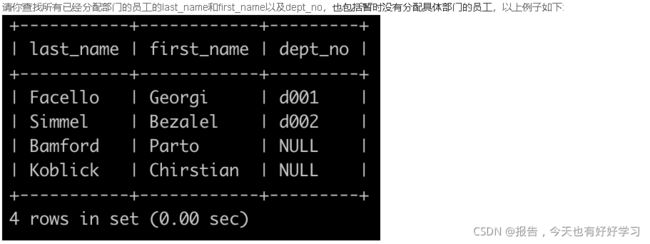
/*较上一题多了两行null,所以要将left join 改成right join*/
SELECT e.last_name, e.first_name, d.dept_no
FROM dept_emp d
RIGHT JOIN employees e
ON d.emp_no = e.emp_no
SQL7 简单 查找薪水记录超过15次的员工号emp_no以及其对应的记录次数t
原题链接
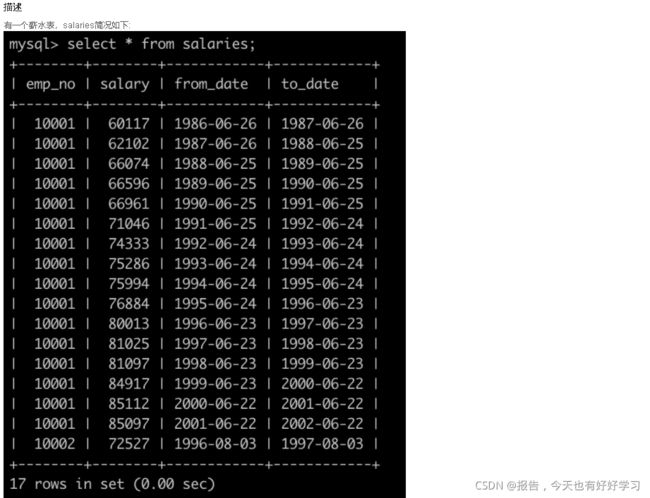

SELECT emp_no, COUNT(emp_no) t
FROM salaries
GROUP BY emp_no
HAVING COUNT(emp_no) > 15
SQL8 简单 找出所有员工当前薪水salary情况
原题链接

SELECT distinct salary
FROM salaries
order by salary DESC
SQL10 简单 获取所有非manager的员工emp_no
原题链接


SELECT emp_no
FROM employees
WHERE emp_no not in (select emp_no from dept_manager)
SQL11 中等 获取所有员工当前的manager
原题链接
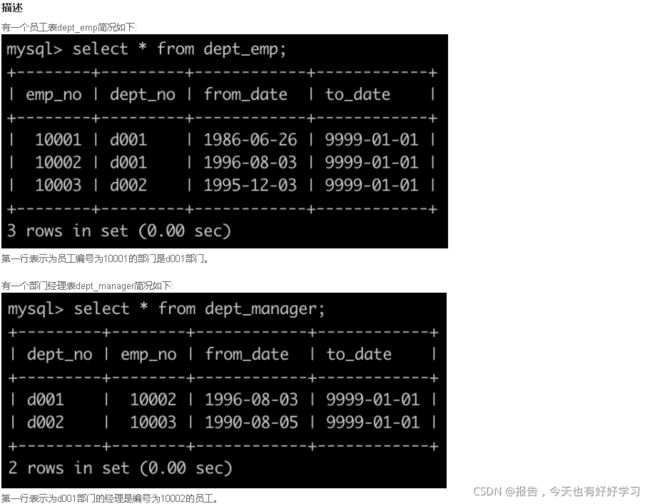

select d1.emp_no, d2.emp_no manager
FROM dept_emp d1
join dept_manager d2
on d1.dept_no=d2.dept_no and d1.emp_no <> d2.emp_no
SQL12 困难 获取每个部门中当前员工薪水最高的相关信息
原题链接

