零基础的嵌入式机器学习:Edge Impulse使用教程之训练模型浅析(1)——分类模型
前言
没有机器学习基础但是想利用嵌入式AI?Edge Impulse绝对是不二之选! 算法自动提供,代码一键生成,移植简单方便,简直是小白的福音!如果你打算涉及嵌入式 机器学习,那就快来看看吧!
Edge Impulse是一个应用于嵌入式领域的在线的机器学习网站,不仅为用户提供了一些现成的神经网络模型以供训练,还能直接将训练好的模型转换成能在单片机MCU上运行的代码,使用方便,容易上手。本文就Edge Impulse的三大模型之一的分类模型进行浅析。
针对于图像的分类识别模型,读者可参考OpenMv或树莓派等主流图像识别单片机系统的现有历程,容易上手,简单可靠。单击此处转到——星瞳科技OpenMv
所以接下来的分析主要是针对数据进行识别的分类模型。
创建数据集
Edge Impulse支持上传的数据集包含了CSV文件,CSV文件数据集是一种适合于纯数据的数据集,在创建CSV文件的数据集时需要注意一下几点:
1、CSV文件是一种以列为单位构建的数据集,假设我要构建一个y=2x+1的CSV数据集,参考格式如下:
| x | y |
| 0 | 1 |
| 1 | 3 |
| 2 | 5 |
| 3 | 7 |
2、由以上的例子可以看出,CSV数据集的第一行为各类数据的标签,例如0,1,2,3这四个数据的标签为x,而1,3,5,7这四个数据的标签为y。
3、CSV文件默认可以由excel打开,但不建议通过新建一个excel表格的方式来创建一个CSV文件,这样在将excel文件转换为CSV文件的过程中会产生乱码。可以通过创建空白文本文档的方式来创建CSV数据集,以上例子的数据集在文本文档中创建数据集的格式为:

4、在创建CSV文件时,注意要在英文字符的输入法状态下进行编辑。
5、Edge Impulse的CSV数据集默认为时间序列,故在创建上述数据集是,还要在前面加上一列时间戳(timestamp),所以,一个完整格式的CSV数据集应该具有的格式为:

6、如果数据集的序列之间没有先后关系,或者不随时间而变化,那么时间戳(timestamp)没有什么实质上的意义。如果数据集的序列之间存在先后关系,那么则要保证先变化的数据所对银行的时间戳小,后变化的数据的时间戳大。
7、在创建好数据集后,将文件的后缀改为CSV,然后上传到Edge Impluse上。
关于Edge Impulse中CSV数据集的创建,可以参考:Edge Impulse官方文档之CSV数据集
数据参数设置
在本节将以一个上升序列和一个下降序列为例子进行讲解,首先分别创建上升序列和下降序列的CSV数据集:
| UP: | timestamp | d | DOWN: | timestamp | d |
| 0 | 1 | 0 | 10 | ||
| 1 | 2 | 1 | 9 | ||
| 2 | 3 | 2 | 8 | ||
| 3 | 4 | 3 | 7 | ||
| 4 | 5 | 4 | 6 | ||
| 5 | 6 | 5 | 5 | ||
| 6 | 7 | 6 | 4 | ||
| 7 | 8 | 7 | 3 | ||
| 8 | 9 | 8 | 2 | ||
| 9 | 10 | 9 | 1 |
在创建CSV数据集时,把第一列和第四列去掉,第二列和第三列作为一个CSV文件,标识为UP,第五列和第六列作为一个CSV文件,标识为DOWN。
创建完毕后在Edge Impulse工程左侧的Data acquisition中上传数据,将上升序列的标签设置为UP,下降序列的标签设置为DOWN。

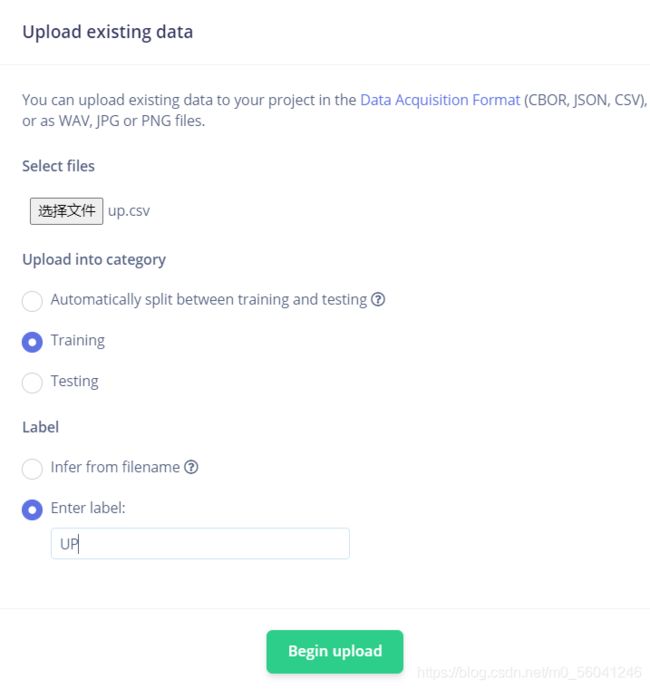
将所有数据上传完毕后,开始创建Impulse。转到Create Impulse,按照如下方式配置并保存(Save Impulse)。
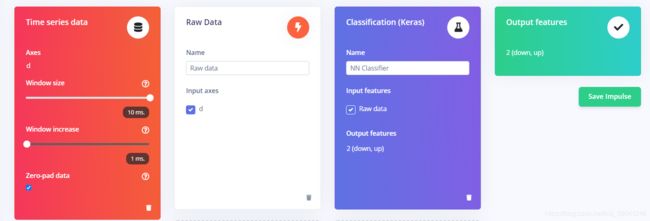
然后在左侧,Create Impulse下面,点击Raw data,点击Save Parameters。然后在上方蓝色栏目处,点击转到Generate features页面,在Generate features页下点击Generate features。

模型训练与测试
然后在左侧,Generate features下,点击NN Classifier,转到训练配置页面,按照如下方式配置训练:

配置完成后点击Start training开始训练模型,等待模型训练完毕。
模型训练完毕后,在右侧转到Model testing,导入一个上升序列的CSV文件或者下降序列的CSV文件进行模型测试,注意导入的CSV序列不可与之前导入的作为训练的序列相同。测试后观察测试结果:
 在配置过程中如果有不明白的地方,可以参考OpenMv口罩识别的视频教程,里面有关于Edge Impulse使用过程的详细视频操作:星瞳科技OpenMv口罩识别
在配置过程中如果有不明白的地方,可以参考OpenMv口罩识别的视频教程,里面有关于Edge Impulse使用过程的详细视频操作:星瞳科技OpenMv口罩识别