【编译原理】自上而下语法分析(C/C++源码+实验报告)
文章目录
-
- 1 实验目的和内容
-
- 1.1 实验目的
- 1.2 实验内容
- 1.3 实验要求
- 2 设计思想
-
- 2.1 根据BNF描述该文法
- 2.2 根据文法画相应的语法图
- 2.3 判断是否是LL(1)文法---求First、Follow集
- 2.4 递归下降子程序
- 3 算法流程
- 4 源程序
- 5 调试数据
- 6 思考:词法分析+语法分析
-
- 6.1 将实验一的词法分析作为函数写入语法分析程序
- 6.2 调试数据
- 6.3 调试结果
- 7 实验调试情况及体会
-
- 7.1 实验调试情况
- 7.2 实验体会
1 实验目的和内容
1.1 实验目的
(1)给出 PL/0 文法规范,要求编写 PL/0 语言的语法分析程序。
(2)通过设计、编制、调试一个典型的自上而下语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步 掌握常用的语法分析方法。
(3)选择最有代表性的语法分析方法,如递归下降分析法、预测分析法; 选择对各种常见程序语言都具备的语法结构,如赋值语句,特别是表达式,作为分析对象。
1.2 实验内容
(1)已给 PL/0 语言文法,构造表达式部分的语法分析器。
(2)分析对象〈算术表达式〉的 BNF 定义如下:
<表达式> ::= [+|-]<项>{<加法运算符> <项>}
<项> ::= <因子>{<乘法运算符> <因子>}
<因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’
<加法运算符> ::= +|-
<乘法运算符> ::= *|/
<关系运算符> ::= =|#|<|<=|>|>=
1.3 实验要求
(1)将实验一“词法分析”的输出结果,作为表达式语法分析器的输入,
进行语法解析,对于语法正确的表达式,报告“语法正确”;对于语
法错误的表达式,报告“语法错误”, 指出错误原因。
(2)把语法分析器设计成一个独立一遍的过程。
(3)采用递归下降分析法或者采用预测分析法实现语法分析。
2 设计思想
2.1 根据BNF描述该文法
(1)对BNF中的各对象简称如下
B:表达式 C:乘法运算符
J:加法运算符 N:无符号整数
X:项 S:标识符
Y:因子 G:关系运算符
(2)文法如下
B->JX(JX)|X(JX)
X->Y(CY)*
Y->S|N|(B)
J->+|-
C->*|/
G->=|#|<|<=|>|>=
2.2 根据文法画相应的语法图
(1)表达式
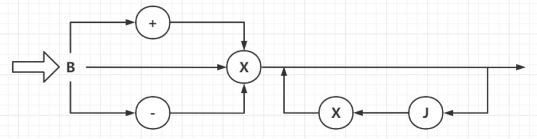
图1 表达式—语法图
(2)项
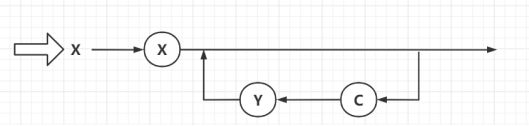
图2 项—语法图
(3)因子
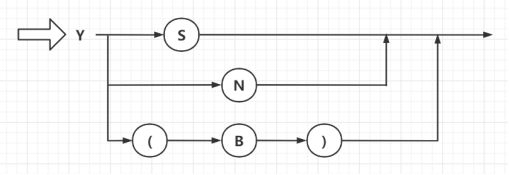
图3 因子—语法图
2.3 判断是否是LL(1)文法—求First、Follow集
(1)改文法没有左递归。
(2)各非终结符的First、Follow集如下所示

(3)根据LL(1)文法的判断规则可知,该文法满足LL(1)文法的条件,所以该文法是LL(1)文法。
2.4 递归下降子程序
(1)表达式
PROCEDUER B;
BEGIN
IF SYM = '+' OR SYM = '-' THEN ADVANCE;
ELSE IF SYM 在 First(X) THEN
BEGIN
ADVANCE;
X;
END
ELSE ERROR;
WHILE SYM = '+' OR SYM = '-' THEN
BEGIN
ADVANCE;
X;
END
END
(2)项
PROCEDUER X;
BEGIN
IF SYM 在 First(Y) THEN
BEGIN
ADVANCE;
Y;
END
ELSE ERROR;
WHILE SYM = '*' OR SYM = '/' THEN ADVANCE;
IF SYM 在 First(Y) THEN
BEGIN
ADVANCE;
Y;
END
ELSE ERROR;
END
(3)因子
PROCEDUER Y;
BEGIN
IF SYM = '(' THEN
BEGIN
ADVANCE;
B;
ADVANCE;
IF SYM = ')' THEN ADVANCE;
ELSE ERROR;
END
ELSE IF SYM 在 First(Y) THEN ADVANCE;
ELSE ERROR;
END
3 算法流程
语法分析程序的输入是一个个单词符号的二元组,输出是一个个语法单位,它的任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
首先逐行扫描单词符号二元组,然后遍历串的每一个字符,判断字符是不是+或-、*或/、因子的first集,再进行下一步的判断,选择进行表达式分析、项分析和因子分析,并输出相应的语句。如果不符合这几种情况,将会归入出错处理。完整算法流程如下图所示。
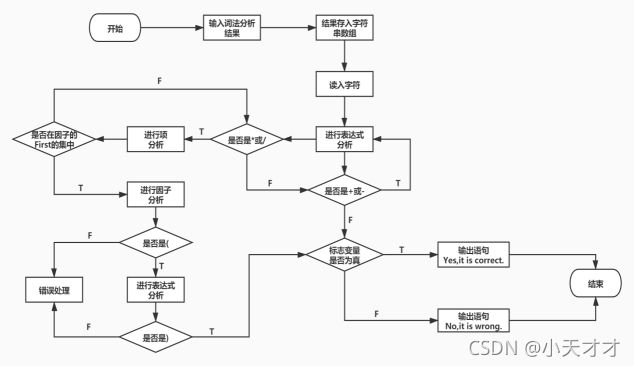
图4 算法流程图
4 源程序
#include5 调试数据
(1)测试样例如下
【样例输入】
(lparen,()
(ident,a)
(plus,+)
(number,15)
(rparen,))
(times,*)
(ident,b)
【样例输出】
Yes,it is correct.
