Python数据分析与机器学习
Python基础知识和数据结构
基本的数据结构(Basic data structures)
| Name |
Nation |
Declaration e.g. |
| Tuple 元组 |
tuple |
b = (1,2.5, 'data') |
| List 列表 |
list |
c = [1,2.5,'data'] |
| Dictionary 字典 |
dict |
d = {'Name': 'Kobe', 'Country':'US'} |
| Set 集合 |
set |
e = set(['u','d','ud','d','du']) |
- 元组(tuple)只有几种方法可以更改。
- 列表(list)比元组更灵活。
- 字典(dict)是一个键值对存储对象。
- 集合(set)是对象中唯一的无序集合对象。
IPython shell
IPython是一种基于Python的交互式解释器。相较于本地的Python Shell,IPython提供了更为强大的编辑和交互功能。
输入ipython即可进入:

Jupyter notebook
两种安装方法,一种直接pip/pip3 install,一种可以通过Anaconda。
pip3 install jupyter输入jupyter notebook即可进入:
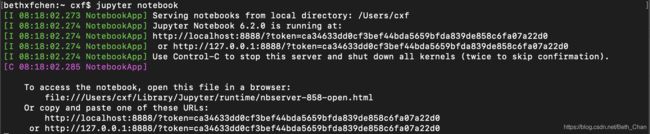
会自动弹出Web UI:
http://localhost:8888/tree
注意:当你使用conda和pip二者安装包时,千万不要用pip升级conda的包,这样会导致环境发生问题。当使用 Anaconda 或 Miniconda 时,最好首先使用conda进行升级。
IPython在in的部分输入代码,按Enter键执行(Jupyter 中是按Shift-Enter)。然后就可以在out看到输出。
概述
python最流行的数据分析库 numpy,pandas,matplotlib。
对于繁琐的机器学习算法,先从原理上进行推导,以算法流程为主结合实际案例完成算法代码,使用scikit-learn机器学习库完成快速建立模型,评估以及预测。
结合经典kaggle案例或其他数据分析案例,从数据预处理开始一步步完成项目,从而对如何应用python库完成实际的项目有完整的经验与概念。
什么样的数据?
当书中出现“数据”时,究竟指的是什么呢?主要指的是结构化数据(structured data),这个故意含糊其辞的术语代指了所有通用格式的数据,例如:
- 表格型数据,其中各列可能是不同的类型(字符串、数值、日期等)。比如保存在关系型数据库中或以制表符/逗号为分隔符的文本文件中的那些数据。
- 多维数组(矩阵)。
- 通过关键列(对于 SQL 用户而言,就是主键和外键)相互联系的多个表。
- 间隔平均或不平均的时间序列。
这绝不是一个完整的列表。大部分数据集都能被转化为更加适合分析和建模的结构化形式,虽然有时这并不是很明显。如果不行的话,也可以将数据集的特征提取为某种结构化形式。例如,一组新闻文章可以被处理为一张词频表,而这张词频表就可以用于情感分析。
大部分电子表格软件(比如 Microsoft Excel,它可能是世界上使用最广泛的数据分析工具了)的用户不会对此类数据感到陌生。
引入惯例
Python 社区已经广泛采取了一些常用模块的命名惯例:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels as sm也就是说,当你看到np.arange时,就应该想到它引用的是 NumPy 中的arange函数。这样做的原因是:在 Python 软件开发过程中,不建议直接引入类似 NumPy 这种大型库的全部内容(from numpy import *)。
流程
工作任务不同,大体可以分为几类:
-
与外部世界交互
阅读编写多种文件格式和数据存储;
-
数据准备
数据清洗、修改、结合、标准化、重塑、切片、切割、转换数据,以进行分析;
-
转换数据
对旧的数据集进行数学和统计操作,生成新的数据集(例如,通过各组变量聚类成大的表);
-
建模和计算
将数据绑定统计模型、机器学习算法、或其他计算工具;
-
展示
创建交互式和静态的图表可视化和文本总结。
附:行话
数据规整(Munge/Munging/Wrangling) 指的是将非结构化和(或)散乱数据处理为结构化或整洁形式的整个过程。

