本⽂出⾃于“「2021 友盟+ 移动应⽤性能挑战赛」” 中的参赛作品,该⽂章表述了作者如何借助友盟+ U-APM⼯具进⾏了性能优化。
作为⼀款倒计时⽇历 APP,我们需要对每个⽇期实时显示倒计时并精确到秒。但是我们的 app 在滑动刷新数据时,会出现卡顿。
卡顿在很⼤程度上取决于设备的 CPU 和其他消耗 CPU 时间的进程。于是我们尝试使⽤了友盟 + U-APM 内存分析对 APP 进⾏分析:
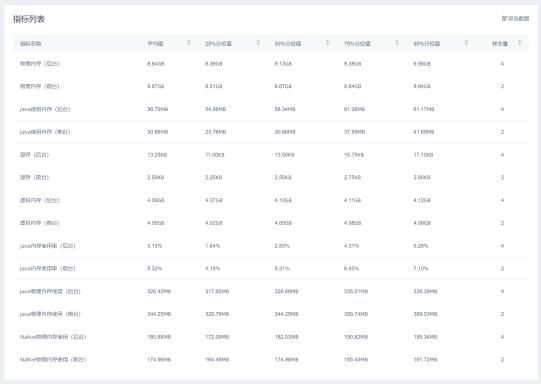
通过观察内存的分布,⼤部分程序的运⾏都处于可预测的范围内,我们需要更加细粒度地进⾏测试。
启动 Android Profiler Tool Window , 打开 CPU Profiler并选择正确的时间线 。连接我们的测试设备并再次进⾏滑动刷新,可以看到Profile线程被添加到应⽤进程并消耗了额外的 CPU 时间。看看 Logcat:
I/Choreographer: Skipped 147 frames! The application may be doing too much查看 CPU Profiler 时间线:
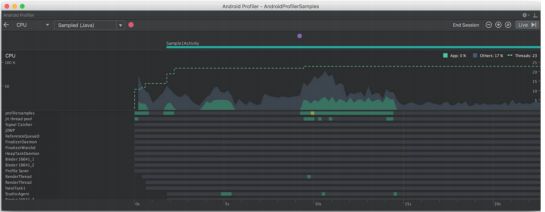
图表上⽅有⼀个视图表示⽤户与应⽤程序的交互。所有⽤户输⼊事件在此处显示为紫⾊圆圈。可以看到⼀个圆圈,代表我们为刷新数据⽽执⾏的滑动。
在事件下⽅,有⼀个 CPU 时间线,它以图形⽅式显示了与可⽤ CPU 总时间相关的应⽤程序和 其他进程的 CPU 使⽤率。还可以查看应⽤程序正在使⽤的线程数。
底部可以看到属于应⽤进程的线程活动时间线 。每个线程处于由颜⾊指示的三种状态之⼀: 活动 (绿⾊) 、等待 (⻩⾊) 或睡眠 (灰⾊)。
在列表顶部,可以找到应⽤程序的主线程。在我的设备 (Nexus 5X) 上,它使⽤的 CPU 时间⼤ 约 5 秒。我们可以记录⼀个⽅法跟踪来查看。
在滑动之前单击“记录”按钮以刷新操作并在数据刷新完成后⽴即停⽌记录:
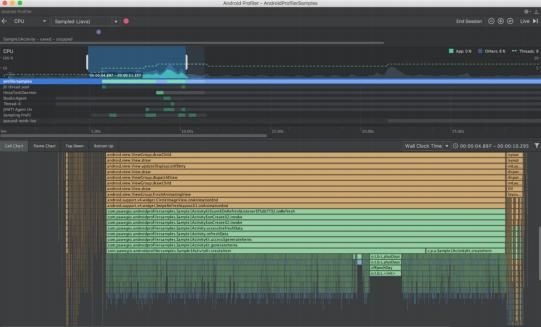
我们将从第⼀个选项卡中显示的图表开始分析。横轴代表时间的流逝。
调⽤者及其被调⽤者(从上到下)显示在垂直轴上。⽅法调⽤也通过颜⾊区分, 具体取决于是调 ⽤系统 API、第三⽅ API 还是我们本地函数 。每个⽅法调⽤的总时间是⽅法⾃身时间及其被调⽤者时间的总和:

从这张图表中,可以推断出性能问题出在 generateItems ⽅法内部。
为了证实我们的推断,我们⼜使⽤了友盟+ U-APM 进⾏了线上测试,测试结果和前⽂相同,下图是友盟+ U-APM 的卡顿分析测试,图中展示了主要是哪些⽅法造成了CPU的⾼耗时, 导致了卡顿情况的发⽣:
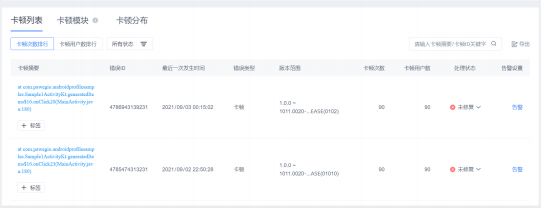
⽕焰图揭示了哪些⽅法占⽤了宝贵的 CPU 时间,并聚合了相同的调⽤堆栈:
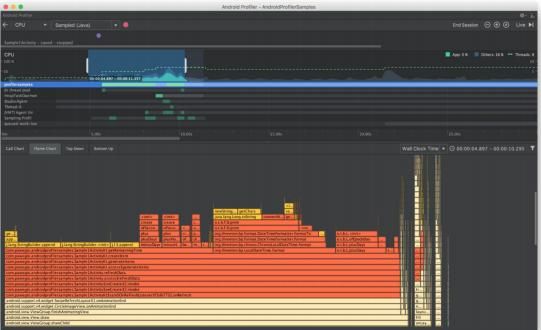
发现了两个可疑的地⽅,getRemainingTime 整个⽅法执⾏时间达到2 秒以上,LocalDateTime.format 占⽤ CPU 时间 1 秒以上:

此时间还包括线程未处于活动状态的时间段。另外, 可以切换要在线程时间中显示的计时信息。
最后⼀个选项卡中的图表显示按 CPU 时间消耗降序排列的⽅法调⽤列表。该图表提供详细的计时信息 (以微秒为单位) :

从图表中获取消耗过多 CPU 时间的⽅法的计时信息。将它们与调⽤堆栈中的两个⽅法相关联:
class method total time (in ms) percentage of recorded duration
Sample1Activity refreshData 3027 89.28
Sample1Activity generateItems 3025 89.22
Sample1Activity getRemainingTime 1723 50.83
LocalDateTime format 1003 29.59可以看到 getRemainingTime 和 LocalDateTime.format 消耗了超过 80% 的时间 。为了解决卡顿问题,我们需要从这⾥⼊⼿ 。
那么该怎么办? 聪明的读者可能已经提出了⼏种解决⽅案。由于我们执⾏了⼤量计算,所以我们将只为少数当前显示和准备显示的项⽬调⽤ getRemainingTime 和 LocalDateTime.format ⽅法。
为了实现它,我们需要更新 Item 属性,保存必要的数据以便稍后执⾏格式化:
data class Item(val now: LocalDateTime, val offset: Int)这需要在 generateItems 和 bindItem 函数中应⽤以下更改:
private fun generateItems(): List- {
val now = LocalDateTime.now()
return List(1_000) { Item(now, it + 1) }
}
private fun bindItem(holder: ViewHolderBinder
- , item: Item) = with(
val date = item.now.plusDays(item.offset.toLong()).toLocalDate().atS
val remainingTime = getRemainingTime(item.now, date)
我们内联了 createItem 函数,现在所有函数都在 bindItem ⽅法内部。
在我们的代码修改⽣效之后,重新启动 CPU Profiler 并记录⽅法的运⾏情况。
为了检查我们的优化是否成功,我们需要查看 Call Chart :

将⿏标移到 generateItems 函数上, 会发现现在耗时约为 0.3 秒。
这⽐优化前减少了13倍以上的 CPU 时间。为了确保我们的更改不会对 bindItem ⽅法的耗时造成负⾯增益,我们切换到⽕焰图标来检查bindItem的总耗时。
如图所示,它最多消耗 0.1 秒:
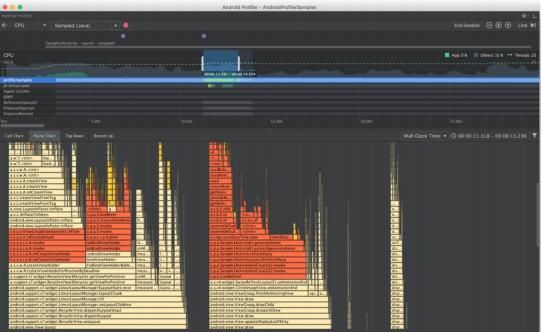
此外,我们可以进⾏滚动测试,以确保我们的代码优化不会影响整体应⽤程序的性能, 并且在滚动过程中加以记录。
测试发现滚动之后不会再出现卡顿和掉帧的情况了。成功!代码已优化!
总结
Android Profiler 和友盟+ U-APM 都是很好的测试⼯具。如果我们追求流畅的⽤户体验,那么使⽤这些优秀的 debug ⼯具是⼗分必要的。在本⽂中,我主要关注性能调优。
但是,本⽂中未涵盖的 Android Profiler 的 Memory Profiler 和 Network Profiler, 友盟+ U-A PM 的内存分析、OOF 异常和内存占⽤也同样值得研究。记录内存分配对查找内存泄漏有很⼤帮助, 例如代码中有没有回收 bitmap。
⽆论如何,使⽤恰当的分析⼯具可以带来多项优化成果,期待读者们的⾃⾏探索。
本⽂出⾃于“「2021 友盟+ 移动应⽤性能挑战赛」中的参赛作品,该⽂章表述了作者如何友盟+ U-APM⼯具进⾏了性能优化。