python实现——文件操作(超详细)
目录
- 基本操作
-
- 文件路径
- 分离路径名和文件名
- 分离文件名和文件后缀
- 当前工作目录(os.getcwd、os.chdir)
- 创建新文件夹(os.makedirs)
- 查看文件夹目录和文件大小(os.path.getsize、os.listdir)
- 路径有效性
- 获取桌面路径
- 文件读写
-
- 读取文件
-
- 使用read(),返回所有文本内容
- 使用readline(),按行读取
- 使用readlines(),把每行的内容添加到列表中
- 使用readlines()读取文本文件
- 写入文件
-
- 使用write直接写
- 使用writelines,以列表的方式写
- 其他
- open() 方法
-
- mode参数
- 组织文件
-
- 复制文件和文件夹
- 移动文件和文件夹
- 删除文件和文件夹
- 遍历目录树
- 重命名文件夹、文件
- 压缩文件
-
- 读取ZIP文件
- 解压缩文件
- 创建zip文件
-
- 写模式
-
- 压缩单个文件
- 压缩文件夹中第一层的所有文件
- 添加模式
-
- 压缩文件夹中的所有文件【一个压缩软件诞生了】
- 破解压缩包
基本操作
文件路径
1:拼接路径
在windows和非windows的系统中,关于路径使用的斜杠不同,使用os.path.join()它能给出正确的答案
import os
print(os.path.join('C', 'Program Files', 'Common Files'))
结果:
C\Program Files\Common Files
路径的三种方式:
(1):使用左斜线【推荐,全平台通用】
file = open(‘C:/Users/asuka/Desktop/新建文本文档.txt’, encoding=‘utf-8’)
(2):使用转义符
file = open(‘C:\Users\asuka\Desktop\新建文本文档.txt’, encoding=‘utf-8’)
(3):使用 r 格式化字符
file = open(r’C:\Users\asuka\Desktop\新建文本文档.txt’, encoding=‘utf-8’)
2:处理绝对路径和相对路径
os.path.abspath()返回参数的绝对路径,可用于把相对路径转换为绝对路径os.path.isabs(),路径是绝对路径的话,就返回Trueos.path.relpath(path,start),返回从 start 到 path 的相对路径,如果不写 start ,就默认返回从当前路径到 path 的相对路径
import os
print(os.getcwd()) #查看当前工作目录
print(os.path.abspath('.')) #把相对路径转换为绝对路径
print(os.path.isabs('.')) #是绝对路径就返回True
print(os.path.relpath('D:\\','D:\\pycharm\\02'))
结果:
D:\pycharm\02
D:\pycharm\02
False
..\..
分离路径名和文件名
os.path.dirname(path)将返回path参数中最后一个斜杠之前的内容,即:返回目录名称
os.path.basename(path)将返回path参数中最后一个斜杠之后的内容,即:返回基本名称

import os
path = r'C:\Windows\System32\calc.exe'
print(os.path.dirname(path)) #获取目录名称
print(os.path.basename(path)) #获取基本名称
结果:
C:\Windows\System32
calc.exe
os.path.split()同时获得路径的目录名称和基本名称,得到的是两个字符串组成的元组
import os
path = r'C:\Windows\System32\calc.exe'
print(os.path.split(path))
结果:
('C:\\Windows\\System32', 'calc.exe')
分离文件名和文件后缀
os.path.splitext()将文件名和扩展名分开os.path.split()返回文件的路径和文件名
import os
path = r'C:\Users\asuka\Desktop\1.txt'
a = os.path.split(path) # 分离路径和文件
print(a)
print(os.path.splitext(a[-1])) # 分离文件名和后缀
# 结果:
# ('C:\\Users\\asuka\\Desktop', '1.txt')
# ('1', '.txt')
一个小例子,把某文件夹下所有png后缀的文件改成jpg后缀
import os
path = r"C:\Users\asuka\Desktop\123"
os.chdir(path) # 修改工作路径
files = os.listdir(path)
print('原始文件名:'+str(files)) # 打印看一下上面目录中有哪些文件
# 使用os.path.splitext分离文件名和后缀
for filename in files:
fa = os.path.splitext(filename)
if fa[1] == ".png":