重要的Python库:
numpy
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包。大多数提供科学计算的包都是用NumPy的数组作为构建基础,eg:Pandas。
提供了以下功能(不限于此):
- 快速高效的多维数组对象
ndarray。 - 用于对数组执行元素级计算以及直接对数组执行数学运算的函数。
- 用于读写硬盘上基于数组的数据集的工具。
- 线性代数运算、傅里叶变换,以及随机数生成。
除了为 Python 提供快速的数组处理能力,NumPy 在数据分析方面还有另外一个主要作用,即作为在算法和库之间传递数据的容器。对于数值型数据,NumPy 数组在存储和处理数据时要比内置的 Python 数据结构高效得多。此外,由低级语言(比如 C 和 Fortran)编写的库可以直接操作 NumPy 数组中的数据,无需进行任何数据复制工作。因此,许多 Python 的数值计算工具要么使用 NumPy 数组作为主要的数据结构,要么可以与 NumPy 进行无缝交互操作。

pandas
pandas经常和其它工具一同使用,如数值计算工具NumPy和SciPy,统计分析库statsmodels,机器学习库scikit-learn,和数据可视化库matplotlib。pandas是基于NumPy数组构建的,特别是基于数组的函数和不使用for循环的数据处理。
主要数据结构:Series,DataFrame和Index。
用得最多的 pandas 对象是DataFrame,它是一个面向列(column-oriented)的二维表结构,另一个是Series,一个一维的标签化数组对象。
Series的字符串表现形式为:索引在左边,值在右边。
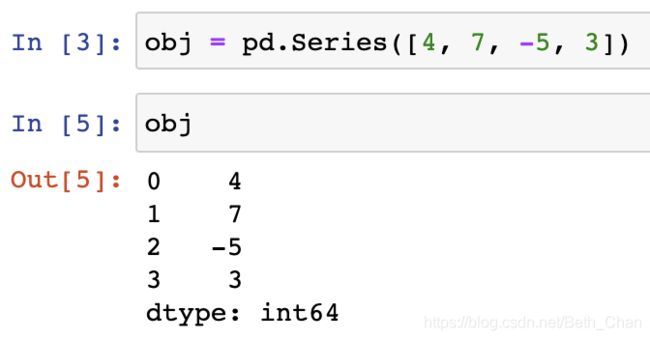
可以通过Series 的values和index属性获取其数组表示形式和索引对象。

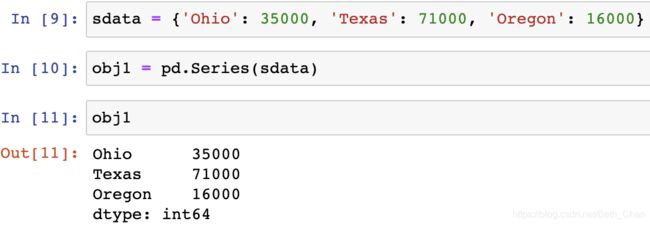
如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series。
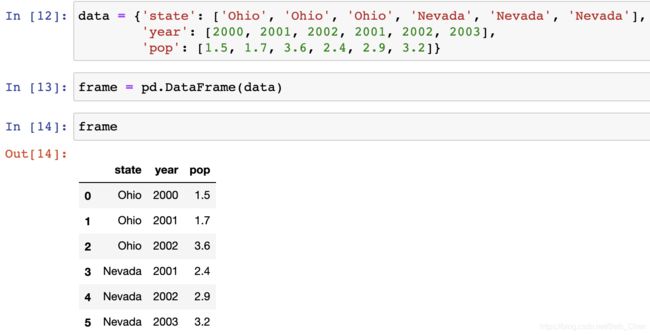
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典,结果DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列。
pandas 兼具 NumPy 高性能的数组计算功能以及电子表格和关系型数据库(如 SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,能更加便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作,数据操作、准备、清洗是数据分析最重要的技能。

scipy
SciPy 是一组专门解决科学计算中各种标准问题域的包的集合,主要包括下面这些包:
scipy.integrate:数值积分例程和微分方程求解器。scipy.linalg:扩展了由numpy.linalg提供的线性代数例程和矩阵分解功能。scipy.optimize:函数优化器(最小化器)以及根查找算法。scipy.signal:信号处理工具。scipy.sparse:稀疏矩阵和稀疏线性系统求解器。scipy.special:SPECFUN(这是一个实现了许多常用数学函数(如伽玛函数)的 Fortran 库)的包装器。scipy.stats:标准连续和离散概率分布(如密度函数、采样器、连续分布函数等)、各种统计检验方法,以及更好的描述统计法。
NumPy 和 SciPy 结合使用,便形成了一个相当完备和成熟的计算平台,可以处理多种传统的科学计算问题。
matplotlib
随着时间的发展,matplotlib衍生出了多个数据可视化的工具集,它们使用matplotlib作为底层。其中之一是seaborn(https://seaborn.pydata.org/)。
seaborn

scikit-learn
Scikit-Learn:https://scikit-learn.org/stable/
User Guide:https://scikit-learn.org/stable/user_guide.html
Github:https://github.com/scikit-learn/scikit-learn
API:https://scikit-learn.org/stable/modules/classes.html
主流深度学习框架:TensorFlow、Keras、PyTorch、Scikit-Learn、Caffe等,算法原理都相通。
Scikit-learn是一个完整的面向机器学习算法的计算库,内建了常见的传统机器学习算法支持,文档和案例也较为丰富,但是 Scikit-learn 并不是专门面向神经网络而设计的,不支持 GPU 加速,对神经网络相关层实现也较欠缺。

