PyTorch入门,帮你构建自己的神经网络模型
文章目录
-
- 基础教程
- 进阶教程
- 自动求导
- 神经网络的构建
- 图像分类器 ResNet实现
-
- 迁移学习
- 数据并行处理 使用 GPU
Pytorch 综合评价:
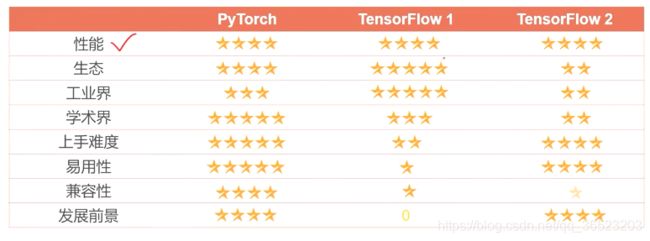
所以当前学pytorch 最合适,等待tensorflow 2的生态完善,
Tensorflow1和2完全不兼容
Pytorch 生态也比较完善
功能:GPU加速
自动求导: autugrad,grad函数
神经网络:全连接层nn.linear,卷积层nn.conv2d,循环层nn,LSTM
激活函数:nn.ReLU,nn.sigmoid
损失函数loss:nn.Softmax,nn.CrossEntropyLoss,nn.MSE
基础教程
- 基础数据类型 tensor
和python的numpy相对应 可以在gpu上运行torch 有类似于numpy的函数,处理数据.
| python | pytorch |
|---|---|
| Int | IntTensor of size() |
| float | FloatTensor of size() |
| Int array | IntTensor of size[d1,d2,…] |
| Float array | FloatTensor of size[d1,d2,d3…] |
| string | ? |
怎样表达string?
one-hot Embedding:1,word2vec 2,glove
数据初始化与类型查看

#cpu转Gpu
data=data.cuda()
标量
a=torch.tensor(1.)
a=tensor(1.)
#作用:计算loss 是标量
向量:张量
torch.tensor([1.1,2.2])
tensor([1.1,2.2])
#直接给尺寸,随机初始化
torch.FloatTensor(2)
#从numpy转换
data=np.ones(2)
torch.from_num(data)#numpy转tonsor
#作用 bias偏置。维度一般为1
#全连接层 输入 输出 [batch_size,feature_size]

dim=3

作用:RNN input [word_num,batch_size,feature]
dim=4
作用:图像 [batch_size,channels,h,w]
#元素数量
a.numel()
创建数据
#使用numpy导入
a=np.array([2,3.2])
torch_from_numpy(a)
#使用list
torch.tensor([2,3.2])
tensor([2,3.2])
#声明内存空间
Torch.empty()#里面传空间大小的参数
torch.Tensor(2,3)#两行三列
#设置默认数据类型
torch.set_default_tensor_type(torch.DoubleTensor)
#随机初始化
a=torch.rand(3,3)#[0,1]均匀分布
torch.rand_like(a)#参考a的shape
torch.randint()#取值[min,max)
#正态分布
torch.randn(3,3)#随机取值N(0,1)
#分布满足N(u,std)
torch.normal(men=torch.full([10],0),std=torch.arange(1,0,-0.1))
#赋值全部一样的数字
torch.full([2,3],7)#值全为7
#递增序列
torch.arange(0,10)
#生成等分
torch.linespace(0,10,steps=4)
torch.logspace(0,10,steps=11)
#全部是0 ,全部是1,对角全是1
torch.ones(3,3)
torch.zeros(3,3)
torch.eye(3,3)
#随机打散
torch.randperm(10)#使用索引的种子去shuffle
索引与切片
#索引
a=torch.rand(4,3,28,28)
a[0].shape#索引第一个位置 输出为torch.size([3,28,28])
a[0,0].shape#索引第一个位置的第二个位置 输出为 torch.size([28,28])
#切片的使用
a[:2].shape #输出为 torch.size([2,3,28,28])
a[:2,1:,:,:]#输出为 torch.size([2,1,28,28])
a[:,:,0:28:2,0:28:2].shape#select by step
#给具体的索引号 .index_select()
a.index_select(2,torch.arange(8)).shape#在第二个维度进行序索引 输出为 torch.Size([4,3,8,28])
#任意多的维度 ...