newname = fa[0] + ".jpg"
os.rename(filename, newname)
files = os.listdir(path)
print('现在文件名:'+str(files)) # 打印看一下上面目录中有哪些文件
当前工作目录(os.getcwd、os.chdir)
如果要更改的工作目录不存在,python会报错。
- print(os.getcwd()) #查看当前工作目录
- print(os.path.abspath(’.’)) #查看当前工作目录
细节:当前工作目录是标准术语,没有当前工作文件夹这种说法
import os
print(os.getcwd()) #获取当前的工作路径
os.chdir('C:\\Program Files\\Common Files') #更换工作目录
print(os.getcwd()) #获取当前的工作路径
结果:
D:\pycharm\02
C:\Program Files\Common Files
创建新文件夹(os.makedirs)
使用os.makedirs创建文件夹,并且会创建出中间所有必要的中间文件夹,来确保完整路径名存在。
import os
print(os.path.exists(r'D:\Program Files\666')) #证明不存在此路径
os.makedirs(r'D:\Program Files\666\777\888')
print(os.path.exists(r'D:\Program Files\666')) #证明不存在此路径
结果:
False
True
查看文件夹目录和文件大小(os.path.getsize、os.listdir)
os.path.getsize(path)返回path参数中,文件的字节数。os.listdir(path)返回path参数中的文件夹内容
查看文件大小
import os
path = r'C:\Windows\System32\calc.exe'
print(os.path.getsize(path)) #27648
查看文件夹的大小
import os
totalSize = 0
for filename in os.listdir(r'D:\我的文档'):
totalSize+=os.path.getsize(os.path.join(r'D:\我的文档',filename))
print(totalSize) #144597950
查看文件夹的内容
import os
path = r'D:\iso'
print(os.listdir(path))
结果
['Cent7', 'kali-linux-2020.3-vmware-amd64', 'kali-linux-2020.3-vmware-amd64.zip', 'Metasploitable2-Linux', 'NGTOS-VM.7z', 'NG升级', 'ovf', 'vmware', 'win2008', 'win7', 'win7.zip', 'xp_sp3', '历史']
路径有效性
os.path.exists:如果路径存在(可以是文件、文件夹),就返回Trueos.path.isfile:如果路径存在,并且是个文件,就返回Trueos.path.isdir:如果路径存在,并且是个文件夹,就返回True
import os
print(os.path.exists(r'C:\Windows')) #检查路径是否存在
print(os.path.isfile(r'C:\Windows\System32\calc.exe')) #检查文件是否存在
print(os.path.isdir(r'C:\Windows')) #检查文件夹是否存在
结果:
True
True
True
获取桌面路径
import os
desktop_path = os.path.join(os.path.expanduser("~"), 'Desktop')
print(desktop_path)
当然把上面的代码包装成一个函数 GetDesktopPath() 需要时调用它会更加方便
import os
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
文件读写
纯文本文件:只包含基本文本字符,不包含字体、大小、颜色信息
二进制文件:非纯文本文件,诸如PDF、图像、电子表格、可执行程序等
在python中,读写文件的三个步骤:
- 调用
open()函数,返回一个File对象(File对象代表计算机中的一个文件,它是python中另一种类型的值) - 调用File对象中的
read()或write()方法 - 调用File对象的
close()方法,关闭该文件
读取文件
python打开文件时,默认是读模式,下面两个代码是等价的,只不过后者指明了用读模式
open(r'C:\Users\asuka\Desktop\hello.txt')和open(r'C:\Users\asuka\Desktop\hello.txt','r')
报错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x8c in position 14: incomplete multibyte sequence
我们使用的大多数软件,一般写入文件的时候使用的是 utf8 编码格式,读取文件也ok,但是windows系统默认使用gbk编码格式读写文件,所以使用winodws系统打开文件的时候会出现编码问题。
