常见字符串函数及其复写
文章目录
- 前言:
- 长度不受限制的函数
-
- strlen
-
- strlen复写(3种,指针,递归,循环)
- strcpy
-
- strcpy复写
- strcat
-
- strcat复写
- strcmp
-
- strcmp复写(2种,正常,vs特置)
- 为什么说这些函数不受限制
- 长度受限制的字符串函数
-
- strncpy
-
- strncpy复写
- strncat
-
- strcat复写
- strncmp
-
- strncmp复写
- 内存操作函数
-
- memcpy,memmove(内存拷贝)
-
- memmove复写
- memcmp(内存比较)
-
- memcmp复写
- memset(内存赋值)
-
- memset复写
- 字符串查找函数
-
- strstr
-
- 复写strstr
- 切分字符串
-
- strtok
-
- strtok复写:
- 错误信息报告
-
- strerror,perror
- 小结
前言:
| 博主实力有限 ,博文有什么错误,请你斧正,非常感谢! |
|---|
| 编译器:VS2019 |
| 本文介绍C语言 |
| 因为C语言只给出了,函数的作用,对函数实现并不关心,因此在VS2019下某些字符串函数的行为可能与其它编译器不同,但是效果是大同小异的。 |
| 复写strstr时,博主目前掌握了BF算法,对于KMP算法将会在后续独立出一篇博客。 |
长度不受限制的函数
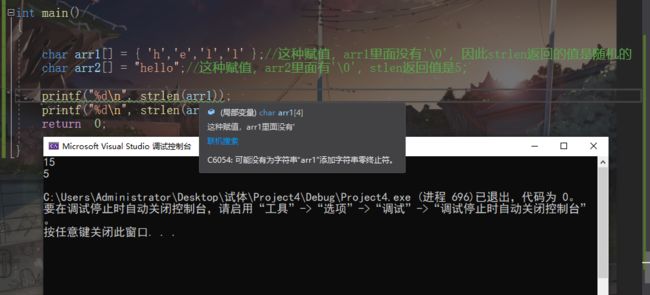
strlen
size_t strlen(const char string);*
- 返回字符串中的字符数,不包括
终止空字符(‘\0’)。注意:strlen在计算字符数时,只要碰到‘\0’,就结束计算.这就可以认为当没碰到‘\0’,就不停止计算。因此说长度不受限制
返回值:无符号整形,因此在赋值时,某些编译器可能会报警告
参数是:
常量字符指针。(不可修改指向的数据)
strlen复写(3种,指针,递归,循环)
#define _CRT_SECURE_NO_WARNINGS
#include 
strcpy
char * strcpy(char dest,const char src);
将src指向的内容依次拷贝到 dest指向的内存,直到遇到str中的’\0‘,同时返回dest的首地址。如果没遇到‘\0’,也就是src不存在’\0‘,会访问非法内存,
常量字符指针,不能更改str指向的内容。
strcpy复写
#define _CRT_SECURE_NO_WARNINGS
#include 
