OpenCV-Python图像的加法运算cv2.add函数详解
☞ ░ 前往老猿Python博文目录 ░
一、加法概述
图像加法主要有两种用途,一种是可用于减少甚至消除图像采集中混入的噪声,由于图像各点的采集噪声是互不相关的,且噪声具有零均值的统计特性,因此可以对图像进行多次采集形成多副图像,然后将这多副图像相加再取平均值,就可以实现噪点的消除;另一种是用来做特效,把多幅图像叠加在一起,再进一步进行处理。
opencv的加运算就是两幅图像或一副图像和一个标量(标量即单一的数值)相加。对两副图像相加,要求两幅或多幅相加的图像的大小应该相同,处理时将两副图像相同位置的像素的灰度值(灰度图像)或彩色像素各通道值(彩色图像)分别相加;对一副图像和一个标量相加时,则将图像所有像素的各通道值分别与标量进行相加。
二、语法介绍
调用语法:
add(src1, src2, dst=None, mask=None, dtype=None)
参数说明:
- src1, src2:需要相加的两副大小和通道数相等的图像或一副图像和一个标量(标量即单一的数值)
- dst:可选参数,输出结果保存的变量,默认值为None,如果为非None,输出图像保存到dst对应实参中,其大小和通道数与输入图像相同,图像的深度(即图像像素的位数)由dtype参数或输入图像确认
- mask:图像掩膜,可选参数,为8位单通道的灰度图像,用于指定要更改的输出图像数组的元素,即输出图像像素只有mask对应位置元素不为0的部分才输出,否则该位置像素的所有通道分量都设置为0
- dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如RGB用三个字节表示,则为24位)。
- 返回值:相加的结果图像
三、加法运算处理的三种场景
-
相同大小和通道数的两个图像数组相加处理
dst(I)=saturate(src1(I)+src2(I))if mask(I)≠0
即目标图像的每个像素,在mask对应位置的值不为0的情况下,该像素每个通道的值等于src1和src2同样位置像素通道的值相加(饱和)。对saturate和src1(I)的理解请参考《opencv图像处理学习随笔:帮助文档运算公式中saturate的含义》 -
一个图像数组和一个标量相加
dst(I)=saturate(src1(I)+src2)if mask(I)≠0
即目标图像的每个像素,在mask对应位置的值不为0的情况下,该像素每个通道的值等于src1图像的每个像素的每个通道值与标量各值相加(数字化的常量会转成一个代表BGRA的四元组,首元素为该数字值,其他元素为0;如果是四元组则分别相加。下同) -
一个标量和一个图像数组相加
dst(I)=saturate(src1+src2(I))if mask(I)≠0
即目标图像的每个像素,在mask对应位置的值不为0的情况下,该像素每个通道的值等于src2图像的每个像素的每个通道值与标量相加
关于后面两种场景,在OpenCV的文档中,标量还可以用一个与另一个参数对应图像数组的通道数相等元素个数的变量(例如针对场景3,opencv是这样描述的:“Sum of a scalar and an array when src1 is constructed from Scalar or has the same number of elements as src2.channels()”)。这点老猿没有理解,做了相关测试(如针对三通道的图像,标量用一个三元组或三个元素的列表代替)行不通,经与CSDN部分专家讨论及验证测试,发现换成一个四元组可以,如:
>>> import cv2
>>> imgBeauty = cv2.imread(r'F:\pic\beauty.jpg')
>>> img = imgBeauty[0:5, 0:5]
>>>
>>> import cv2
>>> import numpy as np
>>> imgBeauty = cv2.imread(r'F:\pic\beauty.jpg')
>>> img = imgBeauty[0:5, 0:5]
>>> mask = np.zeros([5, 5], dtype=np.uint8)
>>> cv2.add(img,(1,1,1,1))
array([[[231, 226, 225],
[231, 226, 225],
[231, 226, 225],
[230, 225, 224],
[228, 223, 222]],
[[232, 227, 226],
[231, 226, 225],
[231, 226, 225],
[231, 226, 225],
[230, 225, 224]],
[[232, 227, 226],
[232, 227, 226],
[232, 227, 226],
[232, 227, 226],
[231, 226, 225]],
[[231, 226, 225],
[232, 227, 226],
[232, 227, 226],
[232, 227, 226],
[231, 226, 225]],
[[232, 227, 226],
[233, 228, 227],
[232, 227, 226],
[232, 227, 226],
[231, 226, 225]]], dtype=uint8)
个人认为这是因为OpenCV强制对彩色图像处理是四通道的。
备注:关于标量的问题在后面文章《OpenCV-Python常用图像运算:加减乘除幂开方对数及位运算》中已经解决。
四、部分特殊场景案例
OpenCV的文档说明中有些内容说得不是很清楚,下面我们做些测试验证一下。
4.1、加法中是否允许两个输入图像是否都为标量
在文档中介绍src1、src2可以是两个图像数组,也可以是一个图像数组一个标量,那么二者是否都可以是标量。验证代码如下:
>>>import numpy as np
>>>import cv2
>>>img = cv2.add(1,2)
>>> img
array([[3.],
[0.],
[0.],
[0.]])
