11 Confluent_Kafka权威指南 第十一章:流计算
文章目录
-
- CHAPTER 10 Stream Processing 流式计算
-
- What Is Stream Processing? 流处理是什么
- Stream-Processing Concepts 流处理的概念
-
- Time 时间
-
- Mind the Time Zone 注意时区
- State 状态
- Stream-Table Duality
- Time Windows 时间窗口
- Stream-Processing Design Patterns 流处理设计模式
-
- Single-Event Processing 单事件处理
- Processing with Local State 本地状态处理
- Multiphase Processing/Repartitioning 多路处理/重新分区
- Processing with External Lookup: Stream-Table Join 处理外部查找:流表连接操作
- Streaming Join 流连接
- Out-of-Sequence Events 按顺序事件
- Reprocessing 再处理
- Kafka Streams by Example kafka流处理例子
-
- Word Count 单词统计
- Stock Market Statistics 股票市场统计数据
- Click Stream Enrichment
- Kafka Streams: Architecture Overview kafka流架构概述
-
- Building a Topology 建立一个拓扑
- Scaling the Topology 扩展拓扑
- Surviving Failures 故障幸存
- Stream Processing Use Cases 流处理用例
- How to Choose a Stream-Processing Framework 如何选择流计算框架
- Summary 总结
CHAPTER 10 Stream Processing 流式计算
kafka 传统上被视为一个强大的消息总线,能够处理事件流,但是不具备对数据的处理和转换能力。kafka可靠的流处理能力,使其成为流处理系统的完美数据源,Apache Storm,Apache Spark streams,Apache Flink,Apache samza 的流处理系统都是基于kafka构建的,而kafka通常是它们唯一可靠的数据源。
行业分析师有时候声称,所有这些流处理系统就像已存在了近20年的复杂事件处理系统一样。我们认为流处理变得更加流行是因为它是在kafka之后创建的,因此可以使用kafka做为一个可靠的事件流处理源。日益流行的apache kafka,首先做为一个简单的消息总线,后来做为一个数据集成系统,许多公司都有一个系统包含许多有趣的流数据,存储了大量的具有时间和具有时许性的等待流处理框架处理的数据。换句话说,在数据库发明之前,数据处理明显更加困难,流处理由于缺乏流处理平台而受到阻碍。
从版本0.10.0开始,kafka不仅仅为每个流行的流处理框架提供了更可靠的数据来源。现在kafka包含了一个强大的流处理数据库作为其客户端集合的一部分。这允许开发者在自己的应用程序中消费,处理和生成事件,而不以来于外部处理框架。
在本章开始,我们将解释流处理的含义,因为这个术语经常被误解,然后讨论流处理的一些基本概念和所有流处理系统所共有的设计模式。然后我们将深入讨论Apache kafka的流处理库,它的目标和架构。我们将给出一个如何使用kafka流计算股票价格移动平均值的小例子。然后我们将讨论其他好的流处理的例子,并通过提供一些标准来结束本章。当你选择在apache中使用哪个流处理框架时可以根据这些标准进行权衡。本章简要介绍流处理,不会涉及kafka中流的每一个特性。也不会尝试讨论和比较现有的每一个流处理框架,这些主题值得写成整本书,或者几本书。
What Is Stream Processing? 流处理是什么
关于流处理的含义存在很多混淆,许多定义混淆了实现细节、性能需求,数据模型和软件工程的许多其他方面。我们在关系数据库的世界中看到了同样的事情,关系模型的抽象定义与流数据引擎的实现和特定的限制混淆在一起。
流处理的世界任在发展,仅仅因为一个特定的流行实现以及特定的方式或者特定的限制并不意味着这些细节是处理流数据的固有部分。
让我们从头开始,什么是流数据,首选,数据是一种抽象,表示无边界的数据集。无边界的意思就是无限和不断增长的。数据集是无届的,因为随着时间的推移,新的记录不断的到达。使用此定义的公司包括谷歌、亚马逊、几乎所有的公司都如此。
这个简单的模型可以用来表示我们要分析的几乎所有的业务活动。我们可以查看信用卡交易,股票交易,包裹交付,通知交换机的网络事件,制造设备的传感器报告的事件,发送的电子邮件,有戏中的移动等。例子不胜枚举,因为几乎每件事都可以看作一系列事件。
除乐它们的无界性质之外,事件流模型还有一些其他的属性:
- Event streams are ordered 事件流是有序的
有一个固定的概念,即哪些事件发生在其他事件之前或者之后。这一点在金融事件中表现得最为明显,我们先把钱存入账户,然后再花钱,这与我们先花钱然后再还债是不同的。后者将导致信用卡透支,而前者不会。请注意,这是事件流和数据库表记录之间的区别之一。再表中总被认为是无序的,SQL的order by 字句不是关系模型的一部分,增加它是为了协助查询。 - Immutable data records 数据记录不可变
事件一旦发生,就永远无法改变。被取消的金融交易不会消失,相反,一个额外的事件被写入流,记录先前被取消的事务。当顾客把商品退给商店的时候,我们不会删除商品已经卖给他的事实,而是把退货作为一个额外的事件进行记录。这是数据流和数据库表之间的另外一个区别。我们可以删除或者更新表中的记录,但是这些激励都是发生再数据库中的所有额外事务。因此可以记录在记录所有事务的事件流中。如果你熟悉数据库的binglog、wals或者redo日志,你可以看到,我们在表中插入一条记录,然后删除,表中将不在包含该记录,但是redo日志将包含两个事务,插入和删除。 - Event streams are replayable 事件流是可以重放的
这是一个理想的特点,虽然很容易想象不可重放的流,通过套接字流tcp的数据包通常是不可重放的。但是对于大多是业务和应用程序来说,能够重放几个月之前发生的原始事件流是至关重要的。这是为了纠正错误,尝试新的分析方法,或者执行审计。这就是我们相信kafka使流处理在现代商业中如此成功的原因,它允许捕获或者重放事件流,如果没有这个功能,流处理将只是数据科学家实验室的玩具。
值得注意的是,无论是事件流的定义,还是我们稍后列出的属性,都没有提到包含在事件流中的数据或者每秒的事件数。数据因系统而异,事件可能很小,有时只有几个字节,也可能很大,有许多xml消息。它们也可以是完全非结构化的key-value,半结构化的json或者结构化的JSON的Avro或者ProtoBuf信息。虽然通常认为数据流是大数据,并且每秒涉及百万个事件,但是我们将讨论的相同技术同样适用于每秒或者每分钟只有几个事件的较小的事件流。
