Python爬虫实战——爬取猫眼TOP100电影信息
Python爬虫实战——爬取猫眼TOP100电影信息
这次的目标是提取出电影的电影名称、时间、评分和图片等信息。
1、打开猫眼电影网站,分析该网站
首先分析网站首页的URL=‘http://maoyan.com/board/4?offset=0’
显示的是TOP1~10的电影排行情况
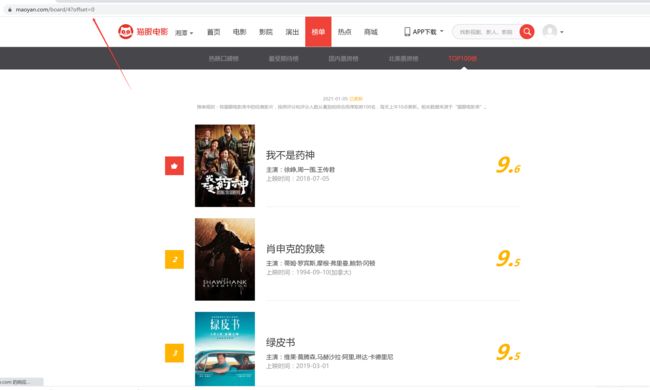
继续打开第二页的时候发现,显示的是TOP11~20的电影排行情况
同时页面的URL变成了URL=‘http://maoyan.com/board/4?offset=10’

由此,我们初步分析可以得知,offset即代表的是偏移量,offset=0显示的是排名1到10的电影,offset=10显示的是排名11到20,offset=n显示的是排名n+1到n+10的电影。
2、首先抓取猫眼电影首页
首先导入requests库,打开猫眼电影首页的开发者模式,在Network中观察我们的User-Agent。
前面有提过,我们需要模仿客户端向服务器发送请求,传递信息给服务器让服务器认为我们是浏览器而不是爬虫,就要用到伪装,即传递我们的User-Agent信息,将其复制下来。

import requests
def get_one_page(url):# url='http://maoyan.com/board/4?offset=0'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:#200是我们的响应状态码,代表服务器成功处理请求
return response.text#返回响应体即html代码
return None
运行代码,观察:

3、使用正则表达式提取我们所需要的信息
首先观察其中一部电影信息所对应的源代码,进行分析。
例如《肖申克的救赎》这部电影,这部电影的所有信息包括主演、上映时间、电影名等等,都包括在dd和/dd这两个标签之内。

其中排名信息是在class为board-index的i节点内,排名信息提取的正则表达式为:

随后提取电影的图片。可以看到,后面的a节点内有两个img节点。经过检查后发现第二个img节点的data-src属性是图片的链接,正则表达式改为:

再往后,提取电影的名称,它在后面的p节点内,class为name。所以,可以用name做一个标志位,然后进一步提取到其内a节点的正文内容,此时正则表达式改为:
 (.*?)" width="650" height="64">
(.*?)" width="650" height="64">
以同样的方法提取主演,发布时间、评分等,最终正则表达式为:
 (.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*?" width="650" height="60">
(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*?" width="650" height="60"> 此时,我们定义一个函数parse_one_page( ),试着提取猫眼电影排行首页中我们想要的内容,同时别忘记导入re库。
def parse_one_page(html):
pattern = re.compile(
'.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*? ',re.S)
items = re.findall(pattern, html)
print(items)

数据太过于杂乱,所以我们试着更改一下输出的方式:遍历提取的结果并生成字典。
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.
*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:] if len(item[4]) > 5 else '',
'score': item[5].strip() + item[6].strip()python
}

4、提取完成后,写入文件
我们将提取的结果写入一个文本文件当中去(.txt)。这里通过JSON库(别忘记导入JSON库)的dumps( )方法实现字典的序列化,并制定ensure_ascii的参数为False,这样可以保证输出结果是中文形式而不是Unicode编码。
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f :
print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False)+'\n')
5、整合代码
用一个函数main( )来调用前面实现的方法,整个逻辑就会非常清晰。
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
6、最后爬取所有页面的电影信息,并且写入文件
这里就可以用到我们一开始分析的内容。利用offset偏移量的改变,来遍历不同网站,在这个过程中提取信息写入文件。
一共十个页面,也就是遍历十次。每遍历一次,URL后的offset偏移量每增加10,以字符串的形式更改在前一次的URL的offset处。
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):# 一共遍历十次
main(offset=i * 10)# 每次遍历都调用整合的函数main(offset),每遍历一次offset都加10
最后结果呈现:
其中代码最后的time.sleep(1),是猫眼现在多了反爬,所以这里又增加了一个延时等待,需要导入time库。