初勘数据处理之预测算法(随机森林random forest)附matlab源码
初勘数据处理之预测算法(随机森林random forest)附matlab源码
-
集成学习方法
集成学习方法,是整合多个分类方法的预测结果,以提高分类准确率。集成学习方法先用训练数据构建一组基分类器,再对所有基分类器的预测进行投票,从而决定分类结果。集成学习方法不是简单地用多个不同的分类器在同一数据集上重复训练,而是使数据集产生一定程度的扰动。分类器预测错误的部分原因是未知数据与所学习数据在分布上存在区别,通过设置一定程度的扰动,分类器能学习到更一般的模型,消除单个分类器产生的偏差,得到更加精准的模型。构建集成分类器的方法主要有装袋bagging、提升boosting等。
基于数据的学习方法都面临数据的随机性这一问题。学习方法的任何一次实现都是基于某一个特定的数据集上,这个数据集只是众多可能数据中的一次随机抽样。这种随机性会影响学习方法的预测结果,并使学习到的分类器具有定的偶然性,尤其是在训练数据集较小时。决策树在每个节点处进行划分时,是根据节点下局部的划分准则进行的,易受样本随机性的影响,这就容形成过学习,使决策树不够稳定。装袋方法正好可以克服单个分类器的不稳定性,随机森林就是装袋方法(bagging)在决策树(decision tree)上的实现。 -
随机森林
随机森林,是由很多决策树组成的“森林”,它通过多棵树的投票来进行决策。
理论与实验研究表明,随机森林能够有效地提高分类器的推广能力。构建随机森林的方法包括三个基本步骤:
1). 首先,从原来的个训练样本中有放回地随机抽取个样本(样本可能有重复),得到一个样本集。重复这个过程 n 次,得到 n 个样本集。
2). 然后,用每个样本集作为训练样本构造决策树。在构造决策树的过程中,在每一个节点处,从候选特征中随机选择 m 个特征,作为决策的备选特征,再从这些特征中选择最好的特征进行划分。每棵决策树都会完整生长而不会剪枝。
3). 最后,得到 n 棵决策树后,对这些树的输出进行投票,将得票最多的类作为最终的决策。
随机森林方法既对训练样本采样,又对特征采样,保证了决策树之间的独立性,使得投票结果无偏。 -
预测效果评价
常用评价系数及matlab实现:
% correlation coefficient, r:相关系数
R21=sum((dataObs -mean(dataObs)).*( dataSim - mean(dataSim)));
R22=sqrt(sumsqr(dataObs -mean(dataObs)).*sumsqr(dataSim - mean(dataSim)));
r = R21/R22;
% Nash-Sutcliffe Efficiencyt, ENS:纳什系数
ENS = (1-(sumsqr(dataObs - dataSim)/sumsqr(dataObs - mean(dataObs))));
% COEFFICIENT OF DETERMINATION(决定系数) d
d =(1-(sumsqr(dataObs - dataSim)/sumsqr(abs(dataSim - mean(dataObs) + abs(dataObs -mean(dataObs))))));
% Peak Percentage Deviation, Pdv:峰值偏差百分比
Pdv = (1-max(dataSim)/max(dataObs))*100;
% Root Mean Square Error, RMSE:均方根误差
RMSE = sqrt(sumsqr(dataObs - dataSim)/length(dataObs));
% Mean Absolute Error, MAE:平均绝对误差
MAE = (sum(abs(dataSim - dataObs)))/length(dataObs);
- 随机森林预测算法(prediction based on random forest)应用案例
应用背景:随着交通基础设置建设和智能运输系统的发展,交通规划和交通诱导巳成为交通领域研究的热点 对于交通规划和交通诱导来说,准确的交通流量预测是其实现的前提和关键通流量预测根据时间跨度可以分为长期交通流量预测和短期交通流量预测:长期交通流量预测以小时、天、月甚至年为时间单位,是宏观意义上的预测;短时交通流量预测一般的时间跨度不超过 15 分钟,是微观意义上的预测。短时交通流量预测是智能运输系统的核心内容,智能运输系统中多个子系统的功能实现都以其为基础。短时交通流量预测具有高度非线性和不确定性等特点,并且同时间相关性较强,可以看成是时间序列预测问题,比较常用的方法包括多元钱性回归预测、AR 模型预测、ARMA 模型预测、指数平滑预测等。
数据集:traffic_flux 《MATLAB神经网络43个案例分析 chapter 32 小波神经网络预测交通流量》
matlab实现代码:
%% 清空数据缓存
clear
clc
close all
%% 功能选项
%randomise parameters, ensure the results are reproducible.