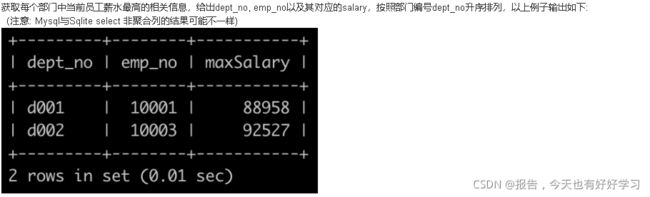
with tmp as (
SELECT d.dept_no, d.emp_no, s.salary
FROM dept_emp d
JOIN salaries s
on d.emp_no = s.emp_no
), tmp2 as (
select *, rank() over(PARTITION by dept_no order by salary desc, emp_no desc) rk
FROM tmp
)
SELECT dept_no, emp_no, salary maxSalary
FROM tmp2
WHERE rk=1
SQL15 简单 查找employees表emp_no与last_name的员工信息
原题链接
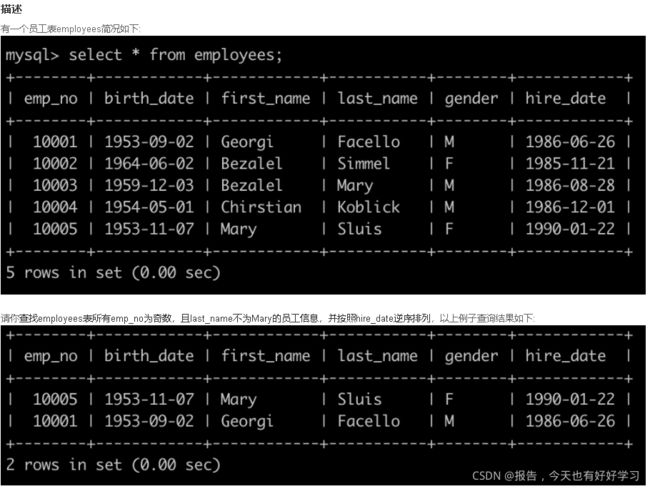
SELECT * FROM employees
where emp_no % 2 = 1 and last_name <> 'Mary'
order by hire_date desc
SQL16 中等 统计出当前各个title类型对应的员工当前薪水对应的平均工资
原题链接
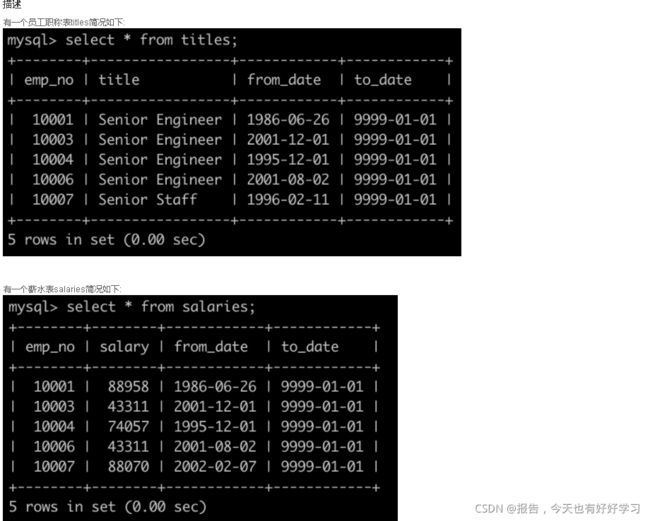

select t.title title, avg(s.salary)
FROM titles t
join salaries s
on t.emp_no = s.emp_no
group by t.title
ORDER by avg(s.salary)
SQL17 简单 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
原题链接
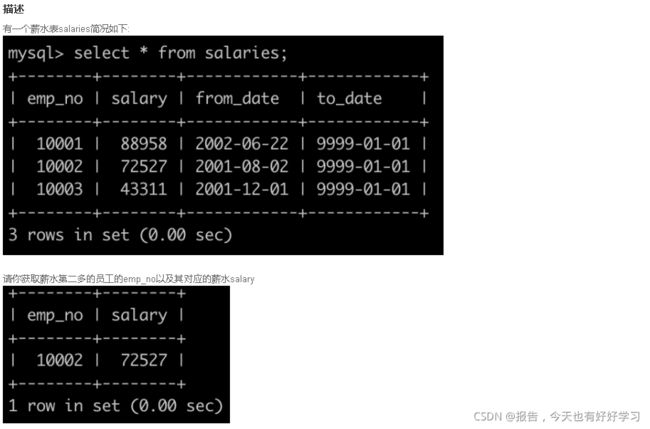
select emp_no, salary
FROM salaries
where salary = (select DISTINCT salary FROM salaries order by salary desc LIMIT 1,1)
/*
with tmp as (
SELECT emp_no, salary, rank() over(order by salary desc, emp_no desc) rk
from salaries
)
select emp_no, salary
from tmp
where rk = 2
*/
SQL18 较难 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
原题链接
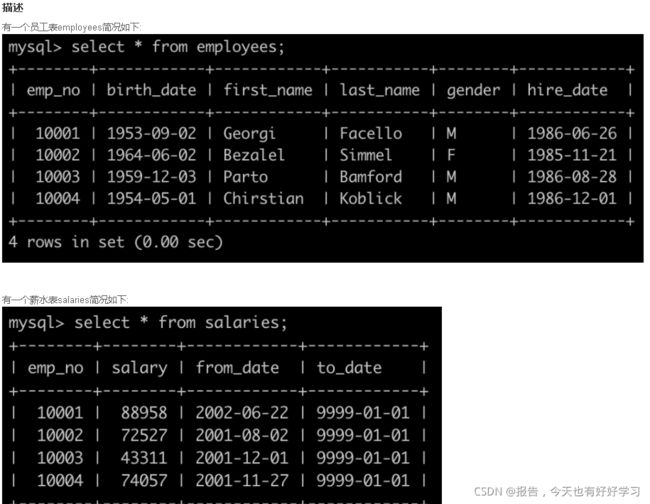
with tmp as (
SELECT s.emp_no, s.salary, e.last_name, e.first_name
FROM employees e
join salaries s
on e.emp_no = s.emp_no
)
select *
from tmp
where salary = (SELECT max(salary) FROM tmp where salary <> (select max(salary) FROM salaries))
SQL19 中等 查找所有员工的last_name和first_name以及对应的dept_name
原题链接
select e.last_name, e.first_name, d.dept_name
from employees e
left join dept_emp on e.emp_no = dept_emp.emp_no
left join departments d on dept_emp.dept_no = d.dept_nojavascript:void(0);
SQL21 困难 查找在职员工自入职以来的薪水涨幅情况
原题链接


with s1 as (
select *
FROM salaries
group by emp_no
having from_date = min(from_date)
),
s2 as (
select *
FROM salaries
where to_date = '9999-01-01'
)
select distinct s1.emp_no, s2.salary - s1.salary growth
FROM s1, s2
where s1.emp_no=s2.emp_no and s2.to_date = '9999-01-01'
order by growth
SQL22 中等 统计各个部门的工资记录数
原题链接

