图解HTTP_笔记(1/3)
图解HTTP_学习笔记
- 第1章 了解Web及网络基础
-
- 1.1使用HTTP协议访问Web
- 1.2HTTP的诞生
- 1.3网络基础TCP/IP
- 1.4 与HTTP关系密切的协议:IP、TCP和DNS 010
- 1.5 负责域名解析的DNS服务
- 1.6 各种协议与HTTP协议的关系
- 1.7 URI和URL 016
-
- 1.7.1 统一资源标识符 URI
- 1.7.2 URI格式 017
- 第2章 简单的HTTP协议
-
- 2.1 HTTP协议用于客户端和服务器端之间的通信 022
- 2.2 通过请求和响应的交换达成通信 022
- 2.3 HTTP是不保存状态的协议 025
- 2.4 请求URI定位资源 026
- 2.5 告知服务器意图的HTTP方法 027
- 2.6 使用方法下达命令 033
- 2.7 持久连接节省通信量 034
- 2.8 使用Cookie的状态管理 037
- 第3章 HTTP报文内的HTTP信息
-
- 3.1 HTTP报文 042
- 3.2 请求报文及响应报文的结构 042
- 3.3 编码提升传输速率 044
- 3.4 发送多种数据的多部分对象集合 046
- 3.5 获取部分内容的范围请求 048
- 3.6 内容协商返回最合适的内容 050
- 第4章 返回结果的HTTP状态码 053
-
- 4.1 状态码告知从服务器端返回的请求结果 054
- 4.2 2XX成功 055
- 4.3 3XX重定向 056
- 4.4 4XX客户端错误 060
- 4.5 5XX服务器错误 062
- 第5章 与HTTP协作的Web服务器 065
-
- 5.1 用单台虚拟主机实现多个域名 066
- 5.2 通信数据转发程序:代理、网关、隧道 067
- 5.3 保存资源的缓存 071
- 第6章 HTTP首部 075
-
- 6.1 HTTP报文首部 076
- 6.2 HTTP首部字段 078
- 6.3 HTTP/1.1通用首部字段 083
- 6.4 请求首部字段 100
- 6.5 响应首部字段119
- 6.6 实体首部字段126
- 6.7 为Cookie服务的首部字段 132
- 第7章 确保Web安全的HTTPS 141
-
- 7.1 HTTP的缺点 142
- 7.2 HTTP+加密+认证+完整性保护=HTTPS 150
- 第8章 确认访问用户身份的认证 167
-
- 8.1 何为认证 168
- 8.2 BASIC认证 169
- 8.3 DIGEST认证171
- 8.4 SSL客户端认证173
- 8.5 基于表单认证 175
- 第9章 基于HTTP的功能追加协议 179
-
- 9.1 基于HTTP的协议180
- 9.2 消除HTTP瓶颈的SPDY 180
- 9.3 使用浏览器进行全双工通信的WebSocket 186
- 9.4 期盼已久的HTTP/2.0 189
- 9.5 Web服务器管理文件的WebDAV 190
- 第 10章 构建Web内容的技术 195
-
- 10.1 HTML 196
- 10.2 动态HTML 198
- 10.3 Web应用 200
- 10.4 数据发布的格式及语言 203
- 第4章 返回结果的HTTP状态码
- 第5章 与HTTP协作的Web服务器
- 第6章 HTTP首部
- 第7章 确保Web安全的HTTPS
- 第8章 确认访问用户身份的认证
- 第9章 基于HTTP 的功能追加协议
- 第10章 构建Web内容的技术
- 第11章 Web的攻击技术
《图解HTTP》 作者:上野 宣 翻译:于均良
原书书名:《HTTP的教科书》
相关图书:
《HTTP权威指南》
《TCP/IP详解,卷1》
这两本书的共同特点:全面,经典,晦涩,不适合初学者
#本书要点
- 包含基础知识和最新动向
- HTTP协议的发展历史
- 基于HTTP1.1标准讲解通信过程
- HTTP协议的结构
- HTTP通信过程中客户端与服务器之间的交互情况
- 图文并茂
第1章 了解Web及网络基础
1.1使用HTTP协议访问Web
