深度学习笔记(三)——归一化&残差网络
6.1 批量归一化和残差网络
- 浅层模型:处理后的任意一个特征在数据集中所有样本上的均值为0、标准差为1。
- 深层模型:利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
全连接层
位置:全连接层中的仿射变换和激活函数之间。
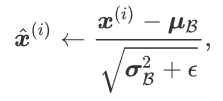
分母加上很小的数值以保证不为零,同时可以引入拉伸参数与偏移参数,可以使归一化效果不好的时候无效化。
卷积层
位置:卷积计算之后、应⽤激活函数之前。
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。 计算:对单通道,batchsize=m,卷积计算输出=pxq 对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差。
卷预测时的BN
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
nn.BatchNorm2d(通道数) #卷积层
nn.BatchNorm2d(输入的个数) #全连接层
残差网络(ResNet)
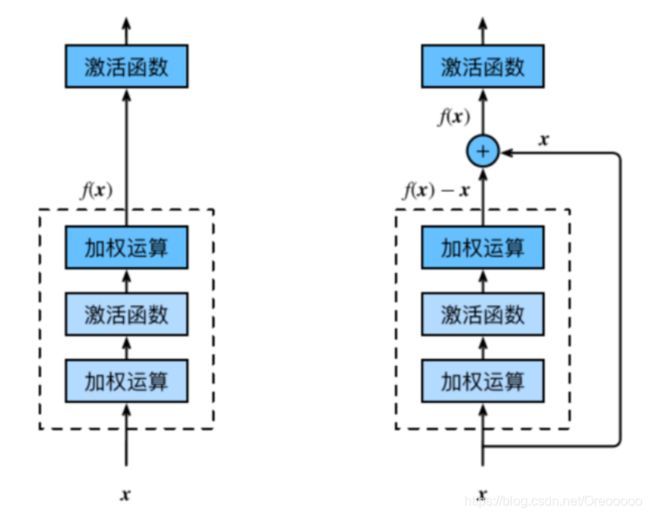 在残差块中,输⼊可通过跨层的数据线路更快地向前传播。
在残差块中,输⼊可通过跨层的数据线路更快地向前传播。
- 残差网络模型结构
卷积 (64,7x7,3)
批量一体化(BN)
最大池化 (3x3,2)
残差块x4 (通过步幅为2的残差块在每个模块之间减小高和宽)
全局平均池化
全连接
稠密连接网络(DenseNet)
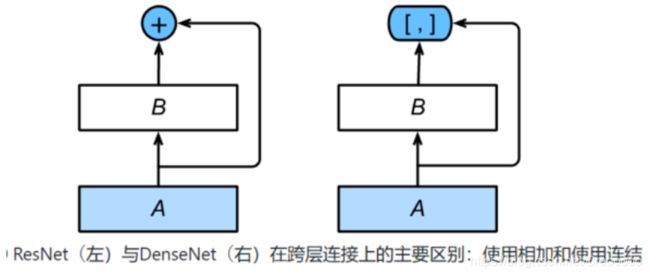
- 稠密块(dense block): 定义了输入和输出是如何连结(Concat)的。
- 过渡层(transition layer):用来控制通道数,使之不过大。
1x1的卷积(减少通道数)+stride = 2 的平均池化(减少高宽)
不断循环输出就是 输入(in)+n 输出(out)*
DenseNet 的输出通道数 = 输入通道数 + 卷积层个数 * 卷积输出通道数
9.1 目标检测基础
bounding box = [左上,右下]
将边界框(左上x, 左上y, 右下x, 右下y)格式转换成matplotlib格式: ((左上x, 左上y), 宽, 高)
- 锚框(anchor box):它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。
S1…Sn;r1…rm,只取第一个
所以共有wh(n+m-1) 个锚框
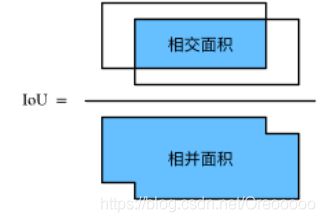
通过锚框中心像素的xy坐标、锚框大小和宽高比生成一组锚框 - 交并比(Intersection over Union,IoU):
- 标注训练集的锚框
我们需要为每个锚框标注两类标签:一是锚框所含目标的类别,简称类别;二是真实边界框相对锚框的偏移量,简称偏移量(offset)。
在目标检测时,我们首先生成多个锚框,然后为每个锚框预测类别以及偏移量,接着根据预测的偏移量调整锚框位置从而得到预测边界框,最后筛选需要输出的预测边界框。
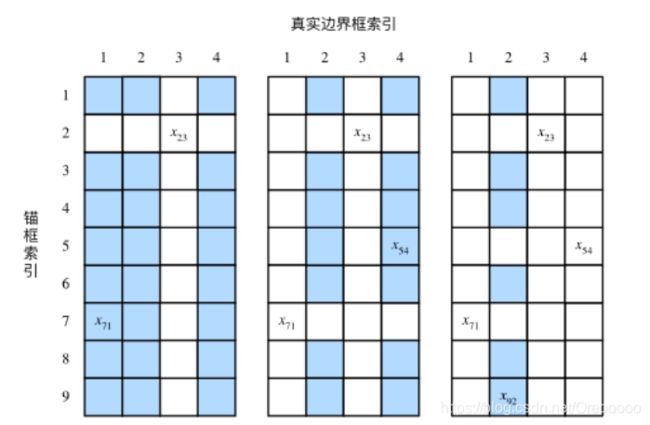 如果一个锚框A被分配了真实边界框B,将锚框A的类别设为B的类别,并根据B和A的中心坐标的相对位置以及两个框的相对大小为A锚框标注偏移量。
