一、概述
根据之前的凡技术必登其官网的原则,我们当然先得找到它的官网:http://hadoop.apache.org/
1.什么是hadoop
先看官网介绍:
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures
中文解释:
- HADOOP是apache旗下的一套开源软件平台——使用Java开发
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
W3C相关概述:https://www.w3cschool.cn/hadoop/hadoop-3rpe22xm.html
推荐阅读:《hadoop权威指南》
hadoop的定位:
- 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
2.而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身
关于上面提到的PaaS的的概念,参考网友的十分钟看懂云计算概念!
这里重点应该注意云计算的本质——社会分工!
1.5.HADOOP版本变迁史
2.0版本新增yarn模块!
混乱的hadoop版本变迁史:
https://www.cnblogs.com/meet/p/5435979.html
图解:http://blog.csdn.net/matthewei6/article/details/50499343
商业发行版本CDH:
http://blog.csdn.net/duyuanhai/article/details/54908298
2.hadoop核心组件
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
翻译过来就是:分布式文件系统、分布式资源管理、分布式运算程序开发框架
当然,这只是狭义的hadoop,而广义的hadoop则是hadoop生态圈:


HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
3.离线数据处理流程
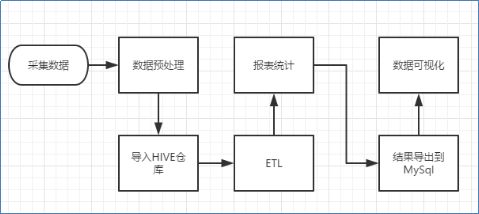
1)数据采集:定制开发采集程序,或使用开源框架FLUME
2)数据预处理:定制开发mapreduce程序运行于hadoop集群
3)数据仓库技术:基于hadoop之上的Hive
4)数据导出:基于hadoop的sqoop数据导入导出工具
5)数据可视化:定制开发web程序或使用kettle等产品
6)整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
大致架构如下:

二、hadoop集群安装
主要包含两个集群:HDFS集群、YARN集群,两者经常是逻辑上分离,物理上一起的。
角色分配:
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
相关的角色介绍,将会在HDFS详解/YARN详解篇等
更多角色介绍,参考:http://blog.csdn.net/gamer_gyt/article/details/51758881
1.环境准备
之前环境(如JDK等)的搭建,参考前面随笔。
虚拟机:VM搭建的3台虚拟机(安装一台,克隆2台)
网络:NAT搭建的网络(IP配置等请参考前文,这里配置为:192.168.137.128/138/148)
(以上在zookeeper环节已经搭建完成)