Web使用一种名为HTTP(HyperText Transfer Protocol,超文本传输协议)的协议作为规范,完成从客户端到服务器端的一系列运作流程。而协议是规则的约定。可以说,Web是建立在HTTP协议上通信的 。
1.2HTTP的诞生
提出
- 1989.03HTTP诞生 CERN 欧洲核子研究组织的 Dr. Tim BernersLee 提出
- 为了让相隔两地的研究者们共享知识
- 通过多文档之间相互关联形成的超文本(HyperText),连成可以相互参阅的WWW(万维网)
当时已有技术
- HTML(超文本标记语言HyperText Markup Language),1.0版本的草案在1990年第一次进行讨论
- HTTP
- URL(Uniform Resource Locator,统一资源定位符)
浏览器的发展
- 1990.11 CERN成功研发了世界上第一台Web服务器 和Web浏览器
- 1994.12网景公司发布:Netscape Navigator 1.0
- 1995 微软公司发布 Internet Explorer 1.0 和 2.0
- 然后是1996年4月开始的 Apache
- 1995-2000,网景和微软浏览器大战,无视html标准
- 2004,Mozilla发布了Firefox浏览器,第二次浏览器大战随即爆发
- 后来Chrome(08年)、Opera、safari等浏览器开始出现,直到现在
HTTP的发展
- HTTP0.9: 1990年并没有正式标准,故称为0.9(1.0之前)
- HTTP1.0:1990.05 ,并记载于 RFC 1945
- HTTP1.1: 1997.01,目前主流的HTTP协议(2020.05),RFC2616
- HTTP2.0: (待了解)
现在的HTTP已经超出了Web这个框架的局限,被运用到了各种场景里
1.3网络基础TCP/IP
通常使用的网络(包括互联网)都是在TCP/IP协议族的基础上运作的;HTTP属于它内部的一个子集
协议:protocol:通信设备之间事先确定的一些规则
例如:谁先发起,如何探测,使用哪种语言,怎样结束,使用哪种电缆,IP地址怎么选,web页面需要处理的步骤
TCP/IP:是互联网各类协议的总称
分层管理
- 包括:应用层、传输层、网络层、数据链路层
- 好处:分层后,改变设计后只需要替代变动的层;规划好各层之间的接口部分,每个层次内部的设计就能自由改动了
-
应用层:
-
决定了向用户提供应用服务时通信的活动
例如:
FTP(File Transfer Protocol,文件传输协议)
DNS(Domain Name System,域名系统)
HTTP协议 传输层
-
传输层对上层应用层,提供两台计算机之间的数据传输。
例如:
TCP(Transmission Control Protocol,传输控制协议)
UDP(User Data Protocol,用户数据报协议) 网络层
- 用来处理在网络上流动的数据包,规定了通过怎样的路径到达对方的计算机 链路层(又名网络接口层)
- 用来处理连接网络的 硬件部分。包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,网络适配器,即网卡),及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
通信传输流

发送端在层与层之间传输数据时,每经过一层时必定会被打上一个该层所
属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对
应的首部消去。
封装encapsulate:把数据信息包装起来的做法
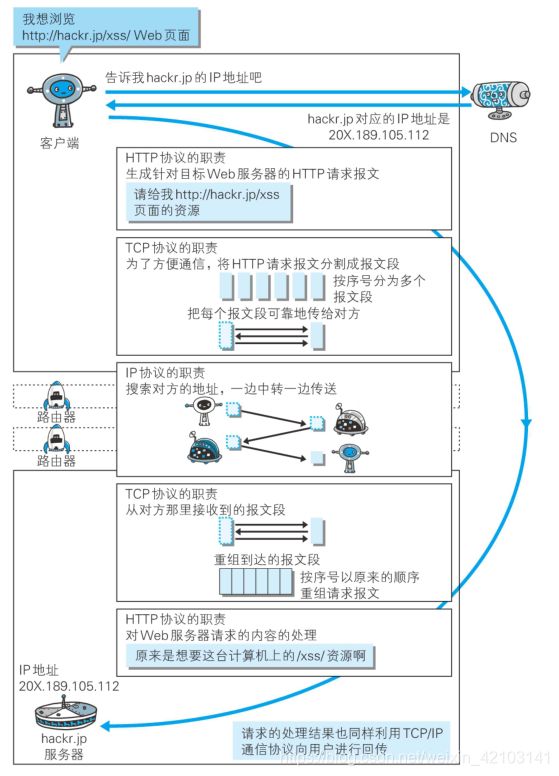
1.4 与HTTP关系密切的协议:IP、TCP和DNS 010
负责传输的IP协议
IP (Internet Protocol)网际协议位于网络层。所有使用网络的系统都会用到 IP 协议。可能有人会把“IP”和“IP 地址”搞混,“IP”其实是一种协议的名称。
IP协议的作用是把各种数据包传送给对方。为保证确实可以传送到对方那里,则需要满足各类条件。其中两个重要的条件是IP地址和MAC地址(Media Access Control Address)