a[0,...].shape#输出为 torch.Size([3,28,28])
#select by mask
x=torch.randn(3,4)
mask=x.ge(0.5)
torch.masked_select(x,mask)#将x中大于0.5的元素取出 维度变成一维
Tensor维度变换
- View/reshape
a=torch.rand(4,1,28,28)
a.view(4,28*28)
a.view(4,28,28,1)#和reshape一致,torch0.4后收拾reshape
- Squeeze/unsqueeze
a=torch.rand(4,1,28,28)
a.unsqueeze(0).shape#输出为 torch.Size([1,4,1,28,28])在0索引前面插入
a.unsqueeze(-1).shape#在-1后面插入 输出为torch.Size([4,1,28,28,1])为像素上增加属性对象
#挤压,维度删减
a.squeeze().shape#输出 torch.Size([32])
a.squeeze(0).shape#输出 torch.Size([32,1,1])
- Transpose/t/permute(转置)
a=torch.randn(3,4)
a.t()#输出为(4,3)只适用于二维数据
#Transpose维度交换
a=torch.randn(3,4,32,32)
a=a.transpose(1,3)#维度1和维度3交换
a.permute(0,2,3,1).shape#输出为3 32 32 4
- Expand/repeat
#可以增加数据 Expand dim前后一致 仅限于原来的维度为1
a=torch.rand(1,32,1,1)
a.expand(4,32,14,14)
#repeat 输出是在维度上复制的次数
a=torch.rand(1,32,1,1)
a.repeat(4,32,1,1).shape#输出的维度为 torch.Size([4,1024,1,1])
进阶教程
- Broadcasting机制 维度扩展
#在小维素匹配,在最前面插入一个维度
#把原来维度为1的尺寸扩张为别人相同大小 size一致,即可进行叠加
# [32,1,1]=>[1,32,1,1]
为什么要brodcasting?
使得不同维度的数据进行相加,内存占用
当时 [4] 和[4,32,8]的情况是不可扩张的 2. 合并与分割
2. 合并与分割
a=torch.rand(4,32,8)
b=torch.rand(5,32,8)
torch.cat([a,b],dim=0).shape#指定在0维上进行合并,输出为torch.Size([9,32,8]) 在非cat的维度上必须保持一致
#stack 指定的维度要相同
torch.cat([a1,a2],dim=2).shape#输出为 torch.Size([4,3,32,32])
torch.stack([a1,a2],dim=2).shape#输出为 torch.Size([4,3,2,16,32])
#分割:split
c=torch.stack([a,b],dim=0).shape#输出为torch.Size([2,32,8])
aa,bb=c.split(1,dim=0)#按1平均拆分
aa.shape,bb.shape#输出为 (torch.Size([1,32,8]),torch.Size([1,32,8]))
aa,bb=c.split([1,1],dim=0)#将维度0上的元素拆分成1和1两个元素
- 数学运算
#加减乘除
a=torch.rand(3,4)
b=torch.rand(4)
a+b#根据broadcasting机制,输出的尺寸为[3,4]
torch.add(a,b)#减:sub,乘:mul 除:div
#比较
torch.all(torch.eq(a-b,torch.sub(a,b)))#输出为1,两个方法是一致的
#乘号 torch.mm 只适用二维
#推荐适用 Torch.matmul 和 @ a@b
a=torch.rand(4,784)
x=torch.rand(4,784)
w=torch.rand(512.784)
(x@w.t()).shape#输出为 torch.Size(4,512)
#二维以上的矩阵相乘 后面最低维度的乘积 拥有broadcast机制
a=torch.rand(4,3,28,32)
b=torch.rand(4,1,64,32)
torch.matmul(a,b).shape#输出为torch.Size(4,3,28,32)
#power 次方
a=torch.full([2,2],3)
a.pow(2)
aa=a**2
aa.rsqrt()
aa**(0.5)
#exp log
a=torch.exp(torch.ones(2,2))
torch.lag(a)#输出为[[1,1],[1,1]]
#取整 floor()向下,ceil()向上,trunc()裁剪整数,frac()裁剪小数
#四舍五入 round()
# clamp
grad=torch.rand(2,3)*15
grad.max()#取最大值
grad.median()#取中位数
grad.clamp(10)#小于10的取10
grad.clamp(0,10)#保留(0,10)的原值
- 属性统计
#norm 求范数
a=torch.full([8],1)
a.norm(1)#输出为tonsor(8)
a.norm(2)#输出为tensor(2.8)#求二范数
a.norm(2,dim=0)#在0维度求2范数
#mean sum
a.mean()
a.sum()
#prod 累乘
#max,min,argmin,argmax 索引,最大值最小值的位置 自动打平索引
#dim和keepdim在统计属性的作用
a#[4,10]
a.max(dim=1) #多张图,返回预测值和预测置信度 tensor(([0.8362,1.7015,1.1297,0.6386]),tensor([3,8,6,4]))
a.max(dim=1,keepdim=True)#输出为tensor(([[0.8362],[1.7015],[1.1297],[0.6386]]),tensor([[3],[8],[6],[4]]))
#kthvalue 第k大 ,topk#最大的k个值
a.topk(3,dim=1,largest=False)#默认最大
#compare
#>,< ,!= ,==
torch.eq(a,b)#位置上元素相等返回1,不相等返回0
torch.equal(a,b)#判断tensor是否完全相等
- 高阶操作
#where
torch.where(condition,x,y)#返回组成的新值
