【JS 逆向百例】转变思路,少走弯路,X米加密分析

文章目录
-
- 声明
- 逆向目标
- 逆向过程
-
- 抓包分析
- 参数逆向
-
- 基本参数
- hash
- 总结
- 完整代码
-
- Python 登录关键代码
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
- 目标:X米账号登录
- 主页:aHR0cHM6Ly9hY2NvdW50LnhpYW9taS5jb20v
- 接口:aHR0cHM6Ly9hY2NvdW50LnhpYW9taS5jb20vcGFzcy9zZXJ2aWNlTG9naW5BdXRoMg==
- 逆向参数:Form Data:
hash: FCEA920F7412B5DA7BE0CF42B8C93759
逆向过程
抓包分析
来到X米的登录页面,随便输入一个账号密码登陆,抓包定位到登录接口为 aHR0cHM6Ly9hY2NvdW50LnhpYW9taS5jb20vcGFzcy9zZXJ2aWNlTG9naW5BdXRoMg==

POST 请求,Form Data 里的参数比较多,分析一下主要参数:
- serviceParam:
{"checkSafePhone":false,"checkSafeAddress":false,"lsrp_score":0.0},从参数的字面意思来看,似乎是在检查手机和地址是否安全,至于具体是什么含义,暂时不得而知,也不知道是在哪个地方设置的。 - callback:
http://order.xxx.com/login/callback?followup=https%3A%2F%2Fwww.xx......,回调链接,一般来说是固定的,后面带有 followup 和 sid 参数。 - qs:
%3Fcallback%3Dhttp%253A%252F%252Forder.xxx.com%252Flogin%252Fcallback%2......,把 qs 的值格式化一下可以发现,其实是 callback、sign、sid、_qrsize 四个值按照 URL 编码进行组合得到的。 - _sign:
w1RBM6cG8q2xj5JzBPPa65QKs9w=,这个一串看起来是经过某种加密后得到的,也有可能是网页源码中的值。 - user:
15555555555,明文用户名。 - hash:
FCEA920F7412B5DA7BE0CF42B8C93759,加密后的密码。
参数逆向
基本参数
先来看一下 serviceParam 等基本参数,一般思路我们是先直接搜索一下看看能不能直接找到这个值,搜索发现 serviceParam 关键字在一个 302 重定向请求里:
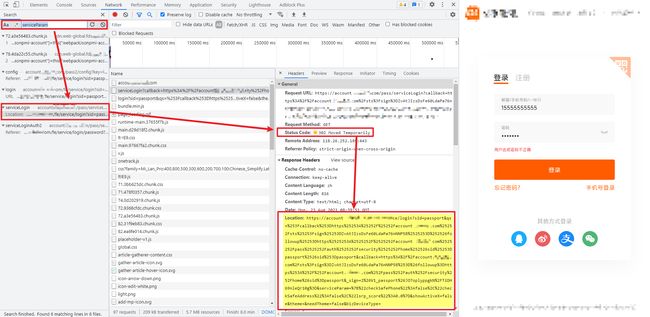
我们注意到,当只输入登录的主页 aHR0cHM6Ly9hY2NvdW50LnhpYW9taS5jb20v,它会有两次连续的 302 重定向,来重点分析一下这两次重定向。
第一次重定向,新的网址里有 followup、callback、sign、sid 参数,这些我们都是在后面的登录请求中要用到的。


第二次重定向,新的网址里同样有 followup、callback、sign、sid 参数,此外还有 serviceParam、qs 参数,同样也是后面的登录请求需要用到的。


