论文阅读笔记 | 分类网络——ParNet
如有错误,恳请指出。
文章目录
- 1. Introduction
- 2. Related Work
-
- 2.1 Analyzing importance of depth
- 2.2 Scaling DNNs
- 3. ParNet Method
-
- 3.1 ParNet Block
- 3.2 Downsampling and fusion block
- 3.3 Network Architecture
- 3.4 Scaling ParNet
- 3.5 Practical Advantages or Parallel Architecures
- 4. Result
paper:NON-DEEP NETWORKS
code:https://github.com/imankgoyal/NonDeepNetworks

摘要:
深度是深度神经网络的标志,但深度越大意味着顺序计算越多延迟也越大。这就引出了一个问题——是否有可能构建高性能的“非深度”神经网络?为了做到这一点,我们使用并行子网,而不是一层接着一层堆叠,且成功实现。
作者实现了一个12层的网络结构实现了top-1 accuracy over 80%on ImageNet的效果。分析网络设计的伸缩规则,并展示如何在不改变网络深度的情况下提高性能。
1. Introduction
人们普遍认为,大深度是高性能网络的重要组成部分,因为深度增加了网络的表征能力,并有助于学习越来越抽象的特征。但是大深度总是必要的吗?这个问题值得一问,因为大深度并非没有缺点。更深层次的网络会导致更多的顺序处理和更高的延迟;它很难并行化,也不太适合需要快速响应的应用程序。
为此,作者进行了研究提出了ParNet (Parallel Networks),在一定程度上可以与SOTA进行比较,但是使用的层数只有12层。ParNet的一个关键设计选择是使用并行子网,不是按顺序排列层,而是在并行的子网络中排列层。
ParNet的子网结构中,除了开始和结束,子网之间没有连接。这使得可以在保持高精度的同时减少网络的深度,而且平行结构不同于通过增加一层神经元的数量来“扩大”一个网络。而由于具有并行的子结构,ParNet可以在多个处理器之间有效地并行化。
ParNet可以被有效的并行化,并且在速度和准确性上都优于resnet。注意,尽管处理单元之间的通信带来了额外的延迟,但还是实现了这一点。如果可以进一步减少通信延迟,类似parnet的体系结构可以用于创建非常快速的识别系统。
不仅如此,ParNet可以通过增加宽度、分辨率和分支数量来有效缩放,同时保持深度不变。作者观察到ParNet的性能并没有饱和,而是随着计算吞吐量的增加而增加。这表明,通过进一步增加计算,可以实现更高的性能,同时保持较小的深度(~ 10)和低延迟。
ParNet与一些backbone的比较:
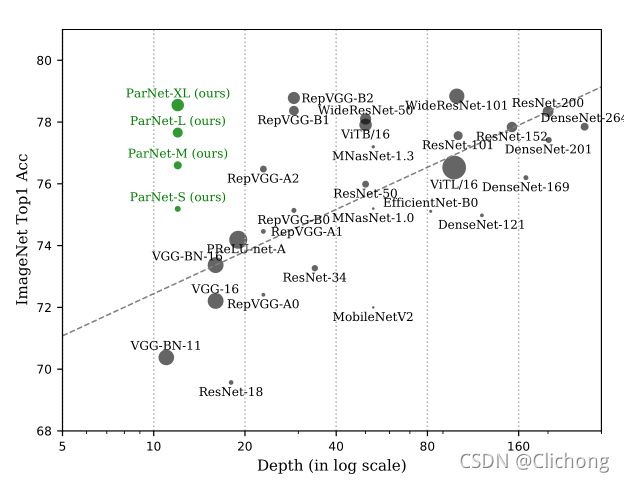
作者的主要贡献:
1)首次证明,深度仅为12的神经网络可以在非常有竞争力的基准测试中取得高性能(ImageNet上80.7%)
2)展示了如何利用ParNet中的并行结构进行快速、低延迟的推断
3)研究了ParNet的缩放规则,并证明了恒定的低深度下的有效缩放
2. Related Work
2.1 Analyzing importance of depth
已有大量的研究证实了深层网络的优点,具有sigmoid激活的单层神经网络可以以任意小的误差近似任何函数,但是需要使用具有足够大宽度的网络。而要近似函数,具有非线性的深度网络需要的参数要比浅层网络所需要的参数少,而且在固定的预算参数下,深度网络的性能优于浅层网络,这通常被认为是大深度的主要优势之一。
但是在这样的分析中,先前的工作只研究了线性顺序结构的浅层网络,不清楚这个结论是否仍然适用于其他设计。在这项工作中,作者表明浅层网络也可以表现得非常好,但关键是要有并行的子结构。
2.2 Scaling DNNs
增加深度、宽度和分辨率可以有效地缩放卷积网络。而在在保持深度不变和较低的情况下,可以通过增加分支数量、宽度和分辨率来有效地扩展ParNet。
3. ParNet Method
ParNet由并行的子结构组成,以不同的分辨率处理特征。作者把这些平行的子结构称为流。来自不同流的特征在网络的后期阶段被融合,这些融合的特征用于下游任务。ParNet的结构如图所示:
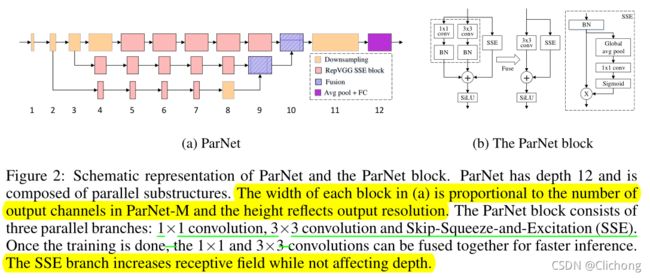
3.1 ParNet Block
在RepVGG中提出了结构重参数化的思想,简单来说就是可以将3x3卷积,1x1卷积两个分支通过代数的处理变成另外的一个3x3的卷积操作。
作者就是借鉴了Rep-VGG的初始块设计,并对其进行修改,使其更适合的非深度架构。但一个只有3×3卷积的非深度网络的挑战是感受野相当有限。为此,作者对结构进行了改进,如图所示:
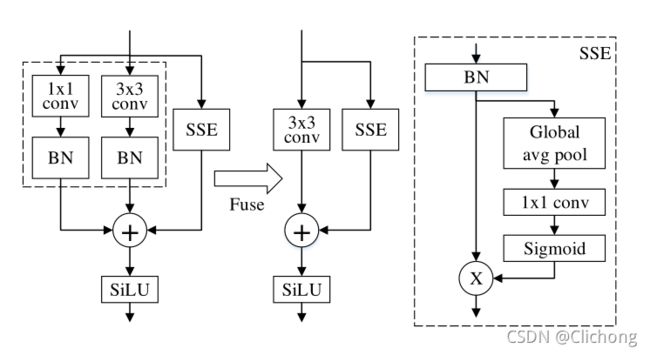
使用了一个Skip-Squeeze-Excitation的设计,这是应用在旁边的跳跃连接和使用一个单一的全连接层,这种设计有助于提高性能。作者将上图的block称为RepVGG-SSE。
另外一个问题是ImageNet这样的大规模数据集,非深度网络可能没有足够的非线性,限制了它的表征能力。因此,作者用SiLU代替ReLU激活。
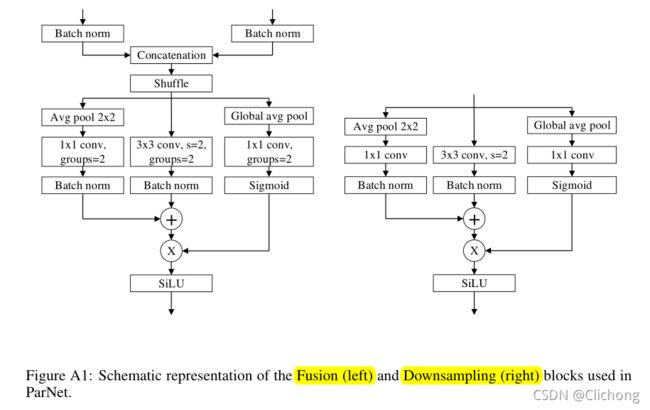
3.2 Downsampling and fusion block
RepVGG-SSE block的输入与输出的大小是相同的,此外,ParNet结构中还有Downsampling block与fusion block。
Downsampling block的作用是降低分辨率,增加宽度,以实现多尺度处理。fusion block的作用是合并来自多个分辨率的信息。
具体结构如图所示:
3.3 Network Architecture
用于ImageNet数据集的ParNet模型如图所示:

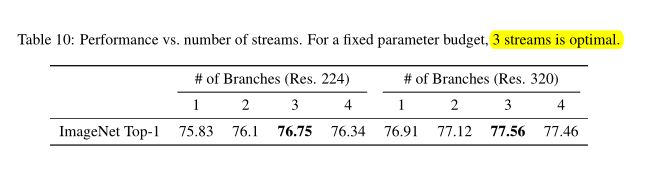
初始层由一系列的Downsampling blocks组成,Downsampling blocks中的2、3和4的输出分别被馈送到流1、2和3中,其中3个流是最优流数,如表格所示:
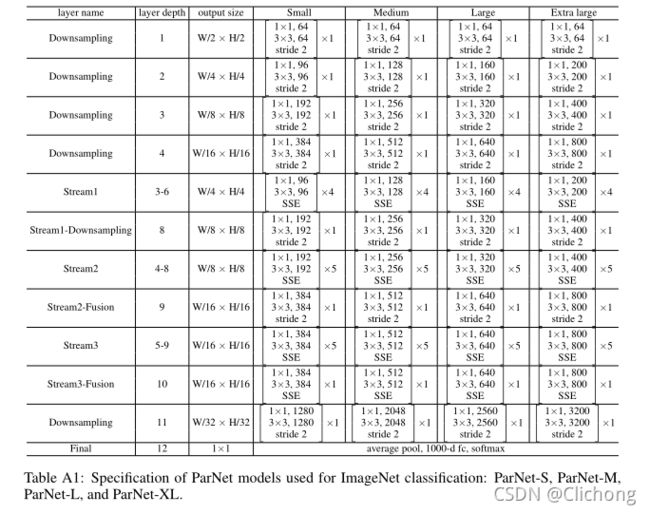
每个流都由一系列的RepVGG-SSE blocks组成来处理出不同分辨率的特征图,然后来自不同流的特征会通过Fusion blocks进行concat拼接。最后通过11层的一个Downsampling blocks,这层的下采样通道数会宽一点,具体的网络结构参数如下图:
ps:在CIFAR中,图像分辨率较低,网络架构与ImageNet略有不同。首先作者用RepVGGSSE块替换深度1和2的Downsampling块。为了减少最后一层的参数数量,将最后一个宽度较大的Downsampling块替换为更窄的1×1卷积层。此外还通过从每个流中删除一个块并添加深度为3的块来减少参数的数量。
3.4 Scaling ParNet
使用神经网络,可以观察到通过扩大网络规模可以获得更高的精度。为此,作者保持深度不变,通过增加宽度、分辨率和流的数量来扩大ParNet。
对于CIFAR10和CIFAR100,作者增加了网络的宽度,同时保持分辨率为32,流的数量为3。对于ImageNet,作者通过改变所有三个维度来进行实验。
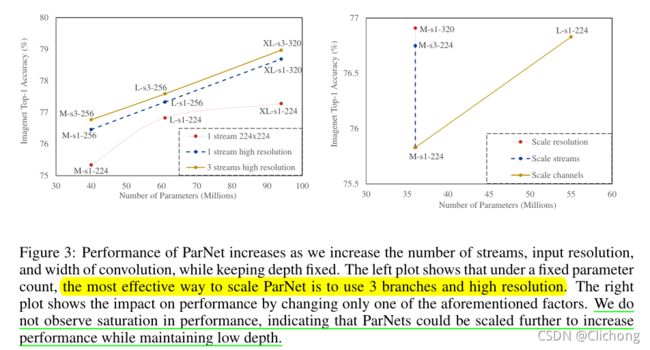
3.5 Practical Advantages or Parallel Architecures
目前的5纳米光刻工艺正在接近0.5纳米尺寸的硅晶格,进一步增加处理器频率的空间有限。这意味着更快的神经网络推断必须来自并行计算。
4. Result
-
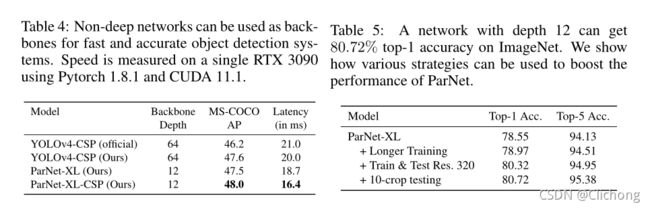
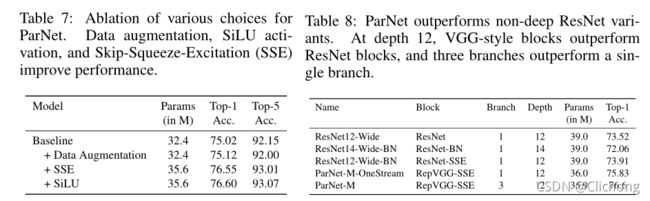
训练时的消融实验:
-
结构的消融实验:
-
与其他backbone在 CIFAR10与CIFAR100的对比:
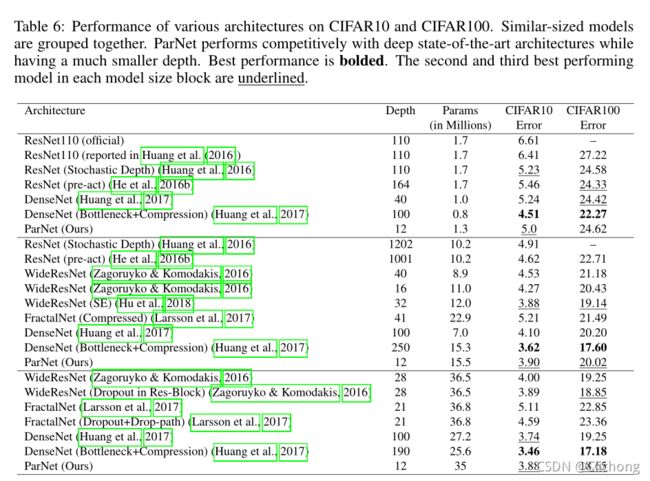
总结:
作者提出了浅层网络能否达到深层网络同样的效果,提出了浅网多分支(流融合)的思想,结合RepVGG的结构重参数化,在训练与推断过程中适当的解耦,使得浅网的性能达到了一定的可比性。