现在我们知道了什么是事件流,是时候确保我们理解流处理了。流处理是指一个或者多个事件流的正在进行的处理。流处理是一种编程范式,就像request response和批处理一样。让我们看看不同的编程范式如何比较,以更好的理解流处理如何适合软件架构。
- Request-response 请求响应
这是最低的延迟范例,响应时间重从亚毫秒到几毫秒不等。通常期望响应时间高度一致。处理模式通常是阻塞,应用程序发送一个请求,然后等待处理系统响应。在数据库世界中,这种范式被称为在线事务处理,OLTP。销售点系统,信用卡处理和时间耿总系统通常在这个范例中工作。 - Batch processing 批处理
这是一个高延迟高吞吐量的选项。处理系统在等待固定的时间被唤醒,每天凌晨2点整等等,它读取所有必须输入,写入所有必须的输出,然后离开,知道下一次计划运行的时间为止。处理时间从几分钟到几小时不等,用户在查看结果时希望读取这些陈旧的数据,在数据库世界中,这些是数据仓库和BI系统,数据每天大量载入一次,生成报告,用户查看相同的报告,知道下一次数据载入发生。这种模式通常具有很高的效率和经济规模。但是近年来,为了使决策更加及时和高效,企业需要在更短的时间内获得可用的数据。这给哪些开放规模经济的系统带来了巨大的压力–无法提供低延迟的报告。 - Stream processing 流处理
这是一个有争议且无阻塞的选项,填补请求-响应和批处理之间的空白,前者等待需要2毫秒处理的事件,而后者每天处理一次数据,需要8个小时才能完成。大多数业务系统不需要在毫秒内立即响应,但也不能等到第二天。大多数业务流程是连续发生的,但是只要亚尔u报告是连续更新的,业务应用程序可以连续响应。处理就可以连续进行。而无需任何人在毫秒内等待特定的响应。对可疑的信贷交易或者网络活动发出警报,根据供求情况实时调整价格,或者跟踪包裹的交付,这些业务对于连续而非阻塞的处理来说都是很自然的。
需要注意的是,这个定义并不强制要求任何特定的框架,APi或者特性。只要你不断的从一个不受限制的数据集中读取数据,然后对他做一些操作,之后输出结果,你正在进行流处理。但是这个过程必须是连续的,持续的。这个过程从每天凌晨两点开始,从流中读取500条记录输出一个结果,然后删除,但流处理的进展不能完全减少记录。
Stream-Processing Concepts 流处理的概念
流处理与其他的数据处理非常类似,你编写代码收到数据,对数据进行处理,转换、聚合、丰富等。然后将结果放在某个地方。但是,有一些流处理的关键概念,当有数据处理经验的人第一次尝试编写流处理的应用程序时,他们常常会引起混淆。让我们来看看其中的一些概念。
Time 时间
时间是流处理中最重要的概念,也是最令人困惑的概念,关于讨论分布式系统时间会变得多么复杂的想法,我们推荐Justin Sheehy 的优秀论文“There is No Now”。在流式处理上下文中,拥有一个共同的时间概念是至关重要的。因为大多数流应用程序在时间窗口上执行操作。例如,我们在流应用程序中可以计算移动的5分分钟的平均股价。在这种情况下,我们需要知道当我们的生产者脱机两小时并返回两小时的数据的时候我们应该怎么做,大多数数据都与5分钟的时间窗口相关,这些时间窗口已经经过很长时间,并且结果已经计算并存储了。
流式处理系统通常包含以下的时间概念:
- Event time 事件事件
这是我们正在跟踪的事件发生和记录创建时测量的时间。在商店出售物品,用户在我们的网站上查看页面时间等等,在版本0.10.0以及更高的版本中,kafka会在生产者被记录创建时自动添加当前时间。如果这与应用程序的时间概念不匹配,比如kakfa记录是在事件发生后一段时间根据数据库记录创建的,那么应该在记录本身中添加事件时间字段,事件时间通常是最重要的时间。 - Log append time 日志添加时间
这是事件到达kafka broker进行存储的的时间。在版本0.10.0以及更高的版本中,如果kafka被配置了这样做,或者如果来自较老的生产者中的记录没有包含时间戳。kafka的broker将自动将这个时间添加到他们收到的记录中。时间的概念通常与流处理不太相关,因为我们通常对事件发生的时间感兴趣,例如,如果我们计算每天生产设备的数量,我们希望计算当天实际生产设备的数量,即使存在网络问题,并且第二天才到达kafka。然而,在没有记录真实事件时间的情况下,日志添加时间任然可以一致地使用,因为它在记录创建后不会更改。 - Processing time 处理时间
这是流处理应用程序接收事件以便执行某些计算的时间。这个时间可以是时间发生后的毫秒,小时或者天。这个时间概念为同一个事件分配不同的时间戳,具体取决于每个流处理应用程序读取事件的确切时间。对于同一个应用程序中的两个线程,它甚至会有所不同。因此,这种时间概念是非常不可靠的,最好避免使用这个时间概念。
Mind the Time Zone 注意时区
在使用时间进行工作时,很重要的一点是要注意时区,整个数据管道应该在单一时区标准化,否则,流操作的结果将是混乱的,而且毫无意义。如果必须处理不同时区的数据流,则需要在确保对时间窗口执行操作之前能够将事件转换为相同的时区。通常这意味着在记录本身中存储时区。
State 状态
只要你只需要单独处理每个事件,流处理就是一个非常简单的活动,例如,如果你所需要的知识阅读来自kafka的在线购物交易流,找到超过10000$的交易并给相关销售人员电子邮件,那么你可能可以使用kafka消费者和smtp库用几行代码就能搞定这个需求。
当你涉及多个事件操作时,流处理变得非常有趣,安类型计算事件的数量,移动平均线,连接两个流来创建丰富的信息流,等等。在这些情况下,只看每个事件本身是不够的,你需要跟踪更多的信息,这一小时我们看到了每种类型的多少事件,所有需求合并,求和,平均的事件等等,我们把存储在事件之间的信息称为状态。
通常很容易将存储在流处理应用程序的本地变量中。比如一个用于存储移动计数简单哈希表,实际上,我们在署中做了很多例子。但是这不是管理流处理中的状态的可靠的方法,因为当流处理应用程序停止的时候,状态将丢失,从而改变结果,着通常不是预期的结果,因此在启动应用程序时,应该注意持久化最近的状态并恢复它。
流处理涉及到如下几种状态:
- Local or internal state 本地或内部状态
自能由流处理应用程序的特定实例访问状态,这种状态通常由应用程序中运行的嵌入式内存数据库来维护和管理。本地状态的优势是它非常快,缺点是可用的内存有限,因此流处理中的许多设计模式关注于将数据划分为子流的方法。这些子流可以使用有限数据量的本地状态进行处理。 - External state 外部状态
在外部存储中维护的状态,通常是cassandra这样的nosql数据库系统。外部状态的优点是它的大小几乎没有限制,并且可以从应用程序的多个实例甚至不同的应用程序中访问他。缺点是附加的系统会带来额外的延迟和复杂性。大多数流处理应用程序试图避免不得不处理外部存储,或者至少通过在本地状态缓存信息并尽可能少地与外部存储通信来限制延迟开销,这通常会带来维护内部和外部状态之间的一致性挑战。