(2)测试样例结果如下
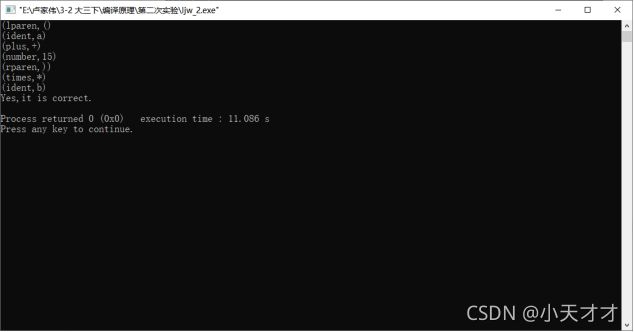
图5 样例测试结果
6 思考:词法分析+语法分析
6.1 将实验一的词法分析作为函数写入语法分析程序
int main()
{
string st1r;
//输入源程序
for(int i=0;i<L-1;i++)
{
cin>>str1;
//检测输入的结束
string str;
str = fun_cifa(str1);//调用词法分析子程序
int zero_id = str.find(',', 0);
//存储识别出来的字母到字符串数组中
input_str[i] = str.substr(1, zero_id - 1);
}
//对字符串数组中的表达式进行分析
if(input_str[str_i] == "plus" || input_str[str_i] == "minus")
{
//数组下标前移
str_i_adv();
}
//表达式分析
exp_aly();
while(input_str[str_i] == "plus" || input_str[str_i] == "minus")
{
//数组下标前移
str_i_adv();
//表达式分析
exp_aly();
}
if(str_i == L-1) cout<<"Yes,it is correct."<<endl;
else cout<<"No,it is wrong.";
return 0;
}
6.2 调试数据
【样例输入】
(a+15)*b
【样例输出】
(lparen,()
(ident,a)
(plus,+)
(number,15)
(rparen,))
(times,*)
(ident,b)
Yes,it is correct.
6.3 调试结果
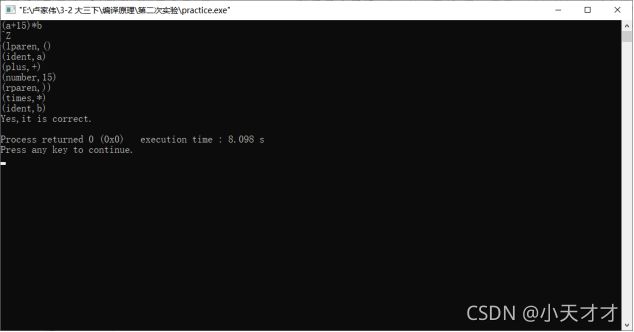
图6 样例测试结果
7 实验调试情况及体会
7.1 实验调试情况
由上两步中的测试样例可以得到,所有的测试样例均得到了相应的输出结果,说明代码编写成功,并且在代码中设置了出错处理,以便解决其他情况。
本次实验同时也实现了词法分析与语法分析合在一起去识别源程序的程序,但依然存在一些问题,比如语句只能一句一句地去识别,而不能进行整体识别,该问题会在后续过程中加以解决。
7.2 实验体会
这次实验采用的方法是自上而下分析中的递归下降分析法,首先画出了递归下降分析的语法图,然后判断文法是否属于LL(1)文法,最后写出了递归下降的子程序,并写出了代码,在代码中即可以调用上次词法分析的程序,直接对输入的字符串进行分割传入字符串str。
通过这次实验对于LL(1)文法的三个条件有了更深刻的认识,以及加深对于first 和follow 集合的求法,并且独立完成递归调用函数的书写和实现,对于递归思想又有了进一步的认识,要写函数结束出口,防止函数进入死循环。
通过这次实验进一步了解了自上而下的语法分析:对于输入的词法分析结果,进行左推导,得到一个合法句子或者非法结构,是一种递归和试探的方法,并且自上而下建立输入序列的分析树,而且需要消除左递归并且提取公因子,进一步理解了理论课所学的具体内容,加深对于一些自上而下课后题的理解。这次实验课的收获很大。
最后,感谢刘善梅老师和其他同学在这次实验中给予我的帮助,不胜感激!