IP地址指明了节点被分配的地址,MAC地址是指网卡所属的固定地址。IP地址可以和MAC地址进行配对。IP地址可以变换,但是MAC地址基本不会改变。
IP之间的通信一般要依赖MAC地址,因为处于同一个局域网(LAN)内的情况是很少的。
通常是经过多台计算机和网络设备中转才能连接到对方。在进行中转时,会利用下一站中转设备的MAC地址来搜索下一个中转目标。
这个过程会采用ARP协议(Address Resolution Protocol)。ARP是一种用以解析地址的协议,根据通信方的IP地址就可以反查出对应的MAC地址
在到达通信目标前的中转过程中,那些计算机和路由器等网络设备只能获
悉很粗略的传输路线。
这种机制就像快递运送中的集散中心一样,等到了集散中心,才判断是否能够送到收件方的手里。
无论哪台计算机,或网络设备,都无法全面掌握互联网中的细节。
确保可靠性的TCP协议
按层次分,TCP协议属于传输层协议;提供可靠的字节流(Byte Stream Service)服务。
字节流服务 Byte Stream Service
为了传输方便,将大段数据分割成报文段(segment)为单位的数据包进行管理。而可靠的传输服务是指,能够把数据准确可靠地传给对方。同时,TCP协议能够确认数据最终是否送达到对方。
为了确保数据能送达目标,TCP协议采用了三次握手(three-way handshaking)策略。握手过程使用了TCP的标志(flag)——SYN(synchronize)和ACK(acknowledgement)
当然TCP协议还有其他手段保证通信可靠性
首先,发送一个带SYN标志的数据包给对方;接收端收到后,回复一个带有SYN/ACK标志的数据包以示传达确认信息。最后发送端再回传一个带ACK标志的数据包,代表握手结束;
如果中间莫名中断,TCP协议会再次以相同的顺序发送相同的数据包
DNS协议(见下节)
1.5 负责域名解析的DNS服务
DNS(Domain Name System),位于应用层。提供域名到IP地址之间的解析服务。
计算机既可以被赋予主机名和域名。比如www.hackr.jp,也可以被赋予IP地址。
为了让计算机理解字母组成的域名,并且对应IP地址,DNS服务应运而生。
DNS服务可以通过域名查找IP地址,或者从IP地址反查域名的服务
如何查?
1.6 各种协议与HTTP协议的关系
1.7 URI和URL 016
与 URI(统一资源标识符)相比,我们更熟悉 URL(Uniform Resource
Locator,统一资源定位符)。
1.7.1 统一资源标识符 URI
URI 是 Uniform Resource Identifier 的缩写,就是由某个协议方案表示的资源的定位标识符。协议方案是指访问资源所使用的协议类型名称。
采用 HTTP 协议时,协议方案就是 http。除此之外,还有 ftp、mailto、
telnet、file 等。标准的 URI 协议方案有 30 种左右,由隶属于国际互联网
资源管理的非营利社团 ICANN(Internet Corporation for Assigned Names
and Numbers,互联网名称与数字地址分配机构)的 IANA(Internet
Assigned Numbers Authority,互联网号码分配局)管理颁布。
URI用字符串标识某一互联网资源,而URL表示资源的地点,可见 URL 是 URI 的子集。
1.7.2 URI格式 017

服务器端口号,若省略则为默认端口。
服务器地址可以是DNS可解析的名称,也可以是192.168.1.1这类IPV4地址名,还可以是[0:0:0:0:0:0:0:1]这类IPv6地址名。
第2章 简单的HTTP协议
2.1 HTTP协议用于客户端和服务器端之间的通信 022
实际情况中,两台计算机的角色可能发生互换,但在一条通信线路上,必有一端为客户端,另外一端为服务器端;
2.2 通过请求和响应的交换达成通信 022
客户端发送请求报文,服务器端收到请求,做出响应(发出响应报文)
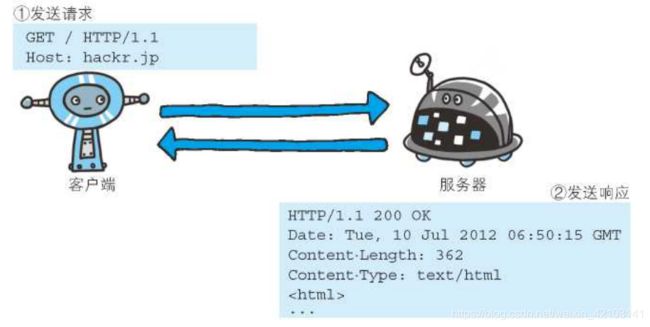
请求报文:
GET:表示访问服务器的类型,称为方法(method)
/index.htm 指明了请求访问的资源对象,也叫请求URI