Stream-Table Duality
我们都非常熟悉数据库的表。表是记录的集合。每个记录都是由其主键标识,并包含一组在模式中定义的属性。表记录是可变的,允许增删改。查询表允许在特定的时间点检查数据的状态,例如,通过查询数据库中的CUSTOMERS_CONTACTS表,我们希望找到所有的客户的当前的联系方式的信息。除非该表是专门设计来包含历史记录的,否则我们不会在该表中找到他们过去的联系人。
与表不同的是,流包含了之前的历史记录,流是一串事件,其中每个事件引起一个变化。表包含当前的状态,这是许多更改的结果。从这个描述中可以清除的看出,流和表是同一枚硬币的两面,世界总是在变化,有时候我们感兴趣的是引起变化的事件,而其他的时候我们感兴趣的是世界的当前状态。允许你在这两种状态查看数据的方式之间来回切换的系统要比在这两种方式之间只能呈现一种的系统更强大。
为了将表转换为流,我们需要捕获修改表的更改操作。将insert、update、delete事件存储在一个流中。大多数数据库提供了用于捕获这些变化的数据的解决方案(CDC)。并且有许多kafka的连接器可以将这些变化传输到kafka中,以进行流处理。
为了将流转换为表,我们需要包含所有对应用流的更改。这也称为物化流。我们在内存,内部状态存储外或者外部数据库中创建一个表,并开始从头到尾检查流中的所有事件,并在过程中更改状态。完成后,我们就有了一个表,标识特定的时间状态,我们可以使用它。
假设我们有一家卖鞋的商店。零售活动的流标识可以是一系列事件:
- 货物送来了红、蓝、绿鞋子
- 蓝色的鞋子卖出
- 红色的鞋子卖出
- 绿色的鞋子卖出
- 蓝色的鞋子卖出
如果我们想值得我们的库存现在包含什么,或者到目前为止我们赚了多少钱,我们需要物化这个视图。如下图所示。我们目前所有蓝色和黄色的鞋子,银行中有170$。如果我们想值得商店有多忙,我们可以查看整个流。看到有5个事务。我们可能还想调查蓝色鞋子被退回的原因。

Time Windows 时间窗口
流上的大多数操作都是窗口操作–在时间片上操作,移动平均线,本周销售的顶级产品,系统上99%的负载等。
两个流的连接操作也有窗口,我们连接在同一时间片上发生的事件。很少有人停下来想想他们需要的操作的时间窗口是什么类型。例如,在计算平均移动时间线时,我们想知道:
- 窗口的大小:我们计算每个5分钟的窗口的所有相关事件的平均值吗?每15分钟的窗口吗?还是一整天?大窗口更平滑。但是滞后事件更久。如果价格上涨,需要比小窗口更长的时间才能注意得到。
- 窗口移动的频率:5分钟的平均值可以每分钟,每秒或者每次有新事件发生的时候更新。当前间隔等于窗口大小时,有时候被称为滚动窗口。当窗口在每个记录上移动时,有时候称为滑动窗口。
- 窗口保持可更新的时间,我们五分钟移动平均线计算了00:00-00:05窗口的平均时间。现在一小时滞后,我们得到了更多的比赛计过,比赛时间是00:02的结果是否更新到00:00-00:05这个窗口?还是我们应该让过去的事情成为过去。理想的情况下,我们能够定义一个特定的时间段,在此期间事件将被添加到他们各自的事件片中。例如,如果事件延迟了4个小时,我们应该重写计算结果并进行更新。如果事件晚于此。我们可以忽略他们。
窗口可以与时间对齐,例如,在美国,一个每分钟移动一次的五分钟的时间窗口将会有第一个切片为00:00-00:05.第二个为00:01-00:06。或者它可以不对齐。只要在应用程序开始的时候,第一个切片可以03:17-03:22。滑动窗口永远不会对其,因为只要有新记录,他们就会移动,请参见如下这两种滑动窗口的区别:

Stream-Processing Design Patterns 流处理设计模式
每个流处理系统都是不同的,从消费者,处理逻辑和生产者的基本组合到诸如SparkStreams及其机器学习库相关的集群。还有很多是介于两者之间的。但是有一些记本的设计模式,他们是流处理体系结构中常见需求的已知解决方案。我们将回顾其中几个众所周知的模式。并通过及时实例展示如何使用他们。
Single-Event Processing 单事件处理
流处理最基本的模式是单独处理每个事件。这也称为map/filter模式。因为他通常从流中筛选不必要的事件或者转换每个事件。(术语map是基于map/reduce模式,其中map阶段转换事件,reduce阶段聚合事件)。
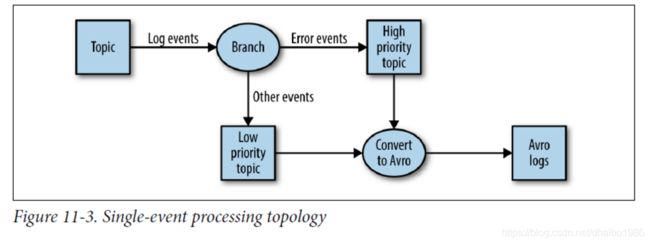
在此模式中,流处理应用程序使用流中的事件,修改每个事件,然后将事件生成到另外一个流中。例如,一个应用程序从流中读取日志消息,并将错误事件写入高优先的流。将其剩余事件写入低优先级流。了一个例子就是从流中读取事件并将其从JSON修改为Avro的应用程序。这也的应用程序都需要在应用程序内维护状态。因为每个事件都可以独立处理,这意味着,从应用程序故障或者负载均衡中恢复非常简单,因为不需要恢复状态。你可以简单地将事件传递给应用程序的另外要给实例来处理。
这个设计模式可以通过一个简单的生产者和消费者来实现,如下图:
Processing with Local State 本地状态处理
大多数流处理应用程序都与信息聚合有关,特别是时间窗口聚合。这方面的一个例子是找出每天交易的最低和最高的股票价格,并计算移动平均线。
这些聚合要维护流状态,在我们的示例中,为了计算每天的最小和平均价格,我们需要存储到当前时间之前看到的最小和最大值。并讲流中的每个新值与存储的最小和最大值进行比较。
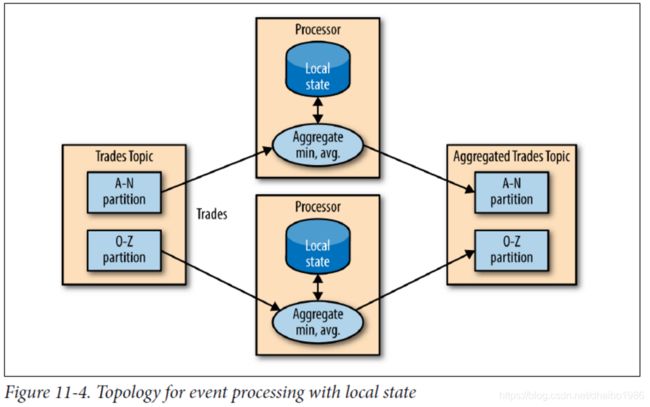
所有的这些都可以使用本地状态而不是共享状态完成,因为我们示例中的每个操作都是按聚合分组完成的。也就是说,我们对股票代码执行聚合,而不是对整个股票市场进行聚合。我们使用kafka分区程序来确保所有具有相同股票代码的事件都被写入到相同的分区中。然后,应用程序的每个实例将从分配给他的分区中获得所有的事件。这事kafka消费者保证的。这意味着,应用程序的每个实例都可以维护股票符号的子集的状态,这些股票符号子集被写入分给给它的分区中,参见下图:
当应用程序具有本地状态时,流处理应用程序将变得非常复杂,而且流处理应用程序必须解决如下几个问题:
- Memory usage 内存使用:本地状态碧玺适合应用程序实例可用的内存。
- Persistence 持久性:我们需要确保当应用程序实例关闭时状态不会丢失,并且当实例再次启动或者被另外要给实例替换时状态可以恢复。Kafka Streams可以很好地处理这一点,本地状态使用嵌入式的RocksDB存储在内存中,它还可以将数据持久化到磁盘,以便在重启后快速恢复。但是对本地状态的所有更改也被发送到一个kafka的topic。如果流节点宕机,则不会丢失本地状态,可以通过重写读入事件轻松地重新创建kafka的topic,例如,如果本地状态包含当前IBM=167.9的这个最小值。我们将其存储在kafka中,以便稍后我们可以从该数据重写填充到本地缓存。kafka对这些topic使用日志压缩来实现。
- Rebalancing 重平衡 分区有时会被重写分配给不同的消费者,当这种情况发生的时候,丢失分区的实例必须存储最后的良好状态,而接收分区的实例必须知道恢复正确的状态。
