一、不用Sequential模型的解决方案:keras函数式API
1.多输入模型
|
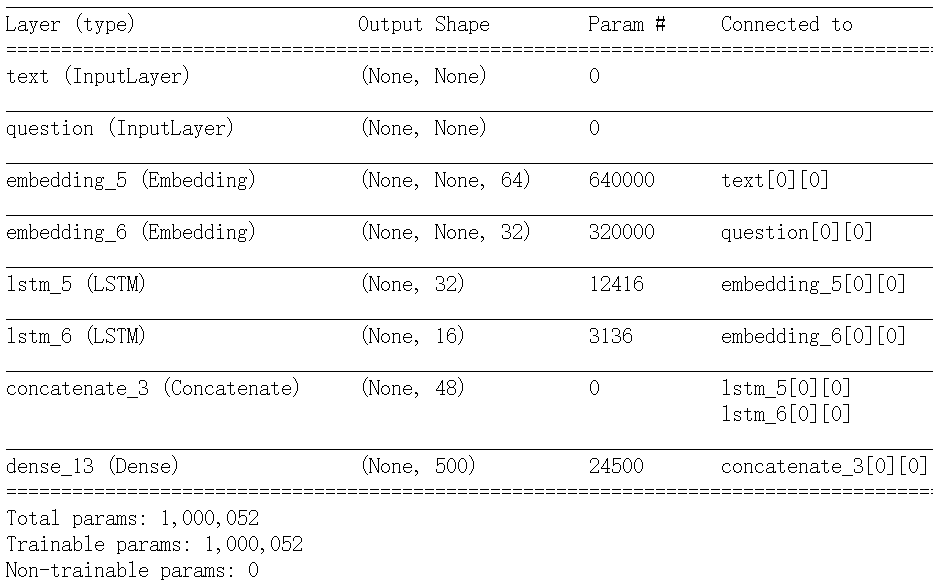
简单的问答模型输入:问题 + 文本片段 输出:回答(一个词) |
|
|
|
训练这种模型需要能够对网络的各个头指定不同的损失函数,例如:年龄预测是标量回归任务,而性别预测是二分类任务,二者需要不同的损失过程。 |
|
|
|
#多输出模型的编译选项:损失加权
|
| 不同的损失值具有不同的取值范围,为了平衡不同损失的贡献,应该对loss_weights进行设置 |
|
|
|
2.多输出模型
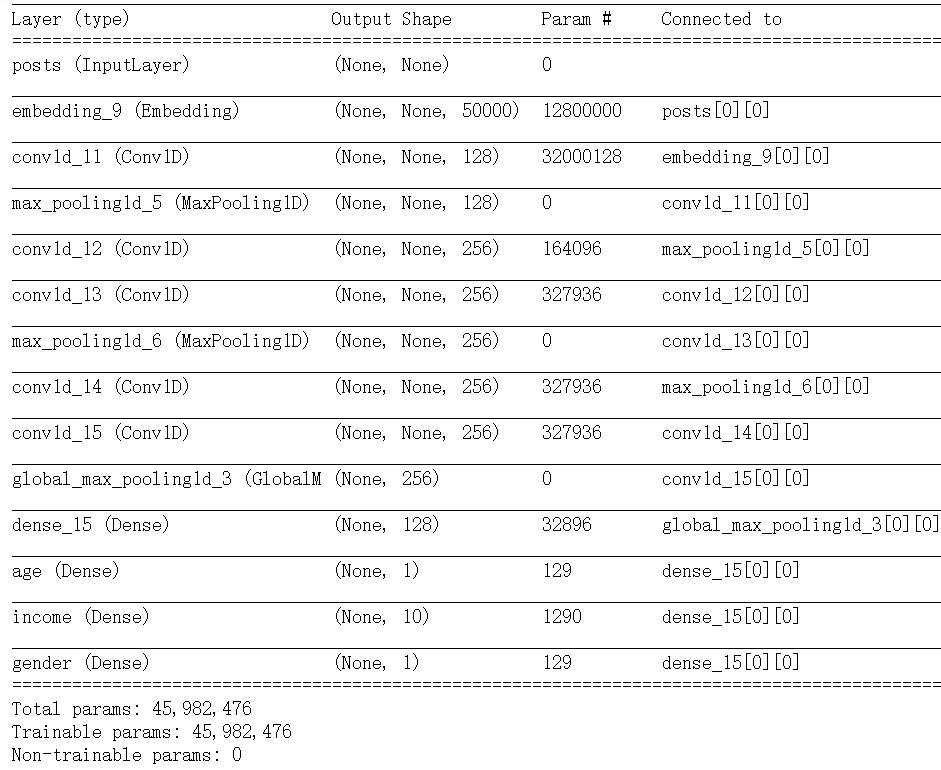
| 一个网络试图同时预测数据的不同性质 输入:某个匿名人士的一系列社交媒体发帖 输出:预测那个人的属性,比如年龄、性别和收入水平 |
|
from keras import layers from keras import Input from keras.models import Model vocabulary_size = 50000 num_income_groups = 10 posts_input = Input(shape=(None,),dtype='int32',name='posts') embedded_posts = layers.Embedding(256,vocabulary_size)(posts_input) x = layers.Conv1D(128,5,activation='relu')(embedded_posts) x = layers.MaxPooling1D(5)(x) x = layers.Conv1D(256,5,activation='relu')(x) x = layers.Conv1D(256,5,activation='relu')(x) x = layers.MaxPooling1D(5)(x) x = layers.Conv1D(256,5,activation='relu')(x) x = layers.Conv1D(256,5,activation='relu')(x) x = layers.GlobalMaxPooling1D()(x) #global池化主要是用来解决全连接的问题,其主要是将最后一层的特征图进行整张图的一个池化, # 形成一个特征点--来源于network in network。 