如果一个锚框A被分配了真实边界框B,将锚框A的类别设为B的类别,并根据B和A的中心坐标的相对位置以及两个框的相对大小为A锚框标注偏移量。
偏移量被标注为:
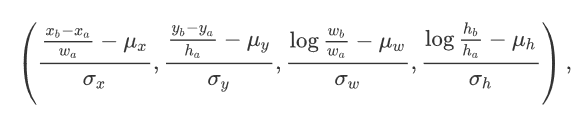
- 多尺度锚框预测
减少锚框个数并不难。一种简单的方法是在输入图像中均匀采样一小部分像素,并以采样的像素为中心生成锚框。此外,在不同尺度下,我们可以生成不同数量和不同大小的锚框。值得注意的是,较小目标比较大目标在图像上出现位置的可能性更多。
因此,当使用较小锚框来检测较小目标时,我们可以采样较多的区域;而当使用较大锚框来检测较大目标时,我们可以采样较少的区域。
- 极大值抑制(NMS)
- 将集合H中存放所有的框,M存放所有的最优框;
- H中进行排序,选择分数最高的m放入集合M中;
- 遍历H中剩余的框,当IoU大于Threshold的话就剔除;
- 反复循环,直到集合H为空。
9.2 图像风格迁移
样式迁移:将某图像中的样式应用在另一图像之上
- 初始化合成图像,该合成图像是样式迁移过程中唯一需要更新的变量;
- 抽取特征的CNN无需更新参数;
- 正向计算损失函数,反向传播迭代模型参数(即更新合成图像)
- 内容损失(content loss)
- 样式损失(style loss)
- 总变差损失(total variation loss):减少噪点
(使相邻的像素值相近)
课后题:
选取靠近输入的层抽取样式特征;
用VGG网络各个卷积块的第一层作为样式层;
内容图像和样式图像的额特征只需提取一次;
训练完成之后,合成图像就是最终的结果,不需要再经过网络卷积块的计算。
9.3 图像分类案例01
nn.mean(data) #求均值
nn.std(data) #求方差
图像增强
# 图像增强
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), #先四周填充0,再把图像随机裁剪成32*32
transforms.RandomHorizontalFlip(), #图像一半的概率翻转,一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.4731, 0.4822, 0.4465), (0.2212, 0.1994, 0.2010)), #R,G,B每层的归一化用到的均值和方差
])
ResNet-18网络结构
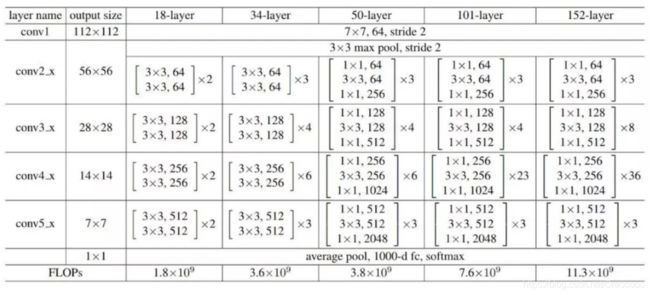
class ResidualBlock(nn.Module): # 我们定义网络时一般是继承的torch.nn.Module创建新的子类
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
#torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
# 添加第一个卷积层,调用了nn里面的Conv2d()
nn.BatchNorm2d(outchannel), # 进行数据的归一化处理
nn.ReLU(inplace=True), # 修正线性单元,是一种人工神经网络中常用的激活函数
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
# 便于之后的联合,要判断Y = self.left(X)的形状是否与X相同
def forward(self, x): # 将两个模块的特征进行结合,并使用ReLU激活函数得到最终的特征。
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential( # 用3个3x3的卷积核代替7x7的卷积核,减少模型参数