流处理框架在帮助开发人员管理所需的本地状态方面存在差异,如果你的应用程序需要维护本地状态。请确保检查框架及其保证。我们讲在本质的最后提供一个简短的比较指南。但是我们都知道,软件变化很快,流处理框架更是如此。
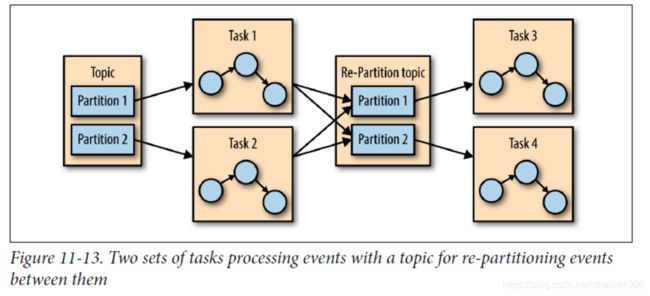
Multiphase Processing/Repartitioning 多路处理/重新分区
如果你需要按聚合类型分组,那么本地状态是非常好的。但是如果你需要一个使用所有可用信息的结果呢?例如,假设我们想从公布的每天排名前十的股票,在每天的交易中从开盘到收盘获利最多的10只股票。显然,我们在每个应用程序实例上做的任何本地操作都是不够的,因为排名前10的股票都可能位于分配给其他实例的分区中。我们需要的是两阶段方法。首先,我们计算每个股票代号和每日的收益,我们可以对每个具有本地状态的实例执行此操作。然后我们将结果写入一个带有单个分区的新的topic中。单个应用程序实例将读取该分区,然后可以找到当天前10个股票。第二个topic包含的每个股票的代码的每日摘要。显然比包含交易本身的topic小得多。流量也少得多。因此它可以由应用程序的单个实例处理。有时候需要采取更多的步骤来产生结果:

对于哪些编写map-reduce代码的人来说,这种多阶段处理是非常熟悉的,这种情况下,你常常不得不求助于多个reduce阶段,如果你曾经编写过map-reduce代码,你就会记得每个reduce步骤都需要一个单独的应用程序,与MapReduce不同的是,大多数流处理框架允许在要给应用程序中包含的所有步骤,框架处理哪个应用程序实例或工作程序将运行实现的步骤。
Processing with External Lookup: Stream-Table Join 处理外部查找:流表连接操作
有时流处理需要与外部的数据集成,根据存储在数据库中的一组规则验证事务。或者使用关于点击用户的数据丰富点击流信息。
关于如何执行外部查找来丰富数据的想法是这样的,对于流中的每个点击事件,在配置文件数据库中查找用户,并编写一个事件,齐庄公包括原始的点击加上用户的年龄、性别到另外要给topic。如下图:

这个明显的想法的问题是,外部查找每个记录的处理增加了很大的延迟,通常在5ms-15ms之间,在许多情况下,这是不可行的。通常外部数据存储上的额外负载也是不可接收的,流处理系统通常每秒处理100-500k事件,但是数据库在合理的性能下每秒只能处理10K事件。我们想要一个可伸缩性更好的解决方案。
为了获得良好的性能和伸缩性。我们需要在流处理应用程序中缓存来自数据库的信息。然而,管理这个缓存是一项挑战。如何防止缓存中的信息过期?如果我们过于频繁地刷新事件,我们仍然在敲打数据库,缓存也没有多大帮助。如果我们等太久来获取新事件,我们就会对陈旧的信息进行流处理。
但是,如果我们能够捕获事件流中发生在数据库表上的所有更改,我们就可以让流处理作业监听该流,并基于数据库更改事件更新缓存。将对数据库的更改捕获为流中的事件称为CDC,如果你使用kafka connect,你将发现多个连接器能够执行CDX并将数据库转换为更改的事件流。这允许你保留自己的表的私有副本,并且当发生数据更改事件时,你将得到通知,以便相应的更改自己的副本。

然后,当你获得单击事件时,你可以在本地缓存中查找user_id,并丰富该事件。而且因为使用的是本地缓存,所以伸缩性更好,不会影响数据库和其他使用它的应用程序。
我们将其称为流表连接,因为其中一个流表示对本地缓存的更改。
Streaming Join 流连接
有时候,你希望连接两个真实的事件流,而不是一个流和表连接。是什么让流变得真实呢?如果你还记得本章开始讨论的部分,流是无限的,当你使用要给流来表示一个表的时候,你可以忽略流中的大部分历史数据,因为你只关系表中的当前状态。但是,当你视图连接两个流的时候,你就需要关心整个历史数据。视图将一个流中的事件与另外要给流中具有相同key并在相同时间窗口发生的事件匹配。这就是为什么流连接也称为窗口连接。
例如,假定我们有一个流包含了人们输入到我们的网站的搜索查询。另外要给流包含点击事件。包括对搜索结果的点击。我们希望将搜索查询与他们点击的结果相匹配,这样我们就可以知道哪个查询结果最受欢迎。显然,我们希望根据搜索词匹配结果,但是旨在一定的时间窗口内匹配。我们假设在查询呗输入到搜索引擎之后的几秒就点击了结果,因此,我们在每个流上保持一个数秒长的小窗口。并匹配来自每个窗口的结果。
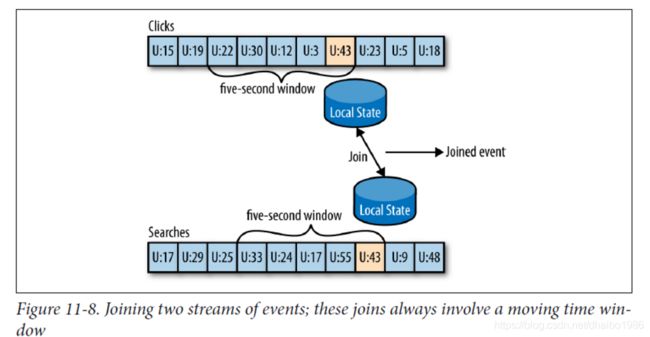
这在kafka流中的工作方式就是,两个流,查询和点击,在相同的key上分区,也是连接的key。这样,来自user_id:42的所有单击事件将在单击topic的分区5中结束。然后kafka流确保这两个topic的分区5呗分配到相同的任务。因此这两个任务看到user_id:42的所有相关事件。它在其嵌入的RocksDB缓存中维护了两个topic的连接窗口,这就是它执行的连接方式。
Out-of-Sequence Events 按顺序事件
处理在错误的时间到达流的事件不仅是流处理的挑战,在传统的ETL系统中也是如此。无序事件在物联网场景中经常发生。例如,要给移动设备丢失WIFI信号几个小时,并在重写连接时发送了几个小时的事件,这种情况也会发生在监控网络设备中(有故障的交换机直到修好后才会发送诊断信号)或者制造业(工程的网络连接是出了名的不可靠,尤其是在发展中国家)。

我们的流式应用程序能够处理这些场景,这通常意味着应用程序必须做以下工作:
- 认识到事件不是按顺序的,这就要求应用程序检查事件的时间并发现它比当前的时间早。
- 定义一个时间段,在此期间它将尝试协调顺序混乱的事件,也许三个小时的延迟应该和解,三州多的事件可以扔掉。
- 具有协调此事件的带内能力,这是流媒体应用程序和批处理作业之间的主要区别。如果我们有一个每天的批处理作业,并且在作业完成之后到达了一些事件,我们通常可以重写允许昨天的作业并更新事件,使用流处理,就不会出现重写允许昨天的作业。相同的连续的过程需要在任何给定时刻处理新旧事件。
- 能够更新结果,如果流处理的结果被写入数据库,一个put或者update就足以更新结果,如果流应用程序通过电子邮件发送结果,更新结果可能会比较麻烦。
一些流处理框架,包括google的Dataflow和kafka流,内置了独立于处理时间的事件时间概念的支持,并且能够处理事件时间比当前处理时间早或者晚的事件。这通常是通过在本地状态中维护多个可用于更新的聚合窗口,并让开发人员能够匹配这些窗口枯涸可用于更新的时间。当然,聚合窗口用于更新的时间越长,维护本地状态所需的内存就越多。
kafka的StreamsAPI总是将聚合结果写入一个结果的topic,这些通常是压缩的topic,这意味着只保留每个key的最新值。如果一个聚合窗口的结果需要由一个延迟事件而更新,Kafka流将简单的为这个聚合窗口编写一个新的结果,它讲覆盖之前的结果。
Reprocessing 再处理
最后一个重要的模式是处理事件的模式,这种模式有两个变体。