找到了参数的来源,直接从第二次重定向的链接里提取各项参数,这里用到了 response.history[1].headers['Location'] 来提取页面第二次重定向返回头里的目标地址,urllib.parse.urlparse 来解析重定向链接 URL 的结构,urllib.parse.parse_qs 提取参数,返回字典,代码样例:
import requests
import urllib.parse
headers = {
'Host': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
index_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
response = requests.get(url=index_url, headers=headers)
location_url = response.history[1].headers['Location']
urlparse = urllib.parse.urlparse(location_url)
query_dict = urllib.parse.parse_qs(urlparse.query)
print(query_dict)
need_theme = query_dict['needTheme'][0]
show_active_x = query_dict['showActiveX'][0]
service_param = query_dict['serviceParam'][0]
callback = query_dict['callback'][0]
qs = query_dict['qs'][0]
sid = query_dict['sid'][0]
_sign = query_dict['_sign'][0]
print(need_theme, show_active_x, service_param, callback, qs, sid, _sign)
hash
其他参数都齐全了,现在还差一个加密后的密码 hash,一般来讲这种都是通过 JS 加密的,老方法,全局搜索 hash 或者 hash:,可以在 78.4da22c55.chunk.js 文件里面看到有一句:hash: S()(r.password).toUpperCase(),很明显是将明文的密码经过加密处理后再全部转为大写:

重点是这个 S(),鼠标移上去会发现其实是调用了 78.4da22c55.chunk.js 的一个匿名函数,我们在匿名函数的 return 位置埋下断点进行调试:

e.exports = function(e, n) {
if (void 0 === e || null === e)
throw new Error("Illegal argument " + e);
var r = t.wordsToBytes(u(e, n));
return n && n.asBytes ? r : n && n.asString ? s.bytesToString(r) : t.bytesToHex(r)
}
可以看到传进来的 e 是明文的密码,最后的 return 语句是一个三目运算符,由于 n 是 undefined,所以最后 return 的实际上是 t.bytesToHex(r),其值正是加密后的密码,只不过所有字母都是小写,按照正常思维,我们肯定是开始扣 JS 了,这里传入了参数 r,var r = t.wordsToBytes(u(e, n));,先跟进 u 这个函数看看:
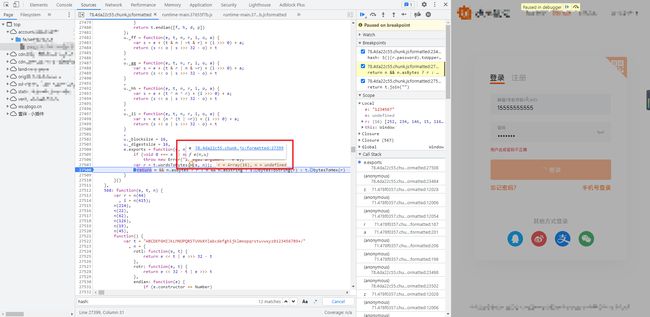
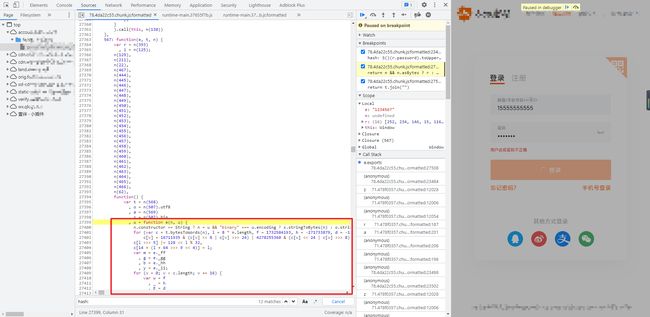
可以看到 u 函数实际上是用到了 567 这个对象方法,在这个对象方法里面,还用到了 129、211、22 等非常多的方法,这要是挨个去扣,那还不得扣到猴年马月,而且还容易出错,代码太多也不好定位错误的地方,所以这里需要转变一下思路,先来看看 t.bytesToHex(r) 是个什么东东,跟进到这个函数:
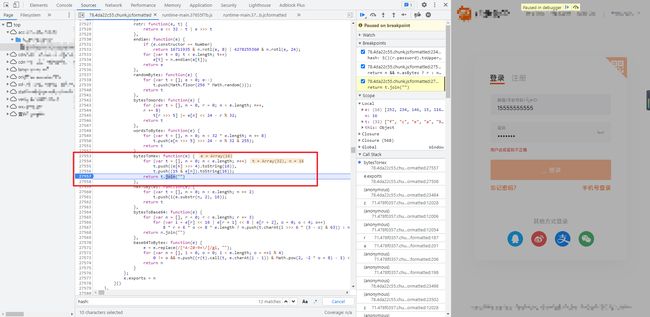
bytesToHex: function(e) {
for (var t = [], n = 0; n < e.length; n++)
t.push((e[n] >>> 4).toString(16)),
t.push((15 & e[n]).toString(16));
return t.join("")
}
解读一下这段代码,传进来的 e 是一个 16 位的 Array 对象,定义了一个 t 空数组,经过一个循环,依次取 Array 对象里的值,第一次经过无符号右移运算(>>>)后,转为十六进制的字符串,将结果添加到 t 数组的末尾。第二次进行位运算(&)后,同样转为十六进制的字符串,将结果添加到 t 数组的末尾。也就是说,原本传进来的 16 位的 Array 对象,每一个值都经过了两次操作,那么最后结果的 t 数组中就会有 32 个值,最后再将 t 数组转换成字符串返回。
结合一下调用的函数名称,我们来捋一下整个流程,首先调用 wordsToBytes() 方法将明文密码字符串转为 byte 数组,无论密码的长度如何,最后得到的 byte 数组都是 16 位的,然后调用 bytesToHex() 方法,循环遍历生成的 byte 类型数组,让其生成 32 位字符串。
无论密码长度如何,最终得到的密文都是 32 位的,而且都由字母和数字组成,这些特点很容易让人想到 MD5 加密,将明文转换成 byte 数组后进行随机哈希,对 byte 数组进行摘要,得到摘要 byte 数组,循环遍历 byte 数组,生成固定位数的字符串,这不就是 MD5 的加密过程么?
直接把密码拿来进行 MD5 加密,和网站的加密结果进行对比,可以发现确实是一样的,验证了我们的猜想是正确的:

既然如此,直接可以使用 Python 的 hashlib 模块来实现就 OK 了,根本不需要去死扣代码,代码样例:
import hashlib
password = "1234567"
encrypted_password = hashlib.md5(password.encode(encoding='utf-8')).hexdigest().upper()
print(encrypted_password)
# FCEA920F7412B5DA7BE0CF42B8C93759
总结
有的时候需要我们转变思路,不一定每次都要死扣 JS 代码,相对较容易的站点的加密方式无非就是那么几种,有的是稍微进行了改写,有的是把密钥、偏移量等参数隐藏了,有的是把加密解密过程给你混淆了,让你难以理解,如果你对常见的加密方式和原理比较熟悉的话,有时候只需要搞清楚他用的什么加密方式,或者拿到了密钥、偏移量等关键参数,就完全可以自己还原整个加密过程!
完整代码
GitHub 关注 K 哥爬虫,持续分享爬虫相关代码!欢迎 star !
https://github.com/kgepachong/
以下只演示部分关键代码,完整代码仓库地址:
https://github.com/kgepachong/crawler/
Python 登录关键代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import json
import hashlib
import urllib.parse
import requests
index_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
login_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'Host': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'Origin': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'Referer': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
session = requests.session()
def get_encrypted_password(password):
encrypted_password = hashlib.md5(password.encode(encoding='utf-8')).hexdigest().upper()
return encrypted_password
def get_parameter():
response = requests.get(url=index_url, headers=headers)
location_url = response.history[1].headers['Location']
urlparse = urllib.parse.urlparse(location_url)
query_dict = urllib.parse.parse_qs(urlparse.query)
# print(query_dict)
return query_dict
def login(username, encrypted_password, query_dict):
data = {
'bizDeviceType': '',
'needTheme': query_dict['needTheme'][0],
'theme': '',
'showActiveX': query_dict['showActiveX'][0],
'serviceParam': query_dict['serviceParam'][0],
'callback': query_dict['callback'][0],
'qs': query_dict['qs'][0],
'sid': query_dict['sid'][0],
'_sign': query_dict['_sign'][0],
'user': username,
'cc': '+86',
'hash': encrypted_password,
'_json': True
}
response = session.post(url=login_url, data=data, headers=headers)
response_json = json.loads(response.text.replace('&&&START&&&', ''))
print(response_json)
return response_json
def main():
username = input('请输入登录账号: ')
password = input('请输入登录密码: ')
encrypted_password = get_encrypted_password(password)
parameter = get_parameter()
login(username, encrypted_password, parameter)
if __name__ == '__main__':
main()