>>> img.shape
(4, 1)
可以看到是允许二者都是标量,但输出结果是一个二维数组。为什么是四个元素呢,老猿认为是OpenCV强制将标量转为了BGRA四通道的分量进行处理导致的。
4.2、掩膜的使用
掩膜前面已经说得比较清楚了,举例说明会有更好的理解。示例代码:
>>> imgBeauty = cv2.imread(r'F:\pic\beauty.jpg')
>>> img = imgBeauty[0:5, 0:5]
>>> img
array([[[230, 225, 224],
[230, 225, 224],
[230, 225, 224],
[229, 224, 223],
[227, 222, 221]],
[[231, 226, 225],
[230, 225, 224],
[230, 225, 224],
[230, 225, 224],
[229, 224, 223]],
[[231, 226, 225],
[231, 226, 225],
[231, 226, 225],
[231, 226, 225],
[230, 225, 224]],
[[230, 225, 224],
[231, 226, 225],
[231, 226, 225],
[231, 226, 225],
[230, 225, 224]],
[[231, 226, 225],
[232, 227, 226],
[231, 226, 225],
[231, 226, 225],
[230, 225, 224]]], dtype=uint8)
>>> mask = np.zeros([5, 5], dtype=np.uint8)
>>> mask[1]=[1,0,-1,1,0]
>>> mask[2] = [-2, -1, 0, 1, 2]
>>> mask
array([[ 0, 0, 0, 0, 0],
[ 1, 0, 255, 1, 0],
[254, 255, 0, 1, 2],
[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0]], dtype=uint8)
>>> dest = np.zeros([5, 5, 3], dtype=np.uint8)
>>> img2 = cv2.add(img, img, mask=mask, dst=dest)
>>> img2
array([[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
[[255, 255, 255],
[ 0, 0, 0],
[255, 255, 255],
[255, 255, 255],
[ 0, 0, 0]],
[[255, 255, 255],
[255, 255, 255],
[ 0, 0, 0],
[255, 255, 255],
[255, 255, 255]],
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]]], dtype=uint8)
>>> img2 is dest
True
从上面执行的案例可以看到:
①、img和img自身相加后,带掩膜参数执行时,只有掩膜为不为0的像素值保留,其他值被置为0
②、由于img每个像素的单通道的值比较大,导致img+img之后,每个通道的值被置为了255,即是饱和加法的结果
③、加法的返回值就是dst参数指定的对象
4.3、关于参数dtype