- 我们有一个流处理应用程序的改进版本,我们相上允许应用程序的新版本相同的事件流,产生一个新的源源不断的结果替换第一个版本,两个版本之间的比较结果,在某种程度上移动客户使用新的而不是现有的结果。
- 现有的流处理应用程序有很多BUG,我们修复了错误,并希望重新处理流处理程序并重新计算结果。
第一个用例很简单,因为ApacheKafka将事件流长时间完整的存储在要给可伸缩的数据存储中,这意味着,有两个版本的流处理应用程序编写两个结果流只需要以下条件:
- 将应用程序的新版本转化为一个新的消费者组。
- 配置新版本,从输入的topic的第一个offset开始处理,这样它将获得输入流中所有事件自己的副本。
- 让新的应用程序继续处理,并在处理作业的新版本完成的时候将客户机应用程序切换到新的结果流。
第二个用例更具有挑战性,他需要重置现有的应用程序,以便在输入流开始处开始处理,重置本地状态。所以我们不会混合来自两个版本的应用程序的结果。可能还会清理之前的输出流。尽管kafka Stream有了一个为处理流应用程序重置状态的工具。我们的建议是尝试使用第一种方法,只要有两个结果流,第一种方法要安全得多。它允许在多个版本之间来回切换。并比较版本之间的结果,而且不会再清理过程中丢失关键数据或者引入错误。
Kafka Streams by Example kafka流处理例子
为了演示这些模式是如何再实践中实现的,我们将用ApacheKafka的Streams API展示几个示例。我们之所以使用这个特定的API,是因为它使用起来相对简单,而且塔斯由ApacheKafka附带的,你已经可以访问它了。重要的是要记住,模式可以再任何流处理框架和库中实现,模式是通用的,但是示例是特定的。
ApacheKafka有两种流APi,低级别的处理API和高级别的DSL。我们将在示例中使用Kafka的Streams DSL。DSL允许你通过定义流中的事件转换链接来定义流处理的应用程序,转换可以像过滤器那样简单,也可以像流到流连接那样复杂。低级别的API允许你自己创建自己的转换。正如你看到的,这很少是必须的。
使用DSL API的应用程序总是首先使用StreamBuilder创建处理的拓扑,以用于流中的事件的转换的的有向无环图DAG。然后根据拓扑创建一个KafkaStreams的执行对象,启动kafkaStreams对象将启动多个线程。每个线程池处理拓扑应用于流中的事件。当你关闭kafkaStreams对象时,处理将结束。
我们将看到几个使用kafka流来实现我们刚才讨论的一些设计模式的例子,将使用一个简单的单词计数示例来演示map/filter模式和简单的聚合。然我我们将转到一个计算股票市场交易的不同统计数据的例子中,浙江允许我们演示窗口聚合。最后,我们将使用ClickStreams Enrichment 作为示例来源演示流连接。
Word Count 单词统计
让我们看看Kafka流处理的一个简短的单词统计计数示例。你可以在github上找到完整的例子。
创建流处理应用程序时需要做的第一件事是配置kafka流。kafka流有很多可能的配置。我们不会再这里讨论,但是你可以再文档中找到它们。此外,你还可以通过添加任何生产者和消费者配置到属性对象来配置嵌入再kafka流中的生产者和消费者。
public class WordCountExample {
public static void main(String[] args) throws Exception{
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG,
"wordcount");//1
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092");//2
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());//3
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());
- 每个kafka的Streams应用程序都必须有一个应用程序ID,这个ID用于协调应用程序实例,也用于命名内部存储以及它们相关的Topic。每个名称必须是唯一的kafka流应用程序与相同的kafka集群一起工作。
- kafka Streams的应用程序总是从kafka的topic读取数据,并将其输出写入到kafka的topic中,正如我们稍后将讨论的,kafka流应用程序也使用kafka的协调器。所以我们最好告诉我们的应用程序在哪可以找到kafka。
- 当读取和写入数据时,我们的应用程序将需要的序列化和反序列化,因此我们提供默认的Serde类,我们可以在稍后构建拓扑的时候覆盖这些默认值。
现在我们有了配置之后,我们开始构建我们流的拓扑。
KStreamBuilder builder = new KStreamBuilder();//1
KStream source =
builder.stream("wordcount-input");
final Pattern pattern = Pattern.compile("\\W+");
KStream counts = source.flatMapValues(value->
Arrays.asList(pattern.split(value.toLowerCase())))//2
.map((key, value) -> new KeyValue(value, value))
.filter((key, value) -> (!value.equals("the")))//3
.groupByKey()//4
.count("CountStore").mapValues(value->
Long.toString(value)).toStream();//5
counts.to("wordcount-output");//6
1.我们创建一个KStreamBuilder对象,并通过指向我们将用作输入的topic来定义流。
2.每个事件我们从源topic读到的都是一行字,我们是员工正则表达式将其拆分为一些列单独的单词,然后我们取每一个单词(当前事件记录的值)并将其放在事件记录的key中,以便可以在按组操作中使用。
3.我们过滤掉the这个词,只是为了显示过滤是多么容易的。
4.我们按key分组,所以我们现在的一个针对每个唯一单词的事件的集合。
5.我们计算每个集合中有多少事件,计数的结果为a长时间的数据类型,我们将其转换为字符串,这样让人更容易阅读结果。
6.只剩下一件事情,把结果回写kafka
现在我们已经定义了应用程序将要允许的转换流,我们只需要:
KafkaStreams streams = new KafkaStreams(builder, props);//1
streams.start();//2
// usually the stream application would be running
forever,
// in this example we just let it run for some time and
stop since the input data is finite.
