python自动化办公技巧 -- word、excel及pdf转换
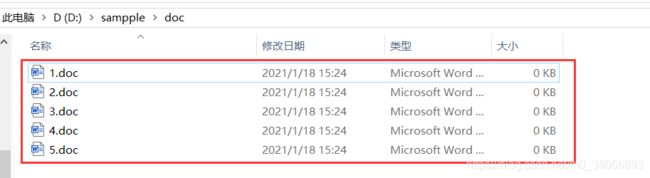
1.doc文件批量转docx文件
(1)原有文件
(2)代码
# 1.doc格式批量转docx.py
import os
from win32com import client
def getAllFilesList(filepath):
"""
获取指定目录下的所有doc文件列表
:param filepath: 指定目录
:return: 指定目录下的所有doc文件列表
"""
files = []
for file in os.listdir(filepath):
if file.endswith(".doc"):
files.append(filepath + file)
return files
if __name__ == '__main__':
filepath = "D:" + os.sep + "sampple" + os.sep + "doc" + os.sep
# print(filepath)
files = getAllFilesList(filepath)
word = client.Dispatch("Word.Application")
i = 0
for file in files:
try:
doc = word.Documents.Open(file) # 打开word文件
doc.SaveAs("{}x".format(file), 12) # 另存为后缀为“.docx”的文件,其中参数12指的doc文件
doc.Close() # 关闭原来的word文件
print(file + '转换成功!')
i += 1
except:
print(file + '转换失败!')
files.append(file) # 将文件名添加到files列表中重新读取
pass
print("转换文件%i个" % i)
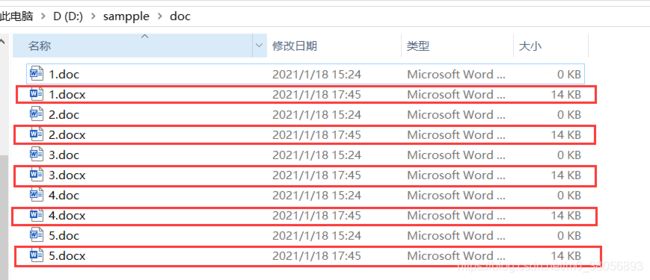
word.Quit()(3)运行结果

目录下新生成了每个doc文件对应的docx文件
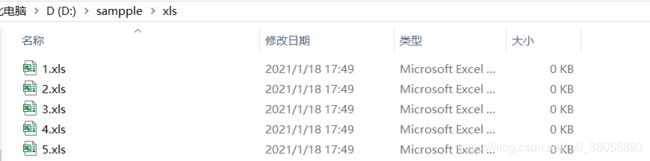
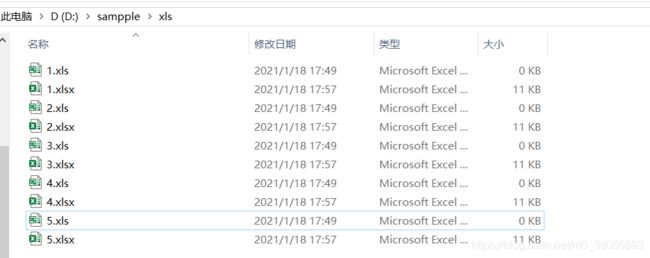
2.xls文件批量转xlsx
(1)原有文件
(2)代码
# 2.xls文件批量转xlsx.py
import os
from win32com import client
def getAllFilesList(filepath):
"""
获取指定目录下的所有xls文件列表
:param filepath: 指定目录
:return: 指定目录下的所有xls文件列表
"""
files = []
for file in os.listdir(filepath):
if file.endswith(".xls"):
files.append(filepath + file)
return files
if __name__ == '__main__':
filepath = "D:" + os.sep + "sampple" + os.sep + "xls" + os.sep
# print(filepath)
files = getAllFilesList(filepath)
# 运行excel程序
excel = client.gencache.EnsureDispatch('Excel.Application')
# 设置excel另存时当有重名的文件时不提示弹窗预警
excel.Application.DisplayAlerts = False
i = 0
for file in files:
try:
xls = excel.Workbooks.Open(file) # 打开excel文件
xls.SaveAs("{}x".format(file), 51) # 另存为后缀为“.xlsx”的文件,其中参数51指的doc文件
xls.Close() # 关闭原来的excel文件
print(file + '转换成功!')
