简介
姓名:徐新宇
细分场景:物联网行业下移动app+人脸识别在工业安卓平板的应用
(注:公司项目信息脱敏,相关图片替换为网络图片,本人无意侵犯版权,已表明相关出处)
一.项目背景
公司是一家物联网公司,意向自研一款人脸会议考勤签到面板机,为了提高产品竞争力,主打性价比+定制化差异(硬件便宜好用,软件页面炫酷叼炸天);软件研发部需要支撑配套的人脸会议考勤安卓平板应用。主要业务功能有:人脸识别功能(人脸采集、对比识别、人脸库管理),会议模块,考勤签到功能,定制化互动模块。
人脸识别交互示意图(图片来源谷歌图片)
(原页面实现由识别定位框+骨骼轮廓图+信息卡片+动画构成)
与硬件产品经理的沟通后,提供一套样机和一套产品清单来支撑软件研发的开发和测试。
主板是RK3288四核 1.8GHZ.2g内存。8G存储的板子,安卓5.1的操作系统。屏幕是15.6英寸 1920*1080分辨率 10点式电容触摸屏。
RK3288主板示意图(图片来源谷歌图片)

RK3288主板核心参数
框架选型是使用的React Native+tracker.js,考虑控制成本,没有集成市面上的Android人脸识别SDK。通过经验使用tracker.js替代opencv实现端的人脸识别捕捉,服务端实现人脸对比(这里为后续的错误埋下了伏笔),经过一段时间加班加点,开发了人脸会议考勤系统V0.1-Alpha版。
采购流程是比较慢的,等到开发板到了开始一轮真机测试运行,搞了一轮以后组员说束手无策,别的机子都好好的,就这个不行,怀疑硬件问题。
排除硬件原因后,我整体的牵头开始对于系统进行性能优化。
一、问题以及所遇到的挑战
1.问题
1.人脸识别不流畅,人画不同步,明显延迟,人员高频次出入镜头框会伴随顿挫感。
2.POE供电,长时间运行软件运行发热发烫。
3.概率偶发性闪退现象,捕捉不到有价值的异常日志。
2.挑战
1.没有使用纯安卓开发(组员基本不会安卓原生开发)+人脸识别安卓SDK(控制成本的诉求)。限制了性能的上限。
2.硬件性能低。RK3288处理器,搭载的Mali-T764GPU,在14年当年算是神U,被誉为国产最强ARM处理器,但是已经6、7年过去了,我们采用的也是基础版。安卓板人脸机还需要内置一些其他相关软件,对性能和稳定性的要求还是比较高的。
3.概率性存在ANR/闪退崩溃问题,报错模糊,定位不到问题。
4.组员整体为前端开发人员,对于app的优化和调试经验不足。
二.解决问题的步骤
1.复盘设计
忠告,先不要盯着问题本身。尤其是对于性能问题,这是大忌。这是对于很多开发人员都容易犯的错误,甚者用精妙的技巧去掩盖系统设计上的缺陷。(产品设计,架构设计,原型设计,交互设计,UI设计等等)
如果系统运行或者测试中出现了远高于阈值的问题,第一步一定是先回过头来看系统的看设计。(一定是)
没有经验的程序员会一头扎入bug中,富有经验的程序员会利用自有的思维方式了解问题,定位问题,分析问题,解决问题,验证问题。而作为一个合格的架构师,或者技术团队的leader。一定要学会“揪头发”思维。
很多系统需要优化的问题,往往并不仅仅是一个技术问题,根源上可能是一个不合理的产品设计,冗余的架构,反人类的交互,层次过深的UI导致的。而由于系统的复杂度和团队的沟通成本以及后期需求变动与场景的细化,往往在项目初期有些问题是很难暴露的。所以对于软件系统的性能优化,第一步要复盘之前的设计与行为是否合理。
而事实上,所谓的差异化设计,在通过梳理精简,剔除掉不合理因素后,对于一个工业平板app它的动画和交互还是太复杂了。
