Linux高并发服务器开发
BIO模型
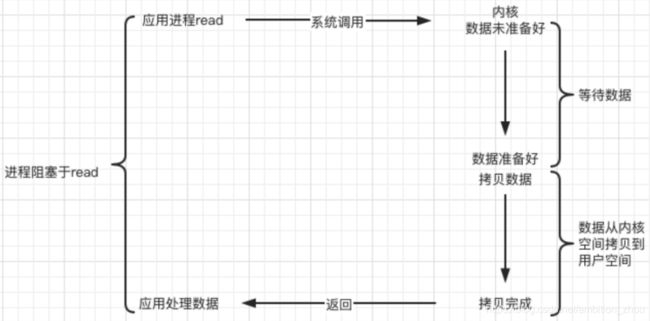
阻塞等待
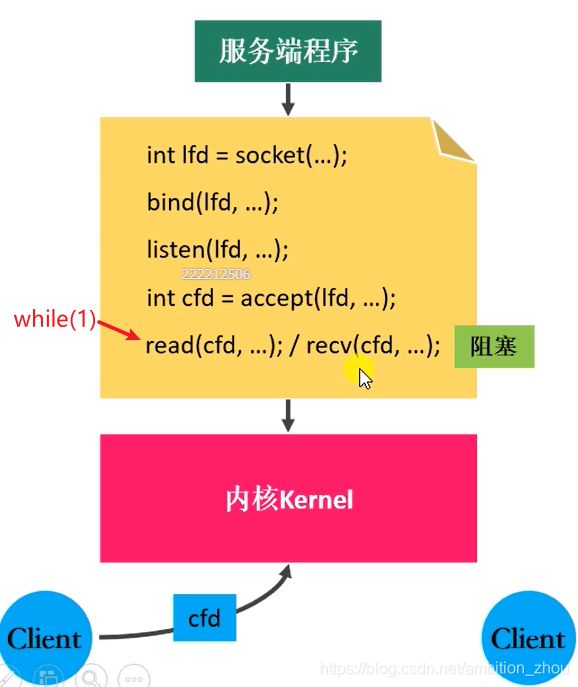
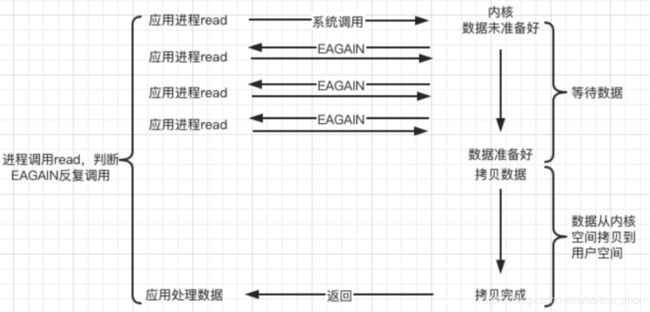
read、recv是阻塞函数,无法实现多个客户端同时请求
NIO模型
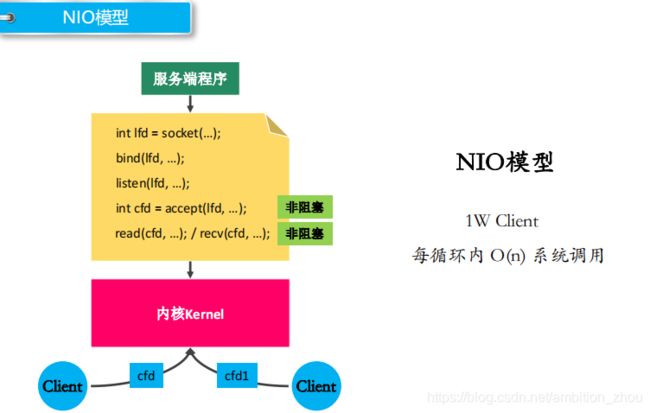
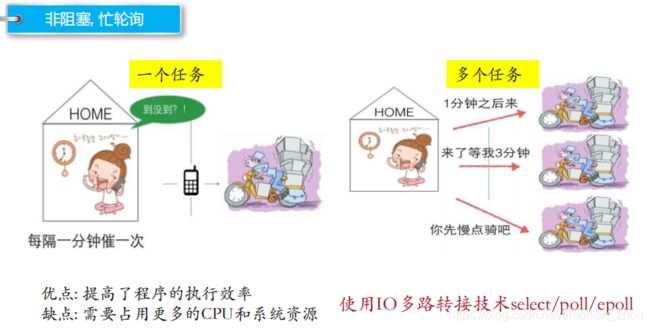
非阻塞,忙轮询
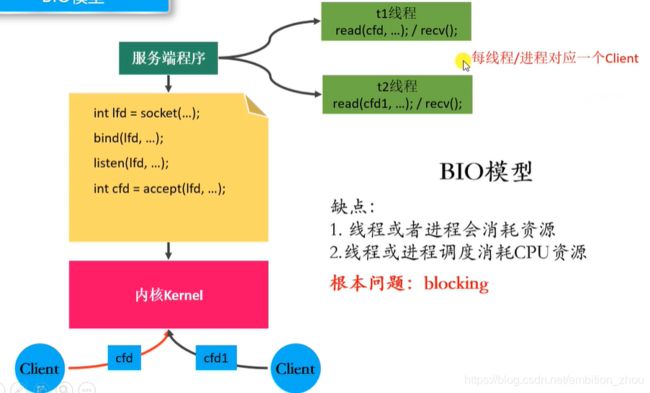
多客户端同时请求-多进程、多线程
TCP服务器通信实现(服务器、客户端)
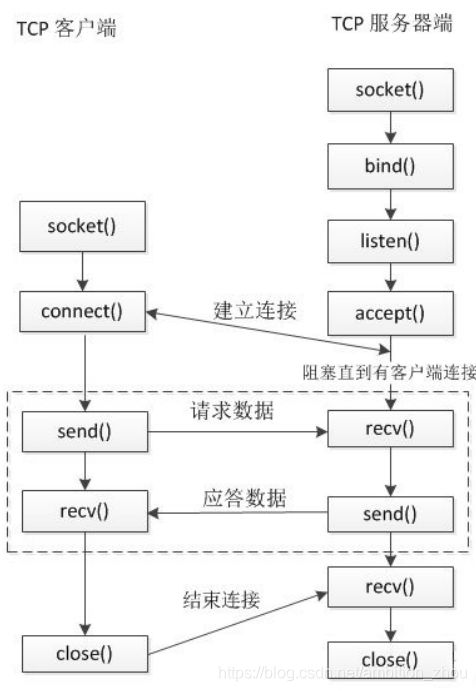
// 套接字:这是一种更为一般的进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
nRC = WSAStartup(0x0101, &wsaData);
// 这个函数是应用程序应该第一个调用的Winsock API函数,完成对Winsock服务的初始化。
srvtcpsock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// 函数执行成功返回一个新的SOCKET,失败则返回INVALID_SOCKET。
// 这时可以调用WSAGetLastError函数取得具体的错误代码。
// 所有的通信在建立之前都要创建一个SOCKET。
nRC=bind(srvtcpsock, (sockaddr *)&srvbindaddr, sizeof(sockaddr));
// 成功地创建了一个SOCKET后,用bind函数将SOCKET和主机地址绑定。
listen(srvtcpsock, 20);
// 对于服务器的程序,当申请到SOCKET,并将通信对象指定为INADDR_ANY之后,
// 就应该等待一个客户机的程序来要求连接,listen函数就是把一个SOCKET设置为这个状态
SOCKET communicatesock = accept(srvtcpsock, (sockaddr*)&thrdinfo.clientaddr, &len);