i += 1
except:
print(file + '转换失败!')
files.append(file) # 将文件名添加到files列表中重新读取
pass
print("转换文件%i个" % i)
excel.Quit()
(3)运行结果
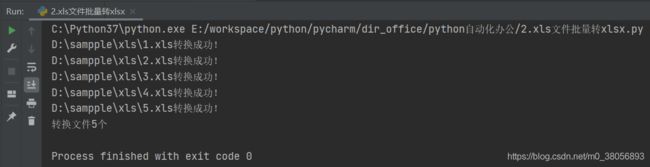
目录下新生成了每个xls文件对应的xlsx文件
3.批量合并结构相同的excel文件
(1)原有的excel文件中内容
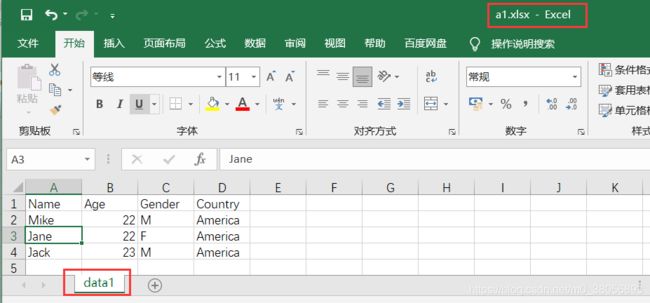
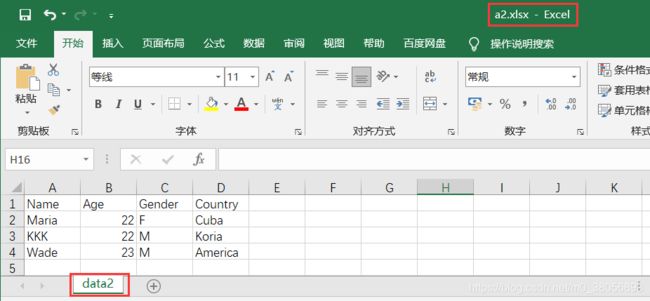
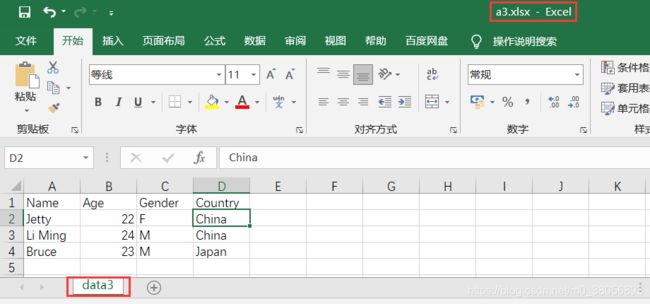
(2)代码
# 3.同结构excel文件批量合并.py
import os
import pandas as pd
def getAllFilesList(filepath):
"""
获取指定目录下的所有xlsx文件列表
:param filepath: 指定目录
:return: 指定目录下的所有xlsx文件列表
"""
files = []
for file in os.listdir(filepath):
if file.endswith(".xlsx"):
files.append(filepath + file)
return files
if __name__ == '__main__':
filepath = "D:" + os.sep + "sampple" + os.sep + "xlsx_merge" + os.sep
files = getAllFilesList(filepath)
# 定义一个空的dataframe
data = pd.DataFrame()
for file in files:
df = pd.read_excel(file)
df_len = len(df)
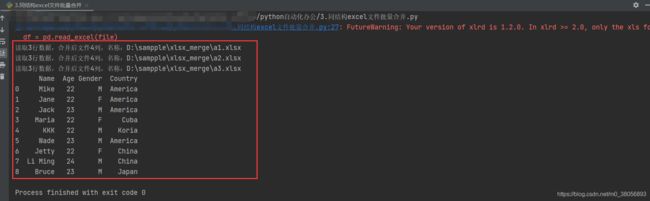
data = data.append(df)
print('读取%i行数据,合并后文件%i列,名称:%s' % (df_len, len(data.columns), file.split('/')[-1]))
# 重置索引
data.reset_index(drop=True, inplace=True)
# 查看数据
print(data)
(3)运行结果
4.批量读取word中表格信息
(1)原有的word中表格数据
word1:两个表格。第一个规范,第二个不规范。
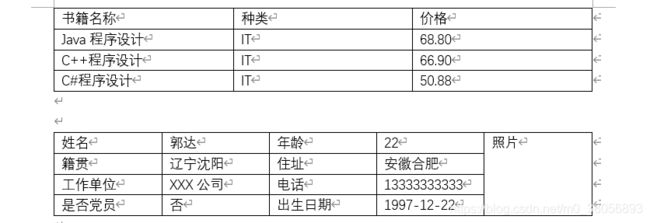
word2:仅一个表格。

(2)代码
# 4.批量读取word中表格数据.py
import docx # pip install python-docx
import os
import pandas as pd
def get_data1(biaoges):
"""
1.读取单个文件中规范的表格数据(第一个表格)
:param biaoges:
:return:
"""
# 读取第一个(规范)表格,可能有多行数据
rowi = len(biaoges[0].rows)
print(rowi)
# 定义空列表
list1 = []
for i in range(1, rowi): # 从第2行开始循环
