【Python爬虫】猫眼电影榜单Top100
这是一个入门级的Python爬虫,结构易于理解。本文对编写此爬虫的全过程进行了讲述。希望对大家的Python爬虫学习有所帮助。
一、目标
爬取猫眼电影榜单Top100,将数据存入Excel文件中,并利用pyecharts库进行数据可视化得到.html文件和.png文件。
二、内容
主要包括四个阶段:爬取网页全部数据、获取数据并进行处理、数据存储、数据可视化。
1、 爬取网页全部数据
通过requests.get()获得页面数据,使用etree.HTML()将字符串数据转变成_Element对象,并存储在列表中。
使用循环获得全部页面(共10页)的数据。
2、 获取数据并进行处理
使用xpath()方法对_Element对象进行解析,以获得所需要的信息。通过此方法可以获得所有电影的信息:电影名、主演、上映时间、评分(整数部分及小数部分)。
对数据进行进一步的处理:
- 将主演原始数据中的反义字符’\n’、空格’ '以及“主演:”去除;
- 将上映时间原始数据中的“上映时间:”去除;
- 将评分的整数部分以及小数部分合并。
最后,将处理过的数据存储在列表中。
3、 数据存储
将爬取的数据放入一个Excel文件中,以实现对数据的长期存储。
4、数据可视化
利用pyecharts实现数据可视化。
统计猫眼电影Top100榜单中电影上映月份,生成echarts柱状图,并对图片进行渲染,将生成的文件存储到工程文件目录下。
三、运行结果
运行程序,控制台输出情况:

工程文件夹下生成了“好片月份分布.html”、“好片月份分布.png”以及“猫眼电影榜单Top100.xls”文件:

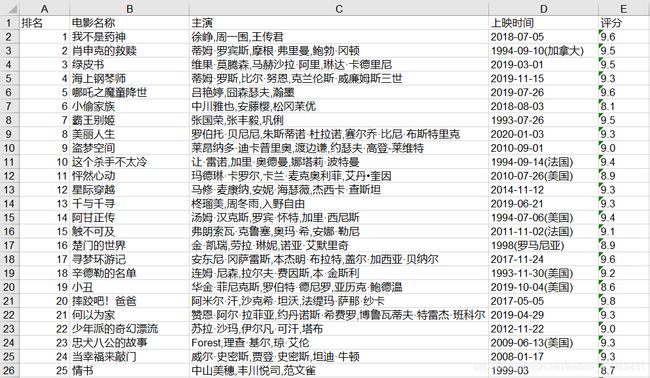
“猫眼电影榜单Top100.xls”文件内容(部分截图):
“好片月份分布.html”文件内容(去掉一个不含月份信息的数据,共99部电影分布情况):

“好片月份分布.png”文件内容:

观察生成的柱状图,可以发现在榜单中的电影竟然没有一部是在2月上映的,9月和12月上映的好片最多。
四、过程
1、爬取网页全部数据实现过程
观察网页地址找出榜单地址变化规律。每页十部电影,共10页。切换页面‘offset=’后的数字发生变化,为[0,10,20,…,90]。因此所有页面的网址为:
board_urls = ['https://maoyan.com/board/4?offset={0}'.format(i) for i in range(0, 100, 10)]
按F12进入元素审查,选择Network选型卡,找到“4?offset=0”文件。

查看此文件的Headers内容,找到‘User-Agent’和 ‘Cookie’。

请求数据时将由‘User-Agent’和 ‘Cookie’组成的headers一起传入即可模拟浏览器对网站进行访问,并绕过滑块拼图验证。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Cookie': 'mta=222214055.1603977692790.1605667197555.1605667216476.84; uuid_n_v=v1; uuid=A8B9B7F019E911EB9D95490677AB0FF651894580EC0942CDA95D1D5CD9BEE13D; _lxsdk_cuid=175748545b3c8-0d6dc6ca2c5b4d-3c634103-144000-175748545b3c8; _lxsdk=A8B9B7F019E911EB9D95490677AB0FF651894580EC0942CDA95D1D5CD9BEE13D; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=222214055.1603977692790.1605606918555.1605606922430.33; _csrf=e50e37a20022fed414d7d479d61fb627bd72f61c2be692b12edc786fdb91dea2; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1604192299,1605603303,1605612340,1605665922; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1605667216; _lxsdk_s=175d9259dda-76-0bc-84b%7C%7C32'}
使用etree.HTML()将获取的数据转换成_Element对象存入列表中。使用循环,将10页的全部内容都存入此列表中。
# 从网页爬取数据
def scraping():
board_urls = ['https://maoyan.com/board/4?offset={0}'.format(i) for i in range(0, 100, 10)]
# 'User-Agent':模拟浏览器访问
# 'Cookie':模拟登录,绕过滑动拼图验证
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Cookie': 'mta=222214055.1603977692790.1605667197555.1605667216476.84; uuid_n_v=v1; uuid=A8B9B7F019E911EB9D95490677AB0FF651894580EC0942CDA95D1D5CD9BEE13D; _lxsdk_cuid=175748545b3c8-0d6dc6ca2c5b4d-3c634103-144000-175748545b3c8; _lxsdk=A8B9B7F019E911EB9D95490677AB0FF651894580EC0942CDA95D1D5CD9BEE13D; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=222214055.1603977692790.1605606918555.1605606922430.33; _csrf=e50e37a20022fed414d7d479d61fb627bd72f61c2be692b12edc786fdb91dea2; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1604192299,1605603303,1605612340,1605665922; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1605667216; _lxsdk_s=175d9259dda-76-0bc-84b%7C%7C32'}
# 获得全部页面信息存入列表中
board_html = []
for board_url in board_urls:
board_url_data = requests.get(board_url, headers=headers)
board_url_html = etree.HTML(board_url_data.content.decode('UTF-8'))
if board_url_html == None:
print("爬取失败。。。")
else:
print(board_url + '爬取成功')
board_html.append(board_url_html)
time.sleep(0.5)
return board_html
第一部分到此结束。
2、 获取数据并进行处理实现过程
查看HTML文件,可以看到我们准备爬取的相关信息。