算法
子模块包括:
- 分类:SVM、KNN近邻、决策树、随机森林、逻辑回归、朴素贝叶斯算法等等。
- 回归:线性回归、多项式回归、Lasso、岭回归等等。
- 聚类:KMeans k-均值、谱聚类等等。
- 降维:PCA、特征选择、矩阵分解等等。
- 选型:网格搜索、交叉验证、度量。
- 预处理:特征提取、标准化。
梯度下降与梯度提升
监督学习分为两类:
- 分类(classification),预测一个对象所属的类别;
- 回归(regression),预测数轴上的一个特定点;
分类算法常用于:
- 过滤垃圾邮件(朴素贝叶斯);
- 语言检测;
- 查找相似文档;
- 情感分析
- 识别手写字母或数字
- 欺诈侦测
回归算法常用于:
- 股票价格预测
- 供应和销售量分析
- 医学诊断
- 计算时间序列相关性
无监督学习:比如聚类、降维
聚类算法常用于:
- 市场细分(顾客类型,忠诚度)
- 合并地图上邻近的点
- 图像压缩
- 分析和标注新的数据
- 检测异常行为
降维算法常用于:
- 推荐系统
- 漂亮的可视化
- 主题建模和查找相似文档
- 假图识别
- 风险管理
集成学习:
Bagging: 随机森林
Boosting: AdaBoost, GBDT, XGBoost, LightGBM, CatBoost
Stacking
Blending
重点分类算法 LightGBM:
https://lightgbm.readthedocs.io/en/latest/
http://www.huaxiaozhuan.com/%E5%B7%A5%E5%85%B7/lightgbm/chapters/lightgbm_usage.html
https://blog.csdn.net/weixin_39807102/article/details/81912566
LightGBM是使用基于树的学习算法的梯度增强(gradient boosting)框架。它被设计为分布式且高效的,具有以下优点:
-
更快的训练速度和更高的效率。
-
降低内存使用率。
-
更好的准确性。
-
支持并行,分布式和GPU学习。
-
能够处理大规模数据。
Jupyter shift+Tab可看参数列表:
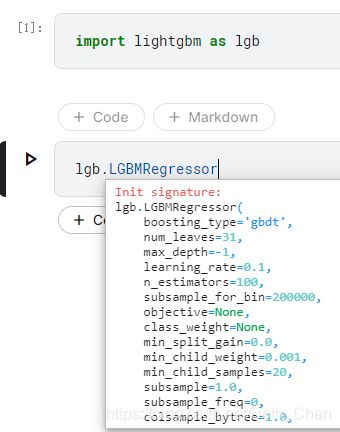
sklearn.model_selection
- train_test_split
- cross_val_score
- cross_val_predict
sklearn.preprocessing
- StandardScaler
- PolynomialFeatures
- LabelEncoder
sklearn.metrics
混淆矩阵、ROC曲线和AUC面积,看看sklearn实现的方法,几个比较常用的方法。
- accuracy_score
分类准确率分数是指分类正确的样本数占总样本总数的比例
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
normalize:默认为true,返回正确分类的比例,如果是false,返回正确分类的数目
>>> import numpy as np
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
>>> accuracy_score(y_true, y_pred, normalize=False)
- confusion_matrix
先看个混淆矩阵的例子
(1)猫预测成猫的有92个,猫预测正狗的有7个,猫预测成猪的有1个
(2)狗预测成猫的有10个,狗预测正狗的有88个,狗预测成猪的有2个
(3)猪预测成猫的有1个,猪预测正狗的有9个,猪预测成猪的有90个
可以看出来对角线上的都是预测正确的样本,其余为分类错误的样本
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
官网例子
>>> from sklearn.metrics import confusion_matrix
>>> y_true = [2, 0, 2, 2, 0, 1]
>>> y_pred = [0, 0, 2, 2, 0, 2]
>>> confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
把这个例子做到表格里看下(标签按sklearn中,数据一般是按大小排序,字母按时字母顺序排序)
- classification_report
这个方法经常会用到,可以一次性获得好几个指标的值
sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False)
官网例子
>>> from sklearn.metrics import classification_report
>>> y_true = [0, 1, 2, 2, 2]
>>> y_pred = [0, 0, 2, 2, 1]
>>> target_names = ['class 0', 'class 1', 'class 2']
>>> print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5