HTTP/1.1,即HTTP的版本号,用来提示客户端使用的HTTP协议功能
总结:一般来说,请求报文,包括请求URI、协议版本、可用请求首部字段和内容实体构成。

响应报文:
HTTP/1.1表示服务器响应的HTTP版本;200OK表示请求的处理结果的状态码(status code)和原因术语(reason-phrase)

2.3 HTTP是不保存状态的协议 025
不保存状态:请求和响应结束后,不会保存,如有下次,需要重新发起请求和响应。
带来的问题:登录网站后,跳转到一个子网站,仍然需要登录。
解决:引入了cookie技术,再用HTTP协议,就可以管理状态了
2.4 请求URI定位资源 026
HTTP协议使用URI可以定位互联网上的任意资源。任意位置的资源都能访问到。
请求时需要把URI包含在请求报文中,具体形式有以下几种
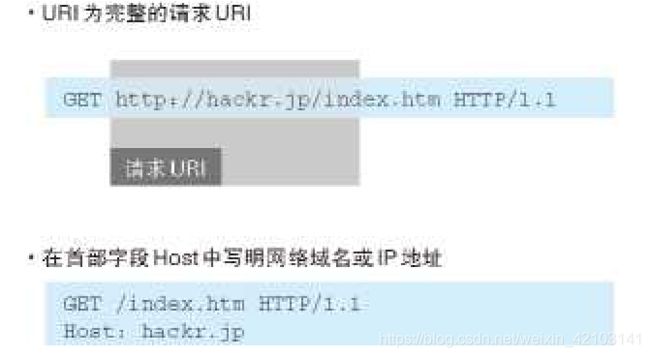
除此之外,如果是访问服务器本身,可以用一个* 来代替URI。
OPTIONS * HTTP/1.1
2.5 告知服务器意图的HTTP方法 027
HTTP1.1中可以使用的方法
GET:获取资源
POST:传输实体主体,主要目的不是获取响应的主体内容。
PUT:传输文件,要求在请求报文的主体中包含文件内容,然后保存到请求 URI 指定的位置。但是由于put方法不带验证机制,存在安全风险,故一般的web网站不使用该方法。
HEAD:获得报文首部,同GET方法一样,只是不返回报文主体部分。用于确认URI的有效性及资源更新的日期时间等。
DELETE:删除文件,与PUT方法相反,为请求URI删除指定的资源。
OPTIONS:询问支持的方法,用来查询针对请求URI指定的资源支持的方法。
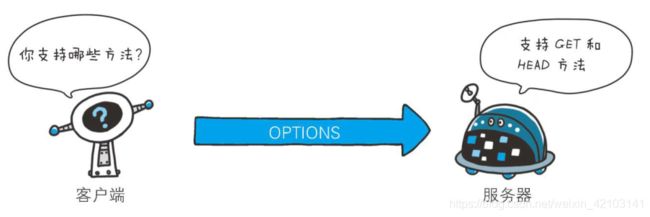
TRACE:追踪路径,客户端利用这个方法可以查询发送出去的请求是怎样被加工修改/篡改的。不常用,具体请查原书。
CONNECT:要求用隧道协议连接代理,要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL(Secure Sockets Layer,安全套接层)和TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
CONNECT 代理服务器名:端口号 HTTP版本
2.6 使用方法下达命令 033
同上一节,
LINK和UNLINK方法已经被HTTP1.1废弃,不再支持
2.7 持久连接节省通信量 034
HTTP协议初始版本(应该是0.9),每进行一次HTTP通信就要断开一次TCP连接。这个设计随着图片HTML网页的增多,问题越来越大。因为每一个图片都会进行一次通信。
为了解决这个问题,在HTTP1.0/1.1中,设计了持久连接的方法(HTTP Persistent Connections, 也 称 为 HTTP keep- alive 或
HTTP connection reuse)旨在解决,一次TCP连接后进行多次请求和响应的交互
即,只要任意一端没有明确提出断开连接,则一直保持TCP连接状态
这样只要连接,就能一次性发送请求的资源了
HTTP1.1中所有连接默认都是持久连接
管线化(pipelining)
持久连接使得多数请求以管线化(pipelining)方式发送成为可能。可以同时并行发送多个请求。
这种方式基于持久连接而且比持久连接还要快,请求数越多,时间差越明显
2.8 使用Cookie的状态管理 037
HTTP协议是无状态协议,好处就是减少服务器CPU及内存资源的消耗。
但是会存在登录信息需要每次请求都重新提交。
为了解决这个问题,引入了cookie技术
Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端的状态。
Cookie会根据从服务器端发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie.当下次再往该服务器发送请求时,客户端会在请求报文中,自动加入Cookie值后发送出去。
第3章 HTTP报文内的HTTP信息
请求和响应是如何运作的?