在需要获取的内容上点击右键,即可复制此属性的XPath。

例如://*[@id=“app”]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a
但这只是第一个电影的属性及内容。将‘dd’后的下标删除后即可获得本页所有电影的相同信息。
即://*[@id=“app”]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a即可。
同理可以获得电影名称、主演、上映时间以及评分(整数及小数部分)的全部数据。
获取原始数据后,需要对数据进行处理:
- 将主演原始数据中的反义字符’\n’、空格’ '以及“主演:”去除;
star.append(str(star_org[i]).replace('\n', '').strip()[3:])
- 将上映时间原始数据中的“上映时间:”去除;
releastime.append(str(releastime_org[i])[5:])
- 将评分的整数部分以及小数部分合并。
score.append(str(float(integer[i][0]) + float(fraction[i]) * 0.1))
最终获得干净整洁的数据。
# 处理数据
def data_processing(board_html):
# 解析排名、电影名、主演、上映时间、评分数据
index = [i for i in range(1, 101)]
name = []
star_org = []
star = []
releastime_org = []
releastime = []
integer = []
fraction = []
score = []
# 数据预处理
for page_html in board_html:
name.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a/@title'))
star_org.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[2]/text()'))
releastime_org.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[3]/text()'))
integer.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[1]/text()'))
fraction.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[2]/text()'))
# 对数据精细处理
for i in range(0, 100):
# 将star_org中的反义字符'\n'、空格' '以及“主演:”去除
star.append(str(star_org[i]).replace('\n', '').strip()[3:])
# 将releastime_org中的“上映时间:”去除
releastime.append(str(releastime_org[i])[5:])
# 将评分的整数部分以及小数部分合并
score.append(str(float(integer[i][0]) + float(fraction[i]) * 0.1))
# data中存入经过处理的所有数据
data = [index, name, star, releastime, score]
return data
至此,第二阶段结束。
3、 数据存储实现过程
通过参数传递获取第二阶段取得的数据,使用xlwt库将数据写入Excel文件中。
将数据存入Excel文件的本质就是将数据一个单元格一个单元格的存入表格中。最后将文件保存即可。
# 将爬取到的数据存入Excel文件中
import xlwt
def build_excel_file(data):
# 创建一个Excel文件
f = xlwt.Workbook(encoding='UTF-8')
# 创建一个sheet
sheet1 = f.add_sheet(u'猫眼电影榜单Top100', cell_overwrite_ok=True)
title = ['排名', '电影名称', '主演', '上映时间', '评分']
# 写入列名
for i in range(len(title)):
sheet1.write(0, i, title[i])
# 填写数据
for i in range(1, 101):
for j in range(len(title)):
sheet1.write(i, j, data[j][i - 1])
f.save('猫眼电影榜单Top100.xls')
第三阶段的数据存储结束。
4、数据可视化实现过程
观察获取到的数据,思考可以进行哪些分析。
我对“榜单中的电影上映时间的月份分布”比较感兴趣,遂将其定为可视化分析目标。
首先,从第二阶段获得的数据中的上映时间获取出月份信息,并统计每个月份的出现次数。由于有电影的上映时间里并没有月份,所以要对获取的数据进行处理,将不含月份信息的数据剔除。
然后使用pyecharts.charts中的Bar生成柱状图。值得注意的是pyecharts的0.5.x版本与1以上版本不兼容,并且有很大的变化。
关于pyecharts更多内容请查看pyecharts项目的Github网页。