2.数据分析
本项目人脸检测验收标准:
包大小:~ 100M
最小人脸检测大小:50px * 50px
可识别人脸角度:yaw ≤ ±30°, pitch ≤ ±30°
检测速度:100ms 720p*
追踪速度:50ms 720p*
人脸检测耗时:< 200ms
人脸库检索速度:< 100ms
检测+识别全流程耗时 < 500ms(app其他性能指标不做过多叙述)
工程化的一个要素就是用设定的标准去衡量离散型数据。如果优化没有可量化的渲染性能评判标准,就是开发者\leader拍脑门决定了,所以不仅仅是测试人员需要了解这些指标,开发者也要学会使用测试工具去定位问题、验证数据。
ok开始行动, Android adb网络连接安卓主板测试,安装apk。
1.渲染模式分析
打开安卓开发者模式,检查 GPU 渲染速度和过度绘制,筛选出渲染压力过大的页面,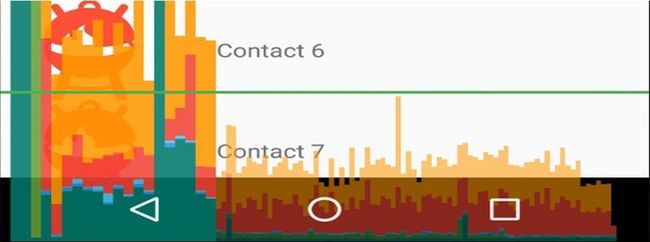
GPU 渲染模式分析示意图(图片来源百度)
渲染颜色说明
过度绘制:实际上对于过度绘制相关的优化,要考虑投入产出比,过于精细的优化整体产出是不高的,该项目中只对于过度绘制红色区域(过度绘制4次及以上区域)进行优化。
2.分析耗电情况
由于软件伴有运行发热发烫的现象,那么一定要分析耗电情况。
耗电统计是系统组件,也就是说系统运行他就一直在统计。所以获取统计报告的时候需要将统计重置。
1.先断开adb服务,然后开启adb服务
杀死adb服务:执行adb kill-server 防止冲突和脏数据。
重启adb: 执行adb devices或者adb start-server2 .重置电池数据收集
adb shell dumpsys batterystats --enable full-wake-history
adb shell dumpsys batterystats --reset
正常情况下,我们应该断开充电器并断开usb连接(连接时充电),这样会大大影响统计有效性。但是由于我们是poe供电,具体情况具体分析,使用数据辅助查找异常点。因为我们是5.1系统,所以使用adb命令:
![]()
由于txt报告实在是比较大,10几个m肉眼看不太现实,一般都配合Battery Historian这个工具来使用。
(注意:Battery Historian是android 5.0(api 21)及以上使用,如果有幸还在使用安卓4.4工业面板的可以略过此条了。)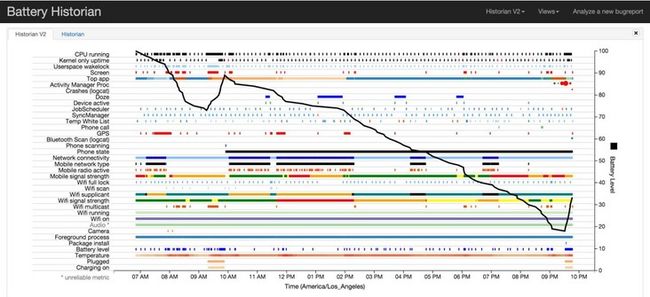
Battery Historian示例图(图片来源百度)
3.线程活动与CPU分析
线程活动与CPU分析 工具有很多,但是Android Studio自带的他不香吗?(Rn安卓打包还是用Android Studio,使用vscode打包坑太多了。)
针对异常点进行分析。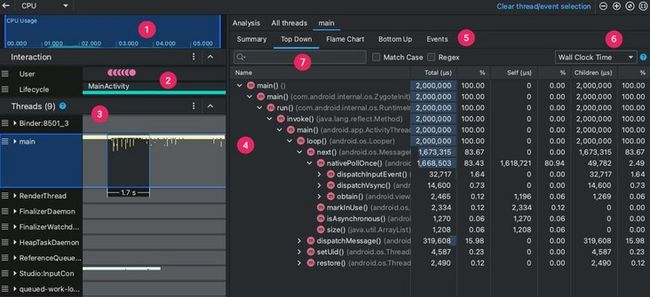
Android Studio CPU 分析器 示例图
(图片来源https://developer.android.com/)
4.数据汇总
数据显示CPU的负担过重,tracking导致进程有阻塞现象。
实际上大家一直认为是完全由于渲染压力大导致的页面卡顿,(渲染是RN 整个框架的瓶颈),报表数据显示的恰恰相反,对于人脸识别,GPU并没跑满,图形界面的渲染工作只有部分由GPU进行的,当tracking阻塞后会暂时等待发生卡顿,再逐个完成canvas 关键点渲染定位,调用接口,取得返回数据后渲染信息卡片和执行动画时导致第二次轻微卡顿(RN渲染卡顿),然后性能反应正弦函数波动,同时卡顿和不流畅现象消失。