在帮助文档中介绍,参数src1和src2可以有不同的图像深度(即图像像素位数,如8位、16位、24位和32位),如可以将16位图像和一个8位图像相加将输出结果保存在32位输出数组中。
关于这点老猿没有理解,如果图像深度不一样,意味着图像的通道数也不一样,通道数不一样,意味着数组大小不一样,这样的两个数组无法相加。做了些测试也无法验证这个说明,一般情况下也不需要这样使用,暂且存疑吧。
备注:关于dtype的问题在后面文章《OpenCV-Python常用图像运算:加减乘除幂开方对数及位运算》中已经解决。
4.4、 关于加法算术表达式
对于上面介绍的加法场景中相同大小和通道数的两个图像数组相加处理,对于公式为:
dst(I)=saturate(src1(I)+src2(I))if mask(I)≠0
opencv文档中介绍上面函数可以使用矩阵表达式进行替换,替换的矩阵表达式如下:
dst = src1 + src2
但老猿对此进行了测试,发现opencv-python执行该加法时是纯粹的矩阵运算,没有执行opencv-python的add加法,因为加法结果未执行饱和加法。因此该说法至少在opencv-python中不正确,在opencv-python中要执行图像加法还是调用add函数执行。
五、加法运算案例
下面有两张图片,第一张图片是图像处理常用的几张图片的合集,图片名为imgs.jpg,对应图片如下:

第二张图片是背景图片,图片名bkground.jpg:

我们将两张图片进行加法处理。代码如下:
import numpy as np
import cv2
def main():
img1 = cv2.imread(r'F:\pic\imgs.png')
img2 = cv2.imread(r'F:\pic\bkground.jpg')
print(img1.shape,img2.shape)
mask = np.zeros(img1.shape[0:2], dtype=np.uint8)
mask[0:100,0:100] = 1
imgNomask = cv2.add(img1, img2)
imgMask = cv2.add(img1, img2,mask=mask)
cv2.imshow('imgNomask',imgNomask)
cv2.imshow('imgMask', imgMask)
cv2.waitKey(0)
main()
运行显示图片:

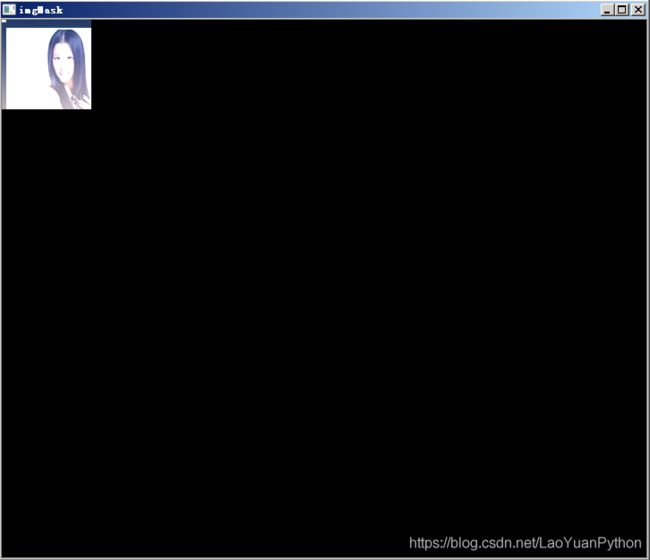
六、小结
本节详细介绍了OpenCV-Python的加法的作用、运算函数add的语法调用、参数使用以及加法运算不同输入场景的处理过程,并就OpenCV官方文档中未详细说明的一些细节进行了解释和验证,同时提供了图像加法处理的代码样例。
更多OpenCV-Python的介绍请参考专栏《OpenCV-Python图形图像处理》相关文章。
关于老猿的付费专栏
老猿的付费专栏《使用PyQt开发图形界面Python应用》专门介绍基于Python的PyQt图形界面开发基础教程,付费专栏《moviepy音视频开发专栏》详细介绍moviepy音视频剪辑合成处理的类相关方法及使用相关方法进行相关剪辑合成场景的处理,两个专栏都适合有一定Python基础但无相关知识的小白读者学习。
付费专栏文章目录:《moviepy音视频开发专栏文章目录》、《使用PyQt开发图形界面Python应用专栏目录》。
对于缺乏Python基础的同仁,可以通过老猿的免费专栏《专栏:Python基础教程目录》从零开始学习Python。
如果有兴趣也愿意支持老猿的读者,欢迎购买付费专栏。