这里使用的是官方的hadoop的原始版本,还有个称之为hadoop商业版本的CDH:https://www.cloudera.com/,这里由于是初次学习,我们安装初始版本的hadoop(通过组件也可以实现类似CDH的功能),CDH将会在后续进行补充!
2.服务器系统设置
1.添加HADOOP用户
具体的用户管理,参考linux用户管理篇随笔:http://www.cnblogs.com/jiangbei/p/7902663.html
useradd hadoop
passwd hadoop
#设置密码为hadoop
2.为HADOOP用户分配sudo权限
visudo
#在98行左右添加
hadoop ALL=(ALL) ALL
// 打开连接,修改用户为hadoop,可以通过sudo hostname测试!
使用root用户,关闭防火墙!
3.下载hadoop
所有的aapche的软件都可以到archive的归档中心下载:http://archive.apache.org/dist/
当然,通过hadoop的官网找到下载也是OK的:http://hadoop.apache.org/releases.html
此处选择2.6.4的版本,下载hadoop-2.6.4.tar.gz即可!
4.安装hadoop
下载完成后选择一台机器,通过rz进行上传,请使用ftp!
解压:当然解压目录随个人意愿,你可以解压到例如自建目录/apps下进行统一管理
#在hadoop自己的家目录下进行目录创建,方便统一管理
mkdir apps
#再解压
tar -zxvf hadoop-2.6.4.tar.gz -C apps/
解压后目录及分析如下:
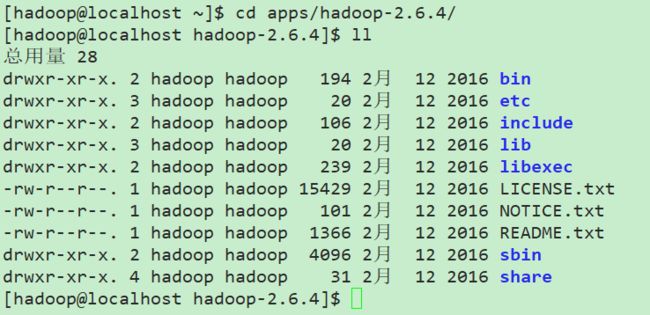
bin:Hadoop最基本的管理脚本和使用脚本所在目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop
etc:Hadoop配置文件所在目录,包括core-site.xml, hdfs-site.xml, mapred-site.xml等从hadoop1.0继承而来的配置文件和yarn-site.xml等hadoop 2.0新增的配置文件
include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用c++定义的,通常用于c++程序访问hdfs或者编写mapreduce程序
lib:该目录包含了Hadoop对外提供的的编程动态库和静态库,与include目录中的头文件结合使用。
libexec:各个服务对应的shell配置文件所在目录,可用于配置日志输出目录,启动参数(比如JVM参数)等基本信息。
sbin:Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本
share:Hadoop各个模块编译后的jar包所在目录
5.配置hadoop
进入hadoop的配置文件目录:
[hadoop@localhost hadoop-2.6.4]$ cd etc/hadoop/
[hadoop@localhost hadoop]$ ls
capacity-scheduler.xml kms-env.sh
configuration.xsl kms-log4j.properties
container-executor.cfg kms-site.xml
core-site.xml log4j.properties
hadoop-env.cmd mapred-env.cmd
hadoop-env.sh mapred-env.sh
hadoop-metrics2.properties mapred-queues.xml.template
hadoop-metrics.properties mapred-site.xml.template
hadoop-policy.xml slaves
hdfs-site.xml ssl-client.xml.example
httpfs-env.sh ssl-server.xml.example
httpfs-log4j.properties yarn-env.cmd
httpfs-signature.secret yarn-env.sh
httpfs-site.xml yarn-site.xml
kms-acls.xml
先配置hadoop-env.sh(hadoop环境)
找到JAVA_HOME路径:
[hadoop@localhost hadoop]$ echo $JAVA_HOME
/opt/java/jdk1.8.0_151
[hadoop@localhost hadoop]$ vim hadoop-env.sh
看到大概25行的JAVA_HOME的配置,由于之前有提到过,如果直接远程通过ssh的方式操作,由于是以一个bash的方式过去的,所以不会执行/etc/profile,也就导致了无法正确读取JAVA_HOME,我们直接改为获取到的JAVA_HOME的绝对路径即可!

接下来就是hadoop自己的配置,也就是图中的site配置文件:

配置core-site.xml
[hadoop@localhost hadoop]$ vim core-site.xml
这里我们可以先去hadoop官网的Documentation下找到这几个参考的默认配置信息:
//打开以后是可以通过经典的ctrl+F进行查找的
最简化的配置如下:(置于根标签下即可)
<property>
<name>fs.defaultFSname>
<value>hdfs://mini1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/hdpdatavalue>
property>
配置hdfs-site.xml
此项有很多默认配置,是可以不用配的,这里我们还是进行简单的配置演示:
[hadoop@localhost hadoop]$ vim hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>2value>
property>
配置mapred-site.xml.template(先更名)
[hadoop@localhost hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@localhost hadoop]$ vim mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
配置yarn-site.xml
[hadoop@localhost hadoop]$ vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mini1value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
以上是最简化配置,常见重要配置,参考:https://www.cnblogs.com/yinghun/p/6230436.html
6.分发配置到其他机器
通过远程拷贝文件命令:scp进行!
[hadoop@localhost hadoop]$ cd
[hadoop@localhost ~]$ scp -r apps/ mini2:/home/hadoop/
//另一个同理,当然,我们这里是应该进行主机名和ip地址映射的,这里参考基础系统设置篇!
7.配置HADOOP环境变量
[hadoop@localhost hadoop]$ sudo vim /etc/profile
加上最后两行:
export JAVA_HOME=/opt/java/jdk1.8.0_151
export PATH=$PATH:$JAVA_HOME/bin
export ZOOKEEPER_HOME=/opt/zookeeper/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
分发配置到其它服务器(后续将会配置hostname和hosts,这样就可以使用主机名了!,当然,更好的解决方式是自己编写一个自动化的脚本!)
sudo scp /etc/profile mini2:/etc/
sudo scp /etc/profile mini3:/etc/
再source一下就可以了!
source /etc/profile
8.格式化HDFS(namenode)
与我们熟悉的文件系统一样,HDFS也需要格式化一下才可以使用!
hadoop namenode -format
9,启动
进入hadoop的sbin目录:
[hadoop@localhost sbin]$ hadoop-daemon.sh start namenode
//验证方式是使用jps进行查看(注:jps为查看所有java程序)
当然,由于内置了jeety,可以通过网页访问:
http://mini1:50070
// 端口50070,IP可以换成主机名(需要关闭防火墙或者配置端口可以通过防火墙),yarn的端口为8088!
再在另外的机器上启动一个datanode
[hadoop@localhost ~]$ hadoop-daemon.sh start datanode
此时再次刷新网页就可以看到有变化了!(浏览器有缓存请刷新缓存!)
原理就是每台机器都配置了namenode,这样每次启动都能找到namenode正确握手!
10.一键启动脚本
之前已经有zk的一键启动脚本的经验了,这里直接借鉴即可!
这里不需要重新编写了,因为sbin目录下已经存在了start-dfs.sh等脚本了!我们只需要修改etc/hadoop下的slaves即可指定小弟了!
[hadoop@localhost hadoop]$ vim slaves
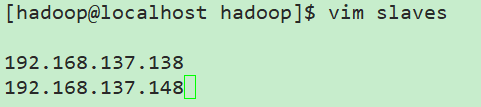
//可以改为主机名!
11.配置免密登录(hadoop用户下!)
这里我们配置128到138/148的
[hadoop@localhost hadoop]$ ssh-keygen
//按3次enter即可
[hadoop@localhost hadoop]$ ssh-copy-id mini1
[hadoop@localhost hadoop]$ ssh-copy-id mini2
[hadoop@localhost hadoop]$ ssh-copy-id mini3
//配置3台(包括自己!)
如果配置出现什么意外导致失败,可以直接删除各个用户家目录下的.ssh/目录,重新配置!
更多ssh-copy-id实现免密登录,参考:http://blog.csdn.net/alifrank/article/details/48241699
启动:
start-all已经过时了,请使用start-dfs.sh和start-yarn.sh进行启动!配置了path则无需路径!
sbin/start-dfs.sh
sbin/start-yarn.sh
三、问题小结
1.datanode无法启动:
在salve上无法通过jps看到datanode
http://www.linuxidc.com/Linux/2015-01/111891.htm
2.日志文件
注意查看日志输出(位于安装目录的logs文件夹下)
如果查看日志发现一些问题(例如datanode无法识别),可以删除工作目录(hdpdata目录),再重新运行hadoop-daemon.sh start datanode重试!
3.踩坑实录
之前的配置都成功,可是一直出现通过start-dfs.sh可以正常启动3个机器,jps也都能看到进程;可是进入namenode页面却发现live nodes中活着的节点为0,百思不得其解。各种百度寻解未果。后面在群里询问,慢慢去看重日志的输出,通过寻找日志的位置:
/home/hadoop/apps/hadoop-2.6.4/logs
通过日志的查看:
tail -100 hadoop-hadoop-datanode-mini3.log
看重点的because处,指出131解析失败:

可是我的静态IP分别是192.168.137.128/138/148,这里居然来个131,于是通过ip addr(centos7)查看:

发现mini2多了一个130,分别查看3台机器,发现多了3个静态IP,分别是129/130/131,看来是静态IP没配置好,选择不整IP的问题,通过hosts文件来,让它认识这3个多的动态IP,于是,修改3台机器的/etc/hosts如下:

这样,就顺利解析了!
所以说,遇到报错查看日志非常重要,比病急乱投医要高效的多!
//这里通过网友的方法还是没能解决动态IP的问题!点击查看
4.集群的时间同步
两种方案:http://blog.csdn.net/xuejingfu1/article/details/52274143
比较简单是使用date命令:sudo date -s 09:37:00
5.其他问题


2/初始化工作目录结构 hdfs namenode -format 只是初始化了namenode的工作目录 而datanode的工作目录是在datanode启动后自己初始化的 3/datanode不被namenode识别的问题 namenode在format初始化的时候会形成两个标识: blockPoolId: clusterId: 新的datanode加入时,会获取这两个标识作为自己工作目录中的标识 一旦namenode重新format后,namenode的身份标识已变,而datanode如果依然 持有原来的id,就不会被namenode识别
5/关于副本数量的问题 副本数由客户端的参数dfs.replication决定(优先级: conf.set > 自定义配置文件 > jar包中的hdfs-default.xml)