导致“拍脑袋”定位问题就是因为前端同事对于日志和数据分析工具的使用是普遍不够的。
3.定位问题
定位问题的方法有多种,像大家常用的二分查找法(二分注释、二分回滚)。或者 断点调试、分析日志。都可以有效的帮助我们快速定位问题。
那么通过数据的分析以及工具提供的关键类,我们也是比较清晰的找出了问题:信息卡片动画+canvas特效+人脸识别相关函数。
4.分析问题
原有的实现方式:引入全部的相关js,new多个tracking.objectTracker来检测人脸、眼睛、嘴的区域。在通过canvas实现人脸关键点的展示效果

Tracking.js文件目录示意图
而对人脸进行采集。Tracking.js 是使用 CPU 进行计算的,在图像的矩阵运算效率上,相对 GPU 要慢一些。
此时,有了数据的支撑,决定替换人脸识别框架层配合RN进行尝试性优化,采用face-api.js
face-api.js
基于 TensorFlow.js 内核,实现了三种卷积神经网络架构,用于完成人脸检测、识别和特征点检测任务;其内部实现了一个非常轻巧,快速,准确的 68 点面部标志探测器。支持多种 tf 模型,微小模型仅为 80kb。另外,它还支持 GPU 加速,相关操作可以使用 WebGL 运行。
核心原理是针对人脸检测工作实现了一个 SSD(Single Shot Multibox Detector)算法,它本质上是一个基于 MobileNetV1 的卷积神经网络(CNN),在网络的顶层加入了一些人脸边框预测层。

face-api面部标志探测器(图片来源官方文档)
确认替换后,针对于React Native线程调度做一下调优,为了方便理解,我简单绘制了一个示意图,讲解下流程:
• JS Thread:React 等 JavaScript 代码都在这个线程执行。
• Bridge:连接桥,具有异步,序列化,批处理的特点
• Shadow Thread:进行布局计算和构造 UI 界面的线程。
• Native modules提供 Native 功能(比如相册、蓝牙)
• UI Thread:Android/iOS(或其它平台)应用中的主线程。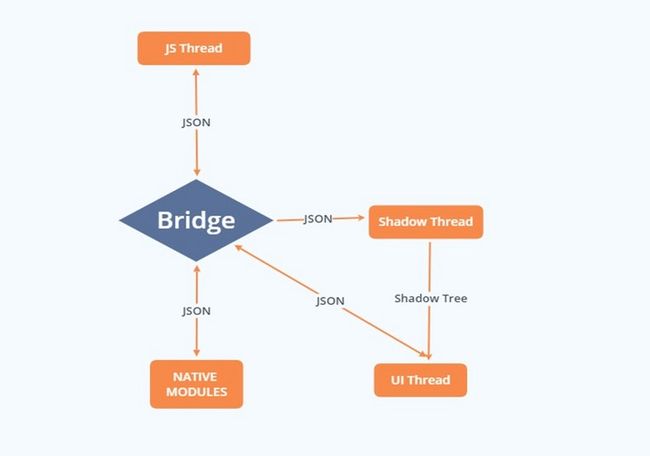
ReactNative线程示意图
比如我们绘制一个UI,JS thread会先对其序列化,形成一条UIManager.createView 消息,然后通过Bridge发到Shadow Thread。Shadow Tread接收到这条信息后,先反序列化,形成Shadow tree,再转换原生布局信息,传给UI thread。
而UI thread 拿到消息后,同样先反序列化,然后根据所给布局信息,进行绘制。
而这一系列都强依赖于 bridge,像高度计算、UI更新每次的操作都通过 bridge传递,任务一多,就会生成任务队列,异步操作批量处理,一些前端的更新很难及时反应到 UI 上,特别是类似于更新频率较高的动画操作,任务较多,很难保证每一帧及时渲染。
那么,优化的方向:
1.减少 JS Thread 和 UI Thread 之间的异步通信,或者减少较少JSON的大小
2.尽量减少 JS Thread 侧的计算
5.解决问题