strcat
char * strcat(char * dest , const char src);**
从dest的字符串结束标志’\0‘开始,将src中的内容追加到dest后面。直到遇到src的’\0‘.如果没遇到,会非法访问内存。因此长度不受限制,不安全
追加字符串时不执行溢出检查。因此dest中 必须由程序执行者,预留足够空间
返回 dest的首地址
strcat复写
#define _CRT_SECURE_NO_WARNINGS
#include 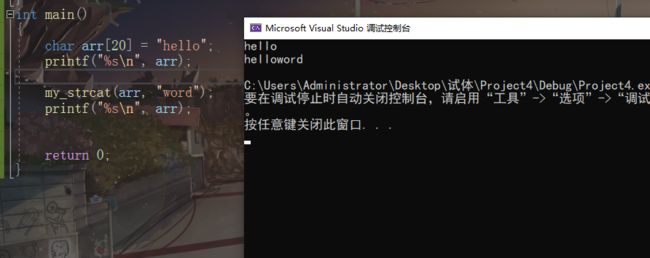
strcmp
int strcmp(const char str1, const char str2);**
比较字符串看的是ASICC,不是长度
比较 字符串str1与字符串str2是否相等.并返回一个比较值(比较字符串,只能用它。)
比较规则:
- 先比较 str1与str2指向字符的ASSICC值,如果不同
(代表字符串不等)就返回 2者差值。一旦相等就继续比较,直到str1与str2 同时都是‘\0’,(代表字符串相等)返回0;
返回值。
<0 字符串1小于字符串2。
0 字符串1与字符串2相同。
>0 字符串1大于字符串2。在复写时,我发现vs2019返回的是三个确定的值。虽然符合返回值要求,但是不能代表全部。这只是 vs内置的结果。因此复写了2种strcmp
strcmp复写(2种,正常,vs特置)
#define _CRT_SECURE_NO_WARNINGS
#include 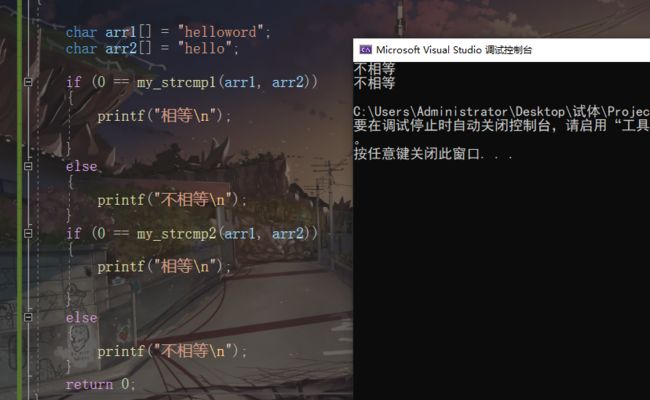
为什么说这些函数不受限制
strlen,strcpy…这些字符串函数,只是执行代码,不关心会发生什么。有可能会访问非法内存。不安全。因此后面介绍长度受限制安全的strcnpy,一定程度上安全,但是不绝对
长度受限制的字符串函数
strncpy
char strncpy(char Dest,const char* Src,size_t count);**
将 src前 count个字符拷贝到dest。但是如果count超过了src的字符个数时,会赋值’\0‘,
dest 的空间仍是程序调用者,自己控制
strncpy复写
#define _CRT_SECURE_NO_WARNINGS
#include 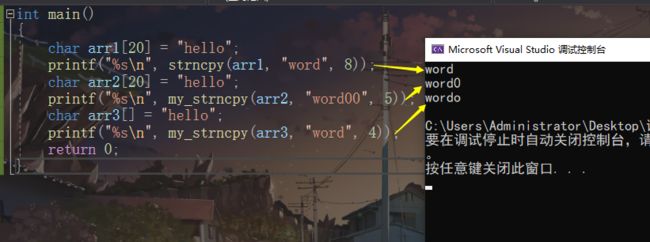
strncat
*char strncat(char Dest,const char Src,size_t count );
