【精品系列】【机器学习实战】【实践项目一】区域房价中位数预测(获取数据)
参照《机器学习实战》第二版
实践项目一:区域房价中位数预测
1、下载数据
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
2、读取下载的数据
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
2.1、数据显示(默认前五列)
housing = load_housing_data()
housing.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
2.2、查看每列属性
housing.info()
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20640 non-null float64
1 latitude 20640 non-null float64
2 housing_median_age 20640 non-null float64
3 total_rooms 20640 non-null float64
4 total_bedrooms 20433 non-null float64
5 population 20640 non-null float64
6 households 20640 non-null float64
7 median_income 20640 non-null float64
8 median_house_value 20640 non-null float64
9 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
2.3、查看某列数值统计
housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
2.4、查看数值列属性摘要
housing.describe()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
- 上面看到
total_bedrooms这一列的count的数值为20433而不是20640,是因为不统计为空的单元格,所以后面需要处理为空的数据。 std行:显示的是标准差,用来测量数值的离散程度,也就是方差的平方根,一般符合高斯分布- 25%、50%、75%:显示相应的百分位数,表示一组观测值中给定百分比的观测值都低于该值;50% 即 中位数。
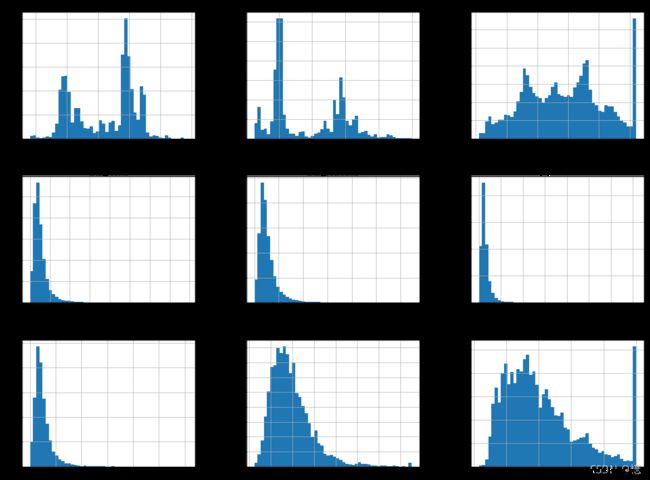
2.5、快速了解数组类型的方法(直方图)
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
plt.show()
3、创建测试集
理论上,创建测试集非常简单,只需要随机选择一些实例,通常是数据集的20%(如果数据量巨大,比例将更小)
- 为了即使在更新数据集之后也有一个稳定的训练测试分割,常见的解决方案是每个实例都使用一个
标识符来决定是否进入测试集(假定每个实例都一个唯一且不变的标识符) - 你可以计算每个实例的标识符的哈希值,如果这个哈希值小于或等于最大哈希值的20%,则将该实例放入测试集。这样可以保证测试集在多个运行里都是一致的,即便更新数据集也依然一致。新实例的20%将被放如新的测试集,而之前训练集中的实例也不会被放入新测试集。
3.1、手动随机生成
from zlib import crc32
import numpy as np
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def splet_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
- housing 数据集没有标识符列。最简单的解决方法是使用索引作为 ID
housing_with_id = housing.reset_index()
train_set, test_set = splet_train_test_by_id(housing_with_id, 0.2, "index")
3.2、使用 Scikit-Learn 提供的方法 train_test_split 随机生成
- 最简单的方法就是使用:train_test_split(),它与前面定义的 split_train_test() 几乎相同,除了几个额外特征。
from sklearn.model_selection import train_test_split
# random_state: 设置随机生成器种子
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
- 到目前为止,我们考虑的是纯随机的抽样方法。如果数据集足够庞大(特别是相较于属性的数量而言),这种方法通常不错
- 如果不是,则有可能会导致明显的抽样偏差。即 应该按照比例分层抽样。
如果你咨询专家,他们会告诉你,要预测房价中位数,收入中位数是个非常重要的属性。于是你希望确保在收入属性上,测试集能够代表整个数据集中各种不同类型的收入。
我们由上面直方图可以看到:大部分收入中位数值聚集在1.5~6左右,但也有一部分超过了6,在数据集中,每个层都要有足够数量的数据,这一点至关重要,不然数据不足的层,其重要程度佷有可能会被错估。
3.3、使用 Scikit-Learn 提供的方法 StratifiedShuffleSplit 按类别比例生成
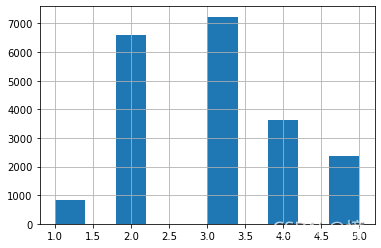
# 用 pd.cut() 来创建 5个收入类别属性(用 1~5 来做标签),0~1.5是类别 1, 1.5~3是类别2
# np.inf 代表无穷大
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0, 1.5, 3, 4.5, 6, np.inf],
labels=[1, 2, 3, 4, 5])
housing["income_cat"].hist()
现在根据收入类进行分层抽样,使用 Scikit-Learn 的 StratifiedShuffleSplit
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
看看上面运行是否如我们所料
compare_pd = pd.DataFrame()
# 全部数据:按收入分类的比例
compare_pd["Overall"] = housing["income_cat"].value_counts() / len(housing)
# 按收入分类的比例 获取测试集比例
compare_pd["Stratified"] = strat_test_set["income_cat"].value_counts() / len(strat_test_set)
# 随机获取测试集比例
_, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_pd["Random"] = test_set["income_cat"].value_counts() / len(test_set)
compare_pd
| Overall | Stratified | Random | |
|---|---|---|---|
| 3 | 0.350581 | 0.350533 | 0.358527 |
| 2 | 0.318847 | 0.318798 | 0.324370 |
| 4 | 0.176308 | 0.176357 | 0.167393 |
| 5 | 0.114438 | 0.114583 | 0.109496 |
| 1 | 0.039826 | 0.039729 | 0.040213 |
由上面数据我们看到,随机抽样的测试集,收入类别比例分布有些偏差。
现在可以删除 income_cat 属性,将数据恢复原样了:
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
我们花了相当长的时间在测试集的生成上,理由很充分:这是及机器学习项目中经常忽视但是却至关重要的一部分。并且,当讨论到交叉验证时,这里谈到的许多想法也对其大有裨益。
欲知后事如何,且听下回分解。