x = layers.Dense(128,activation='relu')(x) age_prediction = layers.Dense(1,name='age')(x) income_prediction = layers.Dense(num_income_groups,activation='softmax',name='income')(x) gender_prediction = layers.Dense(1,activation='sigmoid',name='gender')(x) model = Model(posts_input,[age_prediction,income_prediction,gender_prediction]) model.summary() |
|
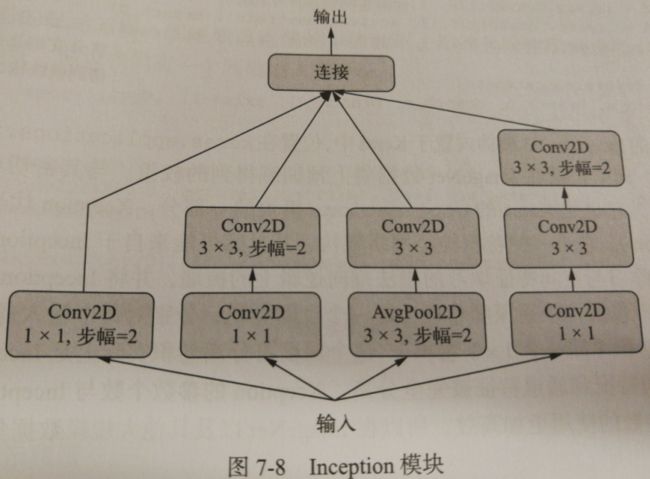
3.层组成的有向无环图
(1)Inception模块
(2)残差网络
如果特征图的尺寸相同,用恒等残差连接(identity residual connection)
from keras import layers
x = ...
y = layers.Conv2D(128,3,activation='relu',padding='same')(x)
y = layers.Conv2D(128,3,activation='relu',padding='same')(y)
y = layers.Conv2D(128,3,activation='relu',padding='same')(y)
y = layers.add([y,x])#将原始x与输出特征相加如果特征图的尺寸不同,用线性残差连接(linear residual connection)
from keras import layers
x = ...