WITH tmp as (
select dept_emp.dept_no, departments.dept_name, salaries.emp_no
from salaries
left join dept_emp
on salaries.emp_no = dept_emp.emp_no
left join departments
on dept_emp.dept_no = departments.dept_no
)
select dept_no, dept_name, count(emp_no) sum
FROM tmp
group by dept_no
order by dept_no
SQL23 较难 对所有员工的薪水按照salary降序进行1-N的排名
原题链接

select emp_no, salary, DENSE_RANK() over(order by salary desc) t_rank
FROM salaries
SQL24 较难 获取所有非manager员工当前的薪水情况
原题链接

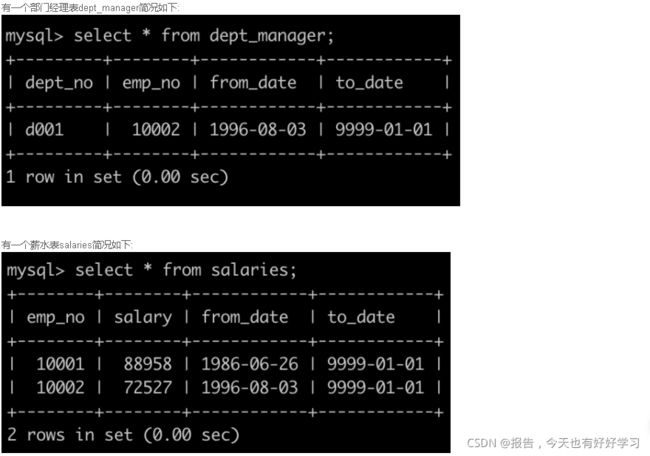

SELECT d1.dept_no, d1.emp_no, s.salary
FROM dept_emp d1
join salaries s
on d1.emp_no = s.emp_no
where d1.emp_no not in (select emp_no from dept_manager)
SQL25 困难 获取员工其当前的薪水比其manager当前薪水还高的相关信息
原题链接

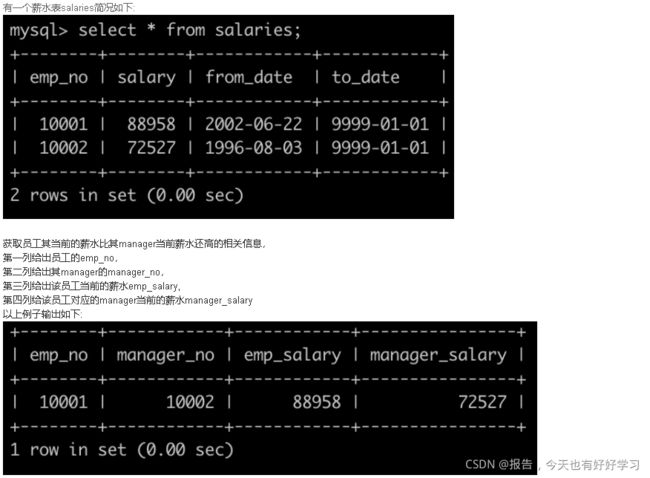
SELECT d1.emp_no, d2.emp_no manager_no, s1.salary emp_salary, s2.salary manager_salary
FROM dept_emp d1
join dept_manager d2
on d1.dept_no = d2.dept_no and d1.emp_no <> d2.emp_no
join salaries s1
on s1.emp_no = d1.emp_no
join salaries s2
on s2.emp_no = d2.emp_no
where s1.salary > s2.salary
SQL26 困难 汇总各个部门当前员工的title类型的分配数目
原题链接

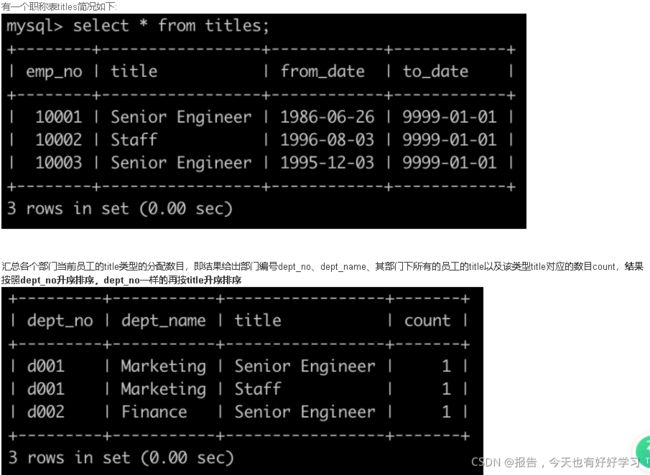
SELECT d1.dept_no, d2.dept_name, t.title, count(t.emp_no) COUNT
from dept_emp d1
join departments d2
on d1.dept_no = d2.dept_no
join titles t
on d1.emp_no = t.emp_no
group by d1.dept_no, t.title
order by dept_no, title
SQL29 中等 使用join查询方式找出没有分类的电影id以及名称
原题链接


