经验分布与真实分布
经验分布函数
- 定义
设 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)是取自分布为 F ( x ) F(x) F(x)的母体中一个简单随机子样的观测值. 若把子样观测值由小到大进行排列, 得到 x ( 1 ) ≤ x ( 2 ) ≤ ⋯ ≤ x ( n ) x_{(1)}\leq x_{(2)}\leq\cdots\leq x_{(n)} x(1)≤x(2)≤⋯≤x(n), 这里 x ( 1 ) x_{(1)} x(1)是子样观测值 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)中最小的一个, x ( i ) x_{(i)} x(i)是子样观测值中第 i i i个小的数, 则
F n ( x ) = { 0 , 当 x < x ( 1 ) k n , 当 x ( k ) ≤ x ≤ x ( k + 1 ) , k = 1 , 2 , ⋯ , n − 1 1 , 当 x ≥ x ( n ) F_{n}(x)= \begin{cases}0,&当x
显然, F n ( x ) F_n(x) Fn(x)是一非减右连续函数,且满足
F n ( − ∞ ) = 0 和 F n ( + ∞ ) = 1 F_n(-\infty)=0和F_n(+\infty) =1 Fn(−∞)=0和Fn(+∞)=1
由此可见, F n ( x ) F_n(x) Fn(x)是一个分布函数, 称为经验分布函数(edf).
分布函数
- 定义
定义在样本空间 Ω \varOmega Ω上, 取值于实数域的函数 ξ ( ω ) \xi(\omega) ξ(ω), 称为是样本空间 Ω \varOmega Ω上的(实值)随机变量, 并称
F ( x ) = P ( ξ ( ω ) ≤ x ) , x ∈ ( − ∞ , ∞ ) F(x)=P(\xi(\omega)\leq x),x\in(-\infty,\infty) F(x)=P(ξ(ω)≤x),x∈(−∞,∞)
是随机变量 ξ ( ω ) \xi(\omega) ξ(ω)的累积分布函数或概率分布函数, 简称分布函数.
性质
根据伯努利大数定律, 只要 n n n足够大, F n ( x ) F_n(x) Fn(x)依概率收敛于 F ( x ) F(x) F(x), 也就是说当样本量足够大时, 经验分布函数是母体分布函数的一个良好的近似.
实验
- 连续性随机变量-正态分布
先出给连续情况下的一个实验. 通过从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1)中分别抽取样本量为20、100、200、400的样本, 构造经验分布函数来对比ecdf与真实分布之间的差别.
from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(20)
mu = 0
sig = 1
xmin = -3
xmax = 3
s4 = np.random.normal(mu, sig, 20)
axis_x = np.arange(xmin, xmax, 0.01)
axis_y = norm.cdf(axis_x)
norm_ecdf = ECDF(s4)
plt.figure(figsize=(12, 8), dpi=70)
ax1 = plt.subplot(221)
ax1.plot(axis_x, axis_y, label="cdf")
ax1.plot(axis_x, norm_ecdf(axis_x), label="ecdf")
plt.ylim(-0.05, 1.05)
plt.vlines(x=0, ymin=-0.05, ymax=1.05, color="k")
#plt.hlines(y=0, xmin=xmin, xmax=xmax, color="k")
plt.title(r'$n=20$')
plt.legend()
s4 = np.random.normal(mu, sig, 100)
norm_ecdf = ECDF(s4)
ax2 = plt.subplot(222)
ax2.plot(axis_x, axis_y, label="cdf")
ax2.plot(axis_x, norm_ecdf(axis_x), label="ecdf")
plt.ylim(-0.05, 1.05)
plt.vlines(x=0, ymin=-0.05, ymax=1.05, color="k")
#plt.hlines(y=0, xmin=xmin, xmax=xmax, color="k")
plt.title(r'$n=100$')
plt.legend()
s4 = np.random.normal(mu, sig, 200)
norm_ecdf = ECDF(s4)
ax3 = plt.subplot(223)
ax3.plot(axis_x, axis_y, label="cdf")
ax3.plot(axis_x, norm_ecdf(axis_x), label="ecdf")
plt.ylim(-0.05, 1.05)
plt.vlines(x=0, ymin=-0.05, ymax=1.05, color="k")
#plt.hlines(y=0, xmin=xmin, xmax=xmax, color="k")
plt.title(r'$n=200$')
plt.legend()
s4 = np.random.normal(mu, sig, 400)
norm_ecdf = ECDF(s4)
ax4 = plt.subplot(224)
ax4.plot(axis_x, axis_y, label="cdf")
ax4.plot(axis_x, norm_ecdf(axis_x), label="ecdf")
plt.ylim(-0.05, 1.05)
plt.vlines(x=0, ymin=-0.05, ymax=1.05, color="k")
#plt.hlines(y=0, xmin=xmin, xmax=xmax, color="k")
plt.title(r'$n=400$')
plt.legend()
#plt.savefig("D:\\Desktop\\ecdf.png", dpi=200)
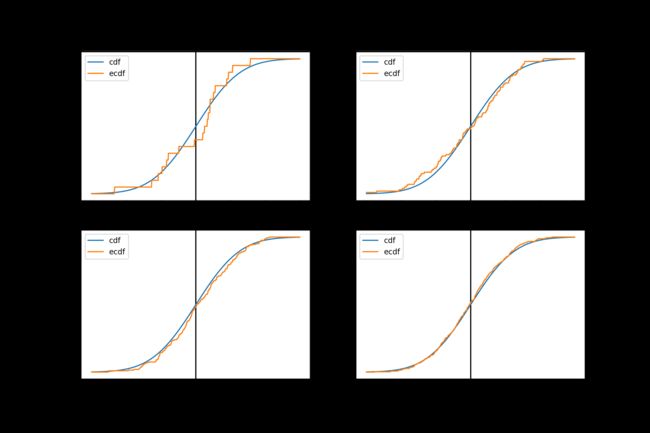
可以看到随着样本量的增加, 经验分布函数的曲线逐渐与真实cdf曲线重合.