【如果提示编码有问题,指定编码即可,把第一行修改为
a =open(r'C:\Users\asuka\Desktop\hello.txt',encoding='utf-8')】
使用read(),返回所有文本内容
a = open(r'C:\Users\asuka\Desktop\hello.txt')
print(a.read())
a.close()
结果:
68218 Oracle Data Integrator拒绝服务攻击变种2
68219 Windows URI处理命名注入攻击变种2
68223 TCPDump print-bgp.c文件远程整数下溢漏洞攻击
68224 Microsoft Windows IP Options Off-By-One
63528 Symantec Client Firewall SACK Attack
68223 Tcpdump BGP Dissector Integer Overflow
可以给read设置读取的长度
file = open('C:/Users/asuka/Desktop/新建文本文档.txt', encoding='utf-8')
print(file.read()) #你喜欢我吗
file.close()
file = open('C:/Users/asuka/Desktop/新建文本文档.txt', encoding='utf-8')
print(file.read(4)) #你喜欢我
file.close()
使用readline(),按行读取
import os
a = open(r'C:\Users\asuka\Desktop\hello.txt',encoding='utf-8')
print(a.readline())
结果:
68218 Oracle Data Integrator拒绝服务攻击变种2
使用readlines(),把每行的内容添加到列表中
import os
a = open(r'C:\Users\asuka\Desktop\hello.txt',encoding='utf-8')
print(a.readlines())
# 结果;
# ['68218 Oracle Data Integrator拒绝服务攻击变种2\n', '68219 Windows URI处理命名注入攻击变种2\n', '68223 TCPDump print-bgp.c文件远程整数下溢漏洞攻击\n', '68224 Microsoft Windows IP Options Off-By-One\n', '63528 Symantec Client Firewall SACK Attack\n', '68223 Tcpdump BGP Dissector Integer Overflow']
使用readlines()读取文本文件
with open(r'C:\Users\asuka\Desktop\1.txt', 'r', encoding='utf8') as file:
f = file.readlines()
for i in f:
i = i.replace('\n', '')
print(i)
结果:
123
hello
核力量
我
写入文件
写入文件分为“写模式”和“添加模式”
- “写模式”:覆写原有的内容(把原来的内容清空,写入新的内容)
- “添加模式”:在原有的内容后面添加新的内容
如果传递给open()的文件名不存在,两种模式都会创建一个新的空文件,在读写结束后,调用close()方法,然后才能再次打开该文件。
写文件时,只能写入字符串或者二进制。字典、数字、列表等都不能直接写到文件里,需要转换为字符串或者二进制数据。
- 转换为字符串:repr/str,使用json模块
- 转换为二进制:使用pickle模块
如下:这样写入列表是会报错的
a = ['alice', 'bob', 'sinba']
file = open(r'C:\Users\asuka\Desktop\2.txt', 'w', encoding='utf8')
file.write(a)
file.close()
使用write直接写
“写模式”:首先覆写内容,关闭文件。再读取内容,关闭文件。
a = open(r'C:\Users\asuka\Desktop\hello.txt', 'w')
a.write('adale hello \n')
a.close()
b = open(r'C:\Users\asuka\Desktop\hello.txt')
print(b.read())
b.close()
结果:
adale hello
“添加模式”:首先追加内容,关闭文件。再读取内容,关闭文件。
a = open(r'C:\Users\asuka\Desktop\hello.txt', 'a')
a.write('adale someone like you')
a.close()
b = open(r'C:\Users\asuka\Desktop\hello.txt')
print(b.read())
b.close()
结果:
adale hello
adale someone like you
使用writelines,以列表的方式写
a = open(r'C:\Users\asuka\Desktop\hello.txt', 'w', encoding='utf-8')