采用链式调用方式添加柱状图的数据及配置项,并使用 snapshot-selenium渲染图片,生成.html文件和.png文件,存储在项目文件下。
snapshot-selenium 是 pyecharts + selenium 渲染图片的扩展,使用 selenium 需要配置 browser driver。
# 可视化
from pyecharts.charts import Bar
import pyecharts.options as opts
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
def build_bar_chart(data) -> Bar:
# 设置行名
columns = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"]
# 分析上映时间数据
num = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
for time in data[3]:
# 提取电影上映的月份
month = time[5:7]
# 若没有月份数据就跳过
if month.isdigit():
num[int(month) - 1] += 1
# 添加柱状图的数据及配置项
c = (
Bar()
# 设置X轴内容
.add_xaxis(columns)
# 设置Y轴内容
.add_yaxis("上映电影数量", num)
# 设置主标题以及副标题
.set_global_opts(title_opts=opts.TitleOpts(title="好片月份分布", subtitle="猫眼电影榜单Top100上映的月份分布情况"))
)
return c
至此,整个项目就都结束了。
五、完整代码
import time
import requests
from lxml import etree
# 从网页爬取数据
def scraping():
board_urls = ['https://maoyan.com/board/4?offset={0}'.format(i) for i in range(0, 100, 10)]
# 'User-Agent':模拟浏览器访问
# 'Cookie':模拟登录,绕过滑动拼图验证
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Cookie': 'mta=222214055.1603977692790.1605667197555.1605667216476.84; uuid_n_v=v1; uuid=A8B9B7F019E911EB9D95490677AB0FF651894580EC0942CDA95D1D5CD9BEE13D; _lxsdk_cuid=175748545b3c8-0d6dc6ca2c5b4d-3c634103-144000-175748545b3c8; _lxsdk=A8B9B7F019E911EB9D95490677AB0FF651894580EC0942CDA95D1D5CD9BEE13D; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=222214055.1603977692790.1605606918555.1605606922430.33; _csrf=e50e37a20022fed414d7d479d61fb627bd72f61c2be692b12edc786fdb91dea2; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1604192299,1605603303,1605612340,1605665922; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1605667216; _lxsdk_s=175d9259dda-76-0bc-84b%7C%7C32'}
# 获得全部页面信息存入列表中
board_html = []
for board_url in board_urls:
board_url_data = requests.get(board_url, headers=headers)
board_url_html = etree.HTML(board_url_data.content.decode('UTF-8'))
if board_url_html == None:
print("爬取失败。。。")
else:
print(board_url + '爬取成功')
board_html.append(board_url_html)
time.sleep(0.5)
return board_html
# 处理数据
def data_processing(board_html):
# 解析排名、电影名、主演、上映时间、评分数据
index = [i for i in range(1, 101)]
name = []
star_org = []
star = []
releastime_org = []
releastime = []
integer = []
fraction = []
score = []
# 数据预处理
for page_html in board_html:
name.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a/@title'))
star_org.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[2]/text()'))
releastime_org.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[3]/text()'))
integer.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[1]/text()'))
fraction.extend(page_html.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[2]/text()'))
# 对数据精细处理
for i in range(0, 100):
# 将star_org中的反义字符'\n'、空格' '以及“主演:”去除
star.append(str(star_org[i]).replace('\n', '').strip()[3:])
# 将releastime_org中的“上映时间:”去除
releastime.append(str(releastime_org[i])[5:])
# 将评分的整数部分以及小数部分合并
score.append(str(float(integer[i][0]) + float(fraction[i]) * 0.1))
# data中存入经过处理的所有数据
data = [index, name, star, releastime, score]
return data
# 将爬取到的数据存入Excel文件中
import xlwt
def build_excel_file(data):
# 创建一个Excel文件
f = xlwt.Workbook(encoding='UTF-8')
# 创建一个sheet
sheet1 = f.add_sheet(u'猫眼电影榜单Top100', cell_overwrite_ok=True)
title = ['排名', '电影名称', '主演', '上映时间', '评分']
# 写入列名
for i in range(len(title)):
sheet1.write(0, i, title[i])
# 填写数据
for i in range(1, 101):
for j in range(len(title)):
sheet1.write(i, j, data[j][i - 1])
f.save('猫眼电影榜单Top100.xls')
# 可视化
from pyecharts.charts import Bar
import pyecharts.options as opts
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
def build_bar_chart(data) -> Bar:
# 设置行名
columns = ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"]
# 分析上映时间数据
num = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
for time in data[3]:
# 提取电影上映的月份
month = time[5:7]
# 若没有月份数据就跳过
if month.isdigit():
num[int(month) - 1] += 1
# 添加柱状图的数据及配置项
c = (
Bar()
# 设置X轴内容
.add_xaxis(columns)
# 设置Y轴内容
.add_yaxis("上映电影数量", num)
# 设置主标题以及副标题
.set_global_opts(title_opts=opts.TitleOpts(title="好片月份分布", subtitle="猫眼电影榜单Top100上映的月份分布情况"))
)
return c
def main():
print("################程序运行开始################")
print("<---------------开始爬取数据--------------->")
board_html = scraping()
print("<---------------数据爬取完成--------------->")
print("<---------------开始处理数据--------------->")
data = data_processing(board_html)
print("<---------------数据处理完成--------------->")
print("<---------------开始存储数据--------------->")
print("将爬取数据存入Excel文件:")
build_excel_file(data)
print("<---------------数据存储完成--------------->")
print("<--------------开始可视化数据-------------->")
print("生成echarts柱状图(.html && .png)")
print("渲染图片中。。。")
make_snapshot(snapshot, build_bar_chart(data).render("好片月份分布.html"), "好片月份分布.png")
print("<--------------数据可视化完成-------------->")
print("################程序运行结束################")
if __name__ == '__main__':
main()