整体解决方案是face-api替代tracker;React Native做一下调优。下面主要分三步讲下React Native调优。
1.开启动画原生驱动
useNativeDrive: true
JS Thread 和 UI Thread 之间是通过 JSON 字符串传递消息的。对于一些非布局的属性、直接事件,(useNativeDriver 这个属性只能使用到只有非布局相关的动画属性上,例如 transform 和 opacity。布局相关的属性,比如说 height 和 position 相关的属性,开启后会报错。)比如人脸识别成功,人员信息卡片动画,我们可以使用 useNativeDrive: true 开启原生动画驱动。
Animated.timing(this.state.animatedValue, { toValue: 1, duration: 500, useNativeDriver: true, // <-- Add this }).start();
通过启用原生驱动,我们在启动动画前就把其所有配置信息都发送到原生端,利用原生代码在 UI 线程执行动画,而不用每一帧都在两端间来回沟通。如此一来,动画一开始就完全脱离了 JS 线程,因此此时即便 JS 线程被卡住,也不会影响到动画了。
2.使用交互管理器 InteractionManager
使用InteractionManager将部分需要优化的任务在交互操作和动画完成之后再执行,比如:会场分布的跳转动画。目的是平衡复杂任务和交互动画之间的执行时机。
const handle = InteractionManager.createInteractionHandle();// 执行动画... (runAfterInteractions中的任务现在开始排队等候)// 在动画完成之后开始清除句柄:InteractionManager.clearInteractionHandle(handle);// 在所有句柄都清除之后,现在开始依序执行队列中的任务
根据官方解释的解释:runAfterInteractions接受一个回调函数,或是一个PromiseTask对象,该对象返回一个Promise。如果提供的参数是一个PromiseTask, 那么即便是异步的它也会阻塞任务队列,直到它执行完毕后,才会执行下一个任务。这样就可以按需优化动画流畅度。
3.重新渲染
首先,RN与React中,当父组件中触发setState, 未修改任何state中的值也会引起所有子组件的重新渲染, 或者当父组件传给子组件的props发生改变, 不管该props是否被子组件用到, 也都会去重新渲染子组件。
那么,针对重新渲染问题,使用PureComponent和shouldComponentUpdate对于普通函数进行优化;对于hook组件使用memo优化;
至验证后整体得到改善,交互较为流畅,达到基本性能指标。现在主要是针对于概率性问题是否复现。寻求测试同事的帮助。
6.验证问题(性能监控平台的应用)
首先为什么要使用性能监控平台:1.处理重复信息,避免一些问题在多个APP上重复处理,或者在一个APP上反复处理;2持续捕捉重要可疑信息,提升效率,降低人力成本。
其次什么时候、什么场景下使用性能监控平台:除了测试、运维需要使用性能监控平台,开发者也要学会利用性能监控平台去辅助定位解决问题,这里推荐两个方案:
- Google Android Vitals + Firebase
