Kafka Streams流式原理解析
前言
本篇文章会从Kafka的核心流式计算原理进行分析,Kafka Streams Low-level processor API 和 核心概念,以及常见的应用场景分析
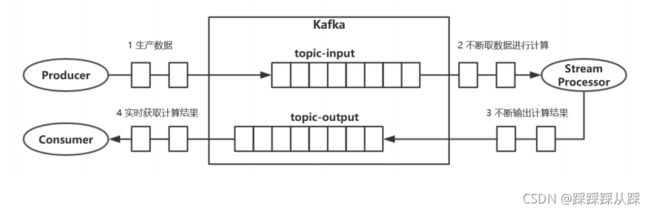
流式计算
通过业务场景去分析流式计算的业务场景:
- 双十一时实时滚动的订单量、成交总金额。
- 每十分钟的成交额
- 股票交易看板
大数据的计算,而且刷新率是非常高的。如果在数据库中去计算,每5秒进行计算,是相当卡的。而且受网络等影响,这些都是影响因素。
流式数据 --> 流式计算
- 数据是随时间不断产生的,没有界限,数据是不能变更的。 这点很重要,数据不能变更
- 计算也是不断进行的,是近实时的计算。
- 计算的结果是不断更新的,每次计算产生最新的结果
- 作为一个简单的轻量级客户端库设计,它可以很容易地嵌入到任何Java应用程序中。
- 除Apache Kafka本身作为内部消息层外,对系统没有外部依赖;值得注意的是,它使用Kafka的分片模型进行水平伸缩处理,同时保持了强大的顺序保证。
- 支持容错的本地状态,这支持非常快速和高效的有状态操作,比如窗口连接和聚合。
- 支持精确的一次处理语义,以确保每条记录将被处理一次,且仅被处理一次,即使流客户机或 Kafka代理在处理过程中出现故障也是如此。
- 使用一次一个记录的处理来实现毫秒级的处理延迟,并支持基于事件时间的窗口操作和记录的延迟到达。
- 提供必要的流处理原语,以及高级流DSL和低级处理器API。
流式计算程序示例
在maven中引入 kafka-streams
org.apache.kafka
kafka-streams
2.3.0
统计单词在消息总出现次数统计的流计算程序
步骤
- 不断消费消息 拉取消息
- 分割消息为单词
- 累计单词的出现次数 做统计次数,进行存储起来
- 每隔一分钟输出统计结果
编写我们的流处理器(实现 Processor接口) 持有上下文 ,并创建存储对象
public class WordCountProcessor implements Processor {
private ProcessorContext context;
private KeyValueStore kvStore;
} (K-V结构)流数据的处理方法,一次处理一条数据,计算逻辑写在该方法中
/*
* (K-V结构)流数据的处理方法,一次处理一条数据,计算逻辑写在该方法中
*/
@Override
public void process(String key, String value) {
String[] words = value.toLowerCase().split(" ");
for (String word : words) {
Long oldValue = this.kvStore.get(word);
if (oldValue == null) {
this.kvStore.put(word, 1L);
} else {
this.kvStore.put(word, oldValue + 1L);
}
}
}使用给定ProcessorContext上下文初始化此处理器实例。框架确保在初始化包含它的topology时,调用每个处理器init()一次。当框架使用处理器完成时,将调用close();稍后,框架可以通过再次调用init()重用处理器。 给入的ProcessorContext上下文,可用来访问流处理流程的topology以及record meta data、调度要定期调用的方法以及访问附加的StateStore状态存储。
public void init(ProcessorContext context) {
// keep the processor context locally because we need it in punctuate()
// and commit()
this.context = context;
/**
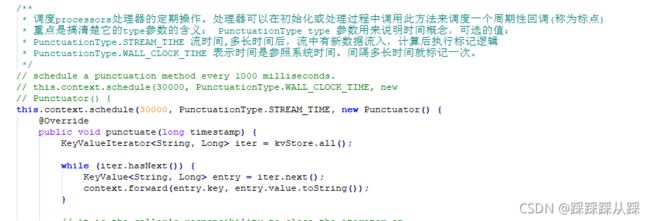
* 调度processors处理器的定期操作。处理器可以在初始化或处理过程中调用此方法来调度一个周期性回调(称为标点)
* 重点是搞清楚它的type参数的含义: PunctuationType type 参数用来说明时间概念,可选的值:
* PunctuationType.STREAM_TIME 流时间,多长时间后,流中有新数据流入,计算后执行标记逻辑
* PunctuationType.WALL_CLOCK_TIME 表示时间是参照系统时间。间隔多长时间就标记一次。
*/
// schedule a punctuation method every 1000 milliseconds.