with tmp as (
select f.film_id, f.title
from film f
join film_category fc
on f.film_id = fc.film_id
join category c
on fc.category_id = c.category_id
)
select film_id, title
from film
where film_id not in (select film_id from tmp)
SQL30 中等 使用子查询的方式找出属于Action分类的所有电影对应的title,description
原题链接


select f.title, f.description
from film f
join film_category fc
on f.film_id = fc.film_id
join category c
on fc.category_id = c.category_id
where c.name = 'Action'
SQL32 简单 将employees表的所有员工的last_name和first_name拼接起来作为Name
原题链接

/*主要就是考察concat函数 */
select CONCAT(last_name, ' ', first_name) NAME
FROM employees
SQL33 中等 创建一个actor表,包含如下列信息
原题链接
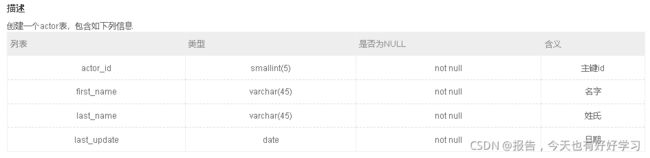
CREATE TABLE actor(
actor_id smallint(5) primary key,
first_name varchar(45) not null,
last_name varchar(45) not null,
last_update date not null);
SQL38 中等 针对actor表创建视图actor_name_view
原题链接

CREATE VIEW actor_name_view AS
SELECT first_name first_name_v ,last_name last_name_v
FROM actor;
SQL50 中等 将employees表中的所有员工的last_name和first_name通过引号连接起来。
原题链接
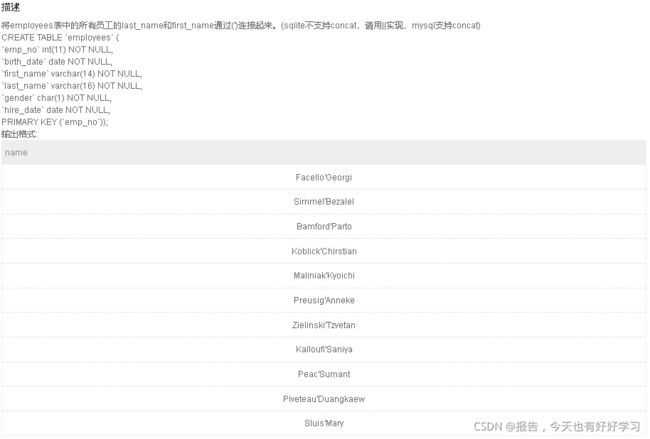
select CONCAT(last_name, '\'', first_name) name
from employees
SQL51 中等 查找字符串 10,A,B 中逗号,出现的次数cnt
原题链接

select 2
/*
select (length('10,A,B') - length(replace('10,A,B',',',''))) AS cnt
*/
SQL52 中等 获取Employees中的first_name
原题链接

select first_name
FROM employees
ORDER BY RIGHT(first_name, 2)
SQL53 中等 按照dept_no进行汇总
原题链接

/*
本次重点是GROUP_CONCAT函数
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
*/
select dept_no, GROUP_CONCAT(emp_no) employees
FROM dept_emp
group by dept_no
SQL54 中等 平均工资
原题链接

select avg(salary) avg_salary
from salaries
where to_date='9999-01-01'
and (to_date, salary) not in (select to_date, max(salary) from salaries where to_date='9999-01-01')
and (to_date, salary) not in (select to_date, min(salary) from salaries where to_date='9999-01-01')
SQL55 中等 分页查询employees表,每5行一页,返回第2页的数据
原题链接

