Python分布式爬虫详解(三)

数据科学俱乐部
中国数据科学家社区

上一章中,利用scrapy-redis做了一个简单的分布式爬虫,虽然很一般(只有30个请求)但是基本能说清楚原理,本章中,将对该项目进行升级,使其成为一个完整的分布式爬虫项目。
Python分布式爬虫详解(一)
Python分布式爬虫详解(二)
本章知识点:
a.代理ip的使用
b.Master端代码编写
c.数据转存到mysql
一、使用代理ip
在 中,介绍了ip代理池的获取方式,那么获取到这些ip代理后如何使用呢?
首先,在setting.py文件中创建USER_AGENTS和PROXIES两个列表:
USER_AGENTS = [
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36'
]
PROXIES = [
{
'ip_port': '118.190.95.43:9001', "user_passwd": None},
{
'ip_port': '61.135.217.7:80', "user_passwd": None},
{
'ip_port': '118.190.95.35:9001', "user_passwd": None},
]
我们知道,下载中间件是介于Scrapy的request/response处理的钩子,每个请求都需要经过中间件。所以在middlewares.py中新建两个类,用于随机选择用户代理和ip代理:
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
#print useragent
request.headers.setdefault("User-Agent", useragent)
# 随机的代理ip
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
# 没有代理账户验证的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']
在setting.py中开启下载中间件:
DOWNLOADER_MIDDLEWARES = {
'dytt_redis_slaver.middlewares.RandomUserAgent': 543,
'dytt_redis_slaver.middlewares.RandomProxy': 553,
}
二、Master端代码
Scrapy-Redis分布式策略中,Master端(核心服务器),不负责爬取数据,只负责url指纹判重、Request的分配,以及数据的存储,但是一开始要在Master端中lpush开始位置的url,这个操作可以在控制台中进行,打开控制台输入:
redis-cli
127.0.0.1:6379> lpush dytt:start_urls https://www.dy2018.com/0/
也可以写一个爬虫对url进行爬取,然后动态的lpush到redis数据库中,这种方法对于url数量多且有规律的时候很有用(不需要在控制台中一条一条去lpush,当然最省事的方法是在slaver端代码中增加rule规则去实现url的获取)。比如要想获取所有电影的分类。
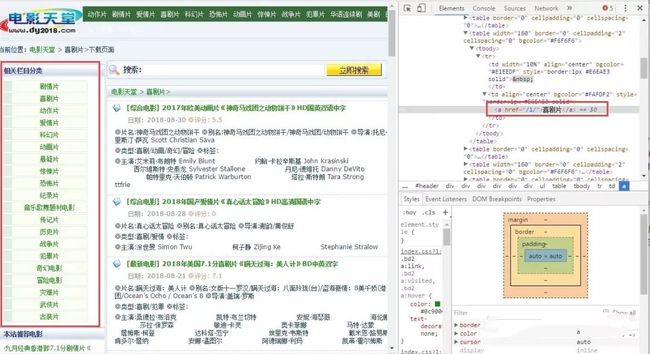
链接就是一个或者两个数字,所以rule规则为:
rules = (
Rule(LinkExtractor(allow=r'/\d{1,2}/$'), callback='parse_item'),
)
在parse_item中返回这个请求链接:
def parse_item(self, response):
# print(response.url)
items = DyttRedisMasterItem()
items['url'] = response.url
yield items
piplines.py中,将获得的url全部lpush到redis数据库:
import redis
class DyttRedisMasterPipeline(object):
def __init__(self):
# 初始化连接数据的变量
self.REDIS_HOST = '127.0.0.1'
self.REDIS_PORT = 6379
# 链接redis
self.r = redis.Redis(host=self.REDIS_HOST, port=self.REDIS_PORT)
def process_item(self, item, spider):
# 向redis中插入需要爬取的链接地址
self.r.lpush('dytt:start_urls', item['url'])
return item
运行slaver端时,程序会等待请求的到来,当starts_urls有值的时候,爬虫将开始爬取,但是一开始并没有数据,因为会过滤掉重复的链接:
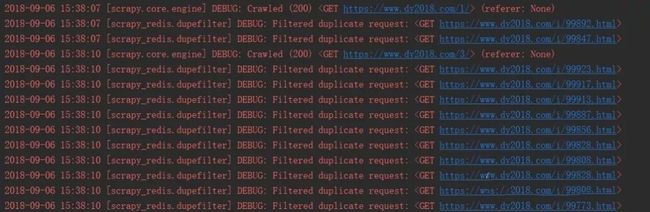
毕竟有些电影的类型不止一种:
![]()
scrapy默认16个线程(当然可以修改为20个啊),而分类有20个,所以start_urls会随机剩下4个,等待任务分配:
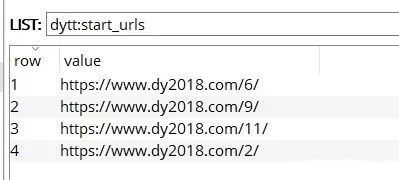
当链接过滤完毕后,就有数据了:

因为在setting.py中设置了:
SCHEDULER_PERSIST = True
所以重新启动爬虫的时候,会接着之前未完成的任务进行爬取。在slaver端中新增rule规则可以实现翻页功能:
page_links = LinkExtractor(allow=r'/index_\d*.html')
rules = (
# 翻页规则
Rule(page_links),
# 进入电影详情页
Rule(movie_links, callback='parse_item'),
)
三、数据转存到Mysql
因为,redis只支持String,hashmap,set,sortedset等基本数据类型,但是不支持联合查询,所以它适合做缓存。将数据转存到mysql数据库中,方便以后查询:
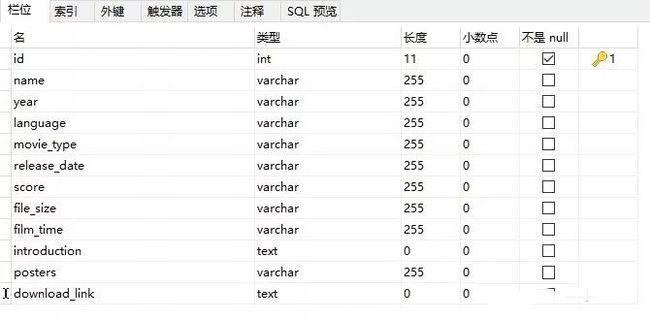
创建数据表:
代码如下:
# -*- coding: utf-8 -*-
import json
import redis
import pymysql
def main():
# 指定redis数据库信息
rediscli = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
# 指定mysql数据库
mysqlcli = pymysql.connect(host='127.0.0.1', user='root', passwd='zhiqi', db='Scrapy', port=3306, use_unicode=True)
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["dytt_slaver:items"])
item = json.loads(data)
try:
# 使用cursor()方法获取操作游标
cur = mysqlcli.cursor()
# 使用execute方法执行SQL INSERT语句
cur.execute("INSERT INTO dytt (name, year, language, "
"movie_type, release_date, score, file_size, "
"film_time, introduction, posters, download_link) VALUES "
"(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s )",
[item['name'], item['year'], item['language'],
item['movie_type'], item['release_date'], item['score'],
item['file_size'], item['film_time'], item['introduction'],
item['posters'], item['download_link']])
# 提交sql事务
mysqlcli.commit()
#关闭本次操作
cur.close()
print ("inserted %s" % item['name'])
except pymysql.Error as e:
print ("Mysql Error %d: %s" % (e.args[0], e.args[1]))
if __name__ == '__main__':
main()
最终结果:

项目地址:
https://github.com/ZhiqiKou/Scrapy_notes
本文作者
Zhiqi Kou,一个向往成为真正程序员的码奴。
地址:zhihu.com/people/zhiqi-kou
投稿邮箱:[email protected]
欢迎点击申请Python中文社区新专栏作者计划

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击下方阅读原文,免费成为社区会员