#例子
cond=tensor([[0.76,0.6],[0.8884,0.4]])
a=torch.zeros(2,2)
b=torch.ones(2,2)
torch.where(cond>0.5,a,b)#输出为tonsor([[0,0],[0,1]])
#gather
自动求导
梯度计算,训练神经网络,为优化提供帮助
import torch
from torch import autograd
#初始变量 ,值为x=1,a=1,b=2,c=3
x=torch.tensor(1.)
a=torch.tensor(1.,requires_grad=True)
b=torch.tensor(2.,requires_grad=True)
c=torch.tensor(3.,requires_grad=True)
y=a**2*x+b*x+c
print('before:'a.grad,b.grad,c.grad)
grads=autograd.grad(y,[a,b,c])
print('after:',grads[0],grads[1],grads[2])#输出y关于a,b,c的求导值
神经网络的构建
基本的网络结构:
自动求导: autugrad,grad函数
神经网络:全连接层nn.linear,卷积层nn.conv2d,循环层nn,LSTM
激活函数:nn.ReLU,nn.sigmoid
损失函数loss:nn.Softmax,nn.CrossEntropyLoss,nn.MSE
#完整的训练过程
import torch
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from lenet5 import Letnet5
from renet import ResNet18
def main():
batchsz=128
cifar_train=datasets.CIFR10('CIFAR',True,transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
#transfoms.RandomRotation,
transforms,Normalize(mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
]) ,download=True)
cifar_trian=DataLoader(cifar_train,batch_size=batchsz,shuffle=True)
cifar_test=datasets.CIFR10('CIFAR',False,transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
#transfoms.RandomRotation,
transforms,Normalize(mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
]) ,download=True)
cifar_test=DataLoader(cifar_test,batch_size=batchsz,shuffle=True)
x,label=iter(cifar_train).next()#加载进迭代器
print('x:',x.shape,'label:'label.shape )
device=torch.device('cuda')
model=ResNet18().to(device)
#损失函数也要在cuda上
criteon=nn.CrossEntropyLoss(),to(device )
#优化器
optimizer=optim.Adam(model.parameters(),lr=1e-3)
print(model)
#开始训练
for epoch in range(1000):#迭代次数
model.train()
for batchidx,(x,label) in enumerate(cifar_train):
x,label=x.to(device),label.to(device)
logits=model(x)
#输出 logits[b,10],10个类别
#label [b]
loss=criteon(logits,label)
#backdrop
optimizer.zero_grad()
loss.backward()
optimizier.step()
print(epoch,'loss:',loss.item())
#模型验证集
model.eval()
with torch.no_grad():
total_correct=0
total_num=0
for x,label in cifar_test:
#x[b,3,32,32] label [b]
x,label=x.to(device),label.to(device)
logits=model(x)
pred=logits.argmax(dim=1)#10->1
correct=torch.eq(pred,label).float().sum().item()
total_correct+=correct
total_num+=x.size(0)
acc=total_correct/total_num
print(epoch,'test acc:',acc)
图像分类器 ResNet实现
示例,搭建简单的网络层:
具有残差结构,特有的
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from lenet5 import Letnet5
from renet import ResNet18
class RestBlk(nn.Module):
def __init__(self,ch_in,ch_out,stride=1):
super(ResBlk,self).__init__()
self.conv1=nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=stride,padding=1)#参数代表意义
self.bn1=nn.BatchNorm2d(ch_out)
self.conv2=nn.Conv2d(ch_out,ch_out,kernel=3,stride=1,padding=1)
self.bn2=nn.BatchNorm2d(ch_out)
self.extra=nn.Sequential()
if ch_out!=ch_in:
self.extra=nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride)
nn.BatchNorm2d(ch_out)