list1.append([biaoges[0].cell(i, 0).text, biaoges[0].cell(i, 1).text, biaoges[0].cell(i, 2).text])
print(list1)
def get_data2(biaoges):
"""
2.读取单个文件中不规范的表格数据(第二个表格)
:param biaoges:
:return:
"""
cells = biaoges[1]._cells
cells_lis = [[cell.text for cell in cells]]
print(cells_lis)
"""
[['姓名', '郭达', '年龄', '22', '照片', '籍贯', '辽宁沈阳',
'住址', '安徽合肥', '照片', '工作单位', 'XXX公司', '电话', '13333333333',
'照片', '是否党员', '否', '出生日期', '1997-12-22', '照片']]
"""
datai = pd.DataFrame(cells_lis)
print('******************* datai完整 *******************')
print(datai)
print('******************* datai完整 *******************')
datai = datai[[1, 3, 6, 8, 11, 13, 16, 18]]
datai.columns = ['姓名', '年龄', '籍贯', '住址', '工作单位', '电话', '是否党员', '出生日期']
print('******************* datai过滤 *******************')
print(datai)
print('******************* datai过滤 *******************')
def get_data_batch():
# 1.3 批量读取数据
new_dir = "D:" + os.sep + "sampple" + os.sep + "word_data" + os.sep
os.chdir(new_dir)
list2 = []
for file in os.listdir('.'):
if file.endswith('.docx'):
doc = docx.Document('./' + file)
biaoges = doc.tables
rowi = len(biaoges[0].rows)
for i in range(1, rowi):
list2.append([biaoges[0].cell(i, 0).text, biaoges[0].cell(i, 1).text, biaoges[0].cell(i, 2).text])
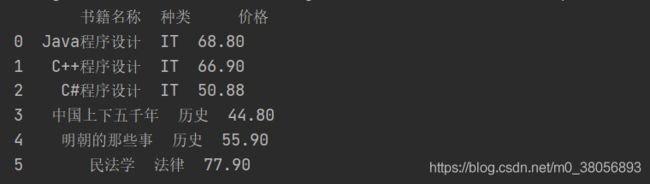
data1 = pd.DataFrame(list2, columns=['书籍名称', '种类', '价格'])
print(data1)
if __name__ == '__main__':
# 读取word文件
filepath = "D:" + os.sep + "sampple" + os.sep + "word_data" + os.sep + "data.docx"
doc = docx.Document(filepath)
