机器学习之路10
决策树算法
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习的方法。
一个小例子:
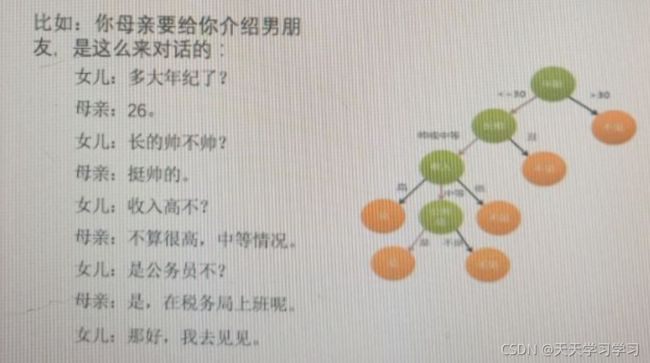
利用决策树要进行高效的决策。就是寻找一个特征的先后顺序,用最少的分支(决策树的深度)来高效的确定最后所属的类别。所以这里就要先看年龄。
再看一个例子:

如果我们先看是否有房子,再看是否有工作,那么只需要看两个特征就能够判断出最后是否需要贷款。
如果我们先看年龄,再看信贷情况,再看工作,那么要看三个特征才能决定是否要贷款。
显然,按房子———>工作来做决策是高效的。
那么如何找到最高效的判断呢?找到最高校的决策顺序呢?要引入信息熵,信息增益
信息熵
是信息的衡量,即信息量,单位是比特,N个样本的信息熵的公式如下:
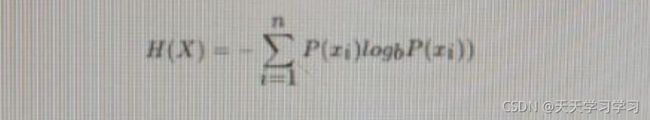

这里,b通常取2。p(xi)为每个样本的概率。 D是样本总是,Ck是某个类别的样本数
小例子计算信息熵:

其中6/15是不贷款的概率,9/15是可以贷款的概率,从而求出总的信息熵是0.971(不确定性),接下来要确定,知道了某个特征之后,不确定性减少的最多,那么我们就应该先看这个特征(以这个特征为开始顺序)
所以我们要求的是,当知道某个特征之后,它的信息熵是多少,所以我们引入信息增益。
决策树的划分依据之一————信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,公式为:

条件熵的计算:

注:信息增益表示得知特征x的信息之后的不确定性减少的程度,使得类Y的信息熵减少的程度
计算H(D|年龄):

所以,哪一个特征的 条件熵最大,那么以此特征进行决策,决策效率会更高一点。
代码实现:利用决策树来进行鸢尾花分类:
#导入决策树算法模块和将树转变为可视化的模块 from sklearn.tree import DecisionTreeClassifier,export_graphviz
#利用决策树对鸢尾花进行分类
def decision_iris():
'''
用决策树对鸢尾花进行分类
:return:
'''
#1 获取数据集
iris = load_iris()
#2 划分数据集,传入特征值和目标值,返回的是,训练集的特征值,测试集的特征值,训练集的目标值,测试集合的目标值
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state = 22)
#3 使用决策树预估器.criterion="entropy"代表用信息增益进行分类
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train,y_train)
#4 模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
#可视化决策树. estimator 预估器。out_file="iris_tree.dot" 输出文件名字(默认当前包下) feature_names = iris.feature_names
#特征名字
export_graphviz(estimator,out_file="iris_tree.dot",feature_names = iris.feature_names)
return None
输出:

决策树的总结:
优点:
简单的理解和解释,决策树能够可视化。
缺点:
决策树学习者可以创建不能很好地推广数据的过于复杂的树,这称为过拟合
改进:
随机森林