// this.context.schedule(30000, PunctuationType.WALL_CLOCK_TIME, new
// Punctuator() {
this.context.schedule(30000, PunctuationType.STREAM_TIME, new Punctuator() {
@Override
public void punctuate(long timestamp) {
KeyValueIterator iter = kvStore.all();
while (iter.hasNext()) {
KeyValue entry = iter.next();
context.forward(entry.key, entry.value.toString());
}
// it is the caller's responsibility to close the iterator on
// state store;
// otherwise it may lead to memory and file handlers leak
// depending on the
// underlying state store implementation.
iter.close();
// commit the current processing progress
context.commit();
}
});
// retrieve the key-value store named "Counts"
this.kvStore = (KeyValueStore) context.getStateStore("Counts");
} 资源释放方法 当Processor被流处理框架使用完后后,框架将调用其close来进行资源释放。注意:不要在此方法中关闭任何流管理资源,比如这里的StateStore,因为它们是由框架管理的。
@Override
public void close() {
// close any resources managed by this processor.
// Note: Do not close any StateStores as these are managed
// by the library
}最后需要定义存储
// 2 定义stateStore
Map changelogConfig = new HashMap();
KeyValueBytesStoreSupplier countStoreSupplier = Stores.inMemoryKeyValueStore("Counts");
StoreBuilder> builder = Stores.keyValueStoreBuilder(countStoreSupplier, Serdes.String(), Serdes.Long())
.withLoggingEnabled(changelogConfig); // enable
// changelogging,with
// custom changelog
// settings 定义处理流程Topology ,定义流属性
Topology topology = new Topology();
// add the source processor node that takes Kafka topic "source-topic"
// as input
topology.addSource("Source", "source-topic")
// add the WordCountProcessor node which takes the source
// processor as its upstream processor
.addProcessor("Process", () -> new WordCountProcessor(), "Source")
// add the count store associated with the WordCountProcessor
// processor
.addStateStore(builder, "Process")
// add the sink processor node that takes Kafka topic
// "sink-topic" as output
// and the WordCountProcessor node as its upstream processor
.addSink("Sink", "sink-topic", "Process");
// 4 定义流属性
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream-processing-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.100.9:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
创建流处理 开启流处理
// 5 创建流处理
KafkaStreams streams = new KafkaStreams(topology, props);
// streams.setGlobalStateRestoreListener(new
// ConsoleGlobalRestoreListerner());
// 6 开启流处理
streams.start();流处理得流程定义
Kafka Streams Low-level processor API 和 核心概念
包括Processor、Topology、Properties 所有得组件都组合在 KafkaStreams 中进行执行。
Processor 处理器 流处理器
这是提供给我们主要处理逻辑得地方,流处理器。
里面包含 init 方法 以及 process 方法 close方法
表示 processor是key-value键值对得处理结构

- init 方法 使用给定ProcessorContext上下文初始化此处理器实例。
PunctuationType type 参数用来说明时间概念,可选的值:
PunctuationType.STREAM_TIME 流时间,多长时间后,流中有新数据流入,计算后执行标记逻辑
PunctuationType.WALL_CLOCK_TIME 表示时间是参照系统时间。间隔多长时间就标记一次
- process 方法 (K-V结构)流数据的处理方法,一次处理一条数据,计算逻辑写在该方法中
- close方法 资源释放方法 当Processor被流处理框架使用完后后,框架将调用其close来进行资源释放。
- kafka中数据为什么key-value结构,所有数据,存储store等都是key-value结构得 这个key充当着数据得key.
