第三章 PyTorch神经网络工具箱
第三章 PyTorch神经网络工具箱
3.1 神经网络核心组件
神经网络看起来很复杂,节点很多,层数多,参数更多。但核心部分或组件不多,把这些组件确定后,这个神经网络基本就确定了。这些核心组件包括:
- 层:神经网络的基本结构,将输入张量转换为输出张量。
- 模型:层构成的网络。
- 损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数。
- 优化器:如何使损失函数最小,这就涉及优化器。
这些核心组件不是独立的,它们之间,以及它们与神经网络其他组件之间有密切关系。

多个层链接在一起构成一个模型或网络,输入数据通过这个模型转换为预测值,然后损失函数把预测值与真实值进行比较,得到损失值(损失值可以是距离、概率值等),该损失值用于衡量预测值与目标结果的匹配或相似程度,优化器利用损失值更新权重参数,从而使损失值越来越小。这是一个循环过程,当损失值达到一个阀值或循环次数到达指定次数,循环结束。
3.2 实现神经网络实例

构建网络层可以基于Module类或函数(nn.functional)。nn中的大多数层(Layer)在functional中都有与之对应的函数。nn.functional 中函数与nn.Module中的Layer的主要区别是后者继承Module类,会自动提取可学习的参数。而nn.functional更像是纯函数。两者功能相同,且性能也没有很大区别,那么如何选择呢?像卷积层、全连接层、Dropout层等因含有可学习参数,一般使用nn.Module,而激活函数、池化层不含可学习参数, 可以使用nn.functional中对应的函数。
3.2.1 背景说明
利用神经网络完成对手写数字进行识别的实例,来说明如何借助 nn工具箱来实现一个神经网络,并对神经网络有个直观了解。
主要步骤:
- 利用PyTorch内置函数mnist下载数据。
- 利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器。
- 可视化源数据。
- 利用nn工具箱构建神经网络模型。
- 实例化模型,并定义损失函数及优化器。
- 训练模型。
- 可视化结果。
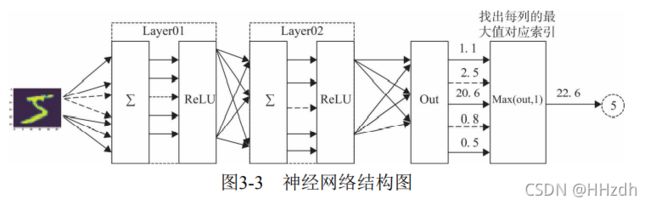
神经网络的结构使用两个隐含层,每层激活函数为ReLU,最后使用torch.max(out,1)找 出张量out最大值对应索引作为预测值。
3.2.2 准备数据
1、导入必要的模块
import numpy as np
import torch
from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据
#import torchvision
#导入预处理模块
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
#导入nn及优化器
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
from tensorboardX import SummaryWriter2、定义一些超参数
# 定义一些超参数
train_batch_size = 64
test_batch_size = 128
learning_rate = 0.01
num_epoches = 203、下载数据并对数据进行预处理
transforms.Compose可以把一些转换函数组合在一起。
#定义预处理函数
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])
#下载数据,并对数据进行预处理
train_dataset = mnist.MNIST('./data', train=True, transform=transform, download=True)
test_dataset = mnist.MNIST('./data', train=False, transform=transform)
#得到一个生成器
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)Normalize([0.5],[0.5])对张量进行归一化,这里两个0.5分别表示对张量进行归一化的全局平均值和方差。因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如3个通道,应该是Normalize([m1,m2,m3], [n1,n2,n3]);
3.2.3 可视化源数据
import matplotlib.pyplot as plt
%matplotlib inline
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
3.2.4 构建模型
数据预处理之后,开始构建网络,创建模型。
1)构建网络。
class Net(nn.Module):
"""
使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x2)实例化网络。
#实例化模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#if torch.cuda.device_count() > 1:
# print("Let's use", torch.cuda.device_count(), "GPUs")
# # dim = 0 [20, xxx] -> [10, ...], [10, ...] on 2GPUs
# model = nn.DataParallel(model)
model = Net(28 * 28, 300, 100, 10)
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)3.2.5 训练模型