3.1 HTTP报文 042
用于HTTP协议交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,相应地,响应报文。
报文本身是多行数据构成的字符串文本。换行符(CR+LF)
HTTP报文大致可分为报文首部和报文主体两块。两者由最初出现的空行(CR+LF)来划分。通常并不一定要有报文主体。
3.2 请求报文及响应报文的结构 042
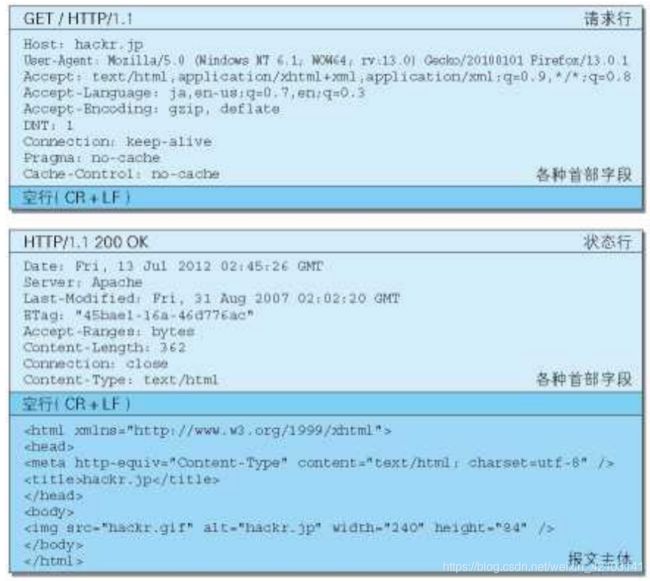
请求行:
包含请求的方法,请求URI和HTTP版本
状态行:
包含表明响应结果的状态码,原因短语和HTTP版本
首部字段:
包含表示请求和响应的各种条件和属性的各类首部
一般四种,通用首部,请求首部,响应首部和实体首部
其他
可能包含HTTP的RFC中未定义的首部(Cookie等)
3.3 编码提升传输速率 044
HTTP在传输数据时,可以直接按原貌传输,但也可以在传输过程中通过编码提升传输速率。但是编码需要计算机完成,消耗更多的CPU资源。
3.3.1 报文主体和实体主体的差异 044
补充:HTTP报文的主体用于传输请求或响应的实体主体;通常报文主体等于实体主体,只有当传输中进行编码时,实体主体的内容发生变化,才导致它和报文主体产生差异
需要认真理解两者的差异
3.3.2 压缩传输的内容编码 044
对实体信息原样压缩,内容编码后的实体由客户端接收并负责解码。
常见内容编码有:
gzip(GNU zip)
compress(UNIX系统的标准压缩)
deflate(zlib)
identity(不进行编码)
3.3.3 分割发送的分块传输编码 045
请求的实体资源如果未全部传输完成之前,浏览器无法显示请求页面。在传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。
这种方法:分块传输编码(Chunked Transfer Coding)
3.4 发送多种数据的多部分对象集合 046
HTTP协议中采用了多部分对象集合,发送的一份报文主体内可含有多类型实体。通常是在图片或文本文件等上传时使用。
多部分对象集合包含的对象类型如下。
- multipart/form-data
- multipart/byteranges
- multipart/form-data
HTTP报文中使用多部分对象集合时,需要在首部字段里加上Content-type。有关这个首部字段,见第6章
3.5 获取部分内容的范围请求 048
可以实现从之前下载中断处恢复下载。
要实现该功能能够,需要指定下载的实体范围。像这样,指定范围发送的请求叫做范围请求(RangeRequest)
执行时,会用到首部字段Range来指定资源的byte范围。
针对范围请求,响应会返回状态码为 206 Partial Content 的响应报文。另
外,对于多重范围的范围请求,响应会在首部字段 Content-Type 标明
multipart/byteranges 后返回响应报文。
如果服务器端无法响应范围请求,则会返回状态码 200 OK 和完整的实体
内容。
3.6 内容协商返回最合适的内容 050
比如,根据浏览器的默认语言返回该语言版本的网页。这样的机制称为内容协商(Content Negotiation)
包含在请求报文中的某些首部字段,就是判断的基准,例如
- Accept
- Accept-Charset
- Accept-Encoding
- Accept-Language
- Content-Language
内容协商有三种类型:
- 服务器驱动协商(Server-driven Negotiation)
- 客户端驱动协商(Agent-driven Negotiation)
- 透明协商(Transparent Negotiation)
第4章 返回结果的HTTP状态码 053
4.1 状态码告知从服务器端返回的请求结果 054
4.2 2XX成功 055
4.2.1 200 OK 055
4.2.2 204 No Content 056
4.2.3 206 Partial Content 056
4.3 3XX重定向 056