a.writelines(['123', 'abc', '***'])
a.close()
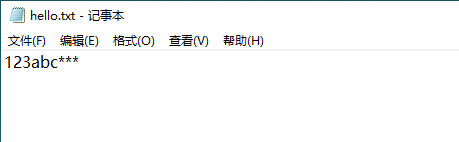
使用writelines,读取一个文本文件
import os
os.chdir(r'C:\Users\asuka\Desktop')
print(os.path.exists('noalert.txt'))
with open('noalert.txt', 'r', encoding='utf8') as f:
contents = f.readlines()
for i in contents:
i = i.replace('\n', '')
print(i)
其他
# 下面的代码用来把终端中的内容输出到一个文本中
a = open(path_result, 'w', encoding='utf8')
for r in result:
a.write(r)
a.write('\n')
a.close()
或者
with open("data.txt",'a',newline='\n') as f:
f.write("Python is awsome")
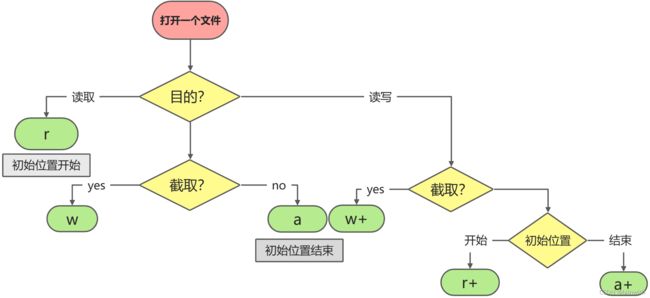
open() 方法
open()方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
**注意:**使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开的模式,默认是r,只读模式
- buffering: 设置缓冲
- encoding: 设置文件打开时使用的编码方式,一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode参数
常用参数【r,w,a即可,其他的操作不慎会出现指针问题】
- r: 只读,文件指针将会放在文件的开头
- w:只写,如果文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除;如果该文件不存在,创建新文件
- a: 打开一个文件用于追加,如果该文件已存在,文件指针将会放在文件的结尾;如果该文件不存在,创建新文件进行写入
- rb: 只读二进制文件,一般用于非文本文件如图片等
- wb: 只写二进制文件,一般用于非文本文件如图片等
- ab: 以二进制格式打开一个文件用于追加
- w+: 打开一个文件用于读写
- r+:可读写(需要文件存在)
- w+:可读写(文件可以不存在)
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
组织文件
用到shutil模块
复制文件和文件夹
1:复制文件shutil.copy
默认使用源文件的文件名,也可以指定文件名,甚至后缀
>>> os.chdir('D:\\')
>>> shutil.copy(r'D:\picture\时间.png',r'D:\iso') #接复制到某目录下(默认保留源文件名)
'D:\\iso\\时间.png'
>>> shutil.copy(r'D:\picture\时间.png',r'D:\iso\time.png') #复制到某目录下,修改新文件的文件名
'D:\\iso\\time.png'
>>> shutil.copy(r'D:\picture\时间.png',r'D:\iso\test.jpg') #复制到某目录下,修改新文件的文件名,甚至后缀
'D:\\iso\\test.jpg'
2:复制文件夹shutil.copytree
把picture文件夹全部复制走,并且把picture改名为picture_bak
>>> import shutil,os
>>> os.chdir('D:\\')
>>> shutil.copytree(r'D:\picture',r'D:\iso\picture_bak')
'D:\\iso\\picture_bak'
>>>
移动文件和文件夹
shutil.move(source,destination)将路径 source 处的文件、文件夹全部移动到 destination,并返回新位置的绝对路径的字符串
1:把文件移动到目标文件夹
import shutil
import os
os.chdir(r'C:\Users\asuka\Desktop')
shutil.copy(r'1\test.txt', r'2')

2:把文件移动到目标位置,并重命名。
import shutil
import os
os.chdir(r'C:\Users\asuka\Desktop')
shutil.copy(r'1\test.txt', r'2\666.txt')
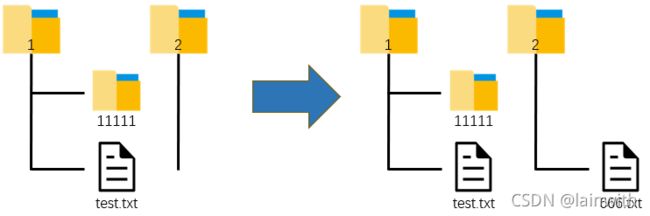
移动文件夹,子文件及子文件夹的所有内容都会被移动
import shutil
import os
os.chdir(r'C:\Users\asuka\Desktop')
shutil.copytree('1', '2\\666')

假如目标路径中,存在同名文件、文件夹,就需要在移动的收修改一下名字,如下,把 D:\film中的 1.txt 移动到D:\demo 中,并更名为 2.txt。否则会报错!
