图像分类网络综述
图像分类
- 1原理
- 2数据集
-
- 2.1MNIST
- 2.2fashion-MNIST
- 2.3CIFAR-10
- 2.4CIFAR-100
- 2.5Image Net
- 3 常见网络
- 4评价指标
-
- 4.1准确率
- 4.2top5错误率
- 4.3模型存储大小
- 4.4处理速度(时间)
- 5接下来要完成的
这篇论文讲的特别好:
https://x.cnki.net/read/article/xmlonline?filename=DXKX201911007&tablename=CJFDTOTAL&dbcode=CJFD&topic=&fileSourceType=1&taskId=&from=&groupid=&appId=CRSP_BASIC_PSMC&act=
基于深度学习的图像分类研究综述
在此表示感谢!!!
1原理
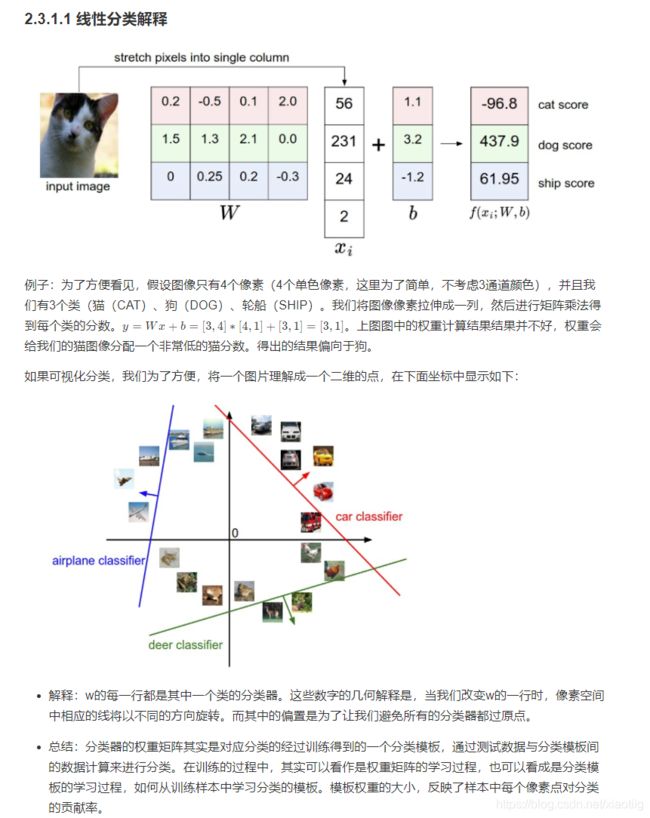
图像分类就是给一幅图像说出它的类别。
图像分类的主要过程包括图像预处理、特征提取和分类器设计。图像预处理包括图像滤波,如中值滤波[7]、均值滤波[8]、高斯滤波[9]以及图像归一化等操作,其主要作用是过滤图像中的一些无关信息,在简化数据的前提下最大限度地保留有用信息,增强特征提取的可靠性。特征提取是图像分类任务中最为关键的一部分,其将输入图像按照一定的规则变换生成另一种具有某些特性的特征表示,新的特征往往具有低维度、低冗余、低噪声、结构化等优点,从而降低了对分类器复杂度的要求,提高了模型性能。最后通过训练分类器对提取的特征进行分类,从而实现图像的分类。
传统的图像分类研究中,多数为基于图像特征的分类,即根据不同类别图像的差异,利用图像处理算法提取相应的经过定性或定量表达的特征,对这些特征进行数学统计分析或使用分类器输出分类结果。在特征提取方面,主要包括纹理、颜色、形状等底层视觉特征,尺度不变特征变换[10]、局部二值模式[11]、方向梯度直方图[12]等局部不变性特征,这些人工设计特征缺乏良好的泛化性能,且依赖于设计者的先验知识和对分类任务的认知理解。目前,海量、高维的数据也使得人工设计特征的难度呈指数级增加。
在分类器方面,主要包括k NN(k-nearest neighbor,k最近邻)决策树[14]、SVM(support vector machine,支持向量机)[15]、人工神经网络[16]等方法。这些分类器大大地提升了图像分类的效果,但对于处理庞大的图像数据、图像干扰严重等问题,其分类精度无法满足实际需求,故传统分类器不适合复杂图像的分类。
深度学习[17]是机器学习的一种新兴算法,因其在图像特征学习方面具有显著效果而受到研究者们的广泛关注。相较于传统的图像分类方法,其不需要对目标图像进行人工特征描述和提取,而是通过神经网络自主地从训练样本中学习特征,提取出更高维、抽象的特征,并且这些特征与分类器关系紧密,很好地解决了人工提取特征和分类器选择的难题,是一种端到端的模型。