%rand('twister', 123);
s = RandStream('mlfg6331_64');
%% 数据集加载
load traffic_flux input output input_test output_test
trnIn=input;
trnOut=output;
chkIn=input_test;
chkOut=output_test;
%% 查看可用GPU
% Use GPU if available
ngpus=gpuDeviceCount;
disp([num2str(ngpus) ' GPUs found'])
if ngpus>0
lgpu=1;
disp('GPU found')
useGPU='yes';
else
lgpu=0;
disp('No GPU found')
useGPU='no';
end
% Find number of cores
ncores=feature('numCores');
disp([num2str(ncores) ' cores found'])
% Find number of cpus
import java.lang.*;
r=Runtime.getRuntime;
ncpus=r.availableProcessors;
disp([num2str(ncpus) ' cpus found'])
if ncpus>1
useParallel='yes';
else
useParallel='no';
end
[archstr,maxsize,endian]=computer;
disp(['This is a ' archstr ' computer that can have up to ' num2str(maxsize) ' elements in a matlab array and uses ' endian ' byte ordering.'])
% Set up the size of the parallel pool if necessary
npool=ncores;
% Opening parallel pool
if ncpus>1
tic
disp('Opening parallel pool')
% first check if there is a current pool
poolobj=gcp('nocreate');
% If there is no pool create one
if isempty(poolobj)
command=['parpool(' num2str(npool) ');'];
disp(command);
eval(command);
else
poolsize=poolobj.NumWorkers;
disp(['A pool of ' poolsize ' workers already exists.']);
end
% Set parallel options
%paroptions = statset('UseParallel',true);
%Set parrellel streams to have same seed value for repeated results
paroptions = statset('UseParallel',true,'Streams', s, 'UseSubStreams',true);
toc
end
%% 回归预测算法总体
%Random Forest Model variables
tic % starts the timer.
leaf=5; % this number could be varied.
ntrees=800; % this number could be varied.
fboot=1; % this number could be varied.
surrogate='on'; % this could be set 鈥榦n鈥?or 鈥榦ff鈥?
% leaf=1, 3, 5, 10, 20;
% ntrees=50, 200, 800, 1600;
% fboot=0, 0.4, 0.8, 1.0;
% surrogate='on';
%Trainging Periods ------------------
%Build Model
In = trnIn;
Out = trnOut;
b = TreeBagger(ntrees,In,Out,'Method','regression','oobvarimp','on','surrogate',surrogate,'minleaf',leaf,'FBoot',fboot,'Options',paroptions);
reset(s);
toc;
TrainY = oobPredict(b);
yTrain = predict(b,In);
%Predict with traing ------------------
y = predict(b, In);
simulatedTrain = y;
dataObsTrain = Out;
mseTrain = oobError(b,'mode','ensemble'); %single MSE for RF
%Predict with testing ------------------
dataSim = predict(b,chkIn);
dataObs = chkOut;
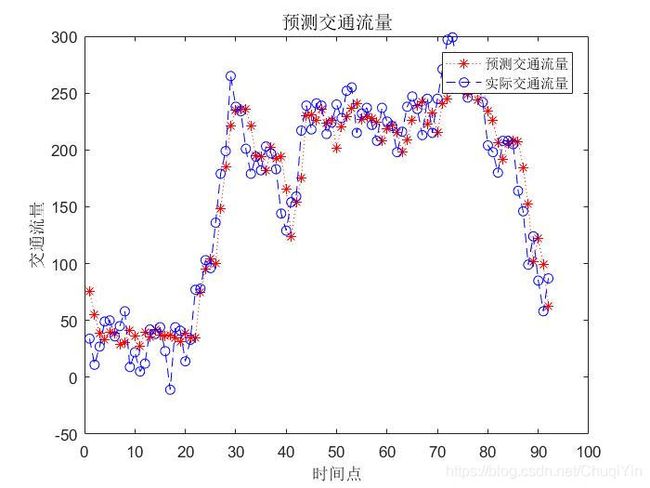
%% 结果分析
figure(1)
plot(dataSim,'r*:')
hold on
plot(dataObs,'bo--')
title('预测交通流量','fontsize',12)
legend({
'预测交通流量', '实际交通流量'})
xlabel('时间点')
ylabel('交通流量')
预测效果图:
具体的评价系数大家可以实测一下!随机森林的工具包可以在我的资源中下载,实测可用!