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) #第一个ResidualBlock的步幅由make_layer的函数参数stride指定
# ,后续的num_blocks-1个ResidualBlock步幅是1
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(ResidualBlock)
每训练一次都会打印 准确值 与 loss
损失函数使用的是交叉熵,多用于分类问题
- ImageFolder 对不可接受的文件类型会直接忽略掉而不是报错
- 从原训练数据集切分出验证数据集,并不可缓和过拟合,其作用在于调整超参数
10.1 图像分类案例02
torch.cuda.manual_seed(0) #设置随机数种子
测试集只有一个种类:unknow
图像增强
transform_train = transforms.Compose([
# 随机对图像裁剪出面积为原图像面积0.08~1倍、且高和宽之比在3/4~4/3的图像,再放缩为高和宽均为224像素的新图像
transforms.RandomResizedCrop(224, scale=(0.08, 1.0),
ratio=(3.0/4.0, 4.0/3.0)),
# 以0.5的概率随机水平翻转
transforms.RandomHorizontalFlip(),
# 随机更改亮度、对比度和饱和度
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
transforms.ToTensor(),
# 对各个通道做标准化,(0.485, 0.456, 0.406)和(0.229, 0.224, 0.225)是在ImageNet上计算得的各通道均值与方差
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # ImageNet上的均值和方差
])
# 在测试集上的图像增强只做确定性的操作
transform_test = transforms.Compose([
transforms.Resize(256),
# 将图像中央的高和宽均为224的正方形区域裁剪出来
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
- 训练
每个 lr_epoch 个 epoch ,lr 衰减一次
10.2 GAN(Generative Adversarial Networks)
mappings(映射) from data points to label
target:从数据集中训练出符合但不属于数据集(生成学习)
two-sample test: 输入Dataset 通过生成器采样的 & 真实图片,进而判断二者是否来自同一个数据集
使用交叉熵做loss
由于判断Generator
![]()
与
Discriminator
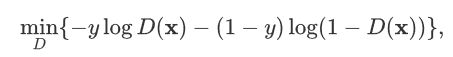 相互对抗,所以叫对抗生成
相互对抗,所以叫对抗生成
10.3 DCGAN(Deep Convolutional Generative Adversarial Networks)
leaky ReLU
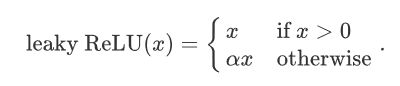
Y = [nn.LeakyReLU(alpha)(Tensor(x)).cpu().numpy()for alpha in alphas] #简洁实现