**传统方法3步:**图像预处理、特征提取和分类器设计,每一种都有多种方法。
**深度学习方法2步:**图像预处理和图像识别,其中图像识别中的骨干网络实现特征提取的功能,后面的softmax等实现图像分类。
2数据集
目前常用的图像分类数据库主要包括以下5个,且数据库在数据体量及复杂程度上依次递增:
2.1MNIST
MNIST是图像分类领域最经典的一个数据库,包含70 000张28 dpi×28 dpi的灰度图像,由数字(0~9)构成,共10个类别。训练集包含60 000个样本和60 000个标签,测试集包含10 000个样本和10 000个标签。
参考下面网址:
详解mnist: https://www.cnblogs.com/xianhan/p/9145966.html
tf加载:https://blog.csdn.net/sinat_34328764/article/details/83832487
2.2fashion-MNIST
fashion-MNIST是一个类似MNIST数据库的时尚产品数据库。涵盖了来自10种类别的共70 000个不同商品的正面图片。fashion-MNIST的大小、格式和训练集、测试集划分与MNIST完全一致,60 000和10 000的训练、测试数据划分,28 dpi×28 dpi的灰度图像。
参考下面网址:
https://blog.csdn.net/qq_36387683/article/details/80612627
2.3CIFAR-10
CIFAR-10数据集包含60 000张32 dpi×32 dpi的彩色图像,由飞机、马、狗等10个类别构成,10类之间相互独立,无任何重叠的情况,训练集包含50 000个样本和50 000个标签,测试集包含10 000个样本和10 000个标签。

参考下面网址:
https://www.cnblogs.com/Jerry-Dong/p/8109938.html
https://blog.csdn.net/qq_41185868/article/details/82793025
2.4CIFAR-100
CIFAR-100数据集同样包含60 000张32 dpi×32 dpi的彩色图像,共100个类别,每类有600幅图像,包括500幅训练图像和100幅测试图像。不同于CIFAR-10,该数据集又将100个类划分为20个超类。
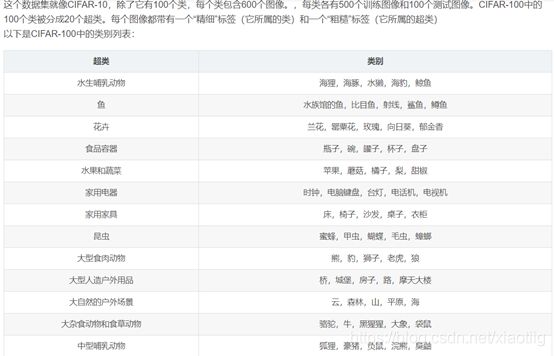
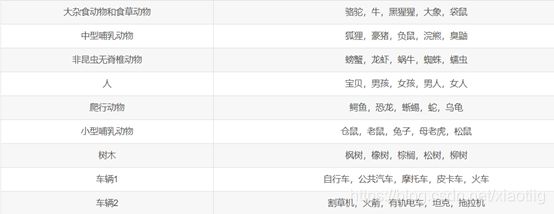
参考下面资料:
https://blog.csdn.net/u013555719/article/details/79343353
2.5Image Net
