web前端开发介绍
前端内容介绍
一、什么是前端
应用软件组成:前端+后端
后端负责处理业务逻辑&提供数据,任何与用户直接打交道的操作界面都可以称之为前端,主要负责页面展示、与用户交互等等下面都是前端:
- 公司官网(在PC通过浏览器来访问公司网站)
- 移动端网页(在手机上来浏览公司信息、小游戏等)
- 移动端APP(例如:淘宝、去哪儿旅游、携程等)
- 微信小程序(微信最新推出的功能,随用随装,不占用手机空间)。
前端开发是从网页制作演变而来的。
早期的网页制作主要内容都是静态的,以文字图片为主,用户使用网站也以浏览为主。
随着互联网的发展,现代网页更佳美观,交互效果显著,功能更加强大。
因此现在的前端开发的主要技术通常是指html、css、js技术和一些开发框架的使用。
二、前端的发展史(了解)

-
web1.0时代的网页制作
网页制作是web1.0时代的产物,那个时候的网页主要是静态网页,所谓的静态网页就是没有与用户进行交互而仅仅供读者浏览的网页,我们当时称为“牛皮癣”网页。
例如一篇QQ日志、一篇博文等展示性文章。在web1.0时代,用户能做的唯一事情就是浏览这个网站的文字图片内容,这时用户也不能像现在在大多数网站都可以评论交流(缺乏交互性)。
相信可能大多数人都听过“网页三剑客
Dreamweaver+Fireworks+Flash吧,这个组合就是web1.0时代额产物 -
web2.0时代的前端开发“前端开发”是从“网页制作”演变而来的。
从2005年开始,互联网进入web 2.0时代,由单一的文字和图片组成的静态网页已经不能满足用户的需求,用户需要更好的体验。
-
在web 2.0时代,网页有静态网页和动态网页。
所谓动态网页,就是用户不仅仅可以浏览网页,还可以与服务器进行交互。举个例子,你登陆新浪微博,要输入账号密码,这个时候就需要服务器对你的账号和密码进行验证通过才行。
web2.0时代的网页不仅包含炫丽的动画、音频和视频,还可以让用户在网页中进行评论交流、上传和下载文件等(交互性)。这个时代的网页,如果是用“网页三剑客Dreamweaver+Fireworks+Flash制作的,那是远远不能满足需求。现在网站开发无论是开发难度,还是开发方式上,都更接近传统的网站后台开发,所以现在不再叫“网页制作”,而是叫“web前端开发”。
所以,处于
web2.0时代的你,如果要学习网站开发技术,就不要再相信所谓的“网页三剑客Dreamweaver+Fireworks+Flash,因为这个组合已经是上个互联网时代的产物。而且这个组合开发出来的网站问题也非常多,例如代码冗余、网站维护困难(学习到后期,你会知道为什么不用这个组合了
更多前端的发展史参考:CSDN
三、为何要学前端开发
我们为什么要学习前端开发,一方面市场对程序员的要求越来越趋于全栈。另外一方面不谋全局者不足以谋一城,也就是说也就是说我们不仅要掌握后端开发的技术还要掌握一定程度的前端开发技术。 通过前面课程的学习,相信大家都已经掌握了Python基础语法、函数、面向对象、网络编程及数据库相关的内容。上面说的那些内容都是属于后端开发范畴的,在接下来的这个章节我们将一起来学习一下前端部分的内容。
四、前端开发学习历程
我们知道,用所谓的网页三剑客已经不能满足需求了,那前端开发究竟要学习什么技术呢?网页最主要由3部分组成:结构、表现和行为。网页现在新的标准是W3C,目前模式是HTML、CSS和JavaScript。
-
HTML是什么?
HTML,全称“Hyper Text Markup Language(超文本标记语言)”,简单来说,网页就是用HTML语言制作的。HTML是一门描述性语言,是一门非常容易入门的语言。
-
css
CSS,全称“(层叠样式表)”。以后我们在别的地方看到“层叠样式表”、“CSS样式”,指的就是CSS。
-
JavaScript
JavaScript是一门脚本语言。
-
前端框架
1、bootstrap
2、JQuery
3、vue
PS:其实框架就是提前给你封装好了很多操作,你只需要按照固定的语法调用即可
**HTML、CSS和JavaScript的区别 **
我们都知道前端技术最核心的是HTML、CSS和JavaScript这三种。但是这三者究竟是干嘛的呢?