注意:在有的python版本中,如果重名的话,在移动的时候好像会出现覆写,所以需要谨慎使用move方法
删除文件和文件夹
os 模块可以删除一个文件或文件夹,但 shutil 可以删除一个文件夹及其所有的内容
删除是跳过回收站从电脑上移除了
- os.unlink(path):将删除path处的文件
- os.rmdir(path): 删除path处的文件夹。文件夹必须是空的
- shutil.rmtree(path):强制删除path处的文件夹,及其附属内容
1:借助for循环,删除一个文件下某类型的文件
(这里endswith(’.txt’)建议保留那个.,防止碰到无后缀名的文件误删)
import os
os.chdir('D:\\film\\')
for filename in os.listdir('D:\\film\\'):
if filename.endswith('.txt'):
os.unlink(filename)
2:shutil.rmtree(path) 是将文件夹连根删除
import shutil
shutil.rmtree('D:\\demo')
安全的删除文件(send2trash)
该工具是第三方模块,需要手动下载pip install send2trash。
使用send2trash(),它删除文件的时候会把文件丢到垃圾桶中
import send2trash,os
send2trash.send2trash(r'D:\photo')
遍历目录树
os.walk()参数传入一个文件夹的路径,通过在for循环使用os.walk()来遍历目录树,这里的遍历指的是遍历全部,而非遍历最外层,如下:
拆分一下:
- 只保留第二个for循环,打印当前目录下所有的文件夹
- 只保留第三个for循环,打印当前目录下所有的文件
import os
for current_folder, list_folders, files in os.walk(r'D:\iso\NG升级'):
print('当前工作在文件夹:' + current_folder)
for lf in list_folders:
print('子文件夹:'+current_folder+':'+lf)
for f in files:
print('文件:'+current_folder+':'+f)
结果:
当前工作在文件夹:D:\iso\NG升级
子文件夹:D:\iso\NG升级:历史
文件:D:\iso\NG升级:FeiQ.exe
文件:D:\iso\NG升级:V3.2294.2027.1_ips_upt
当前工作在文件夹:D:\iso\NG升级\历史
文件:D:\iso\NG升级\历史:V3.2294.2025.1_ips_B_upt
文件:D:\iso\NG升级\历史:V3.2294.2025.1_ips_upt
重命名文件夹、文件
os.rename(“文件/文件夹”,“新文件名/新文件夹名”)
import os
# 将test1.xlsx重命名为“my.xlsx”
os.rename("test1.xlsx","my.xlsx")
# 将“123”文件夹重命名为“abc”文件夹
os.rename("123","456")
压缩文件
使用如下的文件目录

读取ZIP文件
读取zip文件的步骤:
-
调用zipfile.ZipFile()函数,创建一个ZipFile对象【zipfile是python模块的名称,ZipFile是函数的名称】
-
使用
namelist方法查看zip文件中所有的文件和文件夹 -
上一步得到的字符信息,可以传递给getinfo()方法,返回一个关于特定文件的ZipInfo对象。
这个对象有自己的属性,如
file_size(表示原来文件的大小)、compress_size(表示文件压缩后的大小)