Thread.sleep(5000L);
streams.close();//3
}
}
1.基于我们的拓扑和我们定义的属性定义了一个kafkaStreams对象。
2.开始流计算;
3.一段时间之后,停止它。
这就是它!在短短几行代码中,我们演示了实现单个事件处理模式是多么的容易,我们对事件应用了映射和过滤器。我们通过添加要给group-by操作符对数据进行了重新分区,然后在计算将每个单词作为key的记录数量时维护简单的本地状态,然后我们在计算每个单词出现的次数时维护简单的本地状态。
此时,我们建议允许完整的示例,GitHub存储库中的自述文件包含关于如何允许示例的说明。
你将注意到的一件事情就是,你可以在机器上允许整个示例,而不需要安装Apache Kafka以外的任何东西。这与你在类似于本地模式下使用spark看到的体验类似。主要的区别在于,如果你输入的topic包含多个分区,那么你可以允许的wordCount应用程序的多个实例(只需要在几个不同的中断选项中允许该应用程序)并且你又抵押给kafka Streams processing集群的实例的wordCount应用程序相互协调工作。使用spark的一个最大的障碍就是本地模式非常容易使用,但是要运行一个生产集群,你需要安装YARN或者MESOMS,之后再再这些机器上安装Spark,然后学校如何向集群提交你的应用程序。kafka 的Streams API,只需要启动应用程序的多个实例,就有一个集群。在你的开发机器和生产环节中运行的是完全相同的应用程序。
Stock Market Statistics 股票市场统计数据
下一个示例更加复杂–我们将读取一个股票交易的事件流,其中包括股票行情,单价和数量大小。再股票交易中,卖出价是卖方要求的价格,而买入价是买方建议的支付价格。询问规模是指卖方愿意以这个价格出售的股票数量,为了简单起见,我们完全忽略出价,我们也不会再数据中包含时间戳,相反,我们将依赖于由kafka生产者填充的事件时间。
然后我们将创建输出流,其中包含一些窗口统计:
- 每五秒最好的的要价
- 每五秒的交易数
- 每五秒的平均价格
所有的统计信息将以每秒更新一次。
为了简单起见,我们假设我们的加以所只有10各股票报价机在交易,设置和配置非常类似于我们在第256页的单词计数。
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stockstat");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
Constants.BROKER);
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,
TradeSerde.class.getName());
主要的区别在于使用的Serde类。在之前的单词统计中,我们对key和value都使用了字符串。因此使用了serdes.string()作为两者序列化和反序列化的类。在本例中,key任然是一个字符串,但是是一个交易对象,其中包括股票代码,询问价格和询问大小,为了序列化和反序列化这个对象,以及我们在这个小引用程序中使用其他的一些对象,我们使用google的Gson库从我们的java对象生成一个Json序列化和反序列化器。然后创建一个小的包装类,该包装类从这些对象创建一个Serde对象。这是我们如何创建Serde:
static public final class TradeSerde extends WrapperSerde {
public TradeSerde() {
super(new JsonSerializer(),
new JsonDeserializer(Trade.class));
}
}
这没有什么特别之处,但是你需要记住为你想要存储在kafka中每个对象提供一个Serde对象。输入、输出,在某些情况下,还有中间结果。为了使这些更容易,我们建议通过像GSon,Avor、ProtoBufs或者类似的项目生成这些Serdes。
现在我们已经配置好了一切,是时候构建我们的拓扑了:
KStream stats = source.groupByKey()//1
.aggregate(TradeStats::new,//2
(k, v, tradestats) -> tradestats.add(v),//3
TimeWindows.of(5000).advanceBy(1000),//4
new TradeStatsSerde(),//5
"trade-stats-store")//6
.toStream((key, value) -> new TickerWindow(key.key(),
key.window().start()))//7
.mapValues((trade) -> trade.computeAvgPrice());//8
stats.to(new TickerWindowSerde(), new TradeStatsSerde(),
"stockstats-output");//9
- 1.我们首先从输入的topic读取事件并之下groupByKey操作,尽管它的名字,这个操作不做任何分组。相反,它确保基于记录key对象事件流进行分区。由于我们将数据写入带有key的topic中,并且在调用groupByKey之前没有修改key,所以数据任然是按key分区的,因此在本例中此方法不执行任何操作。
- 2.在确保分区正确之后,我们启动窗口聚合的聚合方法将流分隔成重叠的窗口,然后对窗口中的所有事件应用聚合方法。该方法接收第一个参数是一个新对象,在我矛盾例子中,该对象包括Tradestats的聚合数据。这是我们创建的一个对象,用于包含我们对每个时间窗口感兴趣的所有统计信息,最低价格,平均价格和交易数量。
- 3.然后我们提供了一个实际聚合记录的方法,在本例中,使用Tradestats对象的添加记录方法更新窗口中的最小价格,交易数量和总价格,并用最新记录。
- 4.我们定义窗口,在本例中,窗口为5秒,每秒前进一次。
- 5.我们提供一个Serde对象来序列化和反序列化聚合结果,Tradestats对象。
- 6.正如前文提到,窗口聚合需要维护一个状态和一个将在其中维护状态的本地存储。聚合方法最后一个参数是状态存储的名称。可以是任何唯一的名称。
- 7.聚合结果是要给表,其中以计时器和时间窗口为key,聚合结果为value。我们正在将表转换为事件流。并包含整个时间窗口定义的key替换我们自己的key,该key只包含计时器和窗口的开始时间。这个toStream方法将表转换为流。还将key转换为TickerWindow对象。
- 8.最后一步是更新平均价格,现在汇总的这些结果包括价格的交易数量的综合。我们查看这些记录并使用现有的统计数据来计算平均价格,这样就可以将其包含在输出流中。
- 9.最后,我们将结果雪茹到stockstats-output流。
在定义流之后,我们使用它生成了一个kafkaStreams对象并运行它,就像我们之前单词统计中所做的那样。
这个示例展示了如何在流上执行窗口聚合,可能是流处理最流行的用例。需要注意的一件事是,维护聚合的本地状态所需的工作非常少。只需要提供要给Serde并命名存储,然后,这个应用程序将扩展到多个实例,并通过将某些分区的处理转移到一个可用的实例,自动从每个实例中故障恢复。
与之前一样,你可以在github上找到完整的示例,包括它的说明。
Click Stream Enrichment
最后一个例子将通过丰富的网站上的点击流来演示流式连接。我们将生成的模拟点击流,虚拟配置文件数据库表的更新流和web搜索流。我们将这三个流连接来获得对每个用户活动的360度视图。用户搜索什么,他们的点击结果是什么,他们是否改变了用户档案中的兴趣标签?则需类型的连接作为分析提供了丰富的数据采集。产品推荐常常基于这类信息,用户搜索自行车,点击trek的连接,以及对旅行感兴趣,所以我们可以为从trek,头盔到旅游景点等进行广告投放。