select *
from employees
limit 5,5
SQL57 中等 使用含有关键字exists查找未分配具体部门的员工的所有信息。
原题链接
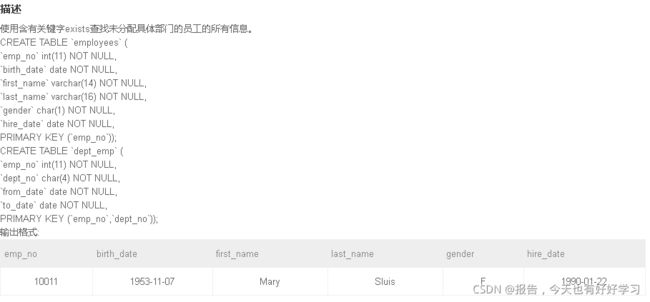
/*
EXISTS语句:执行employees.length次
指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
IN 语句:只执行一次
确定给定的值是否与子查询或列表中的值相匹配。
in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。
所以相对内表比较小的时候,in的速度较快。
*/
select *
from employees
where not EXISTS(
select emp_no
from dept_emp
where dept_emp.emp_no = employees.emp_no
)
SQL59 较难 获取有奖金的员工相关信息。
原题链接
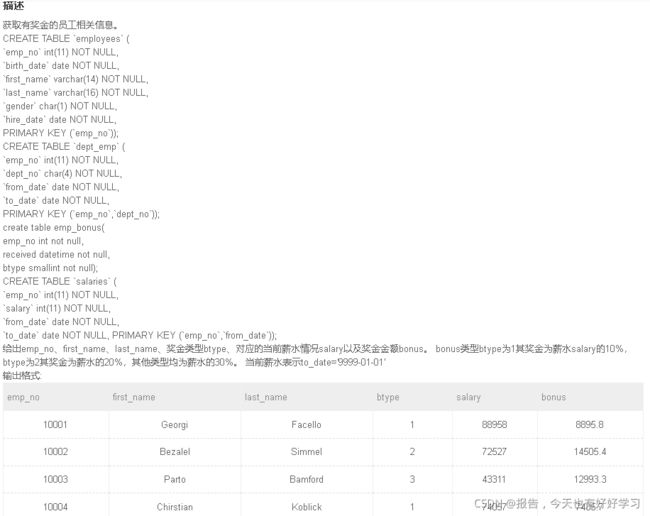
with s as (
select *
FROM salaries
where to_date = '9999-01-01'
)
SELECT e1.emp_no, e2.first_name, e2.last_name, e1.btype, s.salary,
(case
when e1.btype=1 then s.salary * 0.1
when e1.btype=2 then s.salary * 0.2
else s.salary * 0.3
end
) bonus
FROM emp_bonus e1
JOIN employees e2
on e1.emp_no = e2.emp_no
join s
on e1.emp_no = s.emp_no
SQL60 较难 统计salary的累计和running_total
原题链接
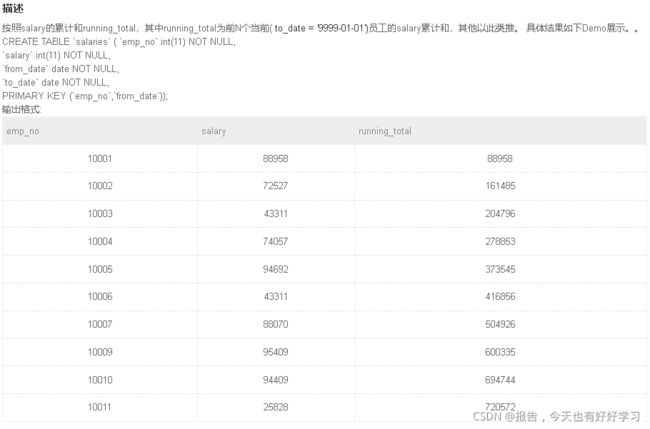
with emp as (
select *
FROM salaries
where to_date = '9999-01-01'
), tmp as (
select e1.emp_no, e1.salary, e2.salary s2
FROM emp e1
join emp e2
on e1.emp_no >= e2.emp_no
)
select emp_no, salary, sum(s2) running_total
from tmp
group by emp_no
SQL61 较难 对于employees表中,给出奇数行的first_name
原题链接
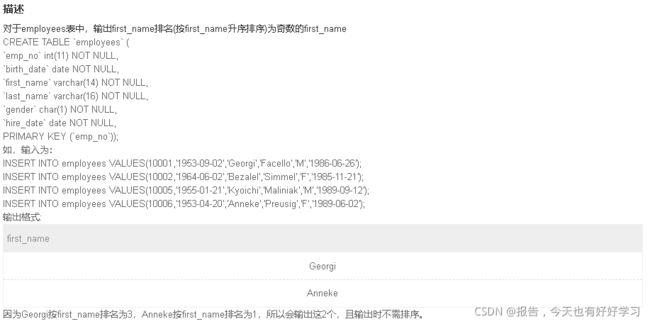
with tmp as (
select first_name, ROW_NUMBER() over(order by first_name) rk
from employees
)
select e.first_name
FROM employees e
join tmp
on e.first_name = tmp.first_name
where rk % 2 = 1
/*
注意题目说“输出的结果不需排序”,但是我们用了ROW_NUMBER(),所以已经排了序,需要重新连接原来的表,保证顺序不变
*/
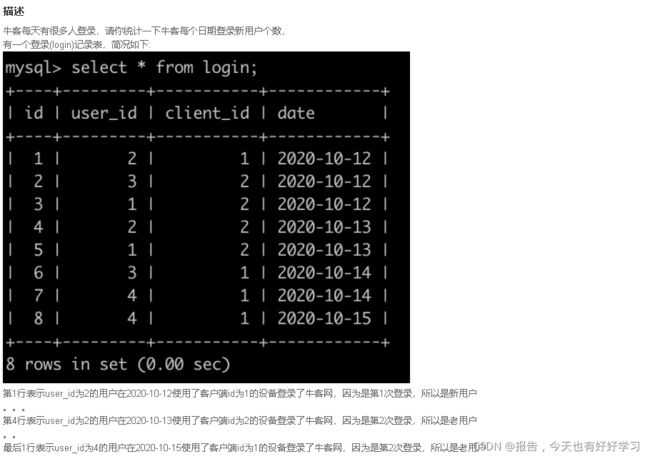
SQL65 较难 异常的邮件概率
原题链接