# 获取文档中所有表格对象的列表
biaoges = doc.tables
print('类型:', type(biaoges)) # 类型:
print('biaoges: ', biaoges)
# biaoges: [, ]
# 处理规范的表格
get_data1(biaoges)
# 处理不规范的表格
get_data2(biaoges)
# 批量处理表格
get_data_batch()
(3)运行结果
-- 单文件表格数据读取
---- 规范表格

---- 不规范表格
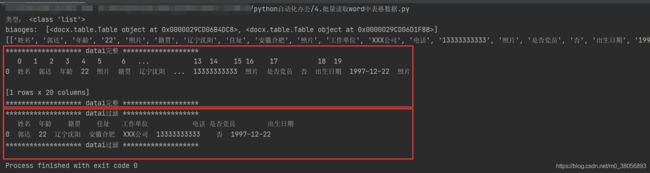
-- 多文件表格读取
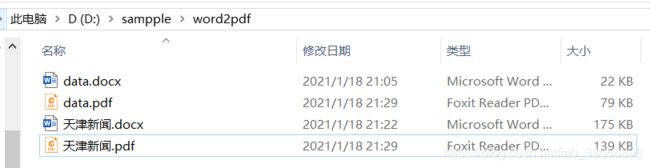
5.word文件批量转pdf
(1)原有的word内容
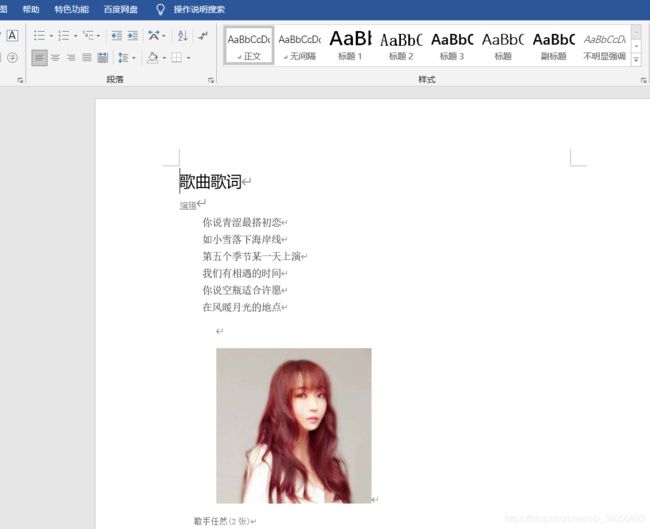
(2)代码
# 5.word文件批量转pdf.py
import docx2pdf # pip install docx2pdf --user
import os
def getAllFilesList(filepath):
"""
获取指定目录下的所有word文件列表
:param filepath: 指定目录
:return: 指定目录下的所有word文件列表
"""
files = []
for file in os.listdir(filepath):
if file.endswith(".docx"):
files.append(filepath + file)
return files
def convert_single(src_file, dst_file):
"""
单个文件实现 word->pdf 转换
:param src_file: 源文件 xxx.docx
:param dst_file: 目标文件 xxx.pdf
:return:
"""
docx2pdf.convert(src_file, dst_file)
def convert_batch(files_list):
"""
批量转换 word->pdf
:param files_list:
:return:
"""
for file in files_list:
docx2pdf.convert(file, file.split('.')[0] + '.pdf')
print(file + '转换成功!')
if __name__ == '__main__':
input_file = "D:" + os.sep + "sampple" + os.sep + "word2pdf" + os.sep + "data.docx"
output_file = "D:" + os.sep + "sampple" + os.sep + "word2pdf" + os.sep + "data.pdf"
filepath = "D:" + os.sep + "sampple" + os.sep + "word2pdf" + os.sep
# 1.单个文件转换
# convert_single(input_file, output_file)
# 2.批量转换
files = getAllFilesList(filepath)
convert_batch(files_list=files)
(3)运行结果
-- 单文件操作

生成data.pdf文件

pdf内容如下:

-- 多文件操作