// accept函数从等待连接的队列中取第一个连接请求,并且创建一个新的SOCKET来负责与客户端会话。
err = recv(communicatesock, recvbuf, MAXN, 0);
// InetNtop()分离出IP号
// 通过已经连接的SOCKET接收数据
int ret = send(communicatesock, sendbuf, len_snd + len, 0);
// 用send函数通过已经连接的SOCKET发送数据。
closesocket(srvtcpsock); WSACleanup();
// 关闭指定的SOCKET。
// join()函数是一个等待线程函数,主线程需等待子线程运行结束后才可以结束
// (注意不是才可以运行,运行是并行的),如果打算等待对应线程,则需要细心挑选调用join()的位置
// detach()函数是子线程的分离函数,当调用该函数后,线程就被分离到后台运行,
// 主线程不需要等待该线程结束才结束程序突然退出而系统没有释放端口-端口复用
- 防止服务器重启时之前绑定的端口还未释放
- 程序突然退出而系统没有释放端口
#include
#include
// 设置套接字的属性(不仅仅能设置端口复用)
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
/*
参数:
- sockfd : 要操作的socket文件描述符
- level : 级别
- SOL_SOCKET (端口复用的级别)
- optname : 选项的名称
- SO_REUSEADDR
- SO_REUSEPORT
- optval : 端口复用的值(整形)
- 1 : 可以复用
- 0 : 不可以复用
- optlen : optval参数的大小
*/
setsockopt();
bind();服务器监听文件描述符效率低-IO多路复用
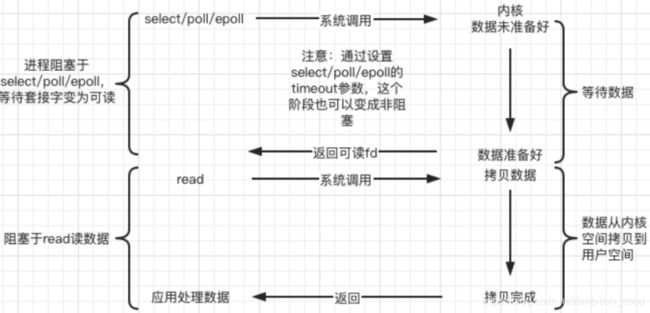
I/O 多路复用使得程序能同时监听多个文件描述符,能够提高程序的性能,Linux 下实现 I/O 多路复用的 系统调用主要有 select、poll 和 epoll。