4.3.1 301 Moved Permanently 057
4.3.2 302 Found 057
4.3.3 303 See Other 058
4.3.4 304 Not Modified 059
4.3.5 307 Temporary Redirect 059
4.4 4XX客户端错误 060
4.4.1 400 Bad Request 060
4.4.2 401 Unauthorized 060
4.4.3 403 Forbidden 061
4.4.4 404 Not Found 061
4.5 5XX服务器错误 062
4.5.1 500 Internal Server Error 062
4.5.2 503 Service Unavailable 062
第5章 与HTTP协作的Web服务器 065
5.1 用单台虚拟主机实现多个域名 066
5.2 通信数据转发程序:代理、网关、隧道 067
5.2.1 代理 068
5.2.2 网关 070
5.2.3 隧道 070
5.3 保存资源的缓存 071
5.3.1 缓存的有效期限 072
5.3.2 客户端的缓存 072
第6章 HTTP首部 075
6.1 HTTP报文首部 076
6.2 HTTP首部字段 078
6.2.1 HTTP首部字段传递重要信息 078
6.2.2 HTTP首部字段结构 078
6.2.3 4种HTTP首部字段类型 079
6.2.4 HTTP/1.1首部字段一览 080
6.2.5 非HTTP/1.1首部字段 082
6.2.6 End-to-end首部和Hop-by-hop首部 083
6.3 HTTP/1.1通用首部字段 083
6.3.1 Cache-Control 084
6.3.2 Connection 091
6.3.3 Date 093
6.3.4 Pragma 094
6.3.5 Trailer 095
6.3.6 Transfer-Encoding 096
6.3.7 Upgrade 097
6.3.8 Via 098
6.3.9 Warning 099
6.4 请求首部字段 100
6.4.1 Accept 101
6.4.2 Accept-Charset 102
6.4.3 Accept-Encoding 103
6.4.4 Accept-Language 104
6.4.5 Authorization 105
6.4.6 Expect 106
6.4.7 From 107
6.4.8 Host 107
6.4.9 If-Match 108
6.4.10 If-Modified-Since 110
6.4.11 If-None-Match 111
6.4.12 If-Range 112
6.4.13 If-Unmodified-Since 113
6.4.14 Max-Forwards 114
6.4.15 Proxy-Authorization 115
6.4.16 Range 116
6.4.17 Referer 116
6.4.18 TE 117
6.4.19 User-Agent 118
6.5 响应首部字段119
6.5.1 Accept-Ranges 119
6.5.2 Age 120
6.5.3 ETag 120
6.5.4 Location 122
6.5.5 Proxy-Authenticate 123
6.5.6 Retry-After 123
6.5.7 Server 124
6.5.8 Vary 125
6.5.9 WWW-Authenticate 125
6.6 实体首部字段126
6.6.1 Allow 126
6.6.2 Content-Encoding 127
6.6.3 Content-Language 128
6.6.4 Content-Length 128
6.6.5 Content-Location 129
6.6.6 Content-MD5 129
6.6.7 Content-Range 130
6.6.8 Content-Type 131
6.6.9 Expires 131
6.6.10 Last-Modified 132
6.7 为Cookie服务的首部字段 132
6.7.1 Set-Cookie 134
