DDBSCAN聚类算法(DBSCAN的改进)
DDBSCAN(论文:Ddbscan: a density detection dbscan algorithm in e-commerce sites evaluation)
一、首先介绍DBSCAN的步骤,毕竟是它基础上的优化
DBSCAN这个博客讲得简单易懂 https://blog.csdn.net/huacha__/article/details/81094891
里面有两个参数需要人为定义:
eps:两点之间的最小距离(也就是一个圆形邻域的半径)。这意味着如果两点之间的距离低于或等于该值(eps),则这些点被认为是相邻。如果选择的eps值太小,则很大一部分数据不会聚集。它将被视为异常值,因为不满足创建密集区域的点数。如果选择的值太大,则群集会被合并,这样会造成大多数对象处于同一群集中。因此应该根据数据集的距离来选择eps,一般来说eps值尽量取小一点。
minPoints:表示形成密集区域的最小点数。例如,如果我们将minPoints参数设置为5,那么我们需要至少5个点来形成密集区域。作为一般规则,minPoints可以从数据集中的多个维度(D)导出,因为minPoints≥D+ 1.对于具有噪声的数据集,较大的minPoints值通常更好,并且将形成更完美的簇。minPoints的最小值必须为3(最小D就是2维),数据集越大,对应选择的minPoints值越大。
(以上两参数文字表述来自:https://cloud.tencent.com/developer/article/1447824 )
二、DDBSCAN来啦
改进的DBSCAN算法引入了密度检测的基本思想,解决了DBSCAN算法在处理高维密度不均匀数据时会产生大量离群值的问题。提出的密度检测方法首先查询n个节点的Eps邻域,从而得到每个节点的cv值。利用cv值对数据分区进行分割。算法如下:
密度
1、节点i的密度公式
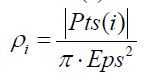 (1)
(1)
其中Eps是半径,Pts(i)是中心为i 半径为Eps的点集,|Pts(i)|是元素个数,ρi=元素个数/面积
节点i的圆形邻域中的其他点,记作k,它们的密度定义为:
![]() (2)
(2)
(2)是根据(1)计算密度,但邻域是以k为圆心,Eps为半径的圆
2、根据(2)式,可以计算平均密度了
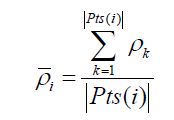 (3)
(3)
3、节点i邻域的密度方差(方差表示数据的离散程度)
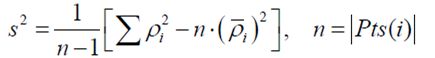 (4)
(4)
反映Eps邻域中每个点与均值的偏差程度
4、密度变异系数,表示在其Eps邻域中,节点i的密度变化;点越多,值越小(你看,s是方差,密度大了,离散程度小了,整个cv都变小了)
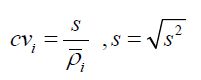
基于等深度分块法的数据分割
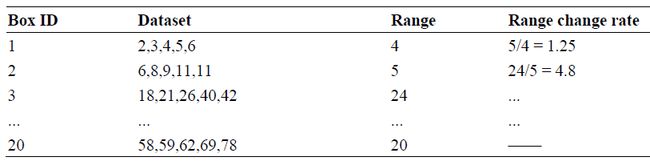
例子:一共一百个点,平均每个box放5个,一共20个box
定义一个阈值λ,用一个box的范围除以下一个box的范围(论文说是这么说,表里却是反过来相除),大于λ则分割,分割点选择这个box的最大或下一个box的最小
各分区Eps参数的自动设置
每个分区的Eps值定义为每个点与其邻域范围内前|Pts(i)|个点之间距离的平均距离
第一步:确定minPts的值。Cv小一点,定为4;cv大一点,定为2。具体情况具体定:-)
第二步:![]() 论文里说是用来计算每个点的Eps邻域中的节点数,并且说ρi由式(1)可得。(这里的|Pts(i)|不是式(1)里的|Pts(i)|,不是同一个东西)
论文里说是用来计算每个点的Eps邻域中的节点数,并且说ρi由式(1)可得。(这里的|Pts(i)|不是式(1)里的|Pts(i)|,不是同一个东西)
第三步: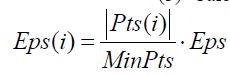 ,这里的Eps应该是DBSCAN的,不是各分区的
,这里的Eps应该是DBSCAN的,不是各分区的
第四步:Eps(i)求和取平均, 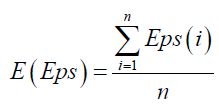
算法步骤:
输入:包含n个对象和半径n的数据集D。
输出:聚类结果。
(1) 首先查询每个节点的Eps邻域,分别计算其密度;
(2) 根据步骤(1)的结果计算每个节点的平均密度,进而得到每个节点的方差s2;
(3) 将步骤(2)的结果代入式(5)中,计算各节点的cv值;
(4) 基于等深度分块法的数据分割;
(5) 自动设定Eps和MinPts值;
(6) 在每个数据分区运行DBSCAN算法;
(7) 得到聚类结果,结束整个算法。