由于配置应用程序类似于前面的例子,让我们跳过这部分,看看加入更多流的拓扑:
KStream views =
builder.stream(Serdes.Integer(),
new PageViewSerde(), Constants.PAGE_VIEW_TOPIC);//1
KStream searches =
builder.stream(Serdes.Integer(), new SearchSerde(),
Constants.SEARCH_TOPIC);//2
KTable profiles =
builder.table(Serdes.Integer(), new ProfileSerde(),
Constants.USER_PROFILE_TOPIC, "profile-store");
KStream viewsWithProfile = views.leftJoin(profiles,//3
(page, profile) -> new UserActivity(profile.getUserID(),
profile.getUserName(), profile.getZipcode(),
profile.getInterests(), "", page.getPage()));//4
KStream userActivityKStream =
viewsWithProfile.leftJoin(searches,//5
(userActivity, search) ->
userActivity.updateSearch(search.getSearchTerms()),//6
JoinWindows.of(1000), Serdes.Integer(),
new UserActivitySerde(), new SearchSerde());//7
- 1.首先,为我们想要连接点击和搜索的两个流创建要给streams对象。
- 2.我们海为用户配置文件定义一个KTable。KTable是通过更改流更新本地缓存。
- 3.然后,我们通过将事件流于概要表连接起来,用户的概要信息丰富单击流。在流标连接中,流中的每个事件从概要标的缓存副本中接收信息,我们正在机械能左连接,因此没有已知用户的情况下单击将保留。
- 4.这就是join方法,他获取两个值,一个来自流,一个来自记录,然后返回第三个值。与数据库不同,你需要决定如何将这两个值组合为要给结果,在本例中,我们创建了一个活动对象,其中包含用户详细信息和查看的页面。
- 5.接下来,我们细羽将单击信息与同一用户执行的搜索连接起来,这任然是一个做连接。但是现在我们连接的是两个流,而不是一个表和一个流。
- 6.这就是join方法,我们只需要将搜索的词添加到所匹配的页视图中。
- 7.这是最有趣的部分,流到流的连接时要给带有时间窗口的连接。为每个用户加入所有的点击和搜索都没有多大的意义,我们希望用与之相关的点击来加入每个搜索。也就是说,在搜索之后很短一段时间内发送的点击。我们定义一个1秒的连接窗口。在搜索一秒内发送的单击呗认为是相关的。并且搜索词将包含在包含单击和用户配置文件的活动记录中。这将允许对搜索及其结果进行全面分析。
在定义流之后,我们用它生成一个kafkaStreams对象并运行它。就像我们之前的单词统计那样。
这个例子展示了流处理中可能出现的两种不同的连接模式。将流与表连接起来,可以用表中的信息丰富所有的流事件。这类似于在数据仓库上运行查询时间将事实表与维度连接起来,第二个示例基于一个时间窗口连接两个流。这个操作是流处理所特有的。
与之前一样,你可以在github上找到完整的示例。
Kafka Streams: Architecture Overview kafka流架构概述
上一节的示例中演示了如何使用kafka流API来实现一些著名的流处理设计模式。但是为了更好的理解kafka的流库实际上是如何工作和扩展的,我们需要窥探其背后,并理解API之后的一些设计原则。
Building a Topology 建立一个拓扑
每个streams应用程序实现和执行至少一个拓扑。拓扑结构在其他流处理框架中也称为DAG,或者有向无环图。是每个事件从输入移动到输出的一组操作和转换。下图展示了单词统计中的拓扑:
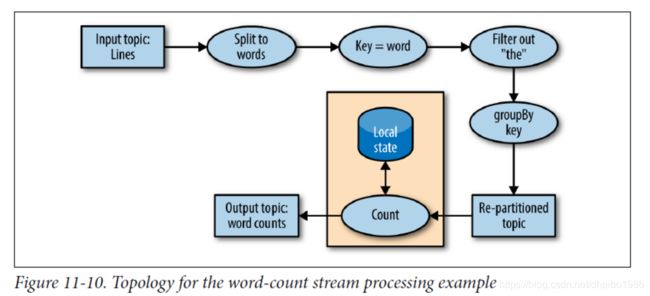
即使一个简单的应用程序,也具有非凡的拓扑结构,拓扑是由处理器组成的,他们是拓扑图中的节点,大多数处理器实现数据筛选,映射,聚合等操作,还有源处理器,使用来自topic的数据并将其传递和接收的处理器。接收来自早期处理器的数据并将其生成到主题。拓扑总是以一个或者多个源处理器开始,以一个或者多个接收处理器结束。
Scaling the Topology 扩展拓扑
kafka流运行在应用程序的一个实例中执行多个线程,并且支持应用程序的分布式实例之间的负载均衡。你可以在一台机器上运行Streams应用程序与多个线程或者在多台机器上执行。这两种情况下,应用程序中的所有活动线程都将平衡涉及数据处理工作。
Streams引擎通过将拓扑分解为任务来并行执行。任务的数量是由流引擎决定的,并取决于应用程序处理的主题中的分区数量。每个任务负责分区的一个子集,该任务将订阅这些分区并使用其中的事件,对他消耗每个事件,该任务在最终将结果写入接收器之前,将按顺序执行应用于此分区的所有处理步骤。这些任务是kafka流并行性的基本单位。因为每个任务都可以独立执行。
如下图:

应用程序的开发人员可以选择每个应用程序的实例将执行的线程数。如果有多个线程可用。每个线程将执行的应用程序创建的任务的一个子集。如果该用于程序的多个实例在多个服务器上运行。那么每个服务器上的每个线程将执行不同的任务。这事流式应用程序扩展的方式,在你处理的topic中,有多少个分区,你就有多少个任务。如果你想要更快的进程,添加更多的线程。如果服务器上资源耗尽,则在另外一台服务器上启动该应用程序的另外一个实例。kafka将自动协调工作。将独立处理来自这些分区的事件。并在拓扑需要的时候使用相关的聚合维护子集的本地状态。

你可能已经注意到,有时候一个处理步骤可能需要来自多个分区的处理结果。这可能会在任务之间创建依赖关系。例如,我们在连接连个流,就像前面点击流例子中的那样。我们需要从每个流的一个分区中获得数据,然后才能发出结果。kafka流通过将一个连接所需要的所有分区分配给同一个任务来处理这种情况,这样任务就可以使用所有相关的分区,并独立地执行连接,这就是为什么kafka的流目前要求所有参与来凝结操作的topic都有相同数量的分区。并基于key进行分区。
任务之间的依赖关系的另外要给例子是应用程序需要重新分区时,丽日,在clickStream示例中,所有的事件都是由用户的ID生成的,但是如果我们像为每个页面生成统计信息呢?还是按邮政编码?我们需要按邮政编码对数据进行重新分区,并使用新分区对数据进行聚合。如果task1处理来自分区1的数据,并到达重新对数据进行分区的处理器执行group By擦着,那么它将需要进行shuffle操作,这意味着将事件发送给他们,将事件发送给其他的任务来处理。
与其他的流处理框架不同,kafka流通过将事件写入要给带有新key的分区的新topic来进行重新分区,然后,另外一组任务重从新的topic中读取事件并继续处理,重新划分步骤将拓扑分解为两个子拓扑,每个子拓扑都有自己的任务,第二组任务依赖于第一组任务,因为它处理第一个子拓扑的结果。然而,第一组和第二组任务任然可以独立并行的运行,因为第一组任务以自己的速度将数据写入topic,而第二组任务用topic并自己处理事件,任务之间不存在通信和共享资源问题。他们不需要相同的线程或在相同的服务器上运行。这事kafka做的更有用的事情之一,减少管道不同部分之间的依赖关系。