- 离散型随机变量-泊松分布
首先给出泊松分布的累积分布函数(形式较为复杂且并不常见, 通常不讨论)
F ( x ) = Γ ( [ k + 1 ] , λ ) [ k ] ! 或 e − λ ∑ i = 0 [ k ] λ i i ! 或 Q ( [ k + 1 ] , λ ) F(x)=\frac{\Gamma([k+1],\lambda)}{[k]!}或e^{-\lambda}\sum_{i=0}^{[k]}\frac{\lambda^i}{i!}或Q([k+1],\lambda) F(x)=[k]!Γ([k+1],λ)或e−λi=0∑[k]i!λi或Q([k+1],λ)
其中 k ∈ 0 , 1 , 2 , 3 , ⋯ k\in{0,1,2,3,\cdots} k∈0,1,2,3,⋯, Γ ( x , y ) \Gamma(x,y) Γ(x,y)是不完全伽玛函数, [ k ] [k] [k]是向下取整符号, Q Q Q是规则化伽玛函数.
对于泊松分布cdf的计算有两种方法: 1. 自主编程. 2. 调用scipy库. 下面给出自主编程代码, 但在实验中为了保证效率调用了scipy, 之后会比较自主编程与scipy库的准确性.
import math
def cdf(k, Lam):
global Sum
Sum = 0
for i in range(k + 1):
Sum = Sum + ((Lam**i)/(math.factorial(i)))
#print(Sum)
fx = np.exp(-Lam)*Sum
return fx
n = 5
f = []
for j in range(n):
a = cdf(j, 1)
f.append(a)
#print(f)
for l in range(n):
plt.plot([l,l+1],[f[l],f[l]],"b")
plt.ylim(0,1.05)
接下来给出实验结果
import numpy as np
from statsmodels.distributions.empirical_distribution import ECDF
import matplotlib.pyplot as plt
from scipy.stats import poisson
Lam3 = 1 # 设定分布参数
xmin, xmax = 0, 10 # 坐标轴参数
n = [20, 100, 200, 400] # 设定样本量
axis_x = np.arange(xmin, xmax, 1)
plt.figure(figsize=(12, 8), dpi=100)
s4 = np.random.poisson(Lam3, n[0]) # 抽样
ecdf = ECDF(s4) # 构造样本经验分布函数
ax1 = plt.subplot(221)
for i in range(10):
ax1.plot([i, i+1], [ecdf(i), ecdf(i)], color="orange",markersize=1)
ax1.scatter(i, ecdf(i), color="orange")
if i == 8:
ax1.plot([i+1, i+2], [ecdf(i), ecdf(i)], color="orange",markersize=1,label="ecdf")
ax1.scatter(i, ecdf(i), color="orange")
break
for j in range(10):
ax1.plot([j, j+1], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1)
ax1.scatter(j, poisson.cdf(j, Lam3), color="b")
if j == 8:
ax1.plot([j+1, j+2], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1,label="cdf")
ax1.scatter(j, poisson.cdf(j, Lam3), color="b")
break
plt.ylim(0, 1.05)
plt.legend()
plt.title(r"$n=20$")
s4 = np.random.poisson(Lam3, n[1]) # 抽样
ecdf = ECDF(s4) # 构造样本经验分布函数
ax2 = plt.subplot(222)
for i in range(10):
ax2.plot([i, i+1], [ecdf(i), ecdf(i)], color="orange",markersize=1)
ax2.scatter(i, ecdf(i), color="orange")
if i == 8:
ax2.plot([i+1, i+2], [ecdf(i), ecdf(i)], color="orange",markersize=1,label="ecdf")
ax2.scatter(i, ecdf(i), color="orange")
break
for j in range(10):
ax2.plot([j, j+1], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1)