y = layers.Conv2D(128,3,activation='relu',padding='same')(x)
y = layers.Conv2D(128,3,activation='relu',padding='same')(y)
y = layers.MaxPooling2D(2,strides=2)(y)
residual = layers.Conv2D(128,1,strides=2,padding='same')(x)
#使用1*1卷积,将原始x张量线性下采样为与y具有相同的形状
y = layers.add([y,residual])#将残差张量与输出特征相加4.共享层权重
如果你对一个层实例调用两次,而不是每次调用都实例化一个新层,那么每次调用可以重复使用相同的权重。这样你可以构建具有共享分支的模型,
即几个分支全部共享相同的知识并执行相同的运算。也就是说,这些分支共享相同的表示,并同时对不同的输入集合学习这些表示。
举个例子: 假设一个模型想要评估两个句子之间的语义相似度。这个模型有两个输入(需要比较的两个句子),并输出一个范围在0-1的分数,0表示
毫不相关,1表示两个句子完全相同或只是换一种表述。这种模型在许多应用中都很有用,其中包括在对话系统中删除重复的自然语言查询。
在这种设置下,两个输入句子是可以互换的,因为语义相似度是一种对称关系,A相对于B的相似度对于B相对于A的相似度。因此,学习两个单独
的模型来分别处理两个输入句子是没有道理的。相反,你需要用一个LSTM层来处理两个句子。这个LSTM层的表示(即它的权重)是同时基于两个输
入来学习的。我们将其称为连体LSTM(siamese LSTM)或共享LSTM(shared LSTM)模型。
from keras import layers
from keras import Input
from keras.models import Model
lstm = layers.LSTM(32)#将一个LSTM层实例化一次
#构建模型的左分支,输入是长度128的向量组成的变长序列
left_input = Input(shape=(None,128))
left_output = lstm(left_input)
#构建模型的右分支,如果调用已有的层实例,那么就会重复使用它的权重
right_input = Input(shape=(None,128))
right_output = lstm(right_input)
#在上面构建一个分类器
merged = layers.concatenate([left_output,right_output],axis=-1)
predictions = layers.Dense(1,activation='sigmoid')(merged)
#将模型实例化并训练,训练这种模型时,基于两个输入对LSTM层的权重进行更新
model = Model([left_input,right_input],predictions)
model.fit([left_data,right_data],targets)5.将模型作为层
在一个输入张量上调用模型,并得到一个输出张量
y = model(x)如果模型具有多个输入张量和多个输出张量,那么应该用张量列表来调用模型
y1,y2 = model([x1,x2])二、使用Keras回调函数和TensorBoard来检查并监控深度学习模型
1.训练过程中将回调函数作用域模型
训练模型时,我们不知道需要多少轮才能得到最佳验证损失。前面所有例子都采用这样一种策略:训练足够多的轮次, 这时模型已经开始过拟合,根据这第一次运行来确定训练
所需要的正确轮数,然后使用这个最佳轮数从头开始再启动 一次新的训练。------->这种方法很浪费
处理这个问题的更好方法是,当观测到验证损失不再改善时就停止训练。这可以使用keras回调函数来实现。 回调函数(callback)是在调用fit时传入模型的一个对象,它在训练
过程中的不同时间点都会被模型调用。 它可以访问关于模型状态与性能的所有可能数据,还可以采取行动:中断训练、保存模型、加载一组不同的 权重或改变模型的状态
回调函数的一些用法如下:
模型检查点:在训练过程中的不同时间点保存模型的当前权重
提前终止:如果验证损失不再改善,则中断训练(当然,同时保存在训练过程中得到的最佳模型)
在训练过程中动态调节某些参数值:比如优化器的学习率
在训练过程中记录训练指标和验证指标,或将模型学到的表示可视化(keras进度条就是一个回调函数)
| # 1.ModelCheckpoint与EarlyStopping回调函数
|
如果监控的目标指标在设定的轮数内不再改善,可以用EarlyStopping回调函数来中断训练。比如, 这个回调函数可以在刚开始过拟合的时候就中断训练,从而避免用更少的轮次重新训练模型。这个 回调函数通常与ModelCheckpoint结合使用,后者可以在训练过程中持续不断地保存模型(你也 可以选择只保存目前的最佳模型,即一轮结束后具有最佳性能的模型) |
|
如果验证损失不再改善,你可以使用这个回调函数来降低学习率。在训练过程中如果出现了 损失平台,那么增大或减小学习率 都是跳出局部最小值的有效策略。 |
|
|
2. TensorBoard的可视化框架
TensorBoad具有以下巧妙的功能,都在浏览器中实现
在训练过程中以可视化的方式监控指标
将模型架构可视化
将激活和梯度的直方图可视化
以三维的形式研究嵌入
三、让模型性能发挥到极致
1.高级架构模式
(1)批标准化
标准化有利于让机器学习模型看到的不同样本彼此之间更加相似,这有助于模型的学习与对新数据的泛化。最常见的就是将数据减去
平均值使其中心为0,然后除以标准差使其标准差为1.实际上,这种做法假设数据服从正态分布,并确保让该分布的中心为0,同时缩
放到方差为1.