Processor Topology 处理器拓扑结构

Topology topology = new Topology();
topology.addSource("SOURCE", "src-topic") // add "PROCESS1" node which takes the source processor "SOURCE" as its upstream
processor .addProcessor("PROCESS1", () -> new MyProcessor1(), "SOURCE") // add "PROCESS2" node which takes "PROCESS1" as its upstream processor .addProcessor("PROCESS2", () -> new MyProcessor2(), "PROCESS1")将源topic ,将后面进行关联起来,做处理操作
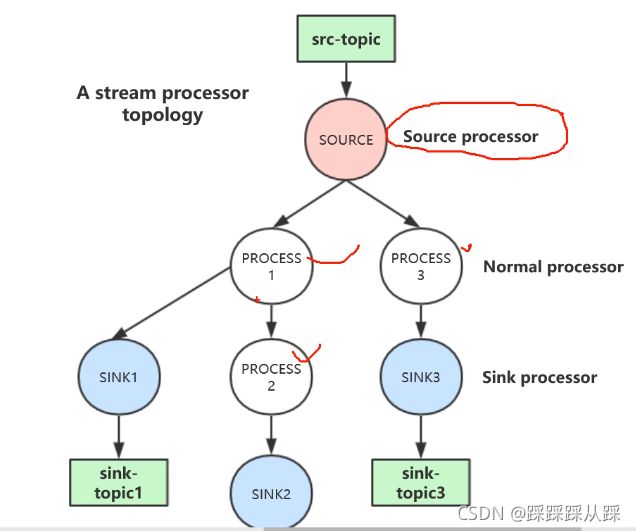
拓扑结构中有两种特殊的处理器:
- Source Processor : Source Processor 是一种没有前置节点的特殊流处理器。它从一个或者多 个 Kafka Topic 消费数据并产出一个输入流给到拓扑结构的后续处理节点。
- Sink Processor : sink processor 是一种特殊的流处理器,没有处理器需要依赖于它。 它从前置流处理器接收数据并传输给指定的 Kafka Topic
State Store
为了使流计算过程能容错,我们需要存储计算状态,那可以存储到内存、磁盘 、db
在上下文中就可以获取到

// 2 定义stateStore
Map changelogConfig = new HashMap();
KeyValueBytesStoreSupplier countStoreSupplier = Stores.inMemoryKeyValueStore("Counts");
StoreBuilder> builder = Stores.keyValueStoreBuilder(countStoreSupplier, Serdes.String(), Serdes.Long())
.withLoggingEnabled(changelogConfig); // enable
// changelogging,with
// custom changelog
// settings
// add the count store associated with the WordCountProcessor
// processor
.addStateStore(builder, "Process") 这里是存到内存中将 statestore进行存储起来。
还可以存到磁盘中去
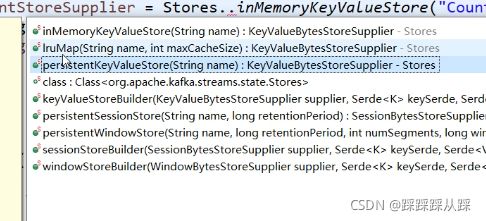
如果机器故障了,为了容错,需要能将计算迁移到其他机器上继续,存储到本机就不合适了。
就存到topic中去 中间状态存到可靠中去,状态变更 都写日志 记录到变更日志上去。 withLoggingEnabled(changlogConfig)
StoreBuilder> countStoreSupplier = Stores.keyValueStoreBuilder( Stores.persistentKeyValueStore("Counts"),
Serdes.String(), Serdes.Long()) .withLoggingEnabled(changlogConfig);
// enable changelogging, with custom changelog settings 
根据不同得用途去查找到。
DSL High-Level API
一个KStream可以是由一个或多个Topic定义的,消费Topic中的消息产生一个个
也可是KStream转换的结果;KTable还可以转换为KStream。
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.120.41:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 用来创建topology
StreamsBuilder builder = new StreamsBuilder();
// KStream是键值对记录流的抽象。例如,, 。
// 一个KStream可以是由一个或多个Topic定义的,消费Topic中的消息产生一个个 记录;
// 也可是KStream转换的结果;KTable还可以转换为KStream。
KStream textLines = builder.stream("source-topic");
// KTable是changelog stream的抽象
KTable wordCounts = textLines.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word).count(Materialized.> as("counts-store"));
wordCounts.toStream().to("sink-topic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
} 
这些都是kafka提供给我们简化得api.
connect
Kafka Connect 是一款可扩展并且可靠地在 Apache Kafka 和其他系统之间进行数据传输的工具。 可以很简单的快速定义 connectors 将大量数据从 Kafka 移入和移出. Kafka Connect 可以摄取数据库数据或者收集应用程序的 metrics 存储到 Kafka topics,使得数据可以用于低延迟的流处理。 一个导出的 job 可以将来自 Kafka topic 的数据传输到二级存储,用于系统查询或者批量进行离线分析。
Kafka Connect 功能包括:
- Kafka connectors 通用框架: - Kafka Connect 将其他数据系统和Kafka集成标准化,简化了 connector 的开发,部署和管理
- 分布式和单机模式 - 可以扩展成一个集中式的管理服务,也可以单机方便的开发,测试和生产环境小型的部署。
- REST 接口 - submit and manage connectors to your Kafka Connect cluster via an easy to use REST API
- offset 自动管理 - 只需要connectors 的一些信息,Kafka Connect 可以自动管理offset 提交的过程,因此开发人员无需担心开发中offset提交出错的这部分。
- 分布式的并且可扩展 - Kafka Connect 构建在现有的 group 管理协议上。Kafka Connect 集群可以扩展添加更多的workers。
- 整合流处理/批处理 - 利用 Kafka 已有的功能,Kafka Connect 是一个桥接stream 和批处理系统理想的方式。
Kafka 中文文档 - ApacheCN
中文文档。
主要用来做灵活数据得导入和导出