非阻塞、忙轮询:隔一段时间询问
NIO模型:有多少个客户端,调用多少次系统调用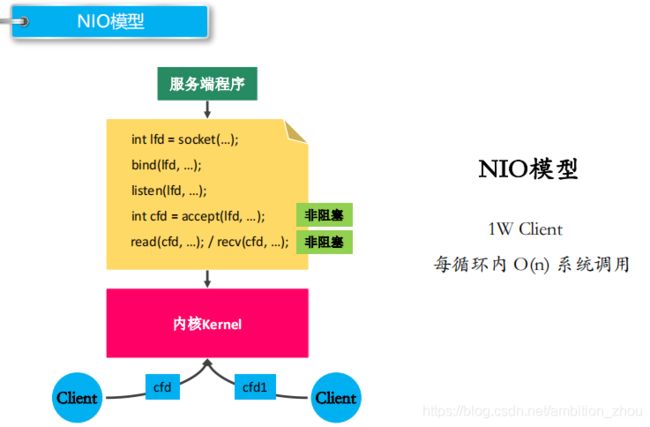
1. select
2. poll
3. epoll

项目实战
1. 阻塞/非阻塞 同步/异步(网络IO)

2. Unix/Linux 5种IO模型
a.阻塞 blocking
b.非阻塞 non-blocking(NIO)
c.IO复用(IO multiplexing)
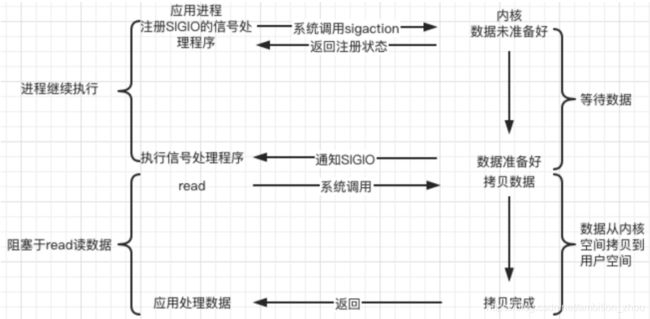
d.信号驱动(signal-driven)
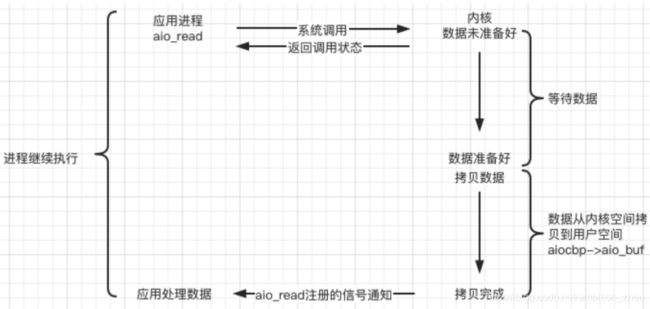
e.异步(asynchronous)
服务器编程基本框架
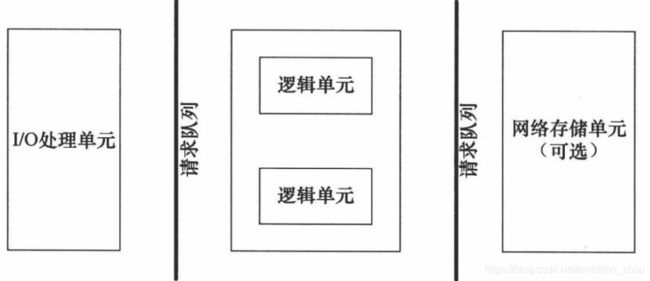
|
模块
|
功能 |
|---|---|
| I/O 处理单元 | 处理客户连接,读写网络数据 |
| 逻辑单元 | 业务进程或线程 |
| 网络存储单元 | 数据库、文件或缓存 |
| 请求队列 | 各单元之间的通信方式 |
两种高效的事件处理模式
| 事件处理模式 | Reactor | Proactor |
|---|---|---|
| IO处理模式 | 同步IO | 异步IO |
| 关注事件 | 读/写就绪 | 读/写完成 |
| 事件处理器读写 | Y(自己读取数据) | N(系统写入用户缓冲区) |
| Redis-单Reactor单进程 |
| 事件处理模式 | Reactor | Proactor |
|---|---|---|
| 简单总结 | 来了事件操作系统通知应用进程,让应用进程来处理 | 来了事件操作系统来处理,处理完再通知应用进程 |
| IO处理模式 | 同步IO | 异步IO |
| 关注事件 | 读/写就绪 | 读/写完成 |
| 事件处理器读写 | Y(自己读取数据) | N(系统写入用户缓冲区) |
| 适用场景 | 耗时短的处理场景处理高效 |
能够处理耗时长的并发场景 |
| 优点 | 实现相对简单 | Proactor性能更高 |
| 缺点 | 处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理 | 实现逻辑复杂;依赖操作系统对异步的支持 |
| 应用 | Redis-单Reactor单进程 Netty、Memcache-多 Reactor 多进程 |
Windows-IOCP 二.1 Linux-AIO |
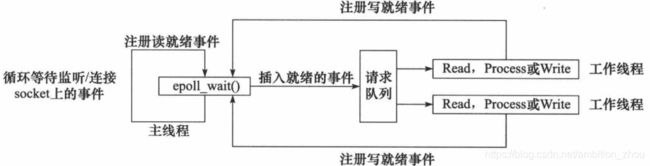
Reactor模式
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往epoll内核事件表中注册该 socket 上的写就绪事件。
- 当主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
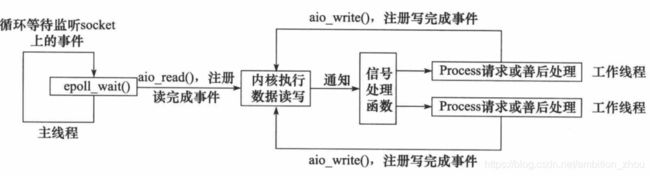
Proactor模式
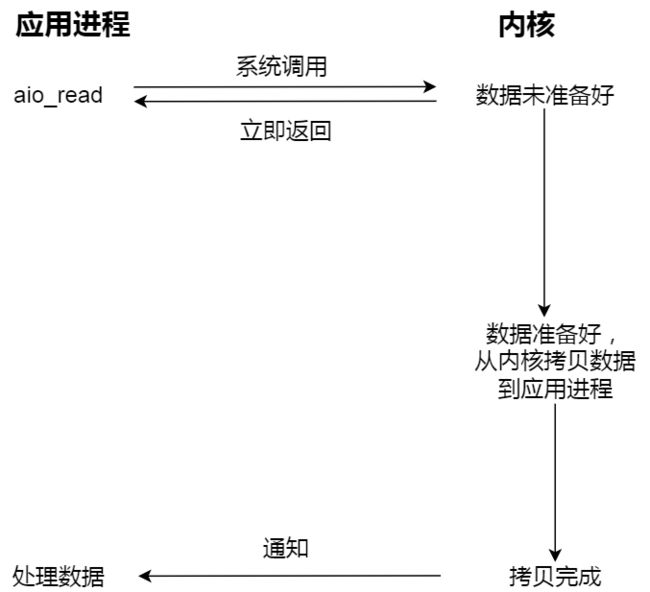
- 主线程调用 aio_read 函数向内核注册 socket 上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例)。
- 主线程继续处理其他逻辑。
- 当 socket 上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据已经可用。
- 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求后,调用 aio_write 函数向内核注册 socket 上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序。
- 主线程继续处理其他逻辑。
- 当用户缓冲区的数据被写入 socket 之后,内核将向应用程序发送一个信号,以通知应用程序数据已经发送完毕。
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭 socket。
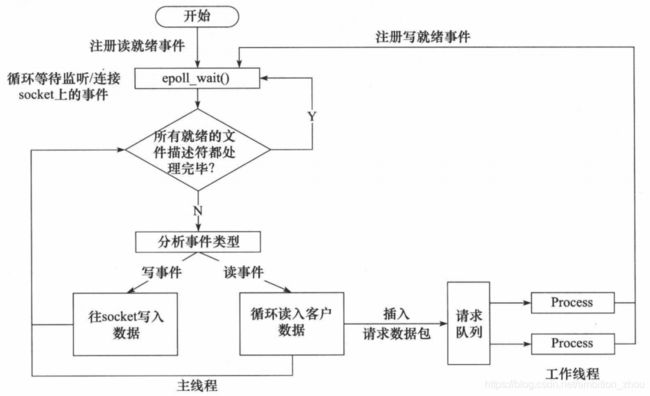
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时,epoll_wait 通知主线程。主线程从 socket 循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往 epoll 内核事件表中注册 socket 上的写就绪事件。
- 主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程往 socket 上写入服务器处理客户请求的结果。
同步 I/O 模拟 Proactor 模式的工作流程:
线程池
- 主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和 Round Robin(轮流选取)算法,但更优秀、更智能的算法将使任务在各个工作线程中更均匀地分配,从而减轻服务器的整体压力。
- 主线程和所有子线程通过一个共享的工作队列来同步,子线程都睡眠在该工作队列上。当有新的任务到来时,主线程将任务添加到工作队列中。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的”接管权“,它可以从工作队列中取出任务并执行之,而其他子线程将继续睡眠在工作队列上。
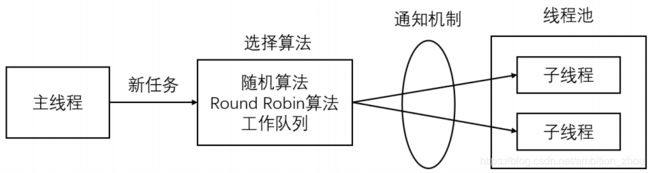
线程池线程数量限制条件:
- 空间换时间,浪费服务器的硬件资源,换取运行效率。
- 池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
- 当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中 获取,无需动态分配。
- 当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
实现线程池步骤:
- 设置一个生产者消费者队列,作为临界资源。
- 初始化几个线程,并让其运行起来,加锁去队列里取任务运行
- 当任务队列为空时,所有线程阻塞。
- 当生产者队列来了一个任务后,先对队列加锁,把任务挂到队列上,然后使用条件变撞去通知阻塞中的一个线程来处理。
有限状态机
STATE_MACHINE( Package _pack )
{
PackageType _type = _pack.GetType();
switch( _type )
{
case type_A:
process_package_A( _pack );
break;
case type_B:
process_package_B( _pack );
break;
}
}EPOLLONESHOT事件
服务器压力测试
webbench -c 1000 -t 30 http://192.168.110.129:10000/index.html
参数:
-c 表示客户端数
-t 表示时间性能瓶颈:
1. 单Reactor单进程
来源:知乎@小林coding

- 第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
- 第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。Redis 是由 C 语言实现的,它采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
2. 单Reactor多线程
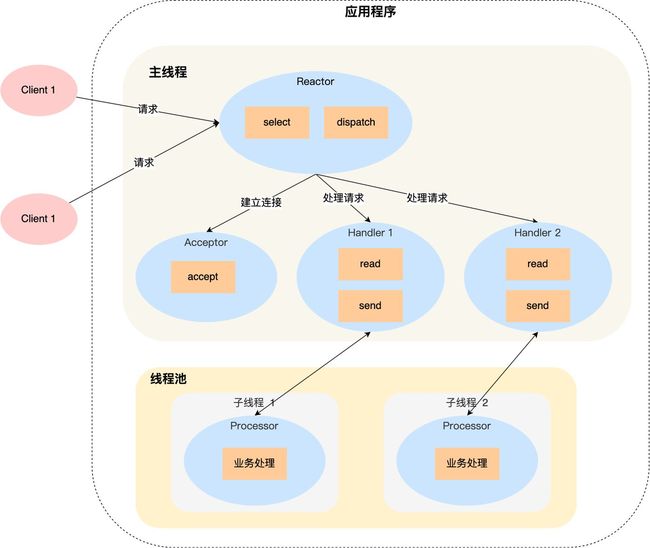
一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
3. 多Reactor多进程
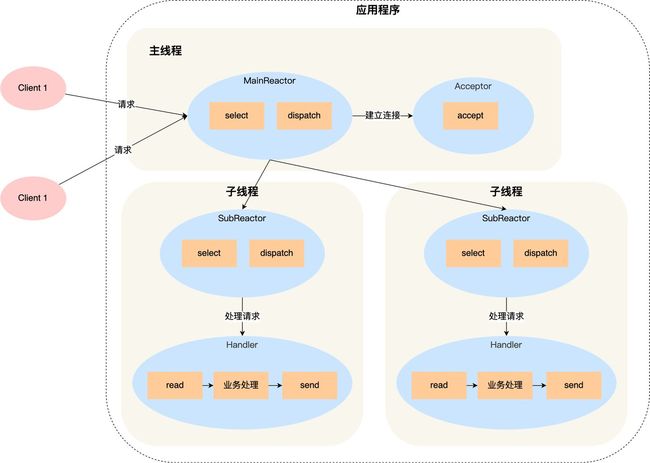
方案详细说明如下:
- 主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
- 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
- 如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
- 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
大名鼎鼎的两个开源软件 Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案。
采用了「多 Reactor 多进程」方案的开源软件是 Nginx,不过方案与标准的多 Reactor 多进程有些差异。
阻塞等待过程:
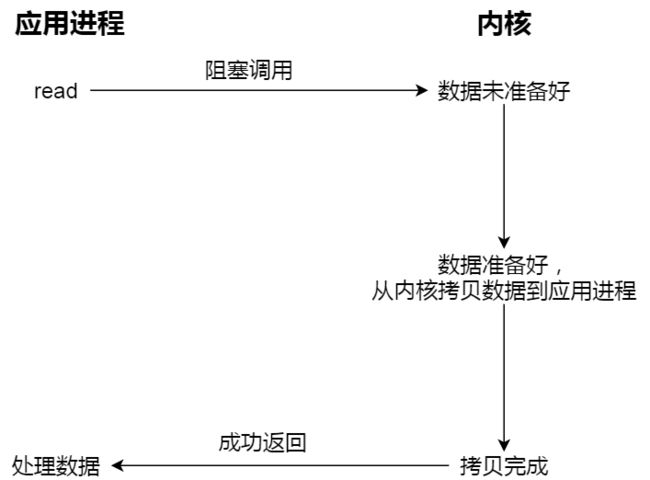
异步IO