ByteTrack实时多目标跟踪
去年的1024我写了一篇FairMOT实时多目标跟踪,兜兜转转,一年过去了,最近FairMOT原作者发布了更快更强的ByteTrack,也就有了这篇文章,有种恍如隔世之感。
简介
ByteTrack是近期公开的一个新的多目标跟踪SOTA方法,第一次在MOT17数据集上到达80以上的MOTA并在多个榜单上排名第一,堪称屠榜多目标跟踪。本文主要介绍如何使用ByteTrack的源码进行实时跟踪(包括视频和摄像头)。本文均采用Ubuntu18.04进行环境配置,采用其他操作系统的在安装一些库时可能有所问题,需要自行解决。
ByteTrack的性能比较如下图,横轴表示推理速度、纵轴表示MOTA精度,圈的大小表示IDF1的数值。可以看到,ByteTrack超越了此前所有的跟踪方法。
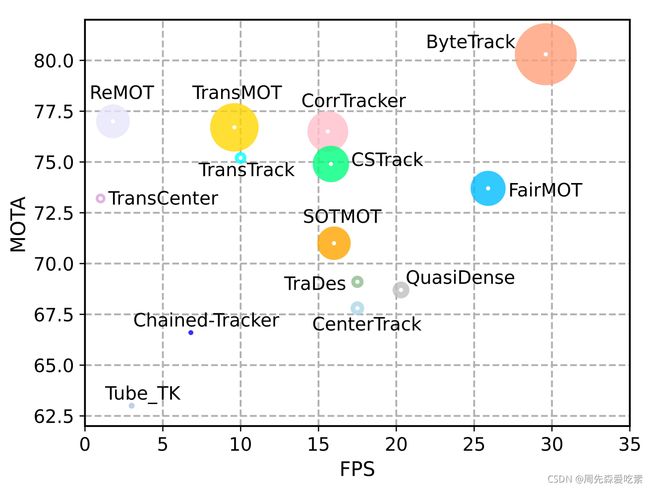
这里简单介绍一下这个算法的一些内容。Tracking-by-detection是MOT中的一个经典高效的流派,通过相似度(位置、外观、运动等信息)来关联帧间的检测框得到跟踪轨迹。不过,由于实际场景的复杂性,检测器往往无法得到完美的检测结果。为了权衡真假正例,目前大部分MOT方法会选择一个阈值(threshold),只保留高于这个阈值的检测结果来做关联得到跟踪结果,低于这个阈值的检测框就直接丢弃。作者认为这种策略是不合理的,就如黑格尔所说:“存在即合理。” 低分检测框往往预示着物体的存在(例如遮挡严重的物体)。简单地把这些物体丢弃会给MOT带来不可逆转的错误,包括大量的漏检和轨迹中断,降低整体跟踪性能。因此,作者提出了一种新的数据关联方法BYTE,将高分框和低分框分开处理,利用低分检测框和跟踪轨迹之间的相似性,从低分框中挖掘出真正的物体,过滤掉背景。简单来说,是一个二次匹配的过程,具体算法流程可以查看原论文。
这种策略行之有效的原因其实和此前一些针对遮挡的方法有很类似的地方,那就是当物体被遮挡的时候,这个过程肯定不是瞬时发生的,它必然伴随着检测框由明确到不明确的过程,也就是框的得分降低的过程,因此挖掘低分的检测框有助于修补那些被破坏的轨迹并保持一个较高的运行速度。
环境配置
下面介绍该项目环境配置的过程,需要保证用户已经安装了Git和Conda,且安装了支持CUDA10.2以上的显卡驱动。
逐行执行下面的命令即可,需要注意,这里通过conda安装了Pytorch和Cuda,因此requirements.txt文件中的torch和torchvision两行需要先行删去。
git clone [email protected]:ifzhang/ByteTrack.git
cd ByteTrack/
conda create -n bytetrack python=3.8 -y
conda activate bytetrack
conda install pytorch=1.7.1 torchvision cudatoolkit -y
pip install -r requirements.txt
python setup.py develop
pip install cython
pip install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
pip install cython_bbox
这时候关于模型推理的环境就安装完成了,当然,官方也给了docker环境配置的教程,这里就不介绍了,感兴趣的可以参考作者的README。
模型下载
使用在 CrowdHuman、MOT17、Cityperson 和 ETHZ 上训练的模型, 下载地址如下表,表中指标在MOT17训练集上测试得到。
| Model | MOTA | IDF1 | IDs | FPS |
|---|---|---|---|---|
| bytetrack_x_mot17 [google], [baidu(code:ic0i)] | 90.0 | 83.3 | 422 | 29.6 |
| bytetrack_l_mot17 [google], [baidu(code:1cml)] | 88.7 | 80.7 | 460 | 43.7 |
| bytetrack_m_mot17 [google], [baidu(code:u3m4)] | 87.0 | 80.1 | 477 | 54.1 |
| bytetrack_s_mot17 [google], [baidu(code:qflm)] | 79.2 | 74.3 | 533 | 64.5 |
本文以最轻量的s版本为例,下载bytetrack_s_mot17.pth.tar文件,下载后在项目的根目录下新建models文件夹并将该文件放入其中。
实时跟踪
经过上面的环境配置和模型下载,此时你可以通过下面的命令来推理作者提供的demo视频文件。
视频文件
python tools/demo_track.py video -f exps/example/mot/yolox_s_mix_det.py -c ./models/bytetrack_s_mot17.pth.tar --path ./videos/palace.mp4 --fp16 --fuse --save_result