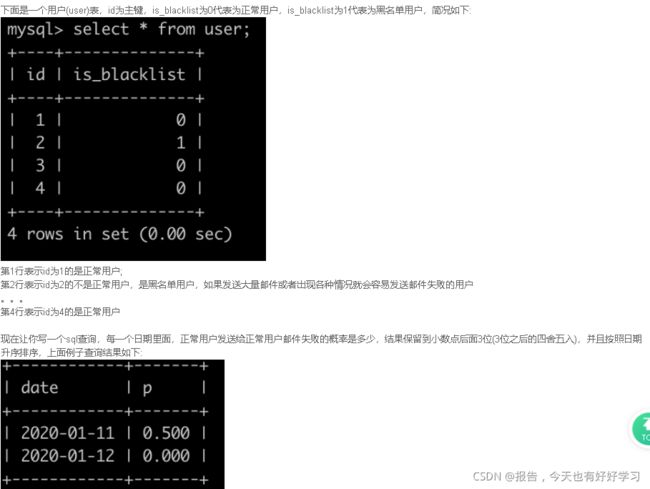

select date, round(sum(if(type='completed', 0, 1)) / count(type), 3) p
from email
where send_id in (select id from user where is_blacklist=0) and receive_id in (select id from user where is_blacklist=0)
group by date
order by date
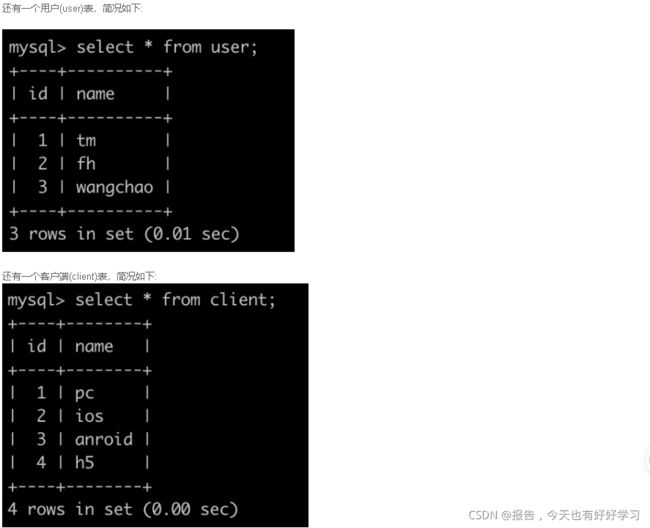
SQL66 简单 牛客每个人最近的登录日期(一)
原题链接
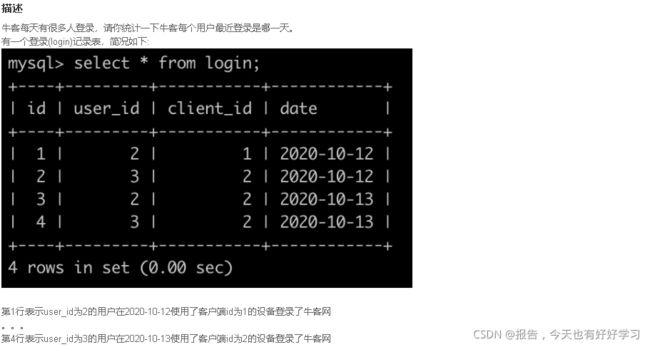

select user_id, max(date) d
from login
group by user_id
order by user_id
SQL67 较难 牛客每个人最近的登录日期(二)
原题链接
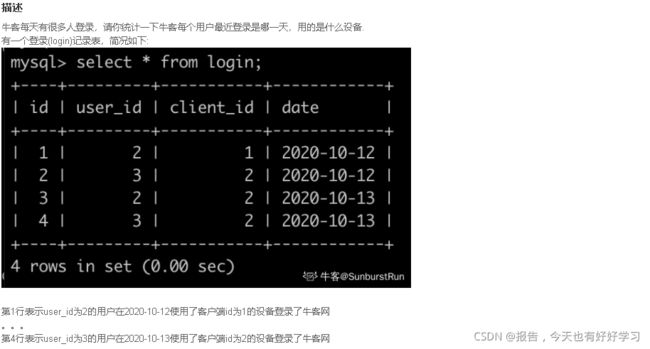

select u.name u_n, c.name c_n, l.date
from login l
join user u
on l.user_id = u.id
join client c
on l.client_id = c.id
where (l.user_id, l.date) in (select user_id, max(date) FROM login group by user_id)
ORDER by u.name
SQL68 较难 牛客每个人最近的登录日期(三)
原题链接


with tmp as (
select user_id, min(date) date
from login
group by user_id
)
select round((select count(user_id) from tmp where (user_id, date+1) in (select user_id, date from login)) / (select count(user_id) from tmp), 3)
SQL69 较难 牛客每个人最近的登录日期(四)
原题链接
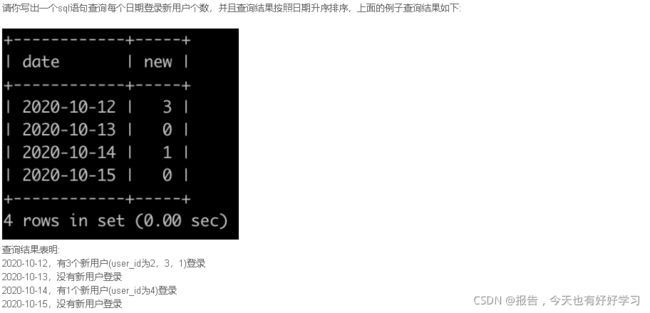
select date, sum(if((user_id, date) in (select user_id, min(date) from login group by user_id), 1, 0)) new
from login
group by date
order by date
SQL70 困难 牛客每个人最近的登录日期(五)
原题链接

