分治法与递归---众数问题
分治法基本思想:
将一个规模为n的问题分解为k个规模较小的子问题,这些子问题相互独立(区别于动态规划)且与原问题相同。递归解决这些子问题,然后将各子问题的解合并(不存在相互利用)得到原问题的解。因此分治法通常和递归一起使用。
下面以求π的前200位众数为例,来理解一下吧!
问题描述:
1. 给定含有n个元素的多重集合S,每个元素在S中出现的次数称为该元素的重数。多重集S中重数最大的元素称为众数。例如,S={1,2,2,2,3,5},S的众数是2,重数是3。设计算法计算对于给定的由n个自然数组成的多重集S的众数及其重数。要求:从input.txt文件读取数据,并将结果保存在output.txt文件中。输入文件中,每行一个自然数,第一行为多重集的元素个数。
2. 求π的前200位中数字的众数及其重数:重点!!!分治法
【π=3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819】。可以将前两百位保存在数组,也可以放在文件中读取
tips:对数据文件的操作与文件流(该程序用到的一些简单的知识)
文件流:是以外存文件为输入输出对象的数据流,输出文件流是从内存流向外存文件的数据,输入文件流是从外存文件流向内存的数据。每一个文件流都有一个内存缓冲区与之对应。文件流本身不是文件,而只是以文件为输入输出对象的流,如果要对磁盘上的文件输入输出,即必须通过文件流来实现。
标准输入输出流:istream、ostream、iostream,此外用于文件操作的文件类如下:
1)ifstream类:从istream类派生的。用于支持硬盘文件的输入
2)ofstream类:从ostream类派生的。用于支持向磁盘文件的输出
3)fstream类:从iostream类派生。支持对磁盘文件的输入和输出
使用示例:
#include //标准输入输出流
#include //文件输入输出
cin>>a>>b;
cout<>a[i];//使用于cin类似
outfile.open("f.txt",ios::out);//写方式打开文件(写数据进文件)
outfile<<"ok";//与cout同理
file.open("f.txt",ios::binary);//二进制方式打开文件(读取数据)
//除了以上三种打开方式还有其他,这里不详细说明
//判断文件打开是否成功
if(!file.is_open()){
cout<<"error"< 1. 暴力求解代码(每个人最直接的想法):
//从文件读取,答案写入文件
#include
#include
#include
using namespace std;
void findModal(int *a,int n,int &MaxCount,int &index)
{
int i, j;
sort(a , a + n);//将数据从小到大排序
for(i = 0;i < n; i++){
int count =1;//计算不同数的重数
for (j = i + 1; j < n; j++){
if (a[i] == a[j])//两个数相等,则重数+1
count++;
}
if (MaxCount < count)//如果该数的重数大于最大的重数
{
MaxCount = count;//记为众数
index = i;//众数的下标
}
}
cout << a[index] <>a[i];;//从磁盘文件读入7个数,顺序存放在a数组中
}
findModal(a,7,MaxCount,index);
outfile< 

分治法求解
2. 快速排序也使用了分治法,这里对数组的排序使用c++中的sort(a,a+n,cmp)函数,默认为从小到大排序,也可以自定义cmp函数。
这里以a={1,2,2,3,3,5,6,6,6}为例说明该算法的执行过程:
首先,median函数找出中位数mid=a[5]=3,然后左边第一个跟3相等的为a[4]即l1=4右边没有与3相等的,则循环结束后r=l1+1=5,则3的个数有r-l1+1=2个,然后比较左边从0到第一个与中位数相等的数的个数如果比众数的重数大,则众数可能在左边,同理,最后一个与中位数相等的数到最后一个数之间的数的个数如果比众数重数大,则众数可能在右边,递归下去。有点类似于二分查找。
这里将π的前200位放在数组a中,用分治法找出其众数及其重数,具体代码如下:
//求π的前200位众数及其重数
#include
using namespace std;
int k= 0; //众数的重数
int modal = 0; //众数
int median(int* a, int& l, int& r) {//对排好序的数返回其中位数
return a[(l + r) / 2];
}
//l为数组第一个元素位置,r为数组最后一个元素的位置
void split(int* a, int mid, int& l, int& r, int& l1, int& r1) {//中位数处分成两段
for (l1 = 0;l <= r;l1++) {
if (a[l1] == mid)
break;
}//找到第一个和中位数相等的数
for (r1 = l1 + 1;r1 <= r;r1++) {
if (a[r1] != mid) {
r1--;
break;
}
}//找到最后一个和中位数相等的数
}
void mode(int* a, int l, int r){
int l1 = 0, r1 = 0;
int mid = median(a, l, r); //求中位数
split(a, mid, l, r, l1, r1);
//下面的l1为第一个与中位数相等的元素的位置,r1位最后一个与中位数相等的元素的位置
if (k < r1 - l1 + 1) {
k = r1 - l1 + 1;
modal = mid;
}//当前重数小于中位数的个数,则中位数的个数为新重数
if (l1 - l > k) {
mode(a, l, l1 - 1);
}//左边的元素个数大于当前重数的个数,则众数可能在左边
if (r - r1 > k) {
mode(a, r1 + 1, r);
}//右边的元素个数大于当前重数的个数,则众数可能在右边
}
int main()
{
int a[200]={3,1,4,1,5,9,2,6,5,3,5,8,9,7,9,3,2,3,8,4,6,2,6,4,3,3,8,3,2,7,9,5,0,2,8,8,4,1,9,
7,1,6,9,3,9,9,3,7,5,1,0,5,8,2,0,9,7,4,9,4,4,5,9,2,3,0,7,8,1,6,4,0,6,2,8,6,2,0,8,9,9,8,6,2,8,
0,3,4,8,2,5,3,4,2,1,1,7,0,6,7,9,8,2,1,4,8,0,8,6,5,1,3,2,8,2,3,0,6,6,4,7,0,9,3,8,4,4,6,0,9,5,5,
0,5,8,2,2,3,1,7,2,5,3,5,9,4,0,8,1,2,8,4,8,1,1,1,7,4,5,0,2,8,4,1,0,2,7,0,1,9,3,8,5,2,1,1,0,5,5,
5,9,6,4,4,6,2,2,9,4,8,9,5,4,9,3,0,3,8,1,9};
char m;
int n=200;
//Quick_Sort(a, 0, n);
sort(a,a+n);
mode(a, 0, n);
cout<<"众数为:"< 运行结果如下:
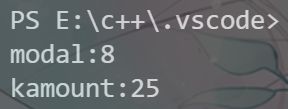
这个相比动态规划较好理解,注意区别分治法和动态规划算法的不同之处!