Surviving Failures 故障幸存
运行我们扩展引用程序的模型也运行我们优雅地处理失败,首先,akfak是高可用的,因此我们持久化的数据是可用的,kafka具有高可用性,因此,如果应用程序失败并需要重新启动,它可以从kafka中查找它在流中最后的位置,并从失败前提交的最后一个offset继续处理,注意,如果本地存储状态丢失了,Streams应用程序总是可以从它在kafka中存储的更改日志中共重新创建它。
kafka流还利用kafka的用户协调为任务提供高可用性,如果任务失败,但有线程或Streams用于程序的其他实例处于活动状态,则任务将在要给可用的线程上重新启动,这类似于消费者通过将分区分配给剩余消费者之一来处理组中某个消费者的故障。
Stream Processing Use Cases 流处理用例
在这一章中,我们学习了如何进行流处理,从一半的概念和模式到kafak流处理中的具体例子,在这一点上,看看处理用例的公共流可能是值得的,正如本章开头所解释的,流处理或连续处理,在你希望快速处理事件而不是等待数小时直到下一批处理的情况下分成有用,而且在你不希望想要以毫秒为单位的到达情况下也非常有用,这些都是真的,也很抽象,我们来看一些实际情况。
-
Customer Service 客户服务
假设你刚刚在一家大型酒店预订了一个房间,你希望收到电子邮件确认和收据。预定几分钟后,你还没收到,你打电话给客服确认你的预定。假设客服概诉你,我在系统中没有看到你的订单。但是将数据从预定系统加载到酒店的批处理系统和客户服务台每天只运行一次,所以请明天回电话。你应该在2-3个工作日看到邮件。这样的话听起来就不像要给很好的服务了,但是我已经有了数次这样的经历。我们真正想要的是,酒店连锁中的每个系统在预定完成之后的几秒或者几分钟都能更新订单信息,包括客户服务中心,酒店,发送确认的邮件系统,网站等。你还希望客户服务中心能够立即打开所有细节关于你去过的任何连锁酒店,在酒店的前台,知道你是要给忠诚的客户,那么将给你进行一个服务升级。有了这样一个系统,我们将在几分钟内收到确认邮件,我都信用卡会及时呗扣款,收据将会被及时发送,服务台会立即回答我们的预定信息。 -
Internet of Things 物联网
物联网可以意味着很多东西,从调节温度和订购洗衣粉的家用设备到只要生产的实时质量控制,将流处理应用于传感器设备时,一个非常常见的用例是尝试预测合适需要进行预防性维护。这类似于应用程序监视,但应用于硬件,在许多行业中很常见,包括制造业,电信业,有线电视等等。每种业务都有自己的模式,但是目标都是相似的,处理来自设备的事件和识别标识着一个设备需要维护的模式,这些指标可以为开关丢包,在制造过程中需要更多的力量来拧紧螺丝,或者用户为电缆更频繁的重启电视的盒子。 -
Fraud Detection 欺诈识别
也称为异常检测,是一个非常广泛的应用领域,主要关注于捕捉系统中的作弊者或者不良参与者。欺诈检测应用程序的例子包括检测信用卡欺诈、股票交易欺诈,视频游戏欺诈等网络安全风险,在所有的这些领域中,最好尽早对欺诈进行识别,所以近实时的系统能够对事件进行quickly-perhaps 停止一个糟糕的交易之前,可能导致这个交易被通过。这比在时候三天才来检测的批处理作业更可取。因为清理工作要复杂得多。这事要给在大规模事件中识别模式的问题。
在网络安全领域,有一种方法被称为信标,当黑客在组织内部植入恶意软件时,它偶尔向外部获取命令。这种活动可能在任何时间,任何频率发生,因此很难检测。通常情况下,网络能够跟好的抵御外部攻击,但是更容易受到内部人员的攻击。通过处理大量的网络连接的事件流,并将通信模式识别为异常。如,检测主机通常不访问哪些特定问题。可以得到更早的警报。
How to Choose a Stream-Processing Framework 如何选择流计算框架
在选择流处理框架时,最重要的是需要考虑你计划编写的程序的类型。不同类型的应用程序需要不同的流处理解决方案。
- Ingest 提取,其目标是将数据从一个系统获取到另外一个系统,并对数据进行一些修改,以使其符合目标系统。
- Low milliseconds actions 低延迟,几乎需要及时响应的任何应用程序,一些欺诈检测用例属于这个范围。
- Asynchronous microservices 异步微服务,这些微服务代表较大的业务流程执行的一个简单的操作,比如更新商店的库存。这些一女婴程序可能需要维护本地状态缓存事件,以提高性能。
- Near real-time data analytics 准实时分析,这些流应用程序执行复杂的聚合和连接,以分隔数据并生产有趣的与业务相关的见解。
你将选择的流处理系统在很大程度上取决于你要解决的问题。
- 如果你正在尝试解决一个摄入问题,那么你应该重新考虑是要一个流处理系统,还是像kafka这样更简单的以摄入为中心的系统连接,如果你缺点你需要一个流处理系统,那么你需要确保它为你的目标系统提供了良好的连接器和高质量的连接器。
- 如果你试图解决一个低延时的问题,你还应该重新考虑你对流的选择,请求响应模式通常更适合此任务。如果你确定需要流处理的系统,那么你需要选择支持低延迟模型的系统,而不是侧重于微批次的系统。
- 如果你正在构建一个异步的微服务,你需要一个流处理系统集成与你选择的消息总线。kafka,改变捕获的功能,轻松实现上游微服务本地缓存的变化,和有良好的支持可以作为缓存的本地存储或者微服务物化视图的数据。
- 如果你正在构建一个复杂的分析引擎,那么你还需要一个流处理系统,该系统对本地存储有强大的支持,这一次,不是为了维护本地缓存和物化视图,而是为了支持高级的聚合,窗口和连接。否则这些就很难实现。这些API应该包括对自定义聚合窗口操作和多种连接的支持。
除了用例的具体考虑之外,还有一些你应该考虑的全局因素: - Operability of the system 系统可操作性。它是易于部署到生产环境中吗,监控和故障是否容易,他能很好地与你现有的基础设施集成吗?如果出现错误,需要对数据进行再处理,应该怎么办?
- Usability of APIs and ease of debugging API可用性和易于调试。 我发现,在同一框架下的不同版本中,编写高质量应用程序所花费的时间有数量级的差异,并发时间和投方时差的时间很重要,因此你需要选择使你更高效的系统。
- Makes hard things easy 使困难变得容易。几乎每个系统都声称可以做到高级的窗口聚合和维护本地缓存,但问题在于:他们让你更容易吗?他们是处理有关规模和恢复的细节,还是提供泄漏的抽象?让你处理大部分混乱?系统越是公开干净的a’pi和抽象,越是独立地处理细节,开发人员的工作效率就越高。
- Community 社区。你考虑的大多数流处理应用程序都是开源的,没有什么可以替代充满活力的活跃社区,良好的社区意味着你可以定期获得令人兴奋的新特性,质量相对较号,没有人希望在坏的软件上工作。big可以迅速修复,用户的问题可以及时得到解答,这也意味着,如果你得到一个奇怪的错误,并google搜素,你将看到有关它的信息,,因为其他人正在使用这个系统,并看到相同的问题。
Summary 总结
我们在本章开始时解释了流处理,我们给出一个正式的定义,并讨论了流处理范式的常见属性。我们还将其他与编程范例进行了比较。
然后我们讨论了重要的流处理概念,通过使用kafka流编写的三个示例应用程序演示这些概念。
在浏览了这些示例应用程序的所有细节之后,我们给出了kafka Streans架构的概述,并解释了它时如何在幕后工作的,我们用流处理用例和关于如何比较不同流处理框架的建议来结束本章和本书。