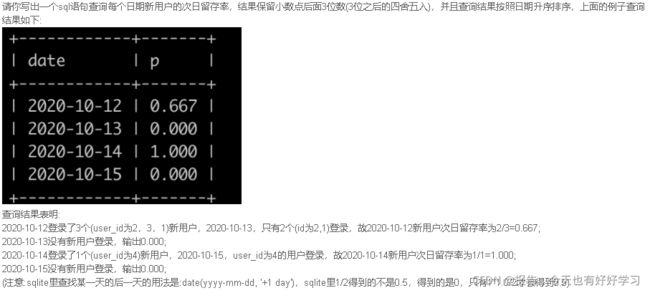
select date, ifnull(round(sum(if((user_id, date+1) in (select user_id, date from login group by user_id), 1, 0)) / sum(if((user_id, date) in (select user_id, min(date) from login group by user_id), 1, 0)), 3), 0) p
from login
group by date
order by date
SQL71 较难 牛客每个人最近的登录日期(六)
原题链接



with tmp as (
select p1.user_id, p1.date, p2.number
from passing_number p1, passing_number p2
where p1.user_id = p2.user_id and p1.date >= p2.date
), tmp2 as (
select user_id, date, sum(number) ps_number
from tmp
group by user_id, date
)
select u.name u_n, date, ps_number
from tmp2 t
join user u
on t.user_id = u.id
order by date, name
SQL87 中等 最差是第几名(一)
原题链接


with tmp as (
select c1.grade, c2.number
from class_grade c1
join class_grade c2
on c1.grade >= c2.grade
)
select grade, sum(number) t_rank
FROM tmp
group by grade
order by grade
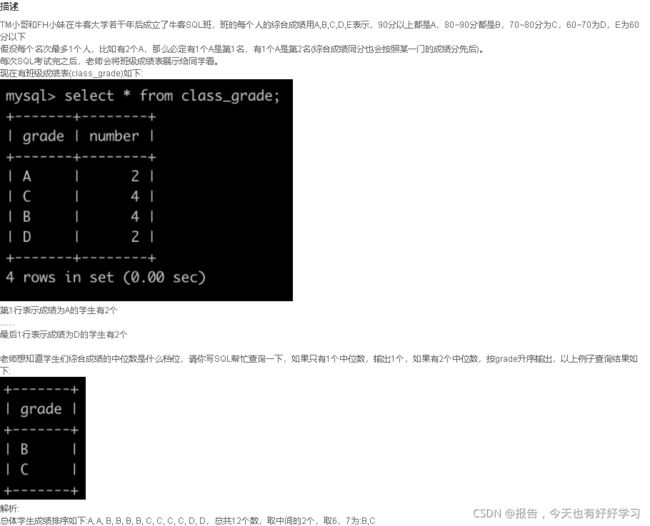
SQL88 较难 最差是第几名(二)
原题链接
select grade
from
(select grade,
(select sum(number) from class_grade) as total,
sum(number)over(order by grade) a, -- 求正序
sum(number)over(order by grade desc) b -- 求逆序
from class_grade
order by grade)t
where a >= total/2 and b >= total/2 -- 正序逆序均大于整个数列数字个数的一半
order by grade;
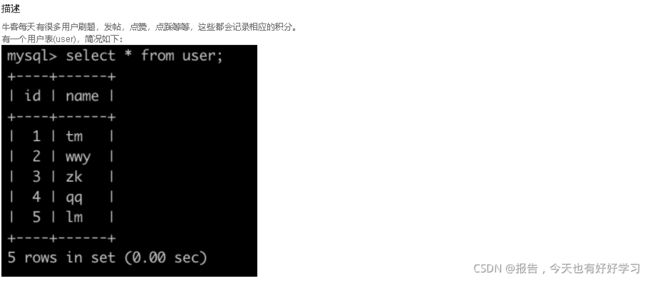
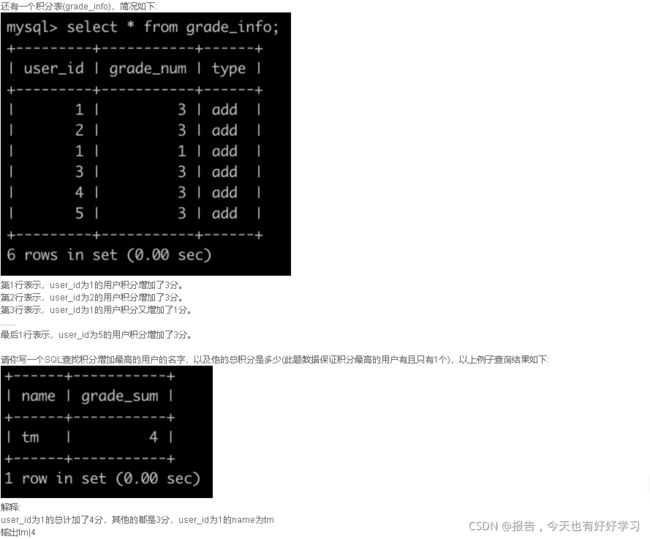
SQL89 中等 获得积分最多的人(一)
原题链接
with tmp as (
select user_id, sum(grade_num) grade_sum
FROM grade_info
group by user_id
)
select u.name, t.grade_sum
from user u
join tmp t
on u.id = t.user_id
order by grade_sum DESC
limit 1
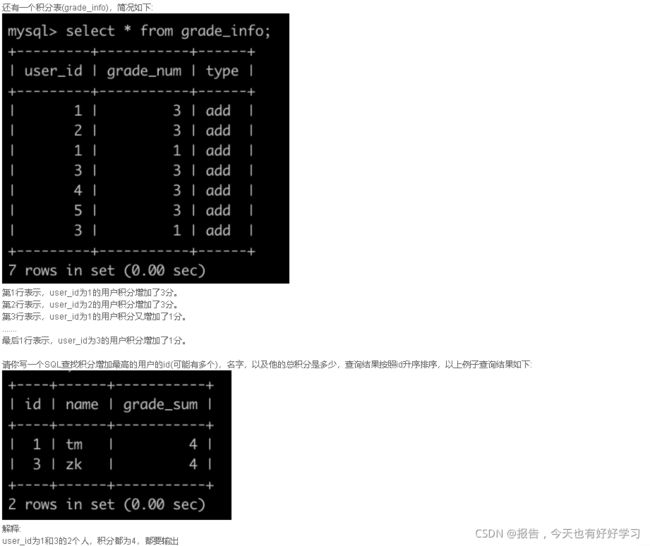
SQL90 较难 获得积分最多的人(二)
原题链接