推理过程中会出现如下的日志,并在当前目录下生成YOLOX_outputs目录,推理生成的跟踪结果就在其中。
其中部分选项符的含义如下。
demo:任务类型,必选项,可选image、video和webcam-f:模型配置文件-c:模型文件--path:需要进行推理的文件路径--save_result:是否保存推理结果
我们在VisDrone数据集中的一个场景下测试了这个s版本模型的效果,结果如下,由于我们采用的最轻量的s版本模型,因此精度不是很高,很多小目标没有检测出来,不过速度是非常快的。想要看到更准确的效果,可以尝试更复杂的模型,即m、l、x版本的模型。
ByteTrack实时多目标跟踪
摄像头
接着就是使用摄像头进行实时跟踪了,我这里使用的是比较方便的USB摄像头。由于作者已经提供了摄像头数据流的接口,并会在推理完成后保存推理的结果视频,但是我们使用摄像头进行跟踪的时候往往想要实时看到跟踪效果,因此,需要将作者的tools/demo_track.py中的imageflow_demo函数修改如下。
def imageflow_demo(predictor, vis_folder, current_time, args):
cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
if args.demo == "video":
save_path = os.path.join(save_folder, args.path.split("/")[-1])
else:
save_path = os.path.join(save_folder, "camera.mp4")
logger.info(f"video save_path is {
save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
tracker = BYTETracker(args, frame_rate=30)
timer = Timer()
frame_id = 0
results = []
while True:
if frame_id % 20 == 0:
logger.info('Processing frame {} ({:.2f} fps)'.format(frame_id, 1. / max(1e-5, timer.average_time)))
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame, timer)
online_targets = tracker.update(outputs[0], [img_info['height'], img_info['width']], exp.test_size)
online_tlwhs = []
online_ids = []
online_scores = []
for t in online_targets:
tlwh = t.tlwh
tid = t.track_id
vertical = tlwh[2] / tlwh[3] > 1.6
if tlwh[2] * tlwh[3] > args.min_box_area and not vertical:
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
timer.toc()
results.append((frame_id + 1, online_tlwhs, online_ids, online_scores))
online_im = plot_tracking(img_info['raw_img'], online_tlwhs, online_ids, frame_id=frame_id + 1,
fps=1. / timer.average_time)
if args.save_result:
vid_writer.write(online_im)
cv2.imshow("demo", online_im)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
frame_id += 1
此时通过下面的命令就可以实时看到摄像头内拍摄到的内容的跟踪效果(命令中的--camid表示摄像头编号),我已经测试了代码并成功运行,不过因为隐私问题我这里就不放跟踪效果视频了。
python tools/demo_track.py webcam -f exps/example/mot/yolox_s_mix_det.py -c ./models/bytetrack_s_mot17.pth.tar --fp16 --fuse --save_result --camid 0
补充说明
本文对应用ByteTrack实现了基于视频流的多目标实时跟踪,是研究ByteTrack代码闲暇之余的小demo,本文涉及的视频仅作示例之用,如有侵权请联系我删除。