Swin Transformer全方位解读【ICCV2021最佳论文】
前言
前言就是唠唠嗑,想看干货的可以直接看下一节。
今年ICCV的最佳论文还是给到了刷榜各大CV竞赛榜的模型Swin Transformer,研究团队来自MSRA(你大爷还是你大爷啊)。
自从ViT、DETR等尝试把language模型中的王炸transformer使用到视觉领域并得到还不错的验证效果后,研究者们一直在致力于“如何更好地将语言模型建模到视觉”这个问题。ViT直接把图片划分patch,用对待word的方式来对待每个patch,轻松将图片建模成sentence;而DETR则需要CNN辅助提取特征,而transformer只是当一个neck。后者更像是一个过渡模式,咱们本文不做过多讨论。
重点说下ViT的问题,首先ViT不适合作为通用模型的backbone,不擅长处理dense输出型(如目标检测、分割等)的视觉任务。ViT通过将图像划分成不相交的patch,通过编码每个patch然后计算两两patch之间的attention,来实现聚合信息。这样,应对更高清的图片时,划分的patch数会受计算资源掣肘。你可以这么想,4x4=16个patch,两两计算注意力,和100x100=10000个patch,两两计算注意力,计算复杂度完全不一样(指数级的差别)。假如用降采样的方法依旧保持少量的patch数,那就没使用到高分辨率带来的好处;假如把用更大的编码器来保持较少的patch数,那么transformer会慢慢往MLP的方向退化。于是,研究者们开始设想一种新的transformer结构,使之能更好地适应视觉任务。
Swin Transformer就是一种通用视觉任务的Backbone而存在的模型,以替代CNN。它做到了,而且outperform现有的CNN模型。这也是其获得Best Paper的主要原因。
将ST复现到我自己的数据集(四分类),效果如下:
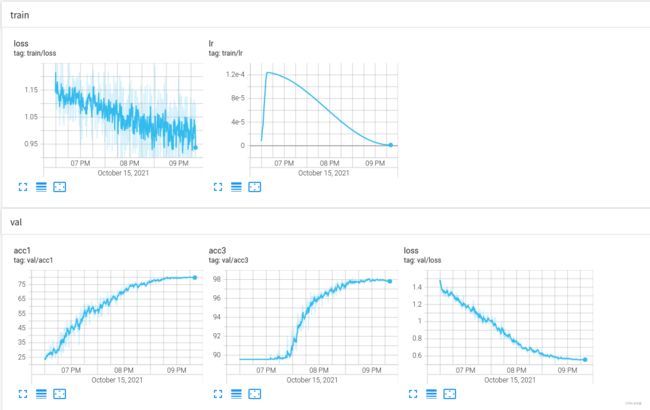
稳步收敛,最终准确率达到81%左右。
论文链接:https://arxiv.org/abs/2103.14030
论文标题:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
官方代码实现(pytorch):https://github.com/microsoft/Swin-Transformer/(本文主要参考代码)
本文行文主要参考是官方代码,次要参考才是论文。所以读者最好结合代码一起看本文。
总概
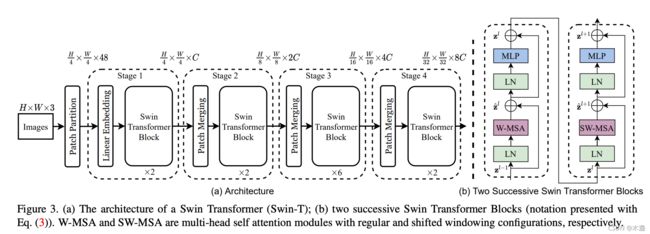
主体结构
Swin的主体结构主要由4个Basic Layer组成。每个Basic Layer都有Depths、NUM_HEADS两个主要参数,以此来区分各种量级的swin transformer(如swin tiny,swin base等)。
Depths代表这个Basic Layer由几个swin transformer block(以下简称“STB”)串联而成,如图1中虚线框中的数字’x2’,‘x2’,‘x6’等待。