ZipFile对象表示整个文档,ZipInfo对象保存该文档文件中每个文件的有用信息 -
还可以计算文件的压缩率
import zipfile, os
os.chdir('D:\\') # 移动到目标所在文件夹
testZip = zipfile.ZipFile('test.zip') # 调用zipfile.ZipFile()函数,创建一个ZipFile对象
print(testZip.namelist()) # 查看zip文件中所有的文件和文件夹
info = testZip.getinfo('test/1.txt') #获取关于此对象的一些信息
# 获取文件被压缩前的大小
print(info.file_size)
# 获取文件被压缩后的大小
print(info.compress_size)
# 获取文件的压缩率
print('文件的压缩率是:{:.2f}%'.format((1 - (info.compress_size / info.file_size))*100))
# 结果
# ['test/', 'test/1.txt', 'test/2.jpg', 'test/pcap/', 'test/pcap/1.pcap', 'test/pcap/2.pcap', 'test/pcap/3.pcap']
# 26326980
# 169977
# 文件的压缩率是:99.35%
解压缩文件
使用extractall()方法从ZIP文件中解压缩里面的所有文件,放到当前目录中
- 如下代码,会把test.zip解压到当前目录下,名为test的文件夹
- 如果当前目录下存在名为test的文件夹,python会把解压出来的内容与test里的内容合并在一个文件夹
- 如果当前目录下不存在名为test的文件夹,python就直接解压
- 只能解压一层,不能解压压缩包里面的压缩包
可以把第6行代码换为testZip.extractall('123'),即:重命名解压处来的文件夹,避免文件夹重名问题。
import zipfile, os
os.chdir('D:\\') # 移动到目标所在文件夹
testZip = zipfile.ZipFile('test.zip') # 调用zipfile.ZipFile()函数,创建一个ZipFile对象
testZip.extractall()
testZip.close()
你还可以使用extract()提取单个文件
创建zip文件
创建处的文件位于:D:\test\test.zip
【前面读取、解压缩的时候,test.zip是我手工压缩的,位于D:\test.zip。不用在意这种细枝末节,理解操作即可】
像写入文件一样,写模式会擦除ZIP文件中原有的内容,如果像把新文件添加到原有的ZIP文件中,需要以添加模式打开ZIP文件,传入’a’参数
写模式
- 创建zip文件,需要以写模式打开ZipFile对象,传入’w’参数
write()方法的第一个参数:要压缩的对象;第二个参数:压缩的算法
压缩单个文件
import zipfile, os
os.chdir('D:\\test') # 移动到目标所在文件夹
test = zipfile.ZipFile('test.zip','w') #以写模式打开ZipFile对象
test.write('1.txt',compress_type=zipfile.ZIP_DEFLATED)
test.close()
画图理解:
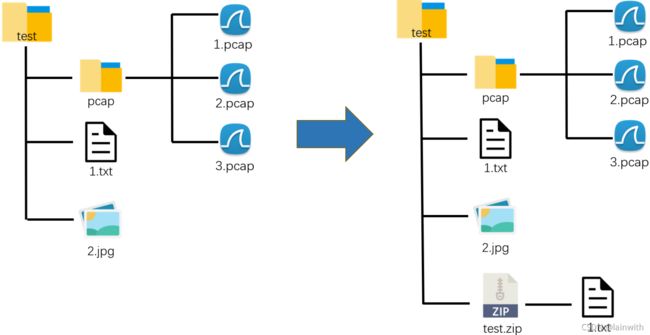
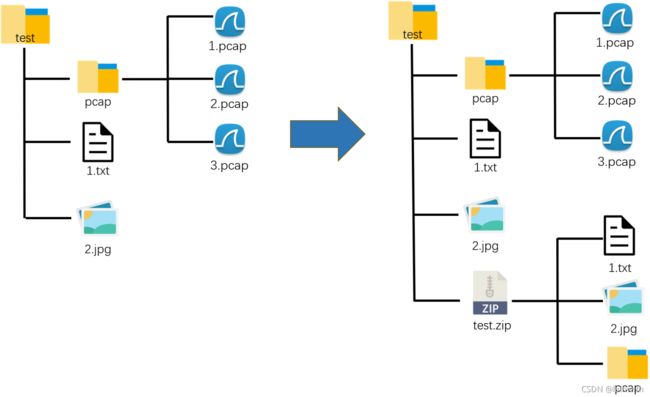
压缩文件夹中第一层的所有文件
【只压缩文件,文件夹不会被压缩】
如果想要压缩test文件夹里的所有内容,需要使用for循环,如下。
出现在test.zip中的pcap文件夹是空文件夹!!!