6.7.2 Cookie 136
6.8 其他首部字段137
6.8.1 X-Frame-Options 137
6.8.2 X-XSS-Protection 138
6.8.3 DNT 138
6.8.4 P3P 139
第7章 确保Web安全的HTTPS 141
7.1 HTTP的缺点 142
7.1.1 通信使用明文可能会被窃听 142
7.1.2 不验证通信方的身份就可能遭遇伪装 146
7.1.3 无法证明报文完整性,可能已遭篡改 148
7.2 HTTP+加密+认证+完整性保护=HTTPS 150
7.2.1 HTTP加上加密处理和认证以及完整性保护后即是HTTPS 150
7.2.2 HTTPS是身披SSL外壳的HTTP 151
7.2.3 相互交换密钥的公开密钥加密技术 152
7.2.4 证明公开密钥正确性的证书 155
7.2.5 HTTPS的安全通信机制 161
第8章 确认访问用户身份的认证 167
8.1 何为认证 168
8.2 BASIC认证 169
8.3 DIGEST认证171
8.4 SSL客户端认证173
8.4.1 SSL客户端认证的认证步骤 174
8.4.2 SSL客户端认证采用双因素认证 175
8.4.3 SSL客户端认证必要的费用 175
8.5 基于表单认证 175
8.5.1 认证多半为基于表单认证 176
8.5.2 Session管理及Cookie应用 177
第9章 基于HTTP的功能追加协议 179
9.1 基于HTTP的协议180
9.2 消除HTTP瓶颈的SPDY 180
9.2.1 HTTP的瓶颈 180
9.2.2 SPDY的设计与功能 184
9.2.3 SPDY消除Web瓶颈了吗 185
9.3 使用浏览器进行全双工通信的WebSocket 186
9.3.1 WebSocket的设计与功能 186
9.3.2 WebSocket协议 186
9.4 期盼已久的HTTP/2.0 189
9.5 Web服务器管理文件的WebDAV 190
9.5.1 扩展HTTP/1.1的WebDAV 191
9.5.2 WebDAV内新增的方法及状态码 192
第 10章 构建Web内容的技术 195
10.1 HTML 196
10.1.1 Web页面几乎全由HTML构建 196
10.1.2 HTML的版本 197
10.1.3 设计应用CSS 198
10.2 动态HTML 198
10.2.1 让Web页面动起来的动态HTML 198
10.2.2 更易控制HTML的DOM 198
10.3 Web应用 200
10.3.1 通过Web提供功能的Web应用 200
10.3.2 与Web服务器及程序协作的CGI 200
10.3.3 因Java而普及的Servlet 201
10.4 数据发布的格式及语言 203
10.4.1 可扩展标记语言 203
10.4.2 发布更新信息的RSS/Atom 204
10.4.3 JavaScript衍生的轻量级易用JSON 206
第 11章 Web的攻击技术 207
11.1 针对Web的攻击技术 208
11.1.1 HTTP不具备必要的安全功能 208
11.1.2 在客户端即可篡改请求 209
11.1.3 针对Web应用的攻击模式 210
11.2 因输出值转义不完全引发的安全漏洞 212
11.2.1 跨站脚本攻击 213
11.2.2 SQL注入攻击 218
11.2.3 OS命令注入攻击 223
11.2.4 HTTP首部注入攻击 225
11.2.5 邮件首部注入攻击 228
11.2.6 目录遍历攻击 229
11.2.7 远程文件包含漏洞 230
11.3 因设置或设计上的缺陷引发的安全漏洞 232
11.3.1 强制浏览 232
11.3.2 不正确的错误消息处理 234
11.3.3 开放重定向 237
11.4 因会话管理疏忽引发的安全漏洞 237
11.4.1 会话劫持 238
11.4.2 会话固定攻击 239
11.4.3 跨站点请求伪造 241
11.5 其他安全漏洞 242
11.5.1 密码破解 242
11.5.2 点击劫持 247
11.5.3 DoS攻击 249
11.5.4 后门程序 250