HTML是网页的结构/骨架,没有任何的样式
CSS是网页的外观,给骨架添加各种样式,变得好看
JavaScript是页面的行为,控制网页的动态效果
举个栗子,如果我们把前端开发的过程比喻成“建房子”,做一个网页就像盖一栋房子
- 先把房子结构建好(HTML)
- 建好房子之后给房子装修(CSS),例如往窗户安上窗帘、往地板铺上漂亮的瓷砖
- 最后呢,装修完了之后,当夜幕降临的时候,我们要开灯(JavaScript),这样才能看得见里面。
五、软件开发架构
前面已经介绍过,点我进入详细介绍,这里只做简单说明:
CS 客户端 服务端
BS 浏览器 服务端
PS: BS本质也是CS
BS架构简单示例
首先,我们手动开发写一个套接字服务端,代码如下。
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('127.0.0.1', 8888))
s.listen(5)
while True:
conn, addr = s.accept()
data = conn.recv(1024)
print(data)
conn.send(b'http/1.1 200 ok\r\n')
conn.send(b'\r\n')
with open('index.html',mode='rb') as f:
data=f.read()
conn.send(data)
conn.close()
然后创建一个index.html文件,,将字符编码改为gbk,否则会出现乱码问题,因为谷歌浏览器默认字符编码为gbk,代码如下:
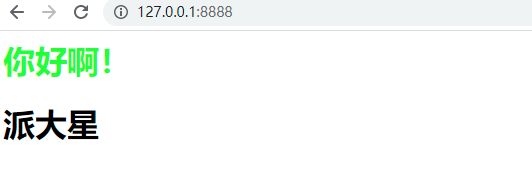
<h1 style="color: chartreuse">你好啊!</h1>
<h1>派大星</h1>
然后将客户端运行起来,在浏览器地址栏输入主机地址和端口号:http://127.0.0.1:8888/,效果如下:
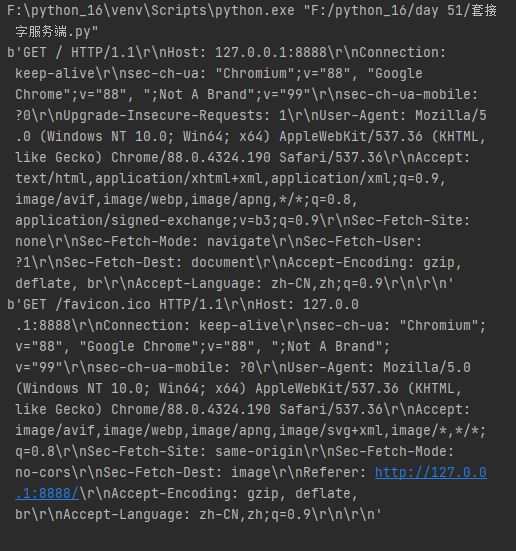
服务端就会收到客户端发送来的数据及链接请求,效果如下图。
这样就简单实现了一个BS架构,怎么样,是不是很简单啊?
六、开发环境
市面上有很多的HTML编辑器可以选择,常见的Hbuild、Sublime Text、Dreamweare都可以用来开发HTML。 当然PyCharm也支持HTML开发。
-
浏览器
浏览器在本地也能打开html文件,浏览器就跟解释器一样,从上倒下,从左到右
全球共有五大浏览器厂商,我们主要以chrome为主
ie
chrome
firfox
safri
presto
浏览器内核不同,浏览器渲染引擎不同(后期考虑兼容性问题),其他浏览器都是使用这5款浏览器内核 -
浏览器历史
世界最早浏览器,网景浏览器(Netscape )
后来它想做操作系统,动了微软的奶酪,微软就想弄死他,
微软做的也特别的绝情,微软利用windows操作系统的市场占有率,提供了免费浏览器ie,而且windows操作系统里还必须有。中国最早浏览器ie6,国企内就用ie6,
浏览器不同,解析的标签标准不同,微软太霸道,就不改标准,坚持不更新,后来谷歌和火狐抢占了市场,IE就傻逼了,目前也只有傻子才用IE。。。
市场越发地混乱,于是
w3c(万维网联盟(World Wide Web Consortium,W3C))成立,用来制定大家的统一标准须知:学前端一半工作在考虑兼容性,目前html5在兼容性方面解决的比较好
-
文件后缀名规范
.htm和.html扩展名的区别-
DOS系统(
win95或win98)下只能支持长度为3的后缀名,所以老版本的系统一直在用.htm后缀 -
但在windows后缀长度可以大于3位,所以windows下无所谓
htm与html,html是为长文件的格式命名的 -
如果文件后缀是
.htm,毫无疑问,浏览器也可以兼容,但推荐使用.html
-
七、浏览器窗口输入网址回车发生了几件事?
- 浏览器向服务端发送请求。
- 服务端接受请求(eg:请求百度请求)
- 服务端返回相应的响应(eg:返回一个百度首页)
- 浏览器接受响应,根据特定的规则渲染页面展示给用户看
浏览器可以充当很多服务端的客户端
百度 腾讯视频 优酷视频…
如何做到浏览器能够跟多个不同的客户端之间进行数据交互?
1. 浏览器很牛逼 能够自动识别不同服务端做不同处理 2. 制定一个统一的标准 如果你想要让你写的服务端能够跟客户端之间做正常的数据交互 3. 那么你就必须要遵循一些规则
八、HTTP协议
1. HTTP协议简介
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
2. 作用
- 用来规定服务端和浏览器之间的数据交互的格式
补充说明:
该协议你可以不遵循 但是你写的服务端就不能被浏览器正常访问
你就自己跟自己玩 你就自己写客户端 用户想要使用 就下载你专门的app即可
3. HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
-
客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。 -
发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。 -
服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。 -
释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求; -
客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
4.四大特性
-
基于请求响应. 向服务端发送请求, 服务端响应客户端请求.
-
基于TCP/IP之上的作用于应用层的协议
-
无状态: 不保存用户的信息
举例:海绵宝宝来了一千次,派大星每次都记不住,每次带她如初见。
拓展:由于HTTP协议是无状态的 所以后续出现了一些专门用来记录用户状态的技术
cookie、session、token... -
无链接&短链接
请求来一次我响应一次 之后我们两个就没有任何链接和关系.
拓展: 长链接. 之后出现了websocket可以实现长链接, 可以让双方建立连接之后默认不断开. 可以实现: 群聊功能、服务端主动给客户端发送消息
4.其他
4.1 请求数据格式
请求首行(标识HTTP协议版本,当前请求方式)
请求头(一大堆k,v键值对)
\r\n
请求体(并不是所有的请求方式都有. get没有post有, post存放的是请求提交的敏感数据)
4.2 响应数据格式
响应首行(标识HTTP协议版本,响应状态码)
响应头(一大堆k,v键值对)
\r\n
响应体(返回给浏览器展示给用户看的数据)
4.3 响应状态码
- 作用:用一串简单的数字来表示一些复杂的状态或者描述性信息
- 例如: 返回响应状态码为404, 则表示请求资源不存在
1xx:信息. 服务器收到请求,需要请求者继续执行操作.
2xx:成功,操作被服务器成功接收并处理 200 OK 表明该请求服务器成功接收并处理
3xx:重定向. 需要进一步的操作以完成请求.(比如: 当你在访问一个需要登陆之后才能看的页面 你会发现会自动跳转到登陆页面)
4xx:客户端请求错误. 请求包含语法错误或无法完成请求 404: 请求资源不存在(服务器无法根据客户端的请求找到对应的网页资源)
403: 服务器理解请求客户端的请求,但是拒绝执行此请求.(当前请求不合法或者不符合访问资源的条件. 比如: 这是千万级别的俱乐部, 只有999万的你被限制无法进入)
5XX: 服务器内部错误补充: 上述的状态码是HTTP协议规定的,其实到了公司之后每个公司还会自己定制自己的状态及提示信息
4.4 请求方式
get请求:
-
向服务端要数据
-
eg: 输入网址获取对应的内容
**post请求: **
-
朝服务端提交数据
-
eg: 用户登陆 输入用户名和密码之后 提交到服务端后端做身份校验
get和post方法的区别:
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如
EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中. - GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
- GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
4.5 url: 统一资源定位符(网址)
url就是我们通常所说的网址
-
形式:
scheme:[//[user:password@]host[:port]][/]path[?query-string][#anchor]提示: 方框内的是可选部分。
scheme:协议(例如:http, https, ftp)user: password@用户的登录名以及密码host:服务器的IP地址或者域名port:服务器的端口(如果是走协议默认端口,http 80 or https 443)path:访问资源的路径query-string:参数,它通常使用键值对来制定发送给http服务器的数据anchor:锚(跳转到网页的指定锚点位置)
参考资料
- 前端开发介绍:百度百科
- 前端的发展史:CSDN
- HTTP协议超级详解:博客园