- 如果count大于src的长度,就将src全部追加到dest,包括‘\0’。反之,追加src前 count的字符。并再追加一个‘\0’
strcat复写
#define _CRT_SECURE_NO_WARNINGS
#include 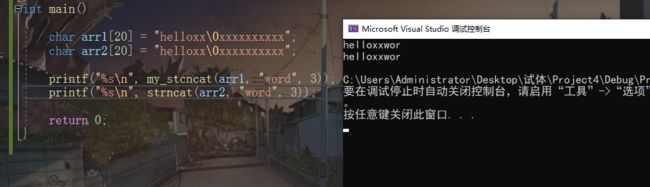
strncmp
int strncmp( const char* str1, const*char str2,size_t cnt )
- 当 cnt 大于 str1与str2 中长度最大的时,效果与 strcmp相同。反之 比较 长度最大的前cnt为。
- 比较规则同strcmp
- 注意复写时,我是以vs2019 为结论编写程序,返回值不是一个定值。
strncmp复写
#define _CRT_SECURE_NO_WARNINGS
#include 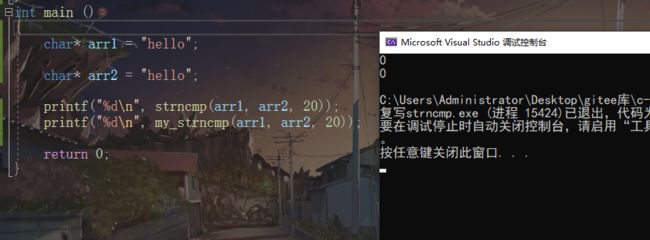
内存操作函数
memcpy,memmove(内存拷贝)
void * memcpy(void dest,const void src, size_t count )**
**void *memmove(void dest,const void src,size_t count);
这2个函数都是内存拷贝函数,效果一样。区别在于 memcpy只管拷贝(不考虑重叠拷贝),而memmove
在拷贝时会注意重叠拷贝的问题。因此称memcpy是半拷 贝,而memmove是全拷贝。
注意VS2019中的memcpy,memmove都是全拷贝。
因此在复写时,我选择了复写一个memmove
memmove复写

#define _CRT_SECURE_NO_WARNINGS
#include memcmp(内存比较)
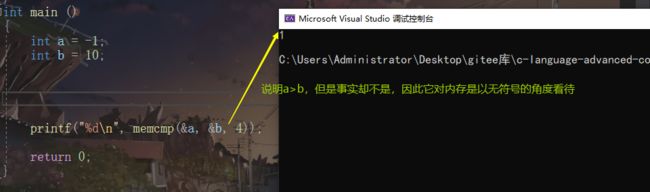
**int memcmp(const void buf1,const void buf2,size_t count);
比较内存中的元素,与strcmp道理相同。只是以内存角度比较字节。
memcmp是将内存中的补码看成无符号型,。
memcmp复写
#define _CRT_SECURE_NO_WARNINGS
#include 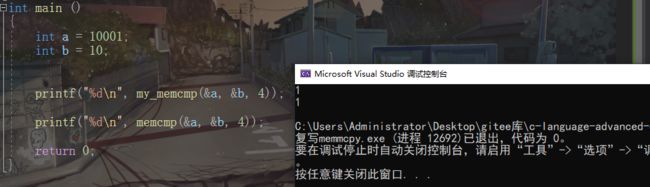
memset(内存赋值)
void memset(void*dest,int c,size_t count);*
- 将缓冲区(内存)设置为指定的字符c。
- 缓冲区的大小由调用者设置,要合适。
memset复写
#define _CRT_SECURE_NO_WARNINGS
