kmeans聚类算法_基于K-means聚类的用户用电行为分析

大数据时代,通过简单的仪表监测家庭、工厂等地的实时用电量后,可以通过聚类算法对用户用电特征进行聚类,这有利于:
1.将用电行为类似的用户进行聚合,以便用电公司提供更合理的套餐服务;
2.根据不同类型的用户行为,收取不同的税费;
3.根据不同类型的用户行为,调整电网的输电效率,提高电能利用率。
本次分析采用K-means聚类方法,数据源自Pecan Street Energy Database的数据库文件dataport_sqlite。
具体分析流程如下
1.导入数据
导入必要的模块
%matplotlib inline
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import pylab
import seaborn as sns
import sqlite3从数据库文件中读取数据
cwd = os.getcwd() #获得当前的文件路径
conn = sqlite3.connect(str(cwd) + "/dataport_sqlite")
cursor = conn.cursor() #构建指针
query = "SELECT * FROM new_table;"
cursor.execute(query) #执行读取数据命令
data = cursor.fetchall() #抓取数据用pandas将数据转换成DataFrame格式
loads_df = pd.DataFrame(data, columns=['id','date','energy_use'])
loads_df.head()
数据中,id代表不同的用户;date代表时间,每15min采集一次;energy_use代表测量的电量,以kW表示。
通过简单的查询命令可以获得数据集的规模:
print("当前数据集含有%s行,%s列"%(loads_df.shape[0],loads_df.shape[1]))当前数据集含有646981行,3列
print(" 最早时间: %s n 最晚时间: %s"%(loads_df.date.min(),loads_df.date.max())) 最早时间: 2015-07-01 00:00:00
最晚时间: 2015-08-01 00:00:00
(正好是一个月的用电记录)
loads_df['id'].value_counts()可以看到本次分析的用户共有216户。
2.数据清洗
查看当前数据中的空缺值
loads_df = loads_df.replace('',np.nan)
loads_df.isnull().sum() 可知,用电量(energy_use)存在10695个空值。
删除空缺值,同时为了保证后期数据运算的需要,改变数据类型
loads_df.loc[:,'energy_use'] = loads_df.energy_use.astype(float)
loads_df.loc[:,'id'] = loads_df['id'].astype(int)
loads_df.loc[:,'date'] = pd.to_datetime(loads_df.date) 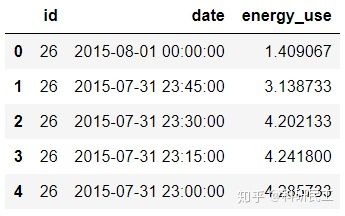
3.特征工程
上面得到的用电数据中,时间列中包含了年月日和具体时间。为了获得用户不同时间的用电行为,进一步对时间列进行处理如下:
# 添加一代表星期的列,isoweekday会根据日期判定是周几
loads_df.loc[:,'type_day'] = loads_df.date.apply(lambda x: x.isoweekday())
# 添加一代表日期的列,day会根据具体日期判定是几号
loads_df.loc[:,'day_of_month'] = loads_df.date.apply(lambda x: x.day)
# 按照id和日期进行重新排序
loads_df = loads_df.sort_values(['id', 'date'], ascending=[True, True])
loads_df = loads_df.reset_index(drop=True)为了更好的避免用电行为的差异,过滤掉时间为周末的用电数据
loads_df=loads_df[loads_df.type_day<=5]将当前的表按照数据透视表的方式进行处理,将不同的时间分列
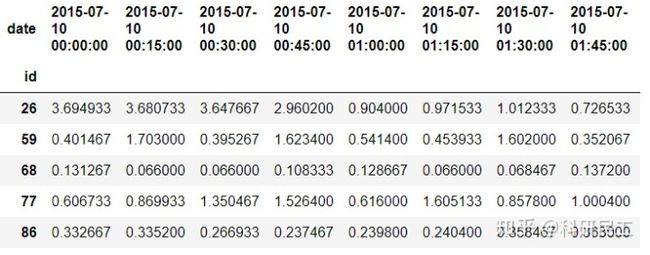
loads_wide_df = pd.pivot_table(data=loads_df,columns=['date','day_of_month'],values='energy_use',index=['id'])
unique_days = loads_df.day_of_month.unique()
loads_wide_df = pd.concat([loads_wide_df.xs(10,level='day_of_month',axis=1) for day in unique_days])这里,我假设工作日每天的用电情况近似,以10号当天不同时间的用电数据进行具体分析
依据获得的数据,绘制当日不同时间不同用户的用电特征曲线如下:
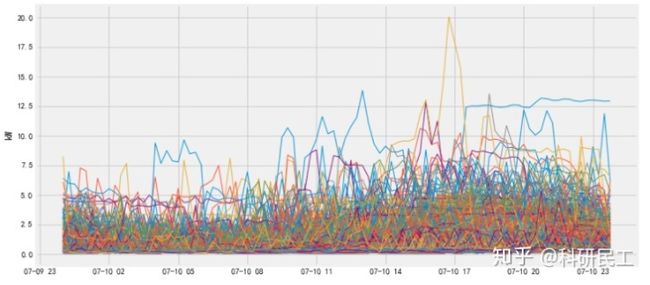
额,结果比较杂乱无章,完全看不出规律,下面我们将当前获得的数据进行聚类。
4.聚类模型
导入分析模块
from sklearn.cluster import KMeans构建可视化类对数据进行分析
class EnergyFingerPrints():
def __init__(self,data):
# 统计每个聚类簇的中心点
self.means = []