import zipfile, os
os.chdir('D:\\test') # 移动到目标所在文件夹
current_folder = os.listdir() #得知当前文件夹中最外层的所有文件和文件
test = zipfile.ZipFile('test.zip','w') #以写模式打开ZipFile对象
for cf in current_folder:
test.write(cf,compress_type=zipfile.ZIP_DEFLATED)
test.close()
画图理解:
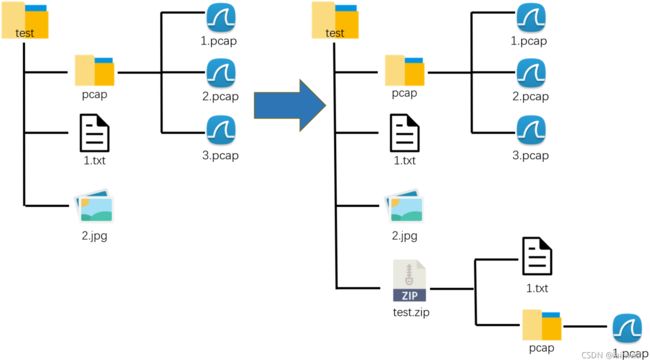
添加模式
添加模式,就是在创造了test.zip中只有1.txt后,再把2.jpg添加进去
import zipfile, os
os.chdir('D:\\test') # 移动到目标所在文件夹
test = zipfile.ZipFile('test.zip','w') #以写模式打开ZipFile对象
test.write('1.txt',compress_type=zipfile.ZIP_DEFLATED)
test.close()
os.chdir('D:\\test') # 移动到目标所在文件夹
test = zipfile.ZipFile('test.zip','a') #以添加模式打开ZipFile对象
test.write('2.jpg',compress_type=zipfile.ZIP_DEFLATED)
test.close()
图示理解:

如果添加的是文件夹中的文件呢?python会创建中间的文件夹
import zipfile, os
os.chdir('D:\\test') # 移动到目标所在文件夹
test = zipfile.ZipFile('test.zip','w') #以写模式打开ZipFile对象
test.write('1.txt',compress_type=zipfile.ZIP_DEFLATED)
test.close()
os.chdir('D:\\test') # 移动到目标所在文件夹
test = zipfile.ZipFile('test.zip','a') #以添加模式打开ZipFile对象
test.write('pcap\\1.pcap',compress_type=zipfile.ZIP_DEFLATED)
test.close()
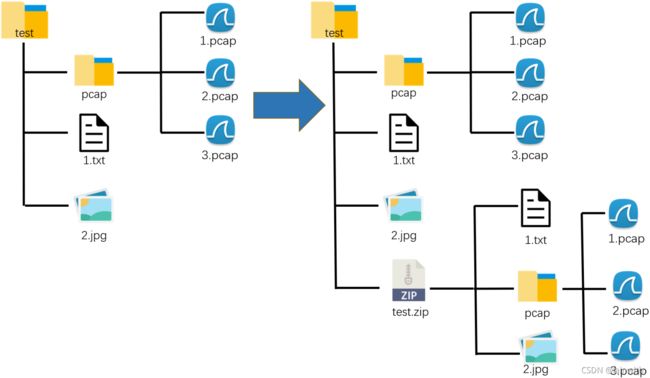
压缩文件夹中的所有文件【一个压缩软件诞生了】
其实用写模式也可以,但还是觉得添加模式更保险
import zipfile, os
path = input(r'请输入压缩的文件路径:') #指明要操作的文件夹路径
os.chdir(path) #进入相关路径
for current_folder, list_folders, files in os.walk(path):
for f in files:
a = current_folder + '\\' + f
test = zipfile.ZipFile('test.zip', 'a') # 以添加模式打开ZipFile对象
test.write(a, compress_type=zipfile.ZIP_DEFLATED)
test.close()
print('压缩完毕')
破解压缩包
参见我之前的文章:python爆破ZIP文件(支持纯数字,数字+字母,密码本)