训练模型,这里使用for循环,进行迭代。其中包括对训练数据的训练 模型,然后用测试数据的验证模型。
1、训练模型
# 开始训练
losses = []
acces = []
eval_losses = []
eval_acces = []
writer = SummaryWriter(log_dir='logs',comment='train-loss')
for epoch in range(num_epoches):
train_loss = 0
train_acc = 0
model.train()
#动态修改参数学习率
if epoch%5==0:
optimizer.param_groups[0]['lr']*=0.9
print(optimizer.param_groups[0]['lr'])
for img, label in train_loader:
img=img.to(device)
label = label.to(device)
img = img.view(img.size(0), -1)
# 前向传播
out = model(img)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
# 保存loss的数据与epoch数值
writer.add_scalar('Train', train_loss/len(train_loader), epoch)
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
train_acc += acc
losses.append(train_loss / len(train_loader))
acces.append(train_acc / len(train_loader))
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
#net.eval() # 将模型改为预测模式
model.eval()
for img, label in test_loader:
img=img.to(device)
label = label.to(device)
img = img.view(img.size(0), -1)
out = model(img)
loss = criterion(out, label)
# 记录误差
eval_loss += loss.item()
# 记录准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
2、可视化训练及测试损失值
plt.title('train loss')
plt.plot(np.arange(len(losses)), losses)
#plt.plot(np.arange(len(eval_losses)), eval_losses)
#plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.legend(['Train Loss'], loc='upper right')
3.3 如何构建神经网络
3.3.1 构建网络层
如果要对每层定义一个名称,我们可以采用Sequential的一种改进方法,在Sequential的基础上,通过add_module()添加每一层,并且为每一层增加一个单独的名字。 此外,还可以在Sequential基础上,通过字典的形式添加每一层,并且设置单独的层名称。
以下是采用字典方式构建网络的一个示例代码:
class Net1(torch.nn.Module):
def __init__(self):
super(Net4, self).__init__()
self.conv = torch.nn.Sequential(
OrderedDict(
[
("conv1", torch.nn.Conv2d(3, 32, 3, 1, 1)),
("relu1", torch.nn.ReLU()),
("pool", torch.nn.MaxPool2d(2))
]
))
self.dense = torch.nn.Sequential(
OrderedDict([
("dense1", torch.nn.Linear(32 * 3 * 3, 128)),
("relu2", torch.nn.ReLU()),
("dense2", torch.nn.Linear(128, 10))
])
)
3.3.2 前向传播
定义好每层后,最后还需要通过前向传播的方式把这些串起来。这就是 涉及如何定义forward函数的问题。forward函数的任务需要把输入层、网络层、输出层链接起来,实现信息的前向传导。该函数的参数一般为输入数据,返回值为输出数据。 在forward函数中,有些层来自nn.Module,也可以使用nn.functional定义。来自nn.Module的需要实例化,而使用nn.functional定义的可以直接使用。
3.3.4 训练模型
层、模型、损失函数和优化器等都定义或创建好,接下来就是训练模型。训练模型时需要注意使模型处于训练模式,即调用model.train()。调用 model.train()会把所有的module设置为训练模式。如果是测试或验证阶段, 需要使模型处于验证阶段,即调用model.eval(),调用model.eval()会把所有的training属性设置为False。
缺省情况下梯度是累加的,需要手工把梯度初始化或清零,调用 optimizer.zero_grad()即可。训练过程中,正向传播生成网络的输出,计算输出和实际值之间的损失值。调用loss.backward()自动生成梯度,然后使用 optimizer.step()执行优化器,把梯度传播回每个网络。
