Pytorch数据加载——Dataset和DataLoader详解
一、可迭代对象与迭代器简介

- 可迭代对象(iterable):实现了 __iter__ 方法,该方法返回一个迭代器对象;
- 迭代器(iterator):迭代器含有 __iter__ 和 next 方法,当调用 __iter__ 返回迭代器自身,当调用 next() 方法返回容器下一个值;
- 二者关系:使用 iter(可迭代对象) 转换为 (迭代器).
二、pytorch输入数据pipline“三步走”策略
一般pytorch的数据加载到模型的操作顺序如下:
1、创建一个 Dataset 对象,必须实现 __len__() ,__getitem__() 两个方法,会用到 transform 对数据进行扩充;
2、创建一个 DataLoader 对象,对 Dataset 对象进行迭代的,一般不需要事先实现里面其他方法了;
3、循环遍历DataLoader对象,将img,label 加载到模型中训练。
注:采样器Sampler、Dataset、DataLoader 这三个类均在 torch.utils.data 中定义,简介代码如下:
from torch.utils.data.sampler import Sampler
from torch.utils.data.dataset import Dataset
from torch.utils.data.dataloader import DataLoader
dataset = MyDataset() # 第一步:构建 Dataset 对象
dataloader = DataLoader(dataset) # 第二步:通过Dataloader来构建迭代对象
num_epoches = 100
for epoch in range(num_epoches):
for i, data in enumerate(dataloader):
# 训练代码数据集遍历一般化流程:
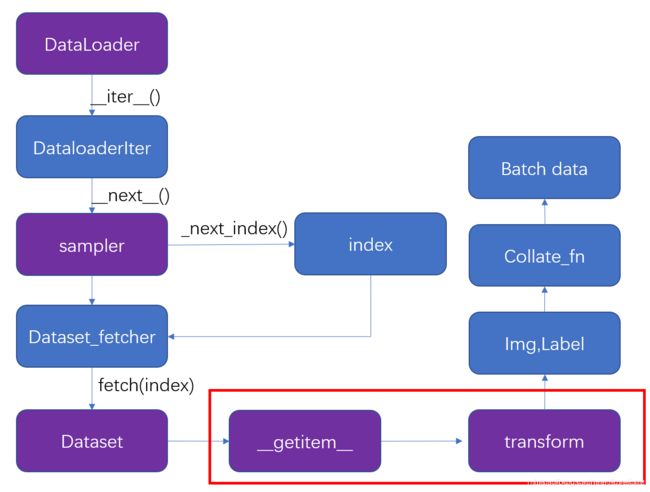
for i, data in enumerate(dataloader): 会调用dataloader 的 __iter__() 方法,产生了一个DataLoaderIter(迭代器),这里判断使用单线程还是多线程,调用 DataLoaderIter 的 __next__() 方法来得到 batch data 。在__next__() 方法中使用 __next_index()方法调用sampler(采样器)获得index索引,接着通过 Dataset_fetcher 的 fetch() 方法根据index(索引)调用dataset的 __getitem__() 方法,然后用 collate_fn 把它们打包成batch。当数据读完后, __next__() 抛出一个 StopIteration 异常,for循环结束,dataloader 失效。
三、Dataset类详解
torch.utils.data.Dataset 是代表这一数据的抽象类(基类),即:Dataset 类是 pytorch 中图像数据中最为重要的一个类,也是 pytorch中所有数据集加载类中应该继承的父类。其中,Dataset类中两个私有成员函数必须被重载,否则将触发错误提示,只需要定义 __len__() 和 __getitem__() 方法。
- def __init__(self): 主要是数据获取,如:某文件中获取;
- def __len__(self): 整个数据集的长度;
- def __getitem__(self,index): 编写支持数据集索引的函数;
例如:通过 dataset[i] 可得到数据集中第 i+1 个数据,即:如果类中定义了 __getitem__() 方法,那么实例对象(假设P)就可以这样 P[key] 取值,当实例对象做 P[key] 操作时,会调用类中的 __getitem__() 方法。 通过复写 __getitem__() 方法 可通过索引 index 来访问数据,能够同时返回 数据 和 标签label,这里的数据和标签都为 Tensor 类型。
四、DataLoader类详解
DataLoader 是pytorch中用来处理模型输入数据的一个工具,组合了数据集dataset+采样器sampler,并在数据集上提供单线程或多线程(num_workers)的可迭代对象。
DataLoader 几种访问方式:
(1)dataloader 本质上是一个可迭代对象,使用 iter() 访问,不能使用 next() 访问,它本身就是一个可迭代对象, 使用 for i, data in enumerate(dataloader) 来访问。
(2)先使用 iter 对 dataloader 进行第一步包装,使用 iter(dataloader) 返回的是一个迭代器,然后可以使用 next 访问。
注:一般不需要自己去实现 DataLoader 方法了, 只需要在构造函数中指定相应的参数即可,重点介绍一下构造函数中参数的含义。
torch.utils.data.DataLoader(dataset, batch_size=1,shuffle=False,sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None)
Arguments:
dataset (Dataset): 是一个DataSet对象,表示需要加载的数据集.
batch_size (int, optional): 每一个batch加载多少组样本,即指定batch_size,默认是 1
shuffle (bool, optional): 布尔值True或者是False ,表示每一个epoch之后是否对样本进行随机打乱,默认是False
------------------------------------------------------------------------------------
sampler (Sampler, optional): 自定义从数据集中抽取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler (Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥)
------------------------------------------------------------------------------------
num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数(这个还不是很懂)
pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
------------------------------------------------------------------------------------
drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了,如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
------------------------------------------------------------------------------------
timeout (numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
worker_init_fn (callable, optional): If not ``None``, this will be called on each worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as input, after seeding and before data loading. (default: ``None``)