NUM_HEADS代表这个Basic Layer中的STB的head数量(每个head就是一组独立的注意力计算机制,类似于CNN中的channel,不了解可戳《transformer详解》)。head数量越多,代表特征channel越多。
第一步,名词解答:Window、Patch、Token
这三个名词,我们可以用一个栗子来解答。假设输入图片的尺寸为224X224,先划分成多个大小为4x4像素的小片,每个小片之间没有交集。224/4=56,那么一共可以划分56x56个小片。每一个小片就叫一个patch,每一个patch将会被对待成一个token。所以patch=token。而一张图被划分为7x7个window,每个window之间也没有交集。那么每个window就会包含8x8个patch。这段计算整明白了,你就会了解window、patch和pixel的关系。
Patch Embedding
一张224x224的图片,被划分成56x56个patch,然后对每个patch(尺寸为4x4)进行编码得到96-d的embedding向量。
那么这一步的张量尺寸变换为:Bx224x224x3 -> Bx3196x96
这里的B表示batch size,而3196=56x56。
用白话描述:咱们每个图片被划分为3196个patch,每个patch又被编码成96维的向量。
这一步在代码上实现十分简单,就是一个Conv2D,把步长和kernel size都设置为patch的长度即可,可看:
nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
这步以后再flatten一下,就可以把56x56x96变为3196x96。
输入到STB(swin transformer block)之前,对输入张量进行dropout,这里的dropout主要是为了进行数据增强,因为这一步会随机性让一些patch embedding的数值为0,详情可戳《pytorch中nn.Dropout的使用技巧》。
Patch Merging
先把STB当做一个黑盒模型,Patch Embedding就是处理STB输入,而Patch Merging就是处理STB的输出。Patch merging模块是整个Swin Transformer模型中唯一的降采样操作。张量通过STB模块的时候尺寸是不发生改变的。

Patch Merging就好比CNN中的Pooling操作,但是比Pooling操作复杂一些。我们看图1,56x56x96对应(H/4)x(W/4)xC。经过Patch Merging以后,变为(H/8)x(W/8)x2C,即28x28x192。
分辨率下降到了1/4,而token的维度扩充到了2倍。
这一步经过了以下操作:
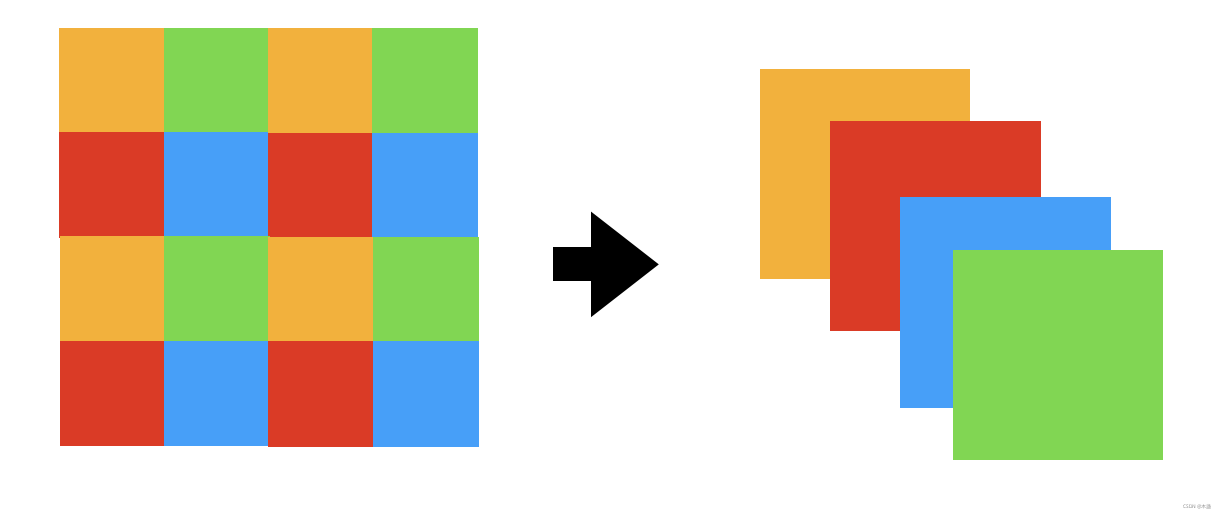
上面操作有没有些熟悉,就是pixel shuffle(链接可戳)的反过程嘛。
这一操作,直接可以把56x56x96变成28x28x(4x96),再通过一个线性层变为28x28x(2x96)。线性层如下:
nn.Linear(4*dim, 2*dim, bias=False)