Android vitals是Google为提高Android设备稳定性和性能而推出的一项计划, Google Play 的Android vitals控制台可以突出显示崩溃率、ANR 发生率、唤醒次数过多以及唤醒锁定被卡住等指标。包含了开发者常用功能,关键是不侵入代码,应用比较方便。
而Firebase除此之外还可以获取详细的自定义崩溃报告数据,以了解应用中出现的崩溃情况。该工具会按相似堆栈轨迹将崩溃分门别类,并根据崩溃对用户所产生影响的严重程度进行分级。除了接收自动生成的报告外,还可以通过记录自定义事件来获知导致应用崩溃的操作。
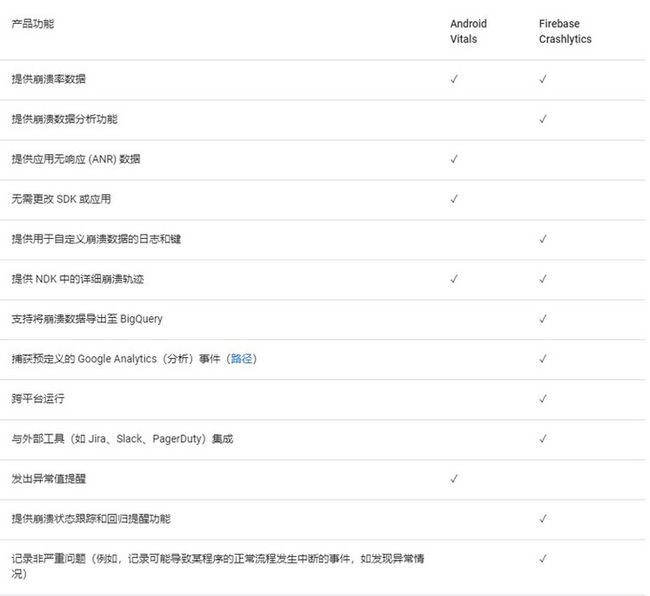
Vitals + Firebase功能对比图(图片来源官网)
所以一般情况下使用Android Vitals可处理大部分简单问题,并可搭配Firebase灵活处理自定义事件。
不太方便的是Google国内限制,需要公司申请专线跨境联网,并且网络波动时,经常需要身份验证(这点比较烦人)。
费用上:Android Vitals使用免费,但是需要25$注册开发者账号;Firebase有免费版和付费版。适合外企、跨国公司或者有相关资质的公司研发使用。
2.友盟+ U-APM
2.1产品概述:
由于Google国内限制,很多企业没有网络报备不能连接外网,那么友盟+ 的U-APM也可以完美满足以上需求。针对于我的项目,我这里是选择接入友盟+SDK协助问题检测。
友盟的推送和统计在业界做的是比较好的,而比较熟悉友盟的朋友应该了解U-APP的稳定性功能,那么U-APM就是友盟+在U-APP稳定性功能的基础上升级推出的一款面向开发者监控应用的稳定性数据产品。

U-APM核心技术与优势(图片来源友盟官网)
为什么选择友盟+ U-APM 应用性能监控平台:
该产品不仅通过发现线上问题-快速定位问题-高效解决问题打造体系化线上质量监控平台。而且拥有支持实时监控线上App崩溃趋势,7*24小时监控告警与修复验证,复现用户崩溃现场,关键环节的重点监控,修复测试等特点。
重点还在于有阿里技术的加持,可以提供长期稳定的产品迭代和项目服务及专家咨询能力。贴心啊,企业工程化需要的就是长期稳定!小厂的产品可能用着用着就找不到人了。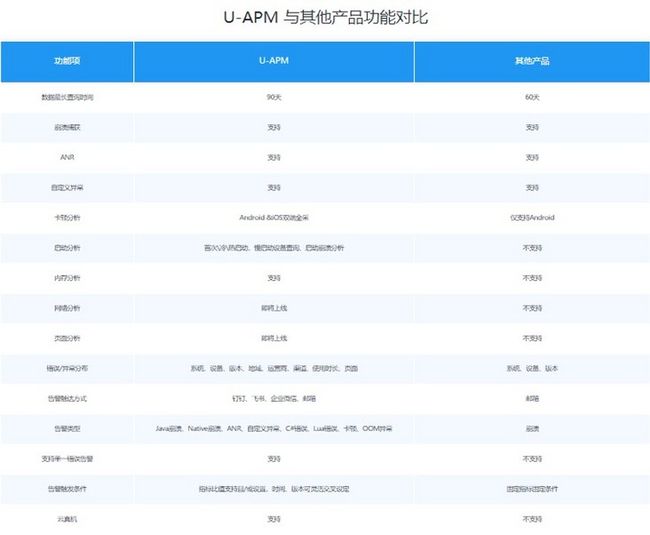
U-APM与竞品功能对比(图片来源友盟官网)
2.2开发准备
如果之前有使用过U-APP的,可以直接查看官网的升级说明按体验U-APM;那么没有使用过友盟产品的需要到 【友盟+】官网 注册并且添加新应用,获得AppKey。
注:请一定认真阅读U-APM合规指南,满足工信部相关合规要求。避免因隐私政策风险导致APP下架。
2.3集成SDK
maven自动集成:
maven自动集成是比较简单快速的
首先在工程build.gradle配置脚本中buildscript和allprojects段中添加【友盟+】sdk 新maven仓库地址。如下图。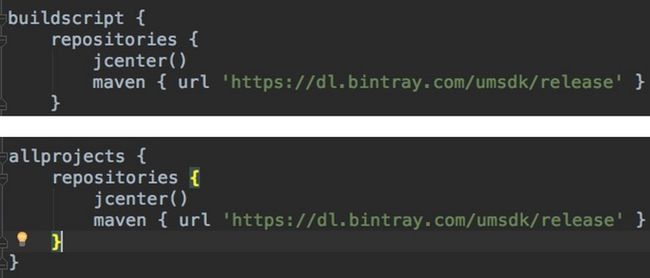
然后在工程App 对应build.gradle配置脚本dependencies段中添加SDK库依赖,是不是很简单呢。
- dependencies {
- implementation fileTree(include:['*.jar'], dir:'libs')
- // 下面各SDK根据宿主App是否使用相关业务按需引入。
- implementation 'com.umeng.umsdk:common:9.4.4'// 必选