ImageNet是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库,也是最常用的数据库,包含1 400多万幅图像,涵盖2万多个类别,其中有超过100万幅图像有明确的类别标注和主要物体的定位边框,图像分类、定位、检测等研究工作大部分基于此数据集展开。也是一个挑战赛。
好像新手都会误以为from scratch train一个网络用到了ImageNet全部1千多万的数据,从前自己train网络的时候就傻傻地问过别人,到底有多少张图片啊?其实稍微查点资料就知道没有用到1500万(对应了2万多类),常用的是ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)比赛用的子数据集,其中:训练集:1,281,167张图片+标签验证集:50,000张图片+标签测试集:100,000张图片
ImageNet可能是指整个数据集(15 million),也可能指比赛用的那个子集(1000类,大约每类1000张),也可能指ILSVRC这个比赛。需要根据语境自行判断。
作者:知乎用户
链接:https://www.zhihu.com/question/273633408/answer/369134332
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
参考下面资料:
https://baike.baidu.com/item/ImageNet/17752829?fr=aladdin
历年冠军和相关模型 https://www.cnblogs.com/liaohuiqiang/p/9609162.html
https://www.zhihu.com/question/273633408
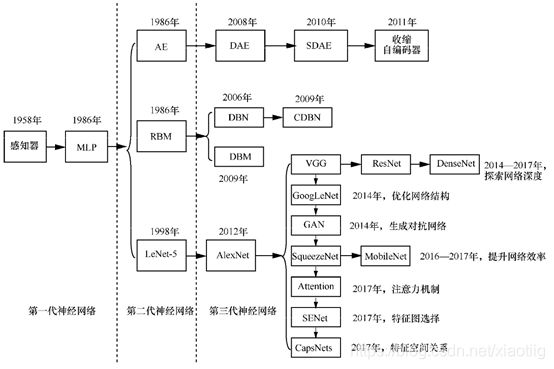
3 常见网络


4评价指标
4.1准确率
4.2top5错误率
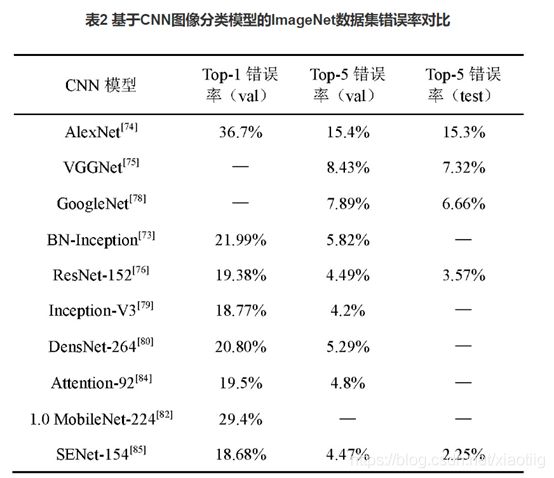
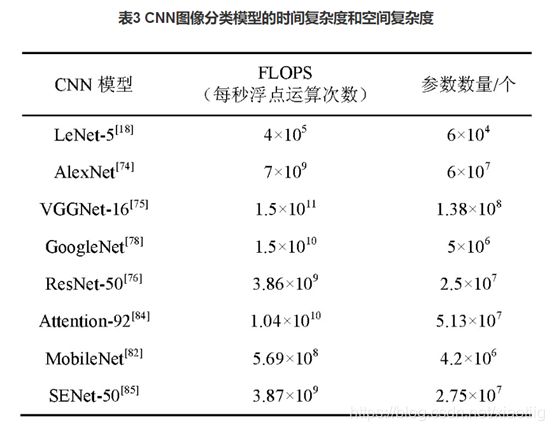
4.3模型存储大小
参数量、网络层数和存储大小
4.4处理速度(时间)
计算量
5接下来要完成的
(1)感知机
(2)bp模型
(3)LeNet
(4)AlexNet
(5)OverFeat
(6)ZFNet
(7)VGGNet16,19
(8)GoogleNet(v1\v2\v3\v4)
(9)ResNet
(10)DenseNet
(11)SENet
(12)ResNext
(13)Xception
(14)SqueezeNet
(15)mobileNet
(16)ShuffleNet
(17)GhostNet
(18)Attention
(19)CapsNets
(20)NasNet
(21)EfficientNet
(22)GAN