有疑问可留言交流~
Swin Transformer Block
重头戏来了,Swin transformer是在标准transformer上的一个改进。主要是用Shifted window来改进标准多头自注意力模块。
ST中使用的激活函数是《GELU》,使用的正则化方法是Layer Normalization(可戳《Layer Normalization》《常见的Normalization》进一步了解)
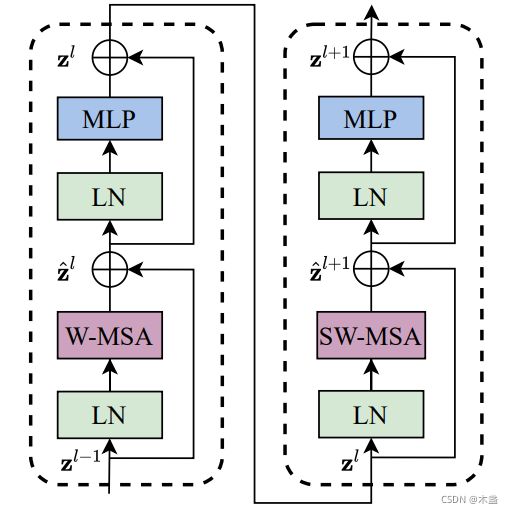
与标准transformer不同的就是紫色部分的两个框,分别是W-MSA和SW-MSA。
W-MSA表示,在window内部的Multi-Head Self-Attention,就是把window当做独立的全局来计算window中每个token两两注意力。
SW-MSA与W-MSA的一丢丢不一样,就是将window的覆盖范围偏移一下,原文设置为window的边长的一半。
W-MSA
全称为Window based Multi-head Self Attention。一张图平分为7x7个window,这些window互相都没有overlap。然后,每个window包含一定数量的token,直接对这些token计算window内部的自注意力。 以分而治之的方法,远远降低了标准transformer的计算复杂度。以第1层为例,7x7个window,每个window包含16x16个patch,相当于把标准transformer应用在window上,而不是全图上。不太了解标准transformer做法的可戳《令人心动的transformer》,文中介绍了QKV、Multi-Head self attention等原理。
那么,不同window之间的信息怎么聚合呢?这就要用到SW-MSA了。
SW-MSA
这里的shifted window相对于初始的划分有一个平移。这个平移距离刚好是单个window边长的一半。

图3
上图是一个2x2个window的例子,window通过对角线方向滑动后,中间那个window就获取到了上一层所有window的信息了。用这种Shifted Window技巧来聚合各个不相交window之间的信息被证明是在各种视觉任务中非常有效的。
SW-MSA在逻辑上很make sense,但在计算上需要颇费心机。我们看图3,当窗口滑动后,窗口数从2x2变到3x3,而且边缘的窗口也比正常窗口小。为了应对计算上的问题,作者提出了基于cyclic shift的batch computation。
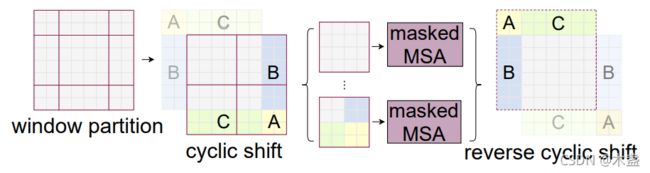
这种做法可以保证window数量不变,也可以保证每个window中的token数量也一样多。然后,通过MSA中的mask来分开window中的子窗口,如那个黄色部分A小块。这样,就可以实现非常高效且省资源的计算。
代码中通过2个torch.roll来实现。一个负责滑动过去,一个负责滑动回来。
torch.roll的图片示例为:
详情可戳《torch.roll图片实验》