- implementation 'com.umeng.umsdk:asms:1.4.1'// 必选
- implementation 'com.umeng.umsdk:apm:1.4.2' // 必选
- }
手动Android Studio集成:
那么我这里是采用的手动集成
1.首先在选择U-APM SDK组件并下载,解压.zip文件得到相应组件包
得到如下文件:
umeng-common-9.4.4.jar // 统计SDK 必选
umeng-asms-armeabi-v1.4.1.aar // 必选
以及apm目录下的
umeng-apm-armeabi-v1.4.2.aar//U-APM SDK 必选
可如有UTDID需求,集成thirdparties下
utdid4all-1.5.2.1-proguard.jar UTDID服务的补充包
如需要ABTest模块,可集成common下
umeng-abtest-v1.0.0.aar ABTest模块
2.在Android Studio的项目工程libs目录中拷入以上jar包。
右键Android Studio的项目工程 —> 选择Open Module Settings —> 在 Project Structure弹出框中 —> 选择 Dependencies选项卡 —> 点击左下“+” —> 选择组件包类型 —> 引入相应的组件包。
3在app的build.gradle文件中引入相应的组件包。参考示例如下:
- repositories{
- flatDir{
- dirs 'libs'
- }
- }
- dependencies {
- implementation fileTree(include:['*.jar'], dir:'libs')
- implementation (name:'umeng-asms-armeabi-v1.4.1', ext:'aar')
- implementation (name:'umeng-apm-armeabi-v1.4.2', ext:'aar')
- }
注意:如果需要适配armeabi 以外的平台,或者遇到了多CPU架构so库加载失败问题[SA10070],除了需要引入相应的包,还要分别下载并考入对应的.so文件。
2.4权限授予
按照官网教程授予如下权限:
2.5混淆设置
如果APP中使用了代码混淆,需要增加如下配置- -keep class com.umeng.* { ; }
- -keep class com.uc.* { ; }
- -keep class com.efs.* { ; }
- -keepclassmembers class *{
- public
(org.json.JSONObject); - }
- -keepclassmembers enum *{
- publicstatic**[] values();
- publicstatic** valueOf(java.lang.String);
- }
2.6初始化sdk
在rn的安卓原生的application.onCreate函数中调用基础组件包提供的初始化函数:
- /**
-
- 注意: 即使您已经在AndroidManifest.xml中配置过appkey和channel值,也需要在App代码中调
-
- 用初始化接口(如需要使用AndroidManifest.xml中配置好的appkey和channel值,
-