如果希望用GPU训练,需要把模型、训练数据、测试数据发送到GPU 上,即调用.to(device)。如果需要使用多GPU进行处理,可使模型或相关数 据引用nn.DataParallel。
3.4 神经网络工具箱nn
在nn工具箱中有两个重 要模块:nn.Model、nn.functional
3.4.1 nn.Module
nn.Module是nn的一个核心数据结构,它可以是神经网络的某个层 (Layer),也可以是包含多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,生成自己的网络/层,nn中已实现了绝大多数层, 包括全连接层、损失层、激活层、卷积层、循环层等,这些层都是 nn.Module的子类,能够自动检测到自己的Parameter,并将其作为学习参数,且针对GPU运行进行了cuDNN优化。
3.4.2 nn.functional
nn.functional中的函数,其名称一般为nn.funtional.xxx,如 nn.funtional.linear、nn.funtional.conv2d、nn.funtional.cross_entropy等。
nn.Model、nn.functional两种功能都是相同的,但PyTorch官方推荐:具有学习参数的(例如,conv2d,linear,batch_norm)采用nn.Xxx方式。没有学习参数的(例 如,maxpool、loss func、activation func)等根据个人选择使用 nn.functional.xxx或者nn.Xxx方式。
3.5 优化器
所有的优化方法都是继承了基类 optim.Optimizer,并实现了自己的优化步骤。最常用的优化算法就是梯度下降法及其各种变种,这类优化算法通过使用参数的梯度值更新参数。
使用优化器的一般步骤为:
(1)建立优化器实例
(2)向前传播
(3)清空梯度
(4)反向传播
(5)更新参数
3.6 动态修改学习率参数
修改参数的方式可以通过修改参数optimizer.params_groups或新建 optimizer。新建optimizer比较简单,optimizer十分轻量级,所以开销很小。 但是新的优化器会初始化动量等状态信息,这对于使用动量的优化器 (momentum参数的sgd)可能会造成收敛中的震荡。所以,这里直接采用修 改参数optimizer.params_groups。
optimizer.param_groups:长度1的list,optimizer.param_groups[0]:长度为6的字典,包括权重参数、lr、momentum等参数。
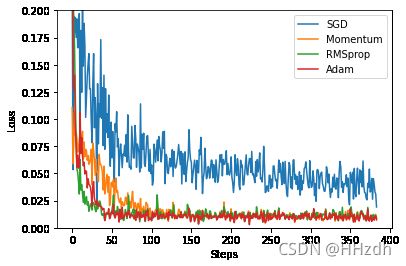
3.7 优化器比较
1)导入需要的模块。
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
# 超参数
LR = 0.01
BATCH_SIZE = 32
EPOCH = 122)生成数据。
# 生成训练数据
# torch.unsqueeze() 的作用是将一维变二维,torch只能处理二维的数据
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
# 0.1 * torch.normal(x.size())增加噪点
y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))3)构建神经网络。
torch_dataset = Data.TensorDataset(x,y)
#得到一个代批量的生成器
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True)
class Net2(torch.nn.Module):
# 初始化
def __init__(self):
super(Net2, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
# 前向传递
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x4)使用多种优化器。
net_SGD = Net2()
net_Momentum = Net2()
net_RMSProp = Net2()
net_Adam = Net2()
nets = [net_SGD, net_Momentum, net_RMSProp, net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.9)
opt_RMSProp = torch.optim.RMSprop(net_RMSProp.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSProp, opt_Adam]5)训练模型。
loss_func = torch.nn.MSELoss()
loss_his = [[], [], [], []] # 记录损失
for epoch in range(EPOCH):
for step, (batch_x, batch_y) in enumerate(loader):
for net, opt,l_his in zip(nets, optimizers, loss_his):
output = net(batch_x) # get output for every net
loss = loss_func(output, batch_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']6)可视化结果。
for i, l_his in enumerate(loss_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()