with tmp as (
select user_id, sum(grade_num) grade_sum
FROM grade_info
group by user_id
)
select id, name, grade_sum
FROM
(
select u.id, u.name, t.grade_sum, rank() over(order by grade_sum desc) rk
from user u
join tmp t
on u.id = t.user_id
) t
where rk = 1
SQL91 困难 获得积分最多的人(三)
原题链接

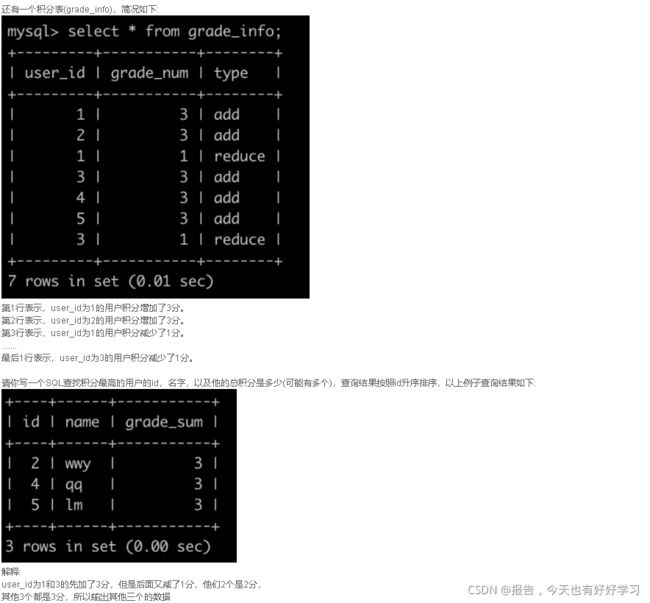
with tmp as (
select user_id, sum(if(type='add', grade_num, 0)) grade_add, sum(if(type='reduce', grade_num, 0)) grade_reduce
FROM grade_info
group by user_id
)
select id, name, grade_sum
FROM
(
select u.id, u.name, (t.grade_add - t.grade_reduce) grade_sum, rank() over(order by (t.grade_add - t.grade_reduce) desc) rk
from user u
join tmp t
on u.id = t.user_id
) t
where rk = 1
SQL92 中等 商品交易(网易校招笔试真题)
原题链接

SELECT g.id, g.name, g.weight, sum(t.count) total
FROM goods g
JOIN trans t
on g.id = t.goods_id
where g.weight < 50
GROUP by t.goods_id
HAVING total > 20
order by g.id
SQL93 较难 网易云音乐推荐(网易校招笔试真题)
原题链接


with tmp as (
select f.user_id, music_name, music_id
from follow f
join music_likes m
on f.follower_id = m.user_id
join music m2
on m2.id = m.music_id
)
select distinct music_name
FROM tmp
where user_id = 1 and music_id not in (select music_id from music_likes where user_id = 1)
order by music_id
结束语
感谢收看,祝学业和工作进步!
推荐关注的专栏
机器学习:分享机器学习实战项目和常用模型讲解
数据分析:分享数据分析实战项目和常用技能整理
CSDN@报告,今天也有好好学习