- UMConfigure.init调用中appkey和channel参数请置为null)。
- */
- UMConfigure.init(Context context,String appkey,String channel,int deviceType,String pushSecret);
或者调用此预初始化函数
- public static void preInit(Context context,String appkey,String channel)
然后打开日志开关 - /**
- *设置组件化的Log开关
- *参数: boolean 默认为false,如需查看LOG设置为true
- */
- UMConfigure.setLogEnabled(true);
至此即可使用卡顿分析功能、Java、Native崩溃分析、ANR分析功能等等基础功能了。因为其原理通过主线程的响应时间,将有卡顿体验的设备信息、卡顿日志进行上报。那么等待设备上报后我们可以在web控制台看到上传的Error(打印SDK集成或运行时错误信息),Warn(打印SDK警告信息),Info(打印SDK提示信息),Debug(打印SDK调试信息)。以及报表。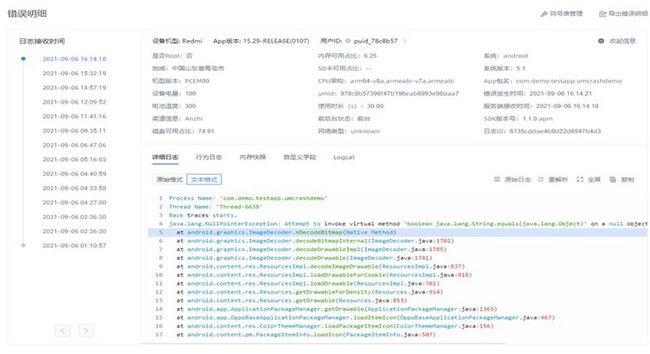
U-APM崩溃信息日志示例图
但是从报文直接看错误堆栈非常麻烦, U-APM利用聚合算法提供了卡顿模块的功能,筛选影响用户量大的200个堆栈从栈顶到栈底双向聚合,展示出现频率前10的模块,子树深度最多支持50层,帮助下挖详细的卡顿模块信息。
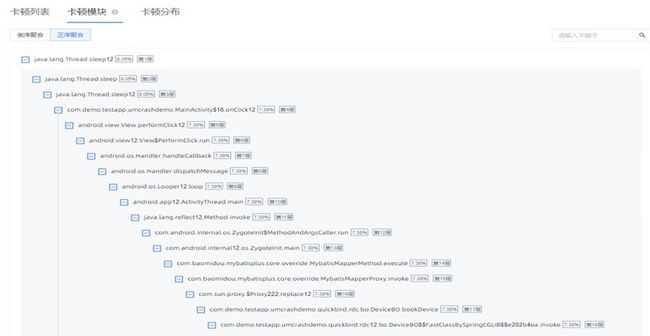
U-APM卡顿模块示例图
除此之外,U-APM中还提供了启动分析、内存分析、网络分析,用户细查模块等高级功能。除了内存分析外是其他功能需要进行配置才能使用的。大家可以去体验一下。
那么最终通过U-APM也是顺利的验证问题、解决问题。完成了整个研发闭环。感兴趣的话,可以免费体验U-APM。
三.项目总结
1.不要盯着问题看。对于app的性能优化也好,系统优化也好。问题的表象可能是由于本质的副作用带来的。例如,本项目中局部现象是卡顿、不流畅,只盯着现象,我们很可能陷入优化困境,去优化渲染、减少canvas绘图,甚至精简业务。而最终突破我们的性能瓶颈是通过修改实现方式达成的,更适合业务场景、更能发挥机器性能。而这一切,需要数据去支撑。
- 用数据说话。不要凭感觉,去检测性能问题、评估性能优化的效果,要有可量化的渲染性能评判标准,以及可量化、可视化的优化工具。利用经验去感觉、猜测对于团队是没有沉淀的,而数据和工具是可以传承的。例如:对于优化性能如果没有标准,对于结果没有数据体现。那么整体的工作是没有意义的,成功与否全靠leader拍脑门决定。
3.使用低配置的设备:同样的程序,在低端配置的设备中,相同的问题会暴露得更为明显。例如:在前期安卓开发真机上并没有卡顿现象,放在工业真机上才暴露出卡顿等问题。而对于高低端设备都能带来很好的用户体验,一直是一个很重要的问题。
4.权衡利弊:在能够保证产品稳定、按时完成需求的前提下去做优化,投入产出比过高时,应采取其他方案,切勿过度优化。永远不要忘记,优化性能的目的是提高用户体验,而不是炫技。
5.抛弃沉没成本:对于研发中已经付出且不可收回的成本,不要影响未来的决策,例如:对于已经使用track开发的人脸识别模块,数据证明选型影响到了性能。投入产出比在可接受范围内,越早替换预期收益越高。