)
def forward(self,x):
"""
"""
x_out=F.relu(self.bn1(self.conv1(x)))
x=self.bn2(self.conv2(x_out))
#short cut
# element-wise add
out= self.extra(x)+x_out
return out
class ReaNet18(nn.Module):
#4*4+2
def __init__(self):
super(ResNet18,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=3,padding=1),
nn.BatchNorm2d(64)
)
#nn.Conv2d的参数说明 in_channels:输入维度out_channels:输出维度
#kernel_size:卷积核大小stride:步长大小padding:补0
dilation:kernel间距
#follewed 4 blocks,残差网络
#[b,64,h,w]=>[b,128,h,w]
self.blk1=ResBlk(64,128,stride=2)#cahnnel增加,w,h减小
self.blk2=ResBlk(128,256,stride=2)
self.blk3=ResBlk(256,512,stride=2)
self.blk4=ResBlk(512,512,stride=2)
self.outlayer=nn.Liner(512,10)
def forward(self,x):
x=F.relu(self.conv1(1))
x=self.blk1(x)
x=self.blk2(x)
x=self.blk3(x)
x=self.blk4(x)
print('after conv:',x.shape)#[b,512,2,2]
#[b,512,h,w]=>[b,512,1,1]
x=F.adaptive_avg_pool2d(x,[1,1])
print('after pool:',x.shape)
x=x.view(x.size(0),-1)#[512]
x=self.outlayer(x)
return x
def main():
blk=ResBlk(64,128,stride=2)#stride可以减小维度
tmp=torch.rand(2,64,32,32)
out=blk(tmp)
print('block:',out.shape)
迁移学习
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from lenet5 import Letnet5
from renet import ResNet18
from torchvision.models import resnet18#导入公共的模型
from utils import Flatten
def main():
trained_model=resnet18(pretrained=True)#得到训练好的resnet18模型
#model=ResNet18(5).to(device)#没迁移时自己定义的网络
model=nn.Sequential(list(trained_model.children())[:-1],
#增加最后一层,输出该有的形式
Flatten(),
nn.Linear(512,5)#5个类别
)。to(device)
optimizer=optim.Adam(model.parameters(),lr=lr)
criteon=nn.CrossEntropyLoss()
best_acc,best_epoch=0,0
global_step=0
#可视化
viz.line([0],[-1],win='loss',opts=dict(title='loss'))
viz.line([0],[-1],win='val_acc',opts=dict(title='val_acc'))
for epoch in range():
for step,(x,y)in enumerate():
x,y=x.to(device),y.to(device)
logits=model(x)
loss=criteon(logits,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()],[global_step],win='loss',update='append')
global_step+=1
if epoch%1==0:
#计算验证集的正确率
val_acc=evalute(model,val_loader)
if val_acc>best_acc:
best_epoch=epoch
best_acc=val_acc
torch.save(model.state_dict(),'best.mdl')
viz.line([val_acc],[global_step],win='val_acc',update='append')
print('best_acc:',best_acc,'best_epoch':,best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt')
test_acc=evalute(model,test_loader)
print('test_acc:',test_acc)
if __name__=='__main__':
main()
数据并行处理 使用 GPU
import torch
import time
print(torch.cuda.is_available)
a=torch.randn(10000,1000)
b=torch.randn(1000,2000)
t0=time.time()
c=torch.matmul(a,b)
t1=time.time()
print(a.divice,t1-t0,c.norm(2))
#搬到GPU上进行计算
device=torch.device('cuda')
a=a.to(device)
b=b.to(device)
t0=time.time()
c=torch.matmul(a,b)
t2=time.time()
print(a.device,t2-t0,c.norm())
#第一次会有初始化的时间
t0=time.time()
c=torch.matmul(a,b)
t2=time.time()
print(a.device,t2-t0,c.norm())
x=torch.randn(2,3,32,32)#两张图像
model=ResNet18()
out=model(x)
print('resnet',out.shape)