precision 精度 TP / (TP+FP)
recall 召回率 TP / (TP+FN)
f1-score F1 2* P*R/(P+R)
support: 样本数
accuracy:准确率 TP +TN/ (TP+FP+TN+FN)
statsmodels
与 scikit-learn 比较,statsmodels 包含经典统计学和经济计量学的算法。包括如下子模块:
- 回归模型:线性回归,广义线性模型,健壮线性模型,线性混合效应模型等等。
- 方差分析(ANOVA)。
- 时间序列分析:AR,ARMA,ARIMA,VAR 和其它模型。
- 非参数方法: 核密度估计,核回归。
- 统计模型结果可视化。
statsmodels 更关注于统计推断,提供不确定估计和参数 p-值。相反的,scikit-learn 注重预测。
资源
本人是信息与计算科学专业,学过线性代数,概率论与数理统计,数学分析,运筹学,离散数学等数学知识。
书籍:
《利用Python进行数据分析》:https://pyda.apachecn.org
《机器学习实战:基于Scikit-Learn和TensorFlow》
《机器学习》周志华
《统计学习方法》
《深度学习》
《Tensorflow 实战Google深度学习框架》
《TensorFlow实战》黄文坚
《TensorFlow机器学习实战指南》
官方网站、视频与其他学习平台:
numpy:https://www.numpy.org.cn/
pandas:https://www.pypandas.cn/
sklearn:https://sklearn.apachecn.org/#/
吴恩达机器学习(coursera英文版):https://www.coursera.org/learn/machine-learning
吴恩达机器学习(bilibili for coursera 中文版):https://www.bilibili.com/video/BV164411b7dx?from=search&seid=6863868916079837393
吴恩达神经网络与深度学习:https://www.coursera.org/specializations/deep-learning#courses
MOOC-北京理工大学-Python机器学习应用:https://www.icourse163.org/course/BIT-1001872001
数据科学、机器学习平台:https://www.kaggle.com
机器学习100天:https://github.com/MLEveryday/100-Days-Of-ML-Code
最全数据分析资料汇总(含python、爬虫、数据库、大数据、tableau、统计学等):
https://zhuanlan.zhihu.com/p/69869004
机器学习Sklearn全套视频教程(千锋教育):https://www.bilibili.com/video/BV1HJ411v7rv?p=1
天池-工业蒸汽量预测(数据分析案例):https://tianchi.aliyun.com/competition/entrance/231693/introduction
慕课网-Python3入门机器学习 经典算法与应用 轻松入行人工智能:https://coding.imooc.com/class/chapter/169.html
机器学习入门 Scikit-learn实现经典小案例(慕课网):https://www.bilibili.com/video/BV14J411c7Xd
https://github.com/FavioVazquez/ds-cheatsheets
https://github.com/jaystone776/python-data-science-cheatsheet
数理统计知识
- 麻省理工公开课-线性代数
- 可汗学院公开课:线性代数
- 同济大学公开课:线性代数
- 山东大学MOOC-线性代数
- 线性代数讲义 - 华东师范大学数学系
- 线性代数-北京大学出版社
- MIT-18.06-线性代数-完整笔记
- 两小时讲完线性代数
- 矩阵编码:线性代数在计算机科学中的应用
- 线性代数应用-戴维森学院
- 可汗学院公开课:统计学
- 加利福尼亚大学伯克利分校公开课:统计学
- 浙江大学公开课:概率论与数理统计
- 可汗学院公开课:概率
- 概率论与数理统计-重庆大学公开课
- 概率论与数理统计-北京大学公开课
- 概率论与数理统计》浙大版(第四版)
- 概率论与数理统计-中科大公开课
- 商务与经济统计-北师大公开课
- 哈佛大学统计学110讲稿
- 概率论和统计学-Khan Academy
- 麻省理工学院公开课:微积分重点
- 清华大学微积分主讲-刘坤林
- 微积分-浙江大学
- 麻省理工学院公开课:多变量微积分
- 可汗学院公开课:微积分预备
- 麻省理工学院公开课:单变量微积分
- HACC公开课:微积分1
- HACC公开课:微积分II
- 微积分—多元函数与重积分-清华大学
- 数学分析讲义 - 南京大学数学系
- 7天搞定微积分
- 托马斯微积分