一、Yarn
以获取Yarn界面队列信息为例:
1. 接口(HTTP Request)
http://ip:port/ws/v1/cluster/...
ip和port:Yarn ResourceManager active节点的ip地址和端口号
2. 请求方式
GET
3. Response Header
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Server: Jetty(6.1.26)4. Response Body
Yarn web ui显示的队列信息:
请求http://bigdatalearnshare01:80...:
{
"scheduler":{
"schedulerInfo":{
"type":"capacityScheduler", -- 调度器类型
"capacity":100,
"usedCapacity":14.583333,
"maxCapacity":100,
"queueName":"root", -- root为根队列
"queues":{
"queue":[
{
"type":"capacitySchedulerLeafQueueInfo",
"capacity":20, -- 分配的容量(占整个队列的百分比)
"usedCapacity":20.83418, -- 使用队列容量(占当前队列的百分比)
"maxCapacity":20,
"absoluteCapacity":20,
"absoluteMaxCapacity":20,
"absoluteUsedCapacity":4.166667,
"numApplications":1,
"queueName":"default", -- 队列名字
"state":"RUNNING", -- 运行状态
"resourcesUsed":{"memory":2048,"vCores":2},
"hideReservationQueues":false,
"nodeLabels":["*"],
"allocatedContainers":2,
"reservedContainers":0,
"pendingContainers":0,
"capacities":{
"queueCapacitiesByPartition":[
{"partitionName":"","capacity":20,"usedCapacity":20.83418,"maxCapacity":20,
"absoluteCapacity":20,"absoluteUsedCapacity":4.166667,
"absoluteMaxCapacity":20,"maxAMLimitPercentage":50}
]
},
"resources":{
"resourceUsagesByPartition":[
{
"partitionName":"",
"used":{"memory":2048,"vCores":2},
"reserved":{"memory":0,"vCores":0},
"pending":{"memory":0,"vCores":0},
"amUsed":{"memory":1024,"vCores":1},
"amLimit":{"memory":5120,"vCores":1}
}
]
},
"numActiveApplications":1,
"numPendingApplications":0,
"numContainers":2,
"maxApplications":2000,
"maxApplicationsPerUser":2000,
"userLimit":100,
"users":{
"user":[
{
"username":"bigdatalearnshare",
"resourcesUsed":{
"memory":2048,
"vCores":2
},
"numPendingApplications":0,
"numActiveApplications":1,
"AMResourceUsed":{
"memory":1024,
"vCores":1
},
"userResourceLimit":{
"memory":10240,
"vCores":1
},....
....
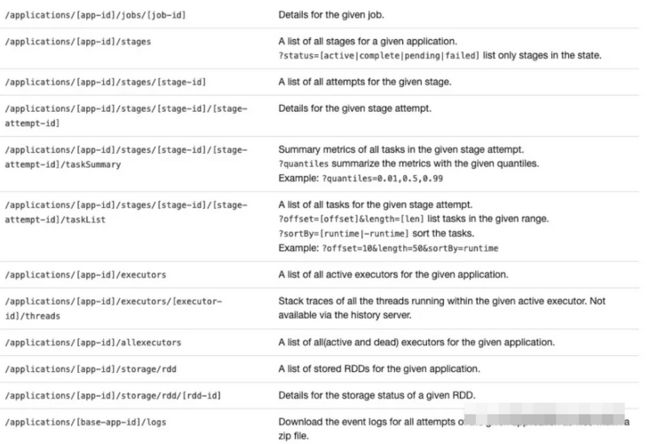
二、Spark UI
以获取Spark UI界面executors指标信息为例:
以bigdatalearnshare01:8088的Yarn上的Spark应用大数据培训实例为例,对应的Spark UI界面Executors主要信息如下:
Spark提供了很多接口去获取这些信息,比如: