文章来源 | 恒源云社区(专注人工智能/深度学习GPU免费加速平台,官方体验网址:https://gpushare.com)
原文作者 | Mathor
原文地址 | https://gpushare.com/forum/to...
个人觉得2021年NLP最火的两个idea,一个是对比学习(Contrastive Learning),另一个就是Prompt
浅谈我对 Prompt 的理解
Prompt 说简单也简单,看了几篇论文以及博客后发现其实就是构建一个语言模版。但是细想起来又觉得复杂,因为总感觉里面还有很多细节,因此本文就来从头梳理一下 Prompt(Prompt 很多地方会翻译成「范式」,但是「范式」这个词本身也不好理解,因此读者把他看作是「模板」即可)
今天我还与室友讨论预训练模型(例如 BERT)到底做了什么,我给出的回答是
预训练模型提供了一个非常好的初始化参数,这组参数在预训练任务上的表现非常好(预训练损失非常低),但是由于下游任务千奇百怪,我们需要在这组参数的基础上进行 Fine-tune 以适应我们的下游任务(使得下游任务的损失值非常低)
上面这段话其实隐含了目前做 NLP 任务的大致流程,即 "Pre-train, Fine-tune",而对我们来说实际上大部分时候都是直接拿别人预训练好的模型做 Fine-tune,并没有 Pre-train 这一步
融入了 Prompt 的模式大致可以归纳成 "Pre-train, Prompt, and Predict",在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有 MLM(Masked Language Model),在文本情感分类任务中,对于 "I love this movie" 这句输入,可以在后面加上 Prompt:"the movie is ___",组成如下这样一句话:
I love this movie, the movie is ___然后让预训练模型用表示情感的答案(例如 "great"、"terrible" 等)做完形填空,最后再将该答案转换为情感分类的标签。这样一来,我们就可以通过构造合适的「模板」,通过小样本数据集训练一个模型来解决各种各样的下游任务
注意,Prompt 设计的这种完形填空和 MLM 任务是有区别的,二者虽然都是都是词分类,但是候选集不同,MLM 的候选词是整个词库,不过如果是生成任务,那么 Prompt 和 MLM 的候选集就是一样的,都是整个词库
如何构建 Prompt
对于输入文本 \( x\) ,存在一个函数 \(f\)Prompt(x),将 \(x\) 转化成 \(x′\) 的形式,即
$$ x^{’}=f_{\text{Prompt}}(x) $$
该函数通常会进行两步操作:
- 使用一个模板,模板通常为一段自然语言句子,并且该句子包含两个空位置:用于填输入 \(x\) 的位置 \([X]\)、用于生成答案文本 \(z\) 的位置 \([Z]\)
- 把输入 \(x\) 填到 \([X]\) 的位置
以前文提到的例子为例,在文本情感分类任务中,假设输入是
x = "I love this movie"使用的模板是
[X]. Overall, it was a [Z] movie那么得到的 \(x′\) 就应该是
I love this movie. Overall, it was a [Z] movie在实际情况中,Prompt 来填充答案的位置一般在句中或句末。如果在句中,一般称这种 Prompt 为 Cloze Prompt;如果在句末,一般称这种 Prompt 为 Prefix Prompt。 \([X]\) 和 \([Z]\) 的位置、数量以及使用模板句的不同,都有可能对结果造成影响,因此需要灵活调整
上面讲的都是简单的情感分类任务的 Prompt 设计,读者看到这里自然而然的会想到,其他 NLP 任务的 Prompt 如何设计呢?实际上刘鹏飞大神在他的论文中给我们提供了一些参考
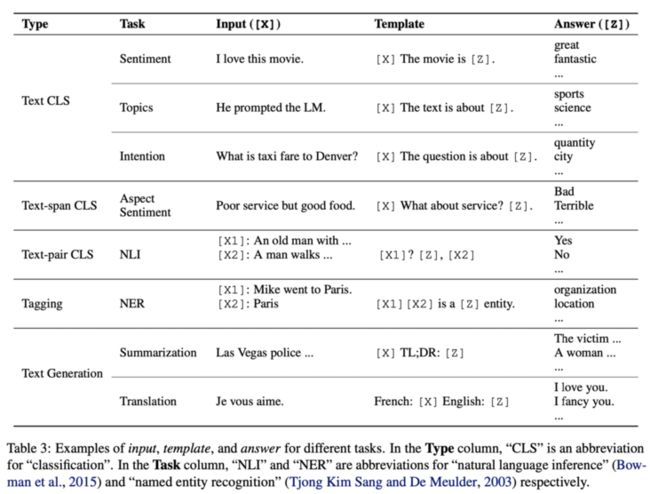
Text Generation 中摘要任务里有一个关键字TL;DR,这其实是Too Long; Don't Read的缩写
Prompt 的选择非常重要且困难
有上述 Prompt 的基础后,我们可以得知 Prompt 的设计主要包含两部分:
- 模板 T:例如
[X]. Overall, It was [Z] - 标签词映射:即 \([Z]\) 位置预测输出的词汇集合与真实标签 \(y\) 构成的映射关系。例如,标签 positive 对应单词 great,标签 negative 对应单词 terrible
在基于 Prompt 的微调方法中,不同的模板和标签词对最终结果影响很大,下图是陈丹琦团队论文中的实验结果

从上图我们可以看出两点:
- 使用相同的「模板」,不同的「标签词」会产生不一样的效果。例如
great/terribel和cat/dog这两组标签词的效果不一样,而且即便是相同标签词,互换顺序也会导致最终效果有所变化,例如cat/dog和dot/cat - 使用相同「标签词」,对「模板」进行小改动(例如增删标点)也会呈现不同的结果
Prompt 的设计
Prompt 大概可以从下面三个角度进行设计:
- Prompt 的形状
- 人工设计模板
- 自动学习模板
Prompt 的形状
Prompt 的形状主要指的是 \([X]\) 和 \([Z]\) 的位置和数量。上文提到的 Cloze Prompt 与 Maksed Language Model 的训练方式非常类似,因此对于 MLM 任务来说,Cloze Prompt 更合适;对于生成任务或者使用自回归 LM 解决的任务,Prefix Prompt 更合适
人工设计模板
Prompt 的模板最开始是人工设计的,人工设计一般基于人类的自然语言知识,力求得到语义流畅且高效的「模板」。例如,Petroni 等人在著名的 LAMA 数据集中为知识探针任务人工设计了 Cloze Templates;Brown 等人为问答、翻译和探针等任务设计了 Prefix Templates。人工设计模板的优点是直观,但缺点是需要很多实验、经验以及语言专业知识。下图是 GPT Understands, Too 论文中的一个实验结果

可以看到不同的 Prompt 只有细微的区别,有的甚至只是增加减少一个词,但是最后的结果会差几十个点
自动学习模板
为了解决人工设计模板的缺点,许多研究员开始探究如何自动学习到合适的模板。自动学习的模板又可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。离散方法主要包括:Prompt Mining,Prompt Paraphrasing,Gradient-based Search,Prompt Generation 和 Prompt Scoring;连续的则主要包括 Prefix Tuning,Tuning Initialized with Discrete prompts,Hard-Soft Prompt Hybrid Tuning,P-Tuning v2
离散 Prompts
简单说一下上述几种方法,首先是离散的 Prompt Mining,这篇文章发表在 TACL 2020,讲的是如何拿预训练语言模型当作「知识库」使用,并且引入了依存树和 Paraphrase(转述)等方法来挖掘更好的「模板」,下图是实验结果
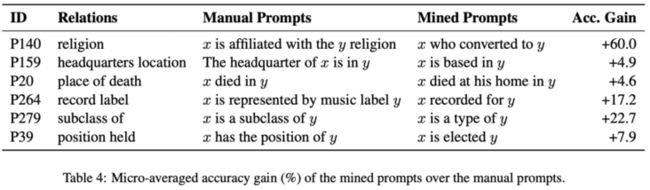
可以看到,被挖掘出来的若干「连接谓词」相比于人工设计的「模板」结果提升还是很明显的
有很多种方法可以实现 Prompt Paraphrsing,例如「回译」,我们通过 DeepL 翻译看个例子:


这样我们就得到了 x shares a border with y 的一个 Prompt Paraphrasing:x and y share a boundary
论文 BARTScore 干脆给我们提供了一张表,里面有各种词组的同义替换,这个我再熟悉不过了,因为以前英语考试我也背过类似的东西
Gradient-based Search(基于梯度的搜索)是由论文 AUTOPROMPT 提出的,这篇文章发表在 EMNLP 2020,它的主要思想用下面这张图就可以表示

上图中,a real joy 是原始的输入句子 \(xinp\),红色的 Trigger tokens 是由 \(x\)inp「激发」的相关词汇集合 \(x\)trig,根据 Template \(λ\) 的配置,将 \(x\)trig 和 \(x\)inp 组合起来构造最终的输入 \(x\)prompt,送入 Masked LM 预测情感标签。下面的表格增加了很多 NLP 其他任务的例子
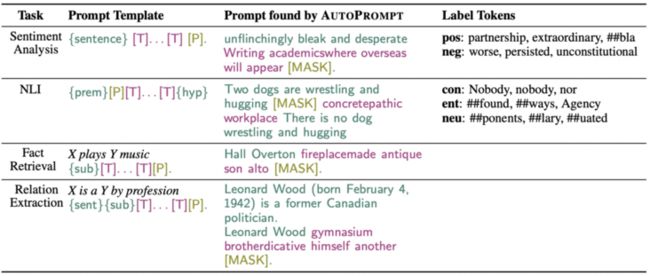
关于如何生成 \(x\)trig 集合,实际上主要使用的是 HotFlip 和对抗训练的思想,感兴趣的同学可以看原论文以及 HotFlip: White-box adversarial examples for text classification、 Universal Adversarial Triggers for Attacking and Analyzing NLP 这两篇论文
Prompt Generation 是陈丹琦团队的一项工作,主要是把 Seq2Seq 预训练模型 T5 应用到模板搜索的过程。T5 基于多种无监督目标进行预训练,其中最有效的一个无监督目标就是:利用 \(
Thank you me to your party week T5 会在 for inviting,在 \(last。很显然,T5 这种方式很适合生成模板,而且不需要指定模板的 token 数。具体来说,有三种可能的生成方式
<\(S_1\)> →<\({X}\)> \({M}(y)\) <\({Y}\)> <\(S_1\)>
<\(S_1\)> → <\(S_1\)><\({X}\)>\({M}(y)\) <\({Y}\)>
<\(S_1\)> <\(S_2\)>→ <\(S_1\)> <\({X}\)> \({M}(y)\) <\({Y}\)> <\(S_2\)>
具体的模板生成过程如下图所示:
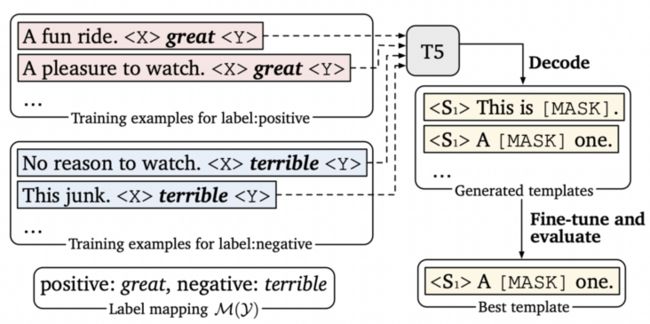
首先在标签词前后添加填充位 \(
我还想说一下这篇论文中另外一个有意思的点,最后送入模型进行预测的句子还拼接上了每种类别的「示例」(Demonstration),如下图所示

这种 Prompt 的设计有点像是在做语义相似度任务,\(X\) 为原始 Input 句子,已知 \(Y\) 为正例,\(Z\) 为负例,构造了如下形式的输入:
X是[MASK]例?Y为正例;Z为负例这有点像是编程语言中的三目运算符,或者说相当于让模型比较 \(X\) 与 \(Y\)、\(Z\) 的语义相似度。这里我们自然而然会想问:\(Y\)、\(Z\) 是如何挑选出来的?实际上是依据下面两条规则:
- 对于每个原始输入句子,从每个类别中随机采样一个样本「示例」拼接到 Prompt 中
- 对于每个原始输入句子,在每个类别中,通过与 Sentence-BERT 进行相似度计算,从相似度最高的前 50% 样本中随机选择一个样本「示例」
连续 Prompts
构造 Prompt 的初衷是能够找到一个合适的方法,让 Pre-trained Language Model(PLM)更好地输出我们想要的结果,但其实并不一定要将 Prompt 的形式设计成人类可以理解的自然语言,只要机器理解就行了。因此,还有一些方法探索连续型 Prompts—— 直接作用到模型的 Embedding 空间。连续型 Prompts 去掉了两个约束条件:
- 模版中词语的 Embedding 可以是整个自然语言的 Embedding,不再只是有限的一些 Embedding
- 模版的参数不再直接取 PLM 的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整
Prefix Tuning 最开始由 Li 等人提出,这是一种在输入句子前添加一组连续型向量的方法,该方法保持 PLM 的参数不动,仅训练前缀(Prefix)向量。Prefix Tuning 的提出主要是为了做生成任务,因此它根据不同的模型结构定义了不同的 Prompt 拼接方式,在 GPT 类的 Auto-Regressive(自回归)模型上采用的是 \([Prefix;x;y]\) 的方式,在 T5 类的 Encoder-Decoder 模型上采用的是 \([Prefix;x;Prefix\)′\(;y]\) 的方式

输入部分 \(Prefix,x,y\) 的 Position id 分别记作 \(Pidx,Xidx,Yidx\)。Prefix Tuning 初始化一个可训练的矩阵,记作 \(P\)θ\(∈R\)|Pidx|×dim(hi),其中

上述公式的含义是,索引 \(i\) 如果属于前缀的部分,则从 \(Pθ\) 中抽取向量;\(i\) 如果不是前缀部分,则由参数固定的预训练模型生成对应的向量。训练目标为:
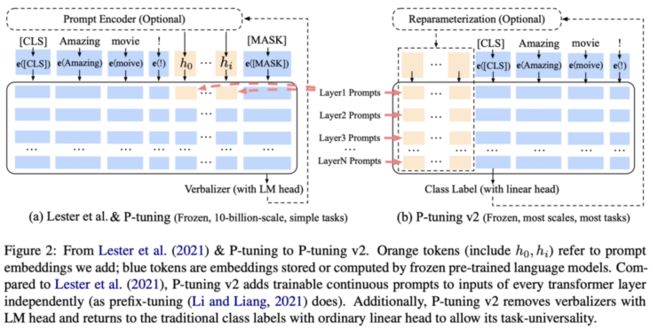
$$ \mathop{\text{max}}\limits_{\phi} \ \log p_{\phi}(y\mid x) = \sum\limits_{i\in \text{Y}{\text{idx}}} \log p{\phi} (z_i\mid h_{ 同样是在连续空间上搜索 Prompt,OptiPrompt 构建的「模板」并不局限于前缀,也可以在句子的中间 首先根据 AutoPrompt 定义一个 Prompt 模板: $$ [x]\ [v]_1\ [v]_2\ …\ [v]_m\ [\text{MASK}] $$ 其中 \([v]i\) 为一个连续型向量(与 BERT 的输入维度一致)。OptiPrompt 还考虑以人工构建的离散 Prompt 作为起点,在连续空间上进行搜索以构建较优的 Prompt。例如 \([x] is [MASK] citizen\) 可以转换为 $$ [x]\ [v]_1\ [\text{MASK}]\ [v]_2 $$ 将 Hard-Soft Prompt Hybrid Tuning 方法可以说是人工设计和自动学习的结合,它通常不单纯使用可学习的 Prompt 模板,而是在人工设计的模板中插入一些可学习的 Embedding。实际上有了上面的基础我们都知道,连续的 Prompt 要比离散的 Prompt 好一点,但是在此基础上还有什么改进的余地吗?Liu 等人提出的 P-Tuning 解决了 Prompt token 之间的关联性问题 之前连续的 Prompt 生成方式无非都是训练一个矩阵,然后通过索引出矩阵的某几行向量拼起来。坦白地说,我们希望这些 prompt token Embedding 之间有一个比较好的关联性,而不是独立地学习,为了解决这个问题,P-Tuning 引入了一个 Prompt Encoder(如下图 b 所示) 上图 a 是传统的离散型 Prompt,我们把生成离散 Prompt token 的东西叫做 Prompt Generator;上图 b 首先传入一些 Virtual(Pseudo)token,例如 BERT 词表中的 [unused1],[unused2],... 当然,这里的 token 数目是一个超参数,插入的位置也可以调整。将这些 Pseudo token 通过一个 Prompt Encoder 得到连续的向量 \(h0,...,hm\),其中 即,Prompt Encoder 是由 BiLSTM+MLP 组成的一个简单网络。作者还发现加入一些 anchor token(领域或者任务相关的 token)可以有助于 Template 的优化。例如文本蕴含任务,输入是前提和假设,判断是否蕴含。一个连续的模版是 $$ \text{[PRE]} [\text{continuous tokens}][\text{HYP}][\text{continuous tokens}] [\text{MASK}] $$ 在其中加入一个anchor token: $$ \text{[PRE]} [\text{continuous tokens}][\text{HYP}]?[\text{continuous tokens}] [\text{MASK}] $$ 大家可能想问,如何优化 P-tuning?实际上根据标注数据量的多少,分两种情况讨论 就在 P-Tuning 方法提出不久后,Liu 等人又提出了 P-Tuning v2,主要解决 P-Tuning 的两个问题: Liu 等人认为先前的 P-Tuning 只用了一层 BiLSTM 来编码 Pseudo token,这是其推理能力不足的原因之一,因此 v2 版本提出 Deep Prompt Tuning,用 Prefix Tuning 中的深层模型替换 BiLSTM,如下图所示 P-Tuning v2 相比于 P-Tuning,区别在于: 关于 P-Tuning 还有一些碎碎念,主要是从各个博客上看到的,汇总在这里。首先是 v1 版本的 LSTM,实际上引入 LSTM 目的是为了帮助「模板」生成的 token(某种程度上)更贴近自然语言,或者说 token 之间的语义更流畅,但更自然的方法应该是在训练下游任务的时候,不仅预测下游任务的目标 token(例如 "great"、"terrible"),还应该同时做其他 token 的预测 比如,如果是 MLM 模型,那么也随机 MASK 掉其它的一些 token 来预测,如果是 LM 模型,则预测完整的序列,而不单单是目标词。这样做的理由是:因为我们的 MLM/LM 都是经过自然语言预训练的,所以我们认为它能够很好的完成序列的重构,即便一开始不能,随着迭代轮数的增加,模型也能很好完成这项任务。所以这本质上是让模型进行「负重训练」 在标准的 Fine-tune 过程中(如上图 b 所示),新引入的参数量可能会很大(独立于原始预训练模型外的参数),例如基于 RoBERTa-large 的二分类任务会新引入 2048 个参数( 为解决这一问题,Prompt 应运而生(如上图 a 所示),直接将下游任务转换为输出空间有限的 MLM 任务。值得注意的是:上述方法在预训练参数的基础上进行微调,并且没有引入任何新参数,同时还减少了微调和预训练任务之间的差距。总的来说,这可以更有效地用于小样本场景 尽管 Prompt 研究搞得如火如荼,但目前仍存在许多问题值得研究者们去探究 最后我还想提一个实际 Code 过程中存在的问题。我们知道 MLM 任务会输出句子中 [MASK] 位置最有可能的词,而 Prompt 也类似的,例如下面的例子 这是一个新闻分类问题,真实标签有 "体育"、"财经"、"娱乐" 等,上面的样本很明显是一条体育新闻,因此我们希望模型对 [MASK] 部分输出 "体育",但事实真的如此吗?实际情况模型的输出可能是 "足球",但你认为模型预测的 "足球" 有问题吗?好像也没啥毛病,因此这就引申出了 Prompt 的一个问题,是否应该限制模型的输出空间? 还是上面新闻分类的例子,我们是否应该限制模型输出的空间,让他固定只能预测 "体育"、"财经"、"娱乐" 这几个标签?或者我们干脆把这几个标签换成索引,那就是让模型从 0,1,2 这三个数字选一个。Wait Wait Wait,如果这么做的话,和 Fine-Tune 有什么区别,Fine-Tune 也是把标签转换成索引,让模型看了句子之后,从这几个索引中选一个作为预测值 这么说的话,那我们就不应该限制模型的输出空间,可是这样的话 [MASK] 位置的输出就限制的太死了,必须一定是 "good"、"财经" 才算对,如果输出 "nice"、"财政" 就算错。实际上输出近义词或者相似词,在零样本的情况下会经常出现,但是如果你用一些有标签的样本去训练,模型自己就会慢慢固定输出空间。例如 "财经",它不会预测成 "财政",只会预测成其它类型的新闻,例如 "体育"
\(P\)θ本质上是一个矩阵,而生成一个矩阵的方法又很多,可以用
nn.Embedding(),或者
nn.Linear()

is 和 citizen 对应的 input Embedding 作为 \([v]1\) 和 \([v]2\) 的初始化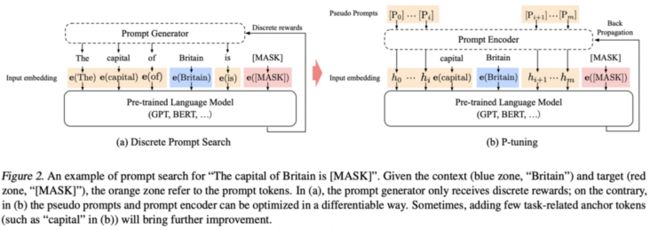

[?]效果会更好,此时模板变成
* 为什么要引入 Prompt?

nn.Linear(1024, 2)),如果你仅有例如 64 个标注数据这样的小样本数据集,微调会非常困难Prompt 的挑战与展望
One More Thing
这是一条__新闻。中国足球出线的可能性只有0.001%,留给中国队的时间不多了References