self.data = data
def elbow_method(self,n_clusters):
fig,ax=plt.subplots(figsize=(8,4))
distortions = []
for i in range(1, n_clusters):
km = KMeans(n_clusters = i,
init='k-means++', #初始中心簇的获取方式,k-means++一种比较快的收敛的方法
n_init=10, #初始中心簇的迭代次数
max_iter=300, #数据分类的迭代次数
random_state=0) #初始化中心簇的方式
km.fit(self.data)
distortions.append(km.inertia_) #inertia计算样本点到最近的中心点的距离之和
plt.plot(range(1,n_clusters), distortions, marker='o',lw=1)
plt.xlabel('聚类数量')
plt.ylabel('至中心点距离之和')
plt.show()
def get_cluster_counts(self): #统计聚类簇和每个簇中样本的数量
return pd.Series(self.predictions).value_counts()
def labels(self,n_clusters): #确定每簇中样本的具体划分
self.n_clusters = n_clusters
return KMeans(self.n_clusters, init='k-means++', n_init=10,max_iter=300,random_state=0).fit(self.data).labels_
def fit(self,n_clusters): #基于划分簇的数量,对数据进行聚类分析
self.n_clusters = n_clusters
self.kmeans = KMeans(self.n_clusters)
self.predictions = self.kmeans.fit_predict(self.data)
def plot(self): #分别绘制各簇中的用户用电行为曲线,并绘制各簇的平均用电行为曲线
self.cluster_names = [str(x) for x in range(self.n_clusters)]
fig,ax=plt.subplots(figsize=(12,16))
for i in range(0,self.n_clusters):
all_data = []
for x,y in zip(self.data,self.predictions):
if y == i:
all_data.append(x)
plt.subplot(4,1,i+1)
plt.plot(x,alpha=0.006,color="blue")
#plt.ylim(0,4)
plt.xlim(0,96)
plt.title('Cluster {}'.format(i+1))
plt.ylabel('用电量/kW')
all_data_array = np.array(all_data)
mean = all_data_array.mean(axis=0)
self.means.append(mean)
plt.plot(mean, color="black",linewidth=4)
plt.show()
def plot_energy_fingerprints(self): #将各簇的用电行为数据绘制在一张表上
fig,ax=plt.subplots(figsize=(8,5))
for i,item in enumerate(self.means):
plt.plot(item, label = "cluster %s"%(str(i+1)))
plt.xlim(0,96)
plt.ylabel('用电量/kW')
plt.legend()
plt.show()5.模型调用
将3中的数据转化成array结构
load_data=np.array(loads_wide_df)基于4中的类,构建类对象,并调用
energy_clusters = EnergyFingerPrints(load_data)分析各簇中心点与样本的距离
energy_clusters.elbow_method(n_clusters=13)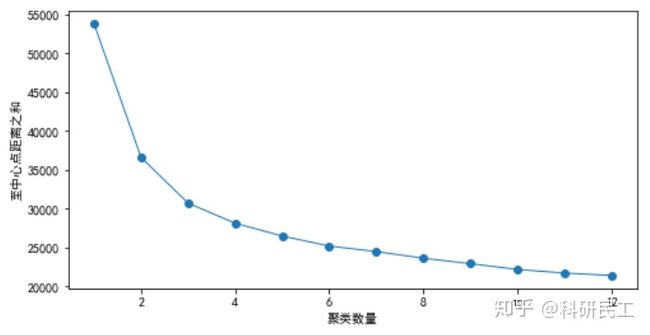
显然,随着聚类簇数n的增加,样本点至中心簇间的距离逐渐减小。这里,我们取n=4为拐点。
随后,构建一个聚类簇为4的模型,并分组
energy_clusters.fit(n_clusters = 4)
energy_clusters.get_cluster_counts()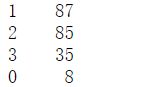
构建簇和用户id的DataFrame(cls),并可以筛选出各簇中相应的id
#获得属于第一分类簇的用户id
np.array(cls.loc[cls.cluster ==0].user_id)
其他簇的结果可以依次类推。
将各簇的用户平均用电行为曲线进行类比,如下:
energy_clusters.plot_energy_fingerprints()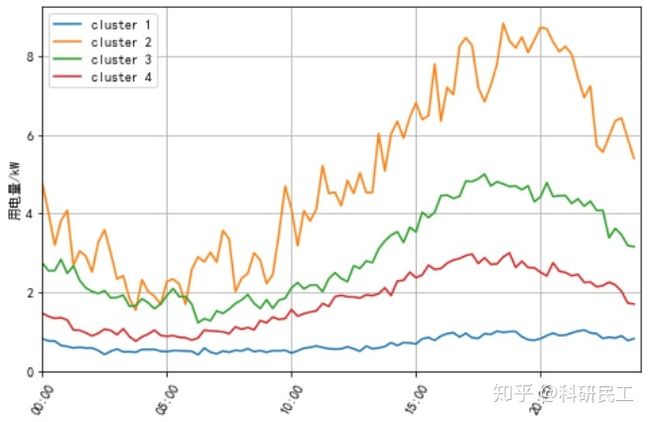
结论:
显然,模型基于用电量梯度,将用户分成了4类:
第一类用户:用电量始终较低,未出现过较大波动;
第三四类用户:用电量特征类似,表现为晚间用电量显著提高;
第二类用户:用电量自早晨5点开始即明显提升,可能是某些产品生产者。
具体的行为有待结合实际情况进行分析。
感谢阅读(数据集在这里,别再问哪里注册了)