ax2.scatter(j, poisson.cdf(j, Lam3), color="b")
if j == 8:
ax2.plot([j+1, j+2], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1,label="cdf")
ax2.scatter(j, poisson.cdf(j, Lam3), color="b")
break
plt.ylim(0, 1.05)
plt.legend()
plt.title(r"$n=100$")
s4 = np.random.poisson(Lam3, n[2]) # 抽样
ecdf = ECDF(s4) # 构造样本经验分布函数
ax3 = plt.subplot(223)
for i in range(10):
ax3.plot([i, i+1], [ecdf(i), ecdf(i)], color="orange",markersize=1)
ax3.scatter(i, ecdf(i), color="orange")
if i == 8:
ax3.plot([i+1, i+2], [ecdf(i), ecdf(i)], color="orange",markersize=1,label="ecdf")
ax3.scatter(i, ecdf(i), color="orange")
break
for j in range(10):
ax3.plot([j, j+1], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1)
ax3.scatter(j, poisson.cdf(j, Lam3), color="b")
if j == 8:
ax3.plot([j+1, j+2], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1,label="cdf")
ax3.scatter(j, poisson.cdf(j, Lam3), color="b")
break
plt.ylim(0, 1.05)
plt.legend()
plt.title(r"$n=200$")
s4 = np.random.poisson(Lam3, n[3]) # 抽样
ecdf = ECDF(s4) # 构造样本经验分布函数
ax4 = plt.subplot(224)
for i in range(10):
ax4.plot([i, i+1], [ecdf(i), ecdf(i)], color="orange",markersize=1)
ax4.scatter(i, ecdf(i), color="orange")
if i == 8:
ax4.plot([i+1, i+2], [ecdf(i), ecdf(i)], color="orange",markersize=1,label="ecdf")
ax4.scatter(i, ecdf(i), color="orange")
break
for j in range(10):
ax4.plot([j, j+1], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1)
ax4.scatter(j, poisson.cdf(j, Lam3), color="b")
if j == 8:
ax4.plot([j+1, j+2], [poisson.cdf(j, Lam3), poisson.cdf(j, Lam3)], "b",markersize=1,label="cdf")
ax4.scatter(j, poisson.cdf(j, Lam3), color="b")
break
plt.ylim(0, 1.05)
plt.legend()
plt.title(r"$n=400$")
#plt.savefig("D:\\Desktop\\ecdf_pois.png", dpi=200)
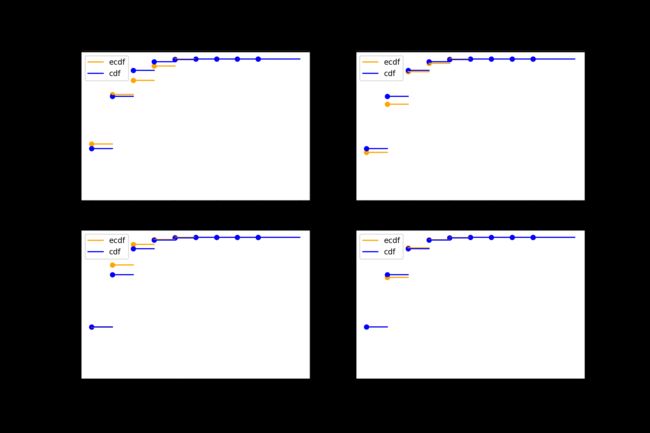
可以看到随着样本量的增加我们得到了和标准正态分布相同的结果. 同时也可以从数值角度来观察这一过程, 例如下面的代码给出了不同方法下 F ( 1 ) F(1) F(1)的计算结果:
s4 = np.random.poisson(Lam3, 400) #抽样
prob_sci = poisson.cdf(1, Lam3) #调包
prob_cdf = cdf(1,Lam3) #自主编程
ecdf = ECDF(s3) #构造经验分布函数
prob_ecdf = ecdf(1) #调用经验分布函数
print(prob_sci, prob_cdf, prob_ecdf)
>>>0.7357588823428847 0.7357588823428847 0.73
可见在样本量400的条件下, 真实 F ( 1 ) F(1) F(1)与 F ^ ( 1 ) \hat{F}(1) F^(1)几乎不存在差距.
参考文献
- 维基百科.
- 魏宗舒. 概率论与数理统计教程[M]. 北京: 高等教育出版社. 2008: 235-236.
- 茆诗松, 周纪芗. 概率论与数理统计[M]. 北京: 中国统计出版社. 2007.