批标准化是Ioffe和 Szegedy在2015年提出的一种层的模型(在Keras中是BatchNormalization),即使在训练过程中均值和方差
随时间发生变化,它也可以适应性的将数据标准化。
-
工作原理: 训练过程中在内部保存已读取每批数据均值和方差的指数移动平均值。
-
主要效果: 它有助于梯度传播(这一点和残差连接很像),因此允许更深的网络。对于有些特别深的网络,只有包含多个Batch
-Normalization层时才能进行训练。
-
例如BatchNormalization广泛用于Keras内置的许多高级卷积神经网络架构,如ResNet50,Inception V3和Xception
-
通常在卷积层或密集连接层之后使用
#在卷积层之后使用
conv_model.add(layers.Conv2D(32,3,activation='relu'))
conv_model.add(layers.BatchNormalization())#在Dense层之后使用
dense_model.add(layers.Dense(32,3,activation='relu'))
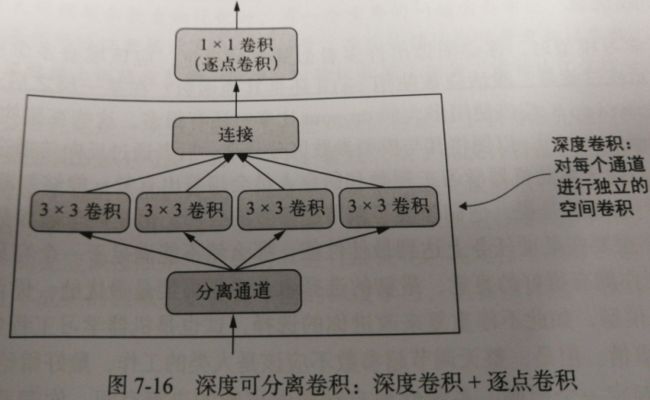
dense_model.add(layers.BatchNormalization())(2)深度可分离卷积
这个层对输入的每个通道分别执行空间卷积,然后通过逐点卷积(1*1卷积)将输出通道混合。这相当于将空间特征学习和通道特征学习分开,
如果你假设输入中的空间位置高度相关,在不同的通道之间相对独立,那么这么做是很有意义的。它需要的参数要少很多,计算量也更小、更
快的模型。因为它是一种执行卷积更高效的方法,所以往往能够使用更少的数据学习到更好的表示,从而得到性能更好的模型。
2.超参数优化
过程如下:
-
选择一组超参数(自动选择)
-
构建相应的模型
-
将模型在训练数据上拟合,并衡量其在验证数据上的最终性能
-
选择要尝试的下一组超参数(自动选择)
-
重复上述过程
-
最后,衡量模型在测试数据上的性能
这个过程的关键在于,给定许多组超参数,使用验证性能的历史来选择下一组需要评估的超参数的算法。有许多不同的技术可供选择:贝叶斯优化、遗传算法、简单随机搜索等。
3.模型集成
以分类问题为例。想要将一组分类器的预测结果汇集在一起【即分类器集成】,最简单的方法就是将他们的预测结果取平均值作为预测结果
#使用4个不同的模型计算初始预测preds_a = model_a.predict(x_val)
preds_b = model_b.predict(x_val)
preds_c = model_c.predict(x_val)
preds_d = model_d.predict(x_val)final_results = 0.25*(preds_a+preds_b+preds_c+preds_d) #这个新的预测数组应该比任何一个初始预测都更加准确只有这组分类器中每一个的性能都差不多一样好的时候,这种方法才奏效。如果其中一个分类器的性能比其他的差很多,
那么最终预测结果可能不如这一组中的最佳分类器那么好。
为了找到一组好的集成权重,你可以使用随机搜索或简单的优化算法(比如Nelder-Mead方法)
final_results = 0.5*preds_a + 0.25*preds_b + 0.1*preds_c + 0.15 * preds_d #加权平均还有许多其他变体,比如你可以对预测结果先取指数再做平均。
集成的模型应该尽可能好,同时尽可能不同。
有一件事基本上是不值得做的,就是对相同的网络,使用不同的随机初始化多次独立训练,然后集成。如果模型之间的唯一区别是随机初始化
和训练数据的读取顺序,那么集成的多样性很小,与单一模型相比只会有微小的改进。
作者提到一种在实践中很有效果的方法:将基于树的方法(比如随机森林或梯度提升树)和深度神经网络进行集成.