#include 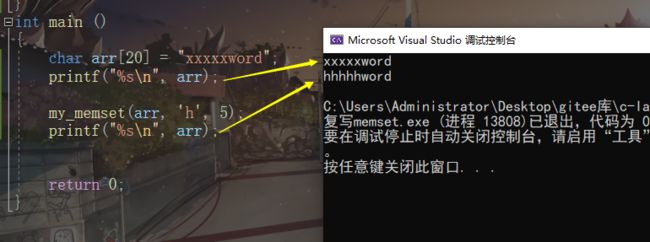
字符串查找函数
strstr
char strstr(const char*str1,const char * str2);*
在str1中搜索str2.要求str1于str2都是NULL结尾的字符串,否则行为未定义
返回一个指针,指向字符串 中首次出现的str2,如果字符串中没有出现str2,则返回NULL。如果str2指向长度为零的字符串,则函数返回字符串。
使用的是BF(暴力查找法)复写。KMP会在后续单独一篇博客
复写strstr
#define _CRT_SECURE_NO_WARNINGS
#include 
切分字符串
strtok
char strtok(char str,const char sep)*
sep是分隔符的集合
str指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的
标记,标记是一个非包含sep的字符串。如果传入的参数str不为NULL,那么strtok会返回第一个标记的首地址,并将分隔符置为‘\0’,同时strtok会记住这个分隔符的位置。如果传入的参数为NULL,strtok会从记住的位置开始分割字符串。
也就是说我们想将一个字符彻底切分完,在第二次调用时要传入NULL。
如果字符串中不存在更多的标记,则返回 NULL 指针
下面距离说明:
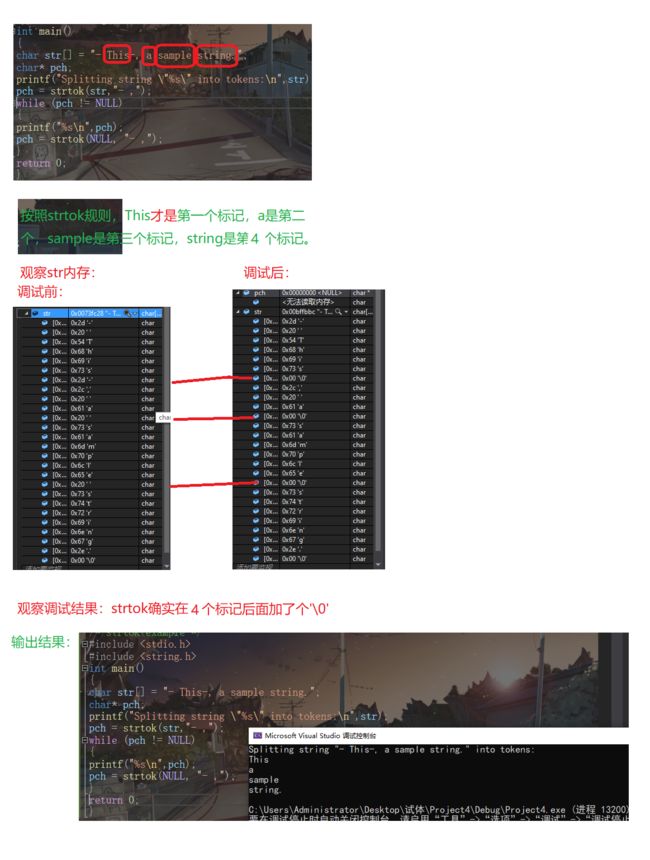
strtok复写:
#define _CRT_SECURE_NO_WARNINGS
#include 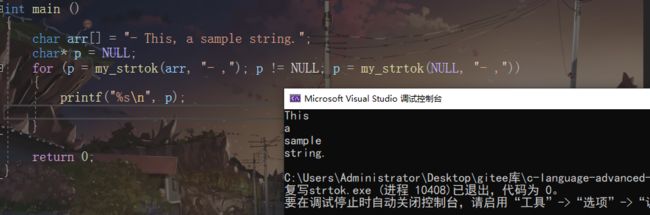
错误信息报告
strerror,perror
char * strerror(int errnum);
*void*perror(const char string);
- 编译器会将程序中的出现所有错误(如少分号,少{}等)对应一个码,称谓错误码。每个错误码对应一个错误信息字符串。而错误码存储在errno中(< errno,h >)
strerror会返回错误码对应字符串的首地址。不会主动打印错误信息,因此如果需要打印错误信息,需要printf函数
perror不仅·可以自动打印错误信息,还可以人为的添加一些信息,与错误信息组成新的字符串。


小结
- 函数的复写过程,必须考虑到很多情况,提高函数的鲁棒性。可能BF算法笨(我就是。。。。。),但是算法都是一步一步优化的。
- 关于字符串函数就介绍到这了。如果